知识增强预训练语言模型|KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation
1.介绍
预训练的语言表征模型(PLMs) ELMo BERT XLNet
从大规模的非结构和未标记的库中学习有效的语言表征
通常缺乏事实世界知识 ->
利用大规模知识库的实体嵌入为plm提供外部知识
- 他们使用了通过单独的知识嵌入(KE)算法学习的固定实体嵌入,这种算法不能很容易地与语言表示对齐,因为它们本质上是在两个不同的向量空间中。
- 它们需要一个实体链接器将上下文中的单词链接到相应的实体上,从而受益于实体嵌入,这使得它们存在错误传播问题。
- 与普通的plm相比,它们检索和使用实体嵌入的复杂机制导致了额外的推理开销。
->知识嵌入方法和自然语言处理模型有着紧密联系,目前不仅有许多研究将知识嵌入到自然语言处理模型中,以提高自然语言处理应用的性能,如机器翻译(Zaremoodi et al., 2018)、阅读理解(Mihaylov and Frank, 2018;钟等,2019)与对话体系。也有一些早期作品将文本作为附加信息(Xie et al., 2016;An et al., 2018)或联合训练嵌入在同一空间的知识和文本。
本文提出用一个统一的模型学习知识嵌入和语言表示,并将它们编码到同一个语义空间中,这样不仅可以更好地将知识整合到plm中,而且还可以利用有效的语言表示学习更多的有益的知识嵌入。我们提出了KEPLER,它是“知识嵌入和预训练语言表示的统一模型”的缩写。我们收集知识图中实体的信息文本描述,利用典型的PLM将描述编码为文本嵌入,然后将描述嵌入视为实体嵌入,并在此基础上优化KE目标函数。其关键思想是利用PLM将结构化知识编码到实体的文本表示中,并将其推广到知识图中未观察到的实体。
本文:
- 我们在KE目标的监督下将世界知识集成到plm中,使plm更加灵活,并将实体和文本编码到同一个空间中,避免了语言表示和固定实体嵌入之间的差距。
- 我们不需要实体链接器或其他机制来检索相应的实体嵌入,这避免了错误传播问题和额外的开销。在推理过程中,我们的KEPLER与标准PLMs完全相同,可以在广泛的NLP应用中采用。
- 与传统的KE方法不同,我们的KEPLER将文本实体描述编码为实体嵌入,这使得我们的模型能够推断出在归纳设置中的知识嵌入(为不可见的实体获取实体嵌入)。这对于部署特别有用,因为模型可能会处理不可见的实体。
现有的KE数据集规模相对较小,不足以对大型模型进行预训练,通常缺乏用于归纳设置的描述数据和数据分割。因此,我们构造了一种新的大型知识图数据集Wikidata5m,该知识图数据集对每个实体进行了对齐的文本描述。Wikidata5m是Wikidata的一个子集,是一个拥有大约6000万个实体的免费知识库。为了确保每个实体信息丰富,知识库尽可能干净,我们只选择具有相应维基百科页面的实体。我们的Wikidata5m包含了500万个实体和2000万个三元组。我们还在Wikidata5m上对几个经典的KE方法进行了基准测试,以促进未来的研究。据我们所知,这是第一个百万规模的通用知识图数据集。
综上所述,我们的贡献有三方面:
- 我们提出将实体和文本编码到同一个空间中,联合训练KE和语言建模目标,从而得到一个更好的知识增强PLM,避免了错误传播和额外的开销。各种NLP任务的实验结果证明了开普勒的有效性。
- 将文本描述编码为实体嵌入,利用文本信息改进了可识别文本,实现了归纳可识别文本。
- 引入新的大规模知识图数据集Wikidata5m,对大规模知识图、归纳知识嵌入以及知识图与自然语言处理的交互研究具有一定的促进作用。
2.相关工作
NLP预训练
