word2vec学习笔记之CBOW和skip-gram
文章目录
- 1. Continuous Bag-of-Word Model(CBOW)
-
- 1.1 One-word context(一个词的上下文)
- 1.2 Multi-word context(多个词的上下文)
- 2. Skip-gram model
在上一篇学习笔记《 word2vec学习笔记之文本向量化概述》中介绍了word2vec提出的一些背景(当然,除了该篇文章中所说的一些向量化方法之外,在word2vec之后,还有fasttext,glove等其他方法,但在
word2vec学习笔记系列中不对这些新的方法进行介绍)。本文将详细针对word2vec中的CBOW和skip-gram这两种形式进行详细介绍。本文主要是学习《word2vec Parameter Learning Explained》进行笔记。
word2vec的两个模型与 上一篇笔记中提到的NNLM相似,均是在训练语言模型的过程中,使用语言模型的中间产物来得到词表的词向量。
1. Continuous Bag-of-Word Model(CBOW)

上图是连续词袋模型CBOW的结构图。该模型中,是使用上下文词汇来预测中间词。下面将与《word2vec Parameter Learning Explained》相同,分别从一个词的上下文和多个词的上下文来进行介绍。
1.1 One-word context(一个词的上下文)
这里是先简单的从一个词的输入上下文开始介绍,即假设输入侧只有一个词。此时CBOW模型的结构如下
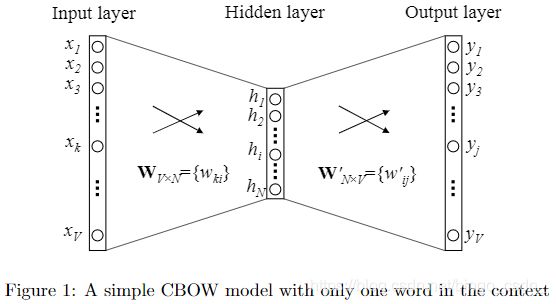
上图中,输入层是一个词的one-hot形式,假设词表大小为V,那么输入是一个大小为V维的one-hot向量,该one-hot向量中,仅有所对应的词的下标处为1,其他位置均为0,我们可以将输入向量记为 x x x。
输入层经过与一个 V ∗ N V*N V∗N大小的矩阵 W V ∗ N W_{V*N} WV∗N相乘后,得到N维大小的隐藏层的向量 h h h,从输入层到隐藏层可以理解为是一个全连接过程,但是跟平时的全连接不同的是,这里没有进行非线性函数的处理。并且,由于输入是一个one-hot向量,因此相乘后的结果实际上是从矩阵 W V ∗ N W_{V*N} WV∗N中取出第 k k k行的向量(one-hot向量中1的下标为k),也就是词 w I w_I wI所对应的词向量。即 h = W T x = W k , ⋅ T : = v w I T h=W^Tx=W^T_{k,·}:=v^T_{w_I} h=WTx=Wk,⋅T:=vwIT
隐藏层再经过与一个 N ∗ V N*V N∗V大小的矩阵 W ′ W' W′相乘后,得到V维大小的输出层的向量 u u u。其中输出层向量中的第 j j j个元素 u j u_{j} uj就是矩阵 W ′ W' W′中的第 j j j列向量 v w j ′ v'_{ w_j} vwj′与隐藏层向量 h h h的乘积 u = h W ′ u=hW' u=hW′ u j = v w j ′ T h u_{j}={v'_{w_j}}^{T}h uj=vwj′Th然后将输出的向量 u u u进行softmax处理,得到此表中每一个词的预测概率,而输出概率最大的词即为本次预测的结果。即,输入 w I w_I wI输出 w j w_{j} wj的概率为 p ( w j ∣ w I ) = y j = e x p ( u j ) ∑ j ′ = 1 V e x p ( u j ′ ) p(w_j|w_I)=y_j=\frac{exp(u_j)}{\sum^V_{j'=1}exp(u_{j'})} p(wj∣wI)=yj=∑j′=1Vexp(uj′)exp(uj)
隐藏层到输出层之间的权重更新
