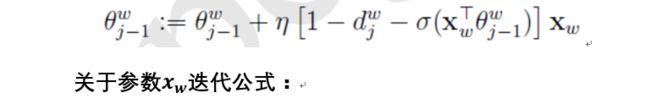Word2Vec理解
综述
本文思想-先论述利用DNN(MLP)模型衍生的CBOW和skip-gram,然后论述负采样算法和哈夫曼树,最后总结
Word2vec两种模型。词嵌入只是模型的副产品,即输入词矩阵。
l 词袋模型就是将句子分词,然后对每个词进行编码,常见的有one-hot、TF-IDF、Huffman编码,假设词与词之间没有先后关系。
l 词向量模型是用词向量在空间坐标中定位,然后计算cos距离可以判断词于词之间的相似性。
1.负采样算法(基于skip-gram模型)
例句(语料库):I want a glass of
orange juice to go along with my cereal
问题:给定例句中的一对单词(例如:orange与juice),预测这是否是一对目标词-上下文词?
思路:此时训练模型必须要有正样本与负样本。假如以(orange-juice)当做正样本,那么固定目标词orange,在例句中随机选取一个单词(假如为juice),则单词对(orange-juice)构成负样本。
l 正样本生成(此时目标词固定为orange):此时orange为目标词,选定窗口大小(假如为2),则在glass of orange juice to 黑色四个单词中随机选取一个(假如选取 of),则单词对(orange-of)构成一个正样本,标签为1。
l 负样本生成:首先必须使用和正样本相同的目标词(即:orange),然后在字典中随机选取一个单词作为上下文词(假如为my),则构成负样本(orange-my),标签为0。其中随机选取K(例如K=4)个单词,生成K个负样本。
下图为一个正样本和K=4个负样本,组成的训练集

注:
01.负样本采样方法:

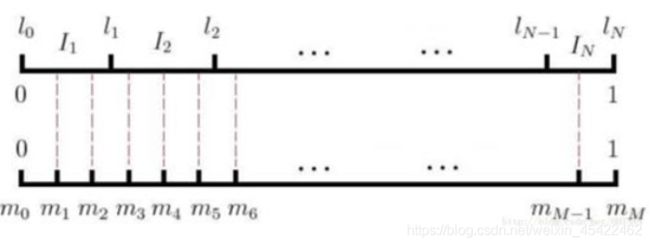
随机生成0-M的整数m,该整数落在那个单词区域内,则对应的对应的单词与固定的目标词就构成一个负样本。
02.在生成负样本构成中,由于是随机生成整数m,那么即使选中窗口内的单词,仍然认为是负样本。例如glass of orange juice to,随机选中glass,则单词对(orange-glass)仍然是负样本。
03.一般数据集越小,K值(负样本数)设置越大。
04.此时按照此方法训练模型,只需要区域训练部分参数(即K+1个),而按照传统的skip-gram模型,需要训练全部的参数(|V|个参数),从而达到简化。


2.层次softmax算法
2.1 哈夫曼树
哈夫曼树是一种带权路径长度最小的二叉树,也称为最优二叉树。
构造流程:假如有如下初始森林(其中左上角为权值,在word2vec中,权值=单词频率)

然后将权值最小的两棵树结合构成新的树,这样循环,直到只剩下一棵树为止,如下图
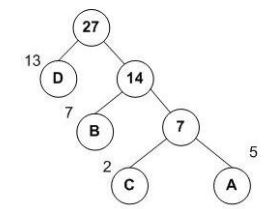
l 其中A,B,C,D为叶子结点,其余称为非叶子节点。
l 此时带权路径长度最小:WPL=131+72+53+23
l 哈夫曼树编码

A:111 C:110 B:10
D:0
2.2 层次softmax算法
首先以单词的频率为权重,构造哈夫曼树,其中每一个非叶子节点对应一个向量。假如以‘喜欢观看巴西足球世界杯’为例,
其哈夫曼树如下:
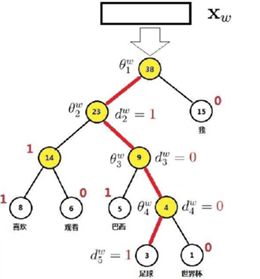
l 其中所用到的参数表达