从 分布式的词嵌入模型 -> 语境化的单词嵌入 =使用预先训练的单词嵌入作为输入特征的方法 -> 预先训练的编码器 - > 一些研究试图将知识信息纳入到预训练工作中(这些方法带来了知识增强技术,但它们要么使用固定的外部知识信息,要么使用复杂的结构或管道来处理句子中的实体)
知识嵌入 人们通过预测图中的缺失环节来研究知识图的嵌入
之后有提出利用实体描述作为外部信息源,并引入实体描述编码器来增强TransE评分功能
与我们的方法相似,Xie等人(2016)的目标是利用实体描述来帮助知识表示学习,而我们将实体描述作为一种工具,将外部知识纳入我们的模型
3. 开普勒模型
在本节中,我们将介绍开普勒模型的结构,以及如何结合掩蔽语言建模和知识表示学习这两个训练目标。
3.1 训练目标
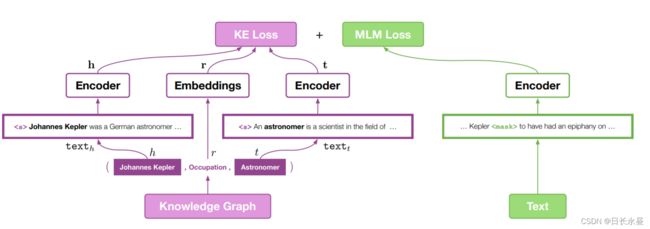
为了将世界知识整合到我们的预训练语言表示模型(PLMs)中,设计了一个如图1和方程1所示的多任务损失
![]()
(同一 plm plm作为文本编码器)
LKE表示知识嵌入损失,LLM表示语言模型损失。由于plm同时参与了这两个任务,联合优化这两个目标可以隐式地将来自外部图的知识与文本编码器整合在一起,同时保持plm强大的语法和语义理解能力。
对于LKE,采用一般的LKE格式,使用负采样。评分函数,有很多选择。与传统的知识嵌入方法不同,对于实体嵌入h和t,我们使用plm作为文本编码器,从它们的描述中提取实体表示,而不是在嵌入表中查找。
对于LLM,可以使用许多备选的预训练语言表示方法,例如掩蔽语言模型。
这两个任务只共享文本编码器,对于每个小批处理,LKE和LLM的文本采样(不一定)是相同的。
3.2 模型细节
实验中使用的特定模型解释如下。
模型结构
使用transformer体系结构。更具体地说,我们在所有的实验中使用了RoBERTaBASE代码和检查点,因为它是最先进的预训练模型之一,具有可接受的计算要求。除了训练数据和超参数外,RoBERTa和BERT之间的一个主要区别是RoBERTa使用BytePair编码(BPE) (Sennrich et al., 2016)来更好地对罕见词进行标记。
给定一个token序列x1, x2,…, xN,输入格式为[CLS], x1, x2,…, xN, [EOS],其中[CLS]和[EOS]是两个特殊的token。在[CLS]处的模型输出经常被用作句子表示。
PLM目标
灵感来自BERT,使用MLM。MLM随机选取15%的输入token,其中80%用特殊标记[MASK]进行屏蔽,10%被另一个随机token替换,其余的保持不变。在MLM下,模型试图预测正确的tokens,在选定的位置上计算交叉熵损失。
我们采用RoBERTaBASE的预先训练的检查点来初始化我们的模型。然而,我们仍然保持MLM作为我们的目标之一,以避免灾难性的遗忘(McCloskey和Cohen, 1989年),并训练KRL损失。注意,实验表明,只有从RoBERTaBASE检查点进一步的预训练不会带来提升,这表明两个任务的结合对性能的贡献最大。
KE目标
我们使用(Sun et al., 2019b)的损失公式作为我们的KE目标,它采用负采样(Mikolov et al., 2013)进行高效优化。
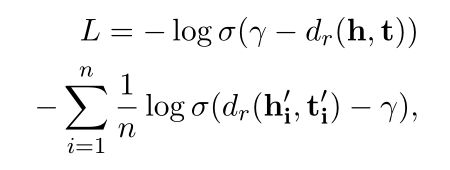
其中(h, r, t)为正确的三元组采样,(h’i, r, t’i)为负采样三元组,γ为边际,σ为sigmoid函数,dr为评分函数。评分函数,由于TransE简单高效,我们选择遵循它。
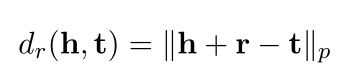
我们取范数p为1。由于计算资源的限制,我们取负抽样大小n为1。负抽样策略是固定头实体,随机抽样尾实体,反之亦然。
与传统的KE方法不同,我们没有实体嵌入查找表。相反,我们使用开普勒模型对相应的实体描述进行编码,并将[CLS]输出作为实体嵌入。
