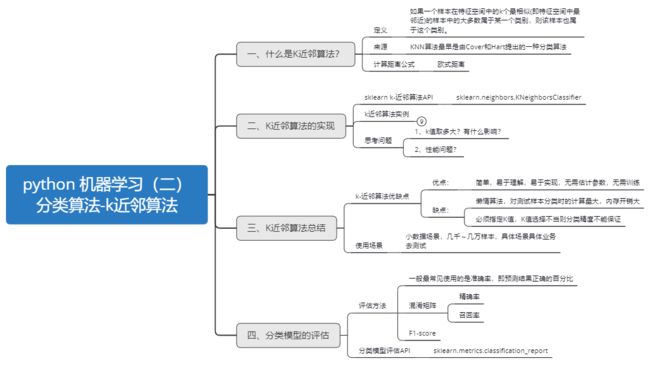
python 机器学习(二)分类算法-k近邻算法
同步更新在个人网站:http://www.wangpengcufe.com/machinelearning/pythonml-pythonml2/
一、什么是K近邻算法?
定义:
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
来源:
KNN算法最早是由Cover和Hart提出的一种分类算法.
计算距离公式:
两个样本的距离可以通过如下公式计算,又叫欧式距离。
比如说,a(a1,a2,a3),b(b1,b2,b3)
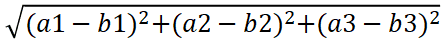
二、K近邻算法的实现
sk-learn近邻算法API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’},可选用于计算最近邻居的算法:‘ball_tree’将会使用 BallTree,‘kd_tree’将使用 KDTree。‘auto’将尝试根据传递给fit方法的值来决定最合适的算法。 (不同实现方式影响效率)
近邻算法实例
案例背景:(kaggle地址:https://www.kaggle.com/c/facebook-v-predicting-check-ins/overview)

数据下载地址:train.csv
数据格式:
row_id x y accuracy time place_id
0 0 0.7941 9.0809 54 470702 8523065625
1 1 5.9567 4.7968 13 186555 1757726713
2 2 8.3078 7.0407 74 322648 1137537235
3 3 7.3665 2.5165 65 704587 6567393236
4 4 4.0961 1.1307 31 472130 7440663949
... ... ... ... ... ... ...
29118016 29118016 6.5133 1.1435 67 399740 8671361106
29118017 29118017 5.9186 4.4134 67 125480 9077887898
29118018 29118018 2.9993 6.3680 67 737758 2838334300
29118019 29118019 4.0637 8.0061 70 764975 1007355847
29118020 29118020 7.4523 2.0871 17 102842 7028698129
[29118021 rows x 6 columns]
实现思路:
1、数据集的处理(缩小数据集范围,处理日期数据,增加分割的日期数据,删除没用的日期数据,将签到位置少于n个用户的删除)
2、分割数据集
3、对数据集进行标准化
4、estimator流程进行分类预测
具体代码如下:
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 读取数据
data = pd.read_csv("./data/FBlocation/train.csv")
# 处理数据
# 1、缩小数据,查询数据集范围
data = data.query("x > 1.0 & x < 1.25 & y > 2.5 & y < 2.75")
# 处理时间的数据
time_value = pd.to_datetime(data['time'], unit='s')
# 把日期格式转换成 字典格式
time_value = pd.DatetimeIndex(time_value)
# 构造一些特征
data['day'] = time_value.day
data['hour'] = time_value.hour
data['weekday'] = time_value.weekday
# 把时间戳特征删除
data = data.drop(['time'], axis=1)
# 把签到数量少于n个目标位置删除
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data['place_id'].isin(tf.place_id)]
# 取出数据当中的特征值和目标值
y = data['place_id']
x = data.drop(['place_id'], axis=1)
# 进行数据的分割训练集合测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 特征工程(标准化)
std = StandardScaler()
# 对测试集和训练集的特征值进行标准化
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 进行算法流程 # 超参数
knn = KNeighborsClassifier()
knn.fit(x_train, y_train)
y_predict = knn.predict(x_test)
print("预测的目标签到位置为:", y_predict)
print("预测的准确率:", knn.score(x_test, y_test))
运行结果:
预测的目标签到位置为: [8258328058 2355236719 6683426742 ... 5606572086 4932578245 9237487147]
预测的准确率: 0.3959810874704492
思考问题
1、k值取多大?有什么影响?
2、性能问题?
三、K近邻算法总结
K近邻算法优缺点
优点:
简单,易于理解,易于实现,无需估计参数,无需训练
缺点
- 懒惰算法,对测试样本分类时的计算量大,内存开销大
- 必须指定K值,K值选择不当则分类精度不能保证
使用场景
小数据场景,几千~几万样本,具体场景具体业务去测试
四、分类模型的评估
评估方法
estimator.score()
一般最常见使用的是准确率,即预测结果正确的百分比
混淆矩阵
在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵(适用于多分类)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2AAZeBHF-1581058236295)(http://wangpengcufe.com/pythonml2.4.png)]
精确率(Precision):预测结果为正例样本中真实为正例的比例(查得准)

召回率(Recall):真实为正例的样本中预测结果为正例的比例(查的全,对正样本的区分能力)

其他分类标准,F1-score,反映了模型的稳健型

分类模型评估API
评估API :
sklearn.metrics.classification_report
用法:
sklearn.metrics.classification_report(y_true, y_pred, target_names=None)
y_true:真实目标值
y_pred:估计器预测目标值
target_names:目标类别名称
return:每个类别精确率与召回率