在模型训练过程中,假设当输入的词是 w I w_I wI时,期望输出的词是 w O w_O wO,那么我们希望 p ( w O ∣ w I ) p(w_O|w_I) p(wO∣wI)能够最大,即我们训练的目标是使得下面的式子最大化 max p ( w O ∣ w I ) = max y j ∗ = max log y j ∗ = u j ∗ − log ∑ j ′ = 1 V e x p ( u j ′ ) : = − E \max p(w_O|w_I)=\max y_{j*}=\max \log y_{j*}=u_{j*}-\log \sum^V_{j'=1}exp(u_{j'}):=-E maxp(wO∣wI)=maxyj∗=maxlogyj∗=uj∗−logj′=1∑Vexp(uj′):=−E其中, E = − log p ( w O ∣ w I ) E=-\log p(w_O|w_I) E=−logp(wO∣wI)就是我们所期望能够达到最小的损失函数, j ∗ j* j∗就是实际输出词或者说是我们期望输出词在此表中的下标。
接下来,我们使用反向传播来进行权重的更新。首先是求损失函数 E E E对于 u j 和 w i j ′ u_j和w'_{ij} uj和wij′的求导( u j u_j uj是输出层输出向量的第 j j j个值, w i j ′ w'_{ij} wij′是矩阵 W ′ W' W′的第 i i i行第 j j j列的元素) ∂ E ∂ u j = y j − t j : = e j \frac{\partial E}{\partial u_{j}}=y_j-t_j:=e_j ∂uj∂E=yj−tj:=ej ∂ E ∂ w i j ′ = ∂ E ∂ u j ⋅ ∂ u j ∂ w i j ′ = e j ⋅ h i \frac{\partial{E}}{\partial w'_{ij}}=\frac{\partial E}{\partial u_{j}}·\frac{\partial u_{j}}{\partial w'_{ij}}=e_j·h_i ∂wij′∂E=∂uj∂E⋅∂wij′∂uj=ej⋅hi其中,当 j = j ∗ j=j^* j=j∗的时候 t j t_j tj为1,否则为0。于是,矩阵 W ′ W' W′的更新公式如下 w i j ′ ( n e w ) = w i j ′ ( o l d ) − η ⋅ e j ⋅ h i {w'_{ij}}^{(new)}={w'_{ij}}^{(old)}-\eta·e_j·h_i wij′(new)=wij′(old)−η⋅ej⋅hi或者 v w j ′ ( n e w ) = v w j ′ ( o l d ) − η ⋅ e j ⋅ h {v'_{w_j}}^{(new)}={v'_{w_j}}^{(old)}-\eta·e_j·h vwj′(new)=vwj′(old)−η⋅ej⋅h其中 η \eta η是learning rate。
输入层到隐藏层之间的权重更新
与上述”隐藏层到输出层之间的权重更新“过程类似,可以使用以下几个式子求得损失函数 E E E对 h i 和 w k i h_i和w_{ki} hi和wki的求导 ∂ E ∂ h j = ∑ j = 1 V ∂ E ∂ u j ⋅ ∂ u j ∂ h i = ∑ j = 1 V e j ⋅ w i j ′ : = E H i \frac{\partial E}{\partial h_j}=\sum^V_{j=1}\frac{\partial E}{\partial u_j}·\frac{\partial u_j}{\partial h_i}=\sum^V_{j=1}e_j·w'_{ij}:=EH_i ∂hj∂E=j=1∑V∂uj∂E⋅∂hi∂uj=j=1∑Vej⋅wij′:=EHi ∂ E ∂ w k i = ∂ E ∂ h i ⋅ ∂ h i ∂ w k i = E H i ⋅ x