MMOCR之DBNET文字检测
MMCV系列之MMOCR
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
今天和大家分享一下MMOCR之DBNET文字检测
论文地址:https://arxiv.org/pdf/1911.08947.pdf
代码地址:https://github.com/open-mmlab/mmocr
#博学谷IT学习技术支持#
文章目录
- MMCV系列之MMOCR
- 前言
- 一、如何使用MMCV?
- 二、DBNET模型的整体架构是什么?
- 三、模型详解
-
- 1.Backbone
- 2.Neck
- 3.Head
- 4.损失函数
- 总结
前言
MMCV系列我会一直更新的,是CV很火很实用的一套框架,非常推荐做CV模型的小伙伴实用。
今天和大家分享一下MMOCR之DBNET文字检测。
下一次是和大家分享MMOCR之文字识别。
最后是关键信息抽取。都是一个完整的系列。
先来看一下模型最终的输出效果。可以看到效果还是不错的,都框出来了。

一、如何使用MMCV?
1.首先先找到模型所在的位置
2.找到train.py,然后把之前模型所在的位置作为参数给配进去
3.运行train.py,这里虽然会报错,但是会在work_dirs里生成新的模型配置文件。
然后改个名字,再把新的配置文件地址写进train.py,就可以了
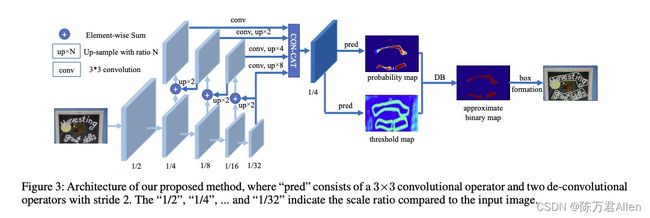
二、DBNET模型的整体架构是什么?
model = dict(
type='DBNet',
backbone=dict(
type='mmdet.ResNet',
depth=18,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=-1,
norm_cfg=dict(type='BN', requires_grad=True),
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet18'),
norm_eval=False,
style='caffe'),
neck=dict(
type='FPNC', in_channels=[64, 128, 256, 512], lateral_channels=256),
bbox_head=dict(
type='DBHead',
in_channels=256,
loss=dict(type='DBLoss', alpha=5.0, beta=10.0, bbce_loss=True),
postprocessor=dict(type='DBPostprocessor', text_repr_type='quad')),
train_cfg=None,
test_cfg=None)
在新生成的配置文件里可以看到模型的整体架构非常的简单
backbone层用的是传统的ResNet
neck层用的是类似unet网络的FPNC
只有最后的head层稍有不同
三、模型详解
1.Backbone
这里非常简单就是一个ResNet提取特征,输出4种不同大小的特征图,没有任何新意。代码省略。
2.Neck
这里也非常简单,FPNC就是用ResNet的输出,分别做上采样,和前一层的输出纬度相同,最后做相加操作即可,和以前的unet结构差不多。
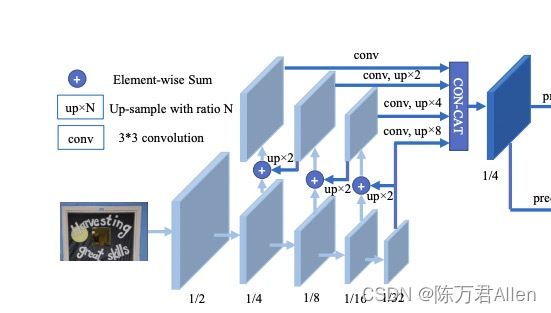
代码如下(示例):
@auto_fp16()
def forward(self, inputs):
"""
Args:
inputs (list[Tensor]): Each tensor has the shape of
:math:`(N, C_i, H_i, W_i)`. It usually expects 4 tensors
(C2-C5 features) from ResNet.
Returns:
Tensor: A tensor of shape :math:`(N, C_{out}, H_0, W_0)` where
:math:`C_{out}` is ``out_channels``.
"""
assert len(inputs) == len(self.in_channels)
# build laterals
laterals = [
lateral_conv(inputs[i])
for i, lateral_conv in enumerate(self.lateral_convs)
]
used_backbone_levels = len(laterals)
# build top-down path
for i in range(used_backbone_levels - 1, 0, -1):
prev_shape = laterals[i - 1].shape[2:]
laterals[i - 1] += F.interpolate(
laterals[i], size=prev_shape, mode='nearest')
# build outputs
# part 1: from original levels
outs = [
self.smooth_convs[i](laterals[i])
for i in range(used_backbone_levels)
]
for i, out in enumerate(outs):
outs[i] = F.interpolate(
outs[i], size=outs[0].shape[2:], mode='nearest')
out = torch.cat(outs, dim=1)
if self.conv_after_concat:
out = self.out_conv(out)
return out
最终得到tensor(16,256,160,160),其中16是batch_size,256是特征图的个数,160*160是每个特征图的大小。
3.Head
head层比较有新意,也是本文的亮点所在。
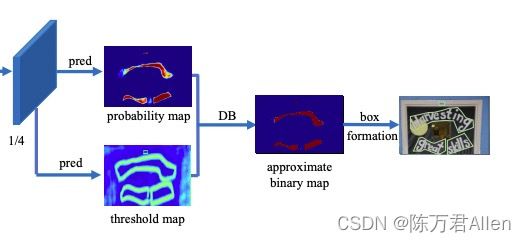
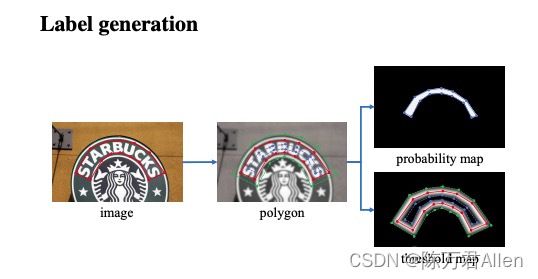
这里用了3种不同的标签,分别是概率图标签,阈值图标签,和二值图标签。
在训练的时候需要算3种损失,而在inference的时候只用概率图的最后输出即可。
也就是说阈值图标签,和二值图标签都是训练时候用,起到辅助作用。
def forward(self, inputs):
"""
Args:
inputs (Tensor): Shape (batch_size, hidden_size, h, w).
Returns:
Tensor: A tensor of the same shape as input.
"""
prob_map = self.binarize(inputs)
thr_map = self.threshold(inputs)
binary_map = self.diff_binarize(prob_map, thr_map, k=50)
outputs = torch.cat((prob_map, thr_map