3.3 下游任务
与所有BERT-like模型一样,我们微调KEPLER对于下游任务,使用[CLS]输出进行句子级预测,并将所有token级别的输出用于序列标记任务。对于监督关系提取和少样本关系提取,我们分别采用了(Baldini Soares et al., 2019)和(Gao et al., 2019)的方法。
4 wikidata5m
构造了一个具有对齐文本描述的大规模知识图数据集。我们的数据集是通过将大型开放知识库Wikidata (Vrandeˇci´c and Kr¨otzsch, 2014)与Wikipedia整合而成的。知识图中的每个实体都与维基百科页面中的文本描述对齐。
4.1 数据收集
我们分别从他们的网站上提取了Wikidata2和Wikipedia3的最新转储文件。我们删除第一段包含少于5个单词的页面。对于每个实体,我们使用MediaWiki wbgetenentities动作API将其与维基百科页面对齐。维基百科页面的第一部分被提取为实体的描述。没有相应维基百科页面的实体将被丢弃。
为了构建知识图,我们检索实体页面中的所有语句,并将语句中的实体和关系映射到Wikidata中的规范id。如果一个语句的两个实体都能与Wikipedia页面对齐,并且它的关系在Wikidata中有一个非空页面,则该语句被认为是一个有效的三元组。最终的知识图数据集包含4,813,455个实体、822个关系和21,344,269个三联体,每个实体都有一个文本描述。我们的Wikidata5m数据集和4个常用数据集的统计数据如表1所示。Top-5实体类别如表3所示。我们可以看到,我们的Wikidata5m比现有的知识图数据集大得多,涵盖了各种领域。
4.2 数据分割
传统的数据分割统计转换设置也如表1所示。
在这项工作中,我们也评估模型在具有挑战性的归纳设置,要求模型为训练时看不到的实体生成实体嵌入,并对看不见的实体进行链接预测,因此,我们为归纳设置评价提供了一个数据分割。归纳设置数据拆分统计数据如表2所示。在归纳设置中,训练集、验证集和测试集中的实体集和三元组集是相互不相交的,而在转换设置中,只有三元组集是相互不相交的。
4.3 基准
为了评估Wikidata5m的挑战,我们在数据集上对几个流行的知识图嵌入模型进行了基准测试。由于传统的知识图嵌入模型具有固有的转导性,我们将知识图的三元组集分为训练集、有效集和测试集。每个模型在训练集上进行训练,并在链接预测任务上评估。
我们进行了5个知识图嵌入模型,包括TransE (Bordes et al., 2013)、DistMult (Yang et al., 2015)、ComplEx (Trouillon et al., 2016)、SimplE (Kazemi and Poole, 2018)和RotatE (Sun et al., 2019b)。因为它们最初的实现不能规模扩展到Wikidata5m,所以我们在GraphVite中使用多gpu实现对这些方法进行基准测试(Zhu等人,2019)。链接预测的性能在过滤设置中进行评估,其中测试三元组与知识图中没有观察到的所有候选三元组进行排序。我们报告了标准指标在N (HITS@N)、平均排名(MR)、平均互惠排名(MRR)。
表4显示了Wikidata5m上流行方法的基准
5 实验
本节介绍了开普勒在各种NLP和KE任务上的实验设置和实验结果
5.1 预训练设置
在实验中,我们选择RoBERTa (Liu et al., 2019c)作为我们的基础模型,并在fairseq框架中实现我们的方法(Ott et al., 2019)进行预训练。由于计算资源的限制,我们选择RoBERTaBASE体系结构并使用发布的robertaBase4参数初始化我们的模型。
