YOLOv5训练自己的数据集(含数据采集、数据标注、数据预处理、借助colab训练)
YOLOv5 github:GitHub - ultralytics/yolov5: YOLOv5 in PyTorch > ONNX > CoreML > TFLite
先从github下载源码到本地,用pycharm打开工程
采集数据:
本次采集数据采用的方式是录取视频,然后用python截取视频帧当做图片,这是处理代码:
import cv2
import os
video_path = "../test"
save_path = "../data/images"
img_name = 0
for video_file in os.listdir(video_path):
cap = cv2.VideoCapture(os.path.join(video_path,video_file))
frame_count = 0
while cap.isOpened():
ret, frame = cap.read()
if (frame_count % 12) == 0 :
print(frame_count)
if ret:
frame = cv2.resize(frame,(416,416))
cv2.imwrite(os.path.join(save_path, str(img_name)+'.jpg'),frame)
img_name += 1
else:
cap.release()
frame_count += 1标注数据:
可以使用labelimg工具、make sense(Make Sense)在线标注,注意数据集需要与yolo对应的格式(label文件夹下是txt文件)
这是之前写过的voc数据集转yolo格式的代码:
from xml.etree import ElementTree as ET
import os
xml_path = r"F:\traffic_signs_yolov5\Annotations"
label_path = r"F:\traffic_signs_yolov5\labels\train"
image_path = r"F:\traffic_signs_yolov5\images\train"
class_name = []
for xml_file in os.listdir(xml_path):
xml2txt_name = os.path.splitext(xml_file)[0] + '.txt'
tree = ET.parse(os.path.join(xml_path,xml_file))
root = tree.getroot()
sign_object = root.findall('object')
