【GNN框架系列】DGL第一讲:使用Deep Graph Library实现GNN进行节点分类
作者:CHEONG
公众号:AI机器学习与知识图谱
研究方向:自然语言处理与知识图谱
本文先简单概述GNN节点分类任务,然后详细介绍如何使用Deep Graph Library + Pytorch实现一个简单的两层GNN模型在Cora引文数据上实现节点分类任务。若需获取模型的完整代码,可关注公众号后回复:DGL第一讲完整代码
一、GNN节点分类概述
节点分类是图/图谱数据上常被采用的一个学习任务,既是用模型预测图中每个节点的类别。在GNN模型被提出之前,常用的模型如DeepWalk,Node2Vec等,都是借助序列属性和节点自身特性进行预测,但显然图数据不像NLP中的文本数据那样具有序列依赖性。相比之下,GNN系列模型是利用节点的邻接子图,使用子图汇聚的方式先获得节点表征,再对节点类别进行预测。例如,在2017年Kipf et al.等提出的GCN模型将图的节点分类问题看作一个半监督学习任务。即只利用图中一小部分节点,模型就可以准确预测其他节点的类别。
接下来的实验将通过构建GCN模型,在Cora数据集上进行半监督节点分类任务的训练和预测。Cora数据集是一个引文网络,其中节点是代指某篇论文,节点之间的边代表论文之间的相互引用关系。
| NumNodes | NumEdges | NumFeats | NumClasses |
|---|---|---|---|
| 2708 | 10556 | 1433 | 7 |
| Num Training Samples | Num Validation Samples | Num Test Samples |
|---|---|---|
| 140 | 500 | 1000 |
如上表格所示,Cora引文网络共包含2708个节点,10556个边,其中每个节点由1433维特征组成,每个特征代表词库中的一个Word,如果此篇论文中包含这个Word则这一维特征为1,否则这一维特征为0。在训练数据划分上,其中训练集140个样本节点,验证集500个,测试集1000个。目的是训练模型少标签半监督任务的预测能力。Cora引文网络中节点共分为七类,因此节点分类任务是个七分类问题。
二、DGL实现GNN节点分类
接下来使用DGL框架实现GNN模型进行节点分类任务,对代码进行逐行解释。
1 import dgl
2 import torch
3 import torch.nn as nn
4 import torch.nn.functional as F
首先,上述四行代码,先加载需要使用的dgl库和pytorch库;
1 import dgl.data
2 dataset = dgl.data.CoraGraphDataset()
3 print('Number of categories:', dataset.num_classes)
4 g = dataset[0]
上面第二行代码,加载dgl库提供的Cora数据对象,第四行代码,dgl库中Dataset数据集可能是包含多个图的,所以加载的dataset对象是一个list,list中的每个元素对应该数据的一个graph,但Cora数据集是由单个图组成,因此直接使用dataset[0]取出graph。
print('Node features: ', g.ndata)
print('Edge features: ', g.edata)
看上面两行代码,需要说明DGL库中一个Graph对象是使用字典形式存储了其Node Features和Edge Features,其中第一行g.ndata使用字典结构存储了节点特征信息,第二行g.edata使用字典结构存储了边特征信息。对于Cora数据集的graph来说,Node Features共包含以下五个方面:
\1. train_mask: 指示节点是否在训练集中的布尔张量
\2. val_mask: 指示节点是否在验证集中的布尔张量
\3. test_mask: 指示节点是否在测试机中的布尔张量
\4. label: 每个节点的真实类别
\5. feat: 节点自身的属性
1 from dgl.nn import GraphConv
2
3 class GCN(nn.Module):
4 def __init__(self, in_feats, h_feats, num_classes):
5 super(GCN, self).__init__()
6 self.conv1 = GraphConv(in_feats, h_feats)
7 self.conv2 = GraphConv(h_feats, num_classes)
8
9 def forward(self, g, in_feat):
10 # 这里g代表的Cora数据Graph信息,一般就是经过归一化的邻接矩阵
11 # in_feat表示的是node representation,即节点初始化特征信息
12 h = self.conv1(g, in_feat)
13 h = F.relu(h)
14 h = self.conv2(g, h)
15 return h
16
17 # 使用给定的维度创建GCN模型,其中hidden维度设定为16,输入维度和输出维度由数据集确定。
18 model = GCN(g.ndata['feat'].shape[1], 16, dataset.num_classes)
上面代码使用dgl库中的dgl.nn.GraphConv模块构建了一个两层GCN网络,每层都通过汇聚邻居节点信息来更新节点表征,每层GCN网络都便随着维度的变化,第一层维度映射(in_feats, h_feats),第二层维度映射(h_feats, num_classes),总共两层网络因此第二层直接映射到最终分类类别维度上。
这里需要强调上面代码第九行中g, in_feat两个参数,参数g代表的Cora数据Graph信息,一般就是经过归一化的邻接矩阵,如下所示,其中 A A A是邻接矩阵, I N I_N IN是单位矩阵, D D D是度矩阵:
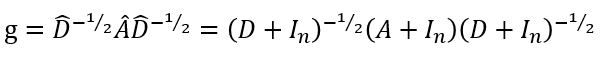
参数in_feat表示的是node representation,即节点初始化特征信息。
def train(g, model):
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
best_val_acc = 0
best_test_acc = 0
features = g.ndata['feat']
labels = g.ndata['label']
train_mask = g.ndata['train_mask']
val_mask = g.ndata['val_mask']
test_mask = g.ndata['test_mask']
for e in range(100):
# Forward
logits = model(g, features)
# Compute prediction
pred = logits.argmax(1)