k \frac{\partial E}{\partial w_{ki}}=\frac{\partial E}{\partial h_i}·\frac{\partial h_i}{\partial w_{ki}}=EH_i·x_k ∂wki∂E=∂hi∂E⋅∂wki∂hi=EHi⋅xk其中 h i = ∑ k = 1 V x k ⋅ w k i h_i=\sum^V_{k=1}x_k·w_{ki} hi=k=1∑Vxk⋅wki而由于输入向量 x x x中仅有一个元素非零,因此 v w I ( n e w ) = v w I ( o l d ) − η E H T {v_{w_I}}^{(new)}={v_{w_I}}^{(old)}-\eta EH^T vwI(new)=vwI(old)−ηEHT
1.2 Multi-word context(多个词的上下文)
多个词上下问的CBOW的结构图如下
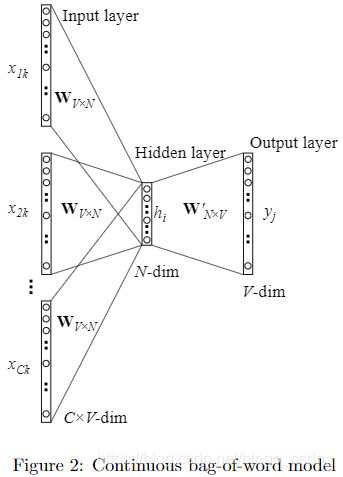
多个词的上下文与单个词的上下文的主要区别在于,每次训练的时候,输入层中的输入词不是一个而是多个。于是,从输入层到中间层的映射变为,将每一个单独的输入词所对应的向量做均值 h = 1 C W T ( x 1 + x 2 + . . . + x C ) = 1 C ( v w 1 + v w 1 + . . . + v w C ) T h=\frac{1}{C}W^T(x_1+x_2+...+x_C)=\frac{1}{C}(v_{w_1}+v_{w_1}+...+v_{w_C})^T h=C1WT(x1+x2+...+xC)=C1(vw1+vw1+...+vwC)T其中,C是输入层输入词的个数。于是损失函数也就变为 E = − log p ( w O ∣ w I , 1 , ⋅ ⋅ ⋅ , w I , C ) E=-\log p(w_O|w_{I,1},···,w_{I,C}) E=−logp(wO∣wI,1,⋅⋅⋅,wI,C) = − u j ∗ + log ∑ j ′ = 1 V e x p ( u j ′ ) =-u_{j^*}+\log \sum^{V}_{j'=1}exp(u_{j'}) =−uj∗+logj′=1∑Vexp(uj′) = − v w O ′ T ⋅ h + log ∑ j ′ = 1 V e x p ( v w j ′ T ⋅ h ) =-{v'_{w_O}}^{T}·h+\log \sum^{V}_{j'=1}exp({v'_{w_j}}^T·h) =−vwO′T⋅h+logj′=1∑Vexp(vwj′T⋅h)于是,更新 W ′ 和 W W'和W W′和W中的值的公式为 v w j ′ ( n e w ) = v w j ′ ( o l d ) − η ⋅ e j ⋅ h {v'_{w_j}}^{(new)}={v'_{w_j}}^{(old)}-\eta·e_j·h vwj′(new)=vwj′(old)−η⋅ej⋅h v w I , c ′ ( n e w ) = v w I , c ′ ( o l d ) − 1 C ⋅ η ⋅ E H T {v'_{w_{I,c}}}^{(new)}={v'_{w_{I,c}}}^{(old)}-\frac{1}{C}·\eta·EH^{T} vwI,c′(new)=vwI,c′(old)−C1⋅η⋅EHT
2. Skip-gram model

上图是跳字模型skip-gram的结构图。该模型中,是使用中间词来预测上下文词汇。
下图中每一个节点均是表示一个向量,将上图中的每一个节点展开为向量,就与下面的图相同
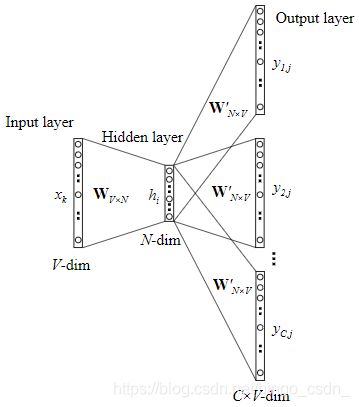