img_size = root.find("size")
img_width = int(img_size.find("width").text)
img_height = int(img_size.find("height").text)
if sign_object:
for sign in sign_object:
name = sign.find('name')
sign_name = name.text
if sign_name not in class_name:
class_name.append(sign_name)
class_id = class_name.index(sign_name)
bndbox = sign.find('bndbox')
xmin = float(bndbox[0].text)
ymin = float(bndbox[1].text)
xmax = float(bndbox[2].text)
ymax = float(bndbox[3].text)
width = (xmax - xmin) / img_width
height = (ymax - ymin) / img_height
x_center = (xmin + (xmax - xmin)/2) / img_width
y_center = (ymin + (ymax - ymin)/2) / img_height
with open(os.path.join(label_path,xml2txt_name), 'a') as f:
f.write("{} {} {} {} {}\n".format(class_id, x_center, y_center, width, height))
else:
#with open(os.path.join(label_path,xml2txt_name),'a') as f:
# f.write("")
remove_img_name = os.path.splitext(xml_file)[0] + '.jpg'
if os.path.exists(os.path.join(image_path,remove_img_name)):
os.remove(os.path.join(image_path,remove_img_name))
print("remove {}".format(remove_img_name))
print("class_name:",class_name)
最后一个是辅助代码,因为存在一种情况,当我们需要手动删除数据图片时,还需要去找对应的label文件删除,这里写了一个代码,检查labels文件夹中多出来的txt文件并删除:
"""