在我们的预训练步骤,我们只使用英文维基百科语料库来节省时间,也为了与以前的知识增强plm进行公平的比较。
5.2 NLP任务
在本节中,我们将介绍开普勒如何在各种NLP任务中作为知识增强的PLM使用,以及与最先进的模型相比,它的性能。
关系分类
关系分类是一项重要的自然语言处理任务,它需要模型对来自文本的两个给定实体之间的关系类型进行分类。我们在两个常用的数据集上评估我们的模型和基线:taced (Zhang et al., 2017)和FewRel (Han et al., 2018)。taced包含42种关系类型,包含106,264个句子。FewRel是一个少样本关系分类数据集,它有100个关系,每个关系有700个实例。
在这里,我们遵循Zhang等人(2019)的关系提取微调过程,在句子中提到的实体前后添加四个特殊token,以突出显示实体所在的位置。然后我们将[CLS]输出作为句子表示进行分类。
表5为taced各模型的结果,从中我们可以看出我们的模型,在这个基准上达到最先进的水平。注意,一些基线使用预训练语言模型的LARGE版本,而我们仍然采用BASE架构,我们已经在我们的基础模型(RoBERTaBASE)上获得了很大的提升,同时比其他有竞争力的方法(即使他们使用了一个large架构)保持了一点领先。
表5:关系分类数据集taced(%)上的结果。带有∗、+和#的结果分别来自Zhang等人(2019)、Baldini Soares等人(2019)和Peters等人(2019)。BASE和LARGE确定模型是使用基本版本还是大型版本的bert - like架构。
我们的模型在FewRel数据集上也显示出了优势。我们使用Prototypical Networks (Snell et al., 2017)和PAIR (Gao et al., 2019)作为基本框架,并尝试使用不同类型的预训练模型作为编码器。如表6所示,对于这两个框架,我们的模型都有优于其他的性能。但需要注意的是,MTP使用的是BERT的大版本,而我们使用的是基本版本,而且它还执行了一个专门针对关系提取的新的预训练任务,而我们的是一种将知识和自然语言结合起来的通用方法,这将有利于所有与知识相关的任务。
实体类型
实体类型要求模型将提到的给定的实体分类为预定义的实体类型。在这项任务中,评估所有模型在OpenEntity上(Choi等人,2018),根据Zhang等人(2019)的设置,该设置关注9种一般实体类型。
评价结果如表7所示。目前,我们已经取得了比RoBERTa更好的结果,ERNIE和KnowBERT的结果略好于我们。这主要是因为我们使用不同的方法提取实体表示。KnowBERT在提及之前和之后添加了特殊的token,并使用提及之前token的输出作为类型的表示,而我们目前直接使用[CLS]。我们将在未来尝试这种更好的实体表示方式。
5.3 知识嵌入
在本节中,我们将展示KEPLER作为KE模型是如何工作的,并对其进行评估它在Wikidata5m数据集上在归纳设置。
我们没有使用现有的KE基准,因为它们缺乏对其实体的高质量文本描述,并且他们没有一个合理的数据分割为归纳设置。
归纳设置
我们通过在Wikidata5m中的归纳设置上测试开普勒来评估它的泛化能力(如4.2节所述),这就要求它对不可见的实体进行有效的实体嵌入。结果如表8所示。
6 结论与未来工作
在本文中,我们提出了一个用于知识嵌入和预训练语言表示的统一模型KEPLER。在语言表示模型的基础上,我们联合训练知识嵌入目标和语言表示目标。在广泛任务上的实验结果验证了该模型的有效性。
在未来,我们将:
- 评估我们的模型是否能够在更多任务下回忆事实知识。
- 尝试现有模型的变体,例如强调描述中提到的实体,或者改变知识嵌入形式以便更好地理解开普勒的工作原理,并为后续任务带来更多的促进。