在skip-gram中的输入层到中间层的过程,就与1.1节中介绍的相似,于是也就有了 h = W ( k , ⋅ ) T : = v w I T h=W^T_{(k,·)}:=v^T_{w_I} h=W(k,⋅)T:=vwIT在隐藏层到输出层中,是有多个词输出,而每一个词的输出概率同样是 p ( w c , j = w O , c ∣ w I ) = y c , j = e x p ( u c , j ) ∑ j ′ = 1 V e x p ( u j ′ ) p(w_{c,j}=w_{O,c}|w_I)=y_{c,j}=\frac{exp(u_{c,j})}{\sum^{V}_{j'=1}exp(u_{j'})} p(wc,j=wO,c∣wI)=yc,j=∑j′=1Vexp(uj′)exp(uc,j)于是skip-gram的损失函数就是 E = − log p ( w O , 1 , w O , 2 , . . . , w O , c ∣ w I ) E=-\log p(w_{O,1},w_{O,2},...,w_{O,c}|w_I) E=−logp(wO,1,wO,2,...,wO,c∣wI) = − log ∏ c = 1 C e x p ( u c , j c ∗ ) ∑ j ′ = 1 V e x p ( u j ′ ) =-\log \prod^C_{c=1}\frac{exp(u_{c,j^*_c})}{\sum^V_{j'=1}exp(u_{j'})} =−logc=1∏C∑j′=1Vexp(uj′)exp(uc,jc∗) = − ∑ c = 1 C u j c ∗ + C log ∑ j ′ = 1 V e x p ( u j ′ ) =-\sum^C_{c=1}u_{j^*_c}+C\log \sum^V_{j'=1}exp(u_{j'}) =−c=1∑Cujc∗+Clogj′=1∑Vexp(uj′)其中 w I w_I wI是输入的词,w_{O,c}表示输入的C个词中的第c个。于是,损失函数对输出的第c个输出词向量的第j个元素的求导为 ∂ E ∂ u c , j = y c , j − t c , j : = e c , j \frac{\partial E}{\partial u_{c,j}}=y_{c,j}-t_{c,j}:=e_{c,j} ∂uc,j∂E=yc,j−tc,j:=ec,j损失函数E对矩阵 W ′ W' W′中的第i行第j列元素的求导为 ∂ E ∂ w i j ′ = ∑ c = 1 C ∂ E ∂ u c , j ⋅ ∂ u c , j ∂ w i j ′ = E I j ⋅ h i \frac{\partial E}{\partial w'_{ij}}=\sum^{C}_{c=1}\frac{\partial E}{\partial u_{c,j}}·\frac{\partial u_{c,j}}{\partial w'_{ij}}=EI_j·h_i ∂wij′∂E=c=1∑C∂uc,j∂E⋅∂wij′∂uc,j=EIj⋅hi于是,可更新权重 w i j ′ ( n e w ) = w i j ′ ( o l d ) − η ⋅ E I j ⋅ h i {w'_{ij}}^{(new)}={w'_{ij}}^{(old)}-\eta·EI_j·h_i wij′(new)=wij′(old)−η⋅EIj⋅hi或者 v w j ′ ( n e w ) = v w j ′ ( o l d ) − η ⋅ E I j ⋅ h {v'_{w_j}}^{(new)}={v'_{w_j}}^{(old)}-\eta·EI_j·h vwj′(new)=vwj′(old)−η⋅EIj⋅h
而在skip-gram的输入层到隐藏层的过程与一个词上下文的CBOW相似,矩阵 W W W的更新公式为 v w I ( n e w ) = v w I ( o l d ) − η ⋅ E H T {v^{(new)}_{w_I}}={v^{(old)}_{w_I}}-\eta·EH^T vwI(new)=vwI(old)−η⋅EHT