# Compute loss
# Note that you should only compute the losses of the nodes in the training set.
loss = F.cross_entropy(logits[train_mask], labels[train_mask])
# Compute accuracy on training/validation/test
train_acc = (pred[train_mask] == labels[train_mask]).float().mean()
val_acc = (pred[val_mask] == labels[val_mask]).float().mean()
test_acc = (pred[test_mask] == labels[test_mask]).float().mean()
# Save the best validation accuracy and the corresponding test accuracy.
if best_val_acc < val_acc:
best_val_acc = val_acc
best_test_acc = test_acc
# Backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
if e % 5 == 0:
print('In epoch {}, loss: {:.3f}, val acc: {:.3f} (best {:.3f}), test acc: {:.3f} (best {:.3f})'.format(
e, loss, val_acc, best_val_acc, test_acc, best_test_acc))
model = GCN(g.ndata['feat'].shape[1], 16, dataset.num_classes)
train(g, model)
上面是模型的训练函数,和pytorch模型训练过程都是相似的,训练过程如下图所示:
In epoch 0, loss: 1.947, val acc: 0.070 (best 0.070), test acc: 0.064 (best 0.064)
In epoch 5, loss: 1.905, val acc: 0.428 (best 0.428), test acc: 0.426 (best 0.426)
In epoch 10, loss: 1.835, val acc: 0.608 (best 0.608), test acc: 0.646 (best 0.646)
In epoch 15, loss: 1.739, val acc: 0.590 (best 0.630), test acc: 0.623 (best 0.648)
In epoch 20, loss: 1.618, val acc: 0.644 (best 0.644), test acc: 0.670 (best 0.670)
In epoch 25, loss: 1.475, val acc: 0.698 (best 0.698), test acc: 0.737 (best 0.737)
In epoch 30, loss: 1.316, val acc: 0.720 (best 0.724), test acc: 0.731 (best 0.731)
In epoch 35, loss: 1.148, val acc: 0.726 (best 0.726), test acc: 0.728 (best 0.728)
In epoch 40, loss: 0.981, val acc: 0.742 (best 0.744), test acc: 0.754 (best 0.747)
In epoch 45, loss: 0.822, val acc: 0.750 (best 0.750), test acc: 0.764 (best 0.764)
In epoch 50, loss: 0.678, val acc: 0.764 (best 0.764), test acc: 0.766 (best 0.766)
In epoch 55, loss: 0.552, val acc: 0.770 (best 0.770), test acc: 0.766 (best 0.766)
In epoch 60, loss: 0.447, val acc: 0.774 (best 0.774), test acc: 0.764 (best 0.764)
In epoch 65, loss: 0.361, val acc: 0.778 (best 0.778), test acc: 0.772 (best 0.772)
In epoch 70, loss: 0.292, val acc: 0.782 (best 0.782), test acc: 0.771 (best 0.771)
In epoch 75, loss: 0.238, val acc: 0.778 (best 0.782), test acc: 0.775 (best 0.771)
In epoch 80, loss: 0.196, val acc: 0.776 (best 0.782), test acc: 0.778 (best 0.771)
In epoch 85, loss: 0.162, val acc: 0.774 (best 0.782), test acc: 0.778 (best 0.771)
In epoch 90, loss: 0.136, val acc: 0.774 (best 0.782), test acc: 0.777 (best 0.771)
In epoch 95, loss: 0.115, val acc: 0.770 (best 0.782), test acc: 0.776 (best 0.771)
三、往期精彩
【知识图谱系列】Over-Smoothing 2020综述
【知识图谱系列】基于生成式的知识图谱预训练模型
【知识图谱系列】基于2D卷积的知识图谱嵌入
【知识图谱系列】基于实数或复数空间的知识图谱嵌入
【知识图谱系列】自适应深度和广度图神经网络模型
【知识图谱系列】知识图谱多跳推理之强化学习
【知识图谱系列】知识图谱的神经符号逻辑推理
【知识图谱系列】动态时序知识图谱EvolveGCN
【知识图谱系列】多关系神经网络CompGCN
【机器学习系列】机器学习中的两大学派
干货 | Attention注意力机制超全综述
干货 | NLP中的十个预训练模型
FastText原理和文本分类实战,看这一篇就够了
机器学习算法篇:最大似然估计证明最小二乘法合理性
Word2vec, Fasttext, Glove, Elmo, Bert, Flair训练词向量教程+数据+源码
若需获取模型的完整代码,可关注公众号后回复:DGL第一讲完整代码,有用点个赞呀!