3.DNN简述
深度神经网络(Deep Neural Networks, 以下简称DNN),有时称为多层神经网络或多层感知机(MLP)。
其结构如下图

其中每一个神经元如下图
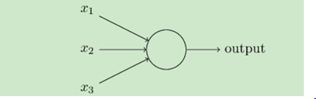
在输入和输出之间学习到一个线性关系,也就是常说的参数

然后在经过激活函数,例如tanx, softmax, ReLU, sigmoid, sign等(认为激活是为了增加其非线性【例如分类中线性无法将其分开,在进行激活,则此时线性变成非线性,可以将其更好的分开,仅此而已】和归一化作用)。求解参数利用反向传播算法(核心就是求偏导,随机梯度下降)。
4.N-gram特征



对于英文数据来说,n-gram也可以在字符级别工作,例如对单个单词matter来说,假设采用3-gram特征,那么matter可以表示成图中五个3-gram特征,这五个特征都有各自的词向量,五个特征的词向量和即为matter这个词的向其中“<”和“>”是作为边界符号被添加,来将一个单词的n-grams与单词本身区分开来:
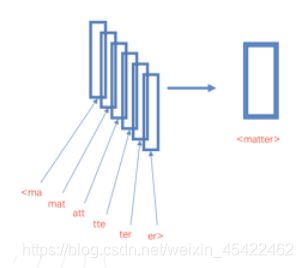
从上面来看,使用n-gram有如下优点
1、为罕见的单词生成更好的单词向量:根据上面的字符级别的n-gram来说,即是这个单词出现的次数很少,但是组成单词的字符和其他单词有共享的部分,因此这一点可以优化生成的单词向量
2、在词汇单词中,即使单词没有出现在训练语料库中,仍然可以从字符级n-gram中构造单词的词向量
3、n-gram可以让模型学习到局部单词顺序的部分信息, 如果不考虑n-gram则便是取每个单词,这样无法考虑到词序所包含的信息,即也可理解为上下文信息,因此通过n-gram的方式关联相邻的几个词,这样会让模型在训练的时候保持词序信息
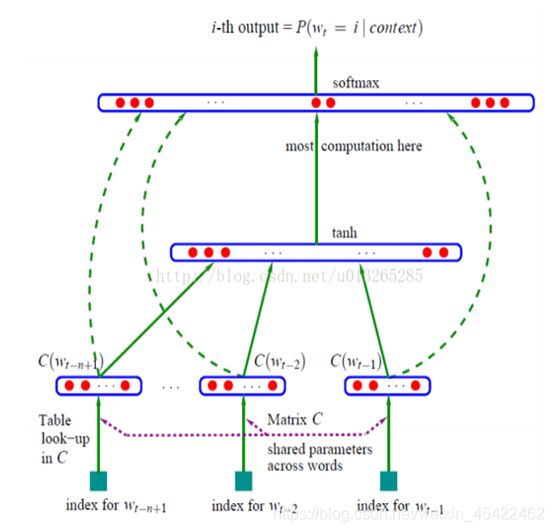
5.NLPM (NNLM)
接下来是NPLM模型,这里直接给出网络结构图:




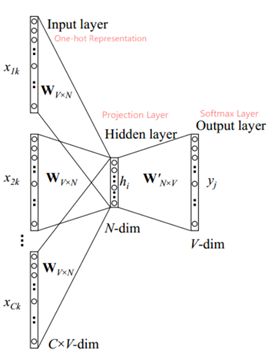
6.原始CBOW模型




7.原始skip-gram模型
原始skip-gram模型,是利用中心词去预测周围词content()。例如选定句子为:“The quick brown fox jumps over lazy dog”,设定我们的窗口大小为2(window_size=2),

则产生如上训练样本。其网络结构图如下:
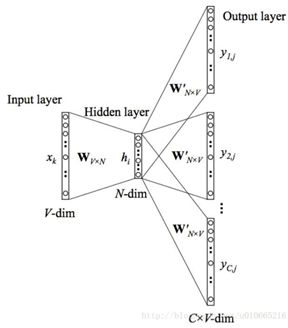



8.word2vec

采用层次softmax对其计算复杂度进行优化,与原始CBOW模型不同之处在于,将原来的输出层变为哈夫曼树。其结构图如下:

其中参数解释

模型输入:基于CBOW的语料训练样本,词向量的维度大小M,CBOW的上下文大小2c,步长η。
模型输出:霍夫曼树的内部节点模型参数θ,所有的词向量w。