删除labels文件夹中多出来的label file,labels文件夹与images文件夹需一一对应
"""
import os
images_path = r"F:\my_traffic_sign_data\my_traffic_sign_data\train\images"
labels_path = r"F:\my_traffic_sign_data\my_traffic_sign_data\train\labels"
imgs_name = []
for img_name in os.listdir(images_path):
imgs_name.append(os.path.splitext(img_name)[0])
for label_file in os.listdir(labels_path):
if os.path.splitext(label_file)[0] not in imgs_name:
os.remove(os.path.join(labels_path, label_file))
print(len(os.listdir(images_path)))
print(len(os.listdir(labels_path)))准备训练:
准备好数据集后,在工程根目录下新建一个datasets文件夹,将我们的数据集放到该文件夹下,如图所示,注意数据集结构:

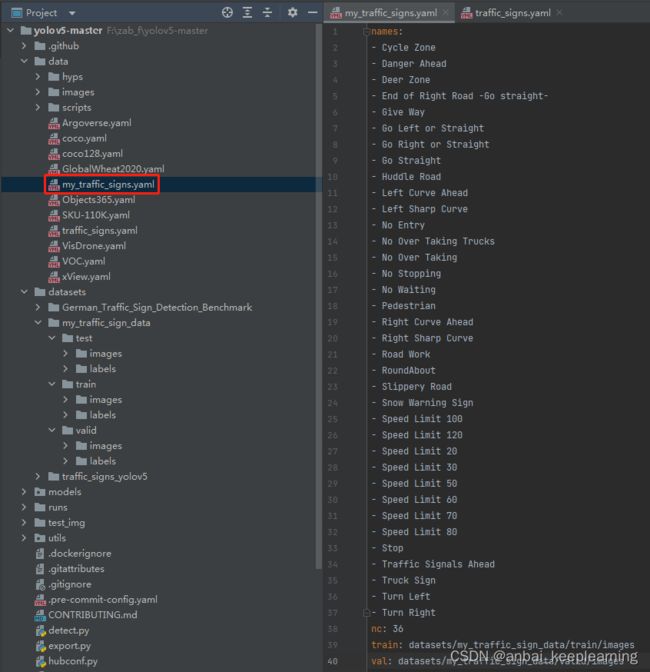
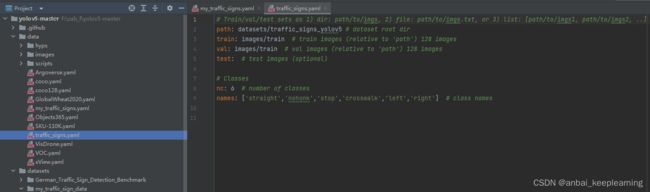
新建yaml文件
接着在yolov5-master/data路径下新建一个yaml文件,根据情况修改类别名称(name)与类别数量(nc)如:
或
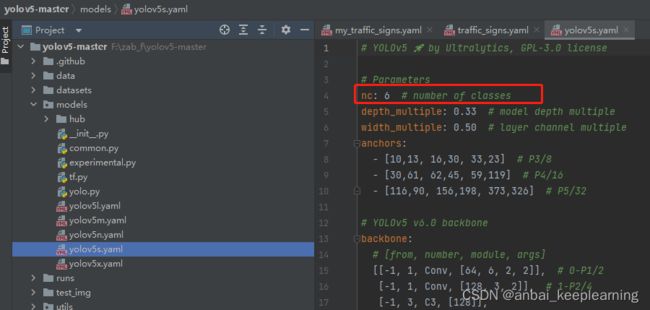
修改yolov5s.yaml文件
修改yolov5-master/models路径下的yolov5s.yaml文件,只需修改类别的数量
训练模型:
在开始训练之前,需要安装环境
可以新建一个虚拟环境
conda create --name yolov5 python=3.7 conda activate yolov5然后找到工程的根目录下的requirements.txt文件,安装所需库
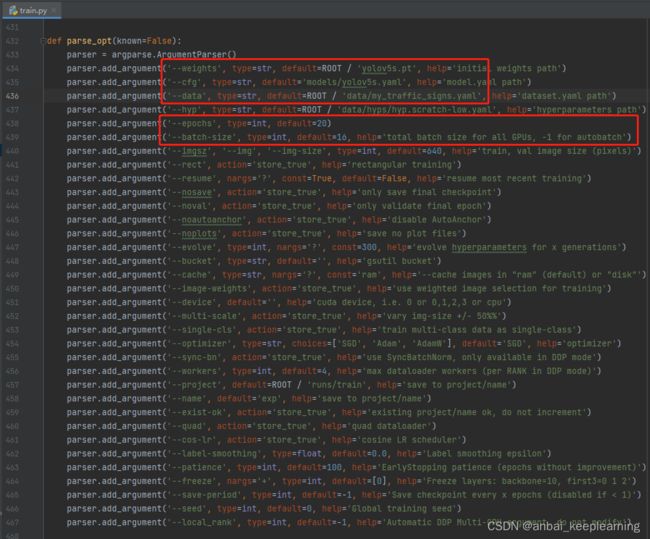
pip install -r requirements.txt # 注意requirement.txt的路径进入到根目录的train.py文件,找到parse_opt()函数,修改相应参数,cfg:配置文件,data:数据集描述文件,其他参数按需修改
运行该文件开始训练
借助colab平台训练:
由于在本地用cpu训练非常慢,这里有一个google的colab云平台(需科学上网),可以免费使用gpu训练,但是有限额,过一会就会恢复
https://colab.research.google.com/
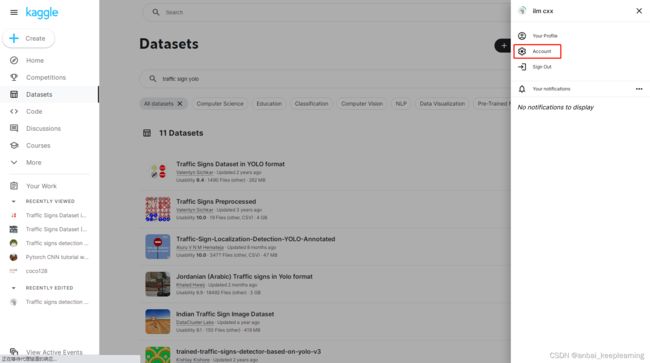
需要上传工程,上传大文件会很慢,若需要上传数据集,可以先上传到kaggle,在自己的kaggle账号中新建datasets,虽然也是很慢,但相对快一点,当上传到kaggle完成后,点击copy API command,复制api下载命令

然后在自己的个人中心中Account,点击生成API Token,然后下载json文件,并将这个json文件上传到colab中

然后在colab中运行以下代码:
!pip install kaggleimport json
token = {"username":"ilmcxx","key":"793c1051a6c90a71e37c111bbf3b7dd5"}
#with open('/content/kaggle.json', 'w') as file:
# json.dump(token, file)
!mkdir -p ~/.kaggle
!cp /content/kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
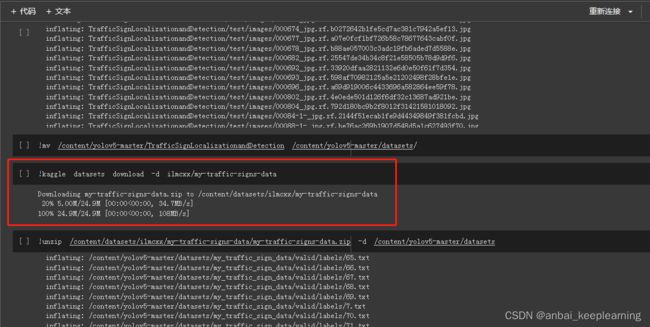
!kaggle config set -n path -v /content然后到colab中复制api下载命令,在前面加上感叹号,代表运行终端命令,运行即可将数据集下载到colab上
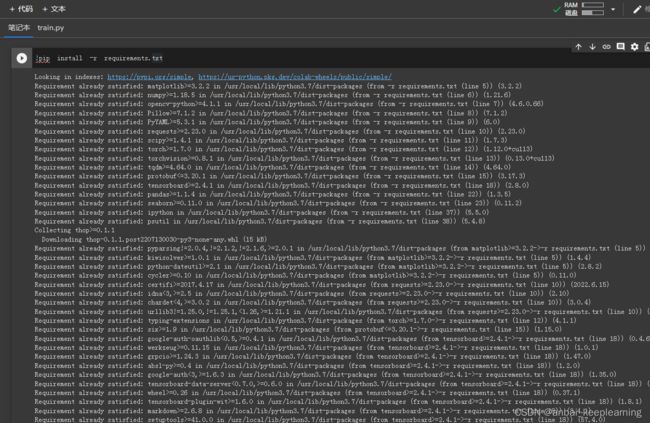
在colab也是需要先安装好环境再进行训练
应用模型:
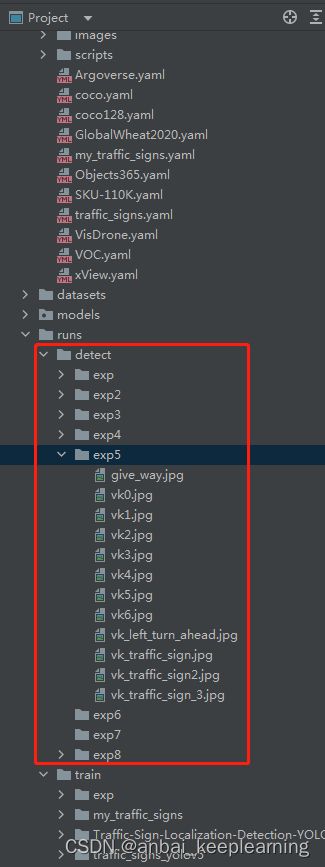
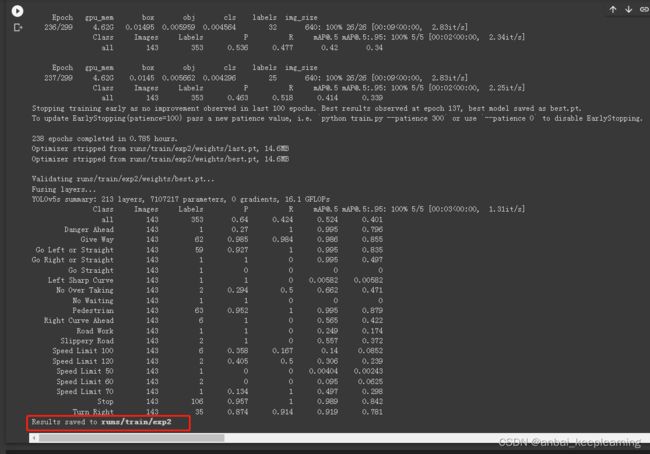
训练完成后,会提示相关文件保存在runs/train文件夹下的exp...中
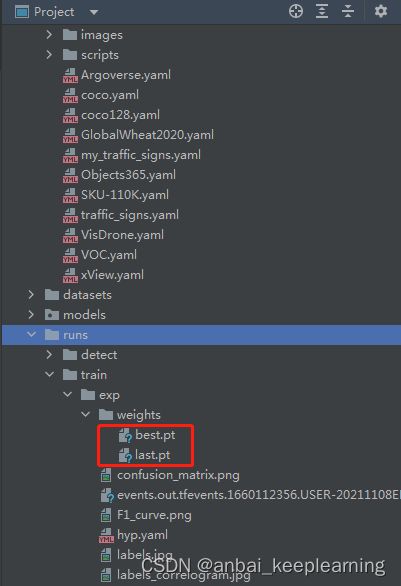
yolov5-master/runs/train/exp/weights文件夹下的则保存了刚刚训练的最好的模型和最后的模型
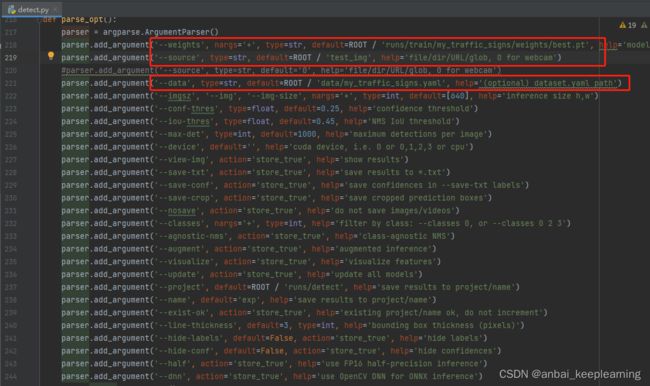
我们打开根目录下的detect.py文件,找到parse_opt()函数,修改相应参数(使用的模型权重文件weights、待识别的图片source、数据集描述文件data),运行该文件
运行完成后,结果会保存在yolov5-master/runs/detect/exp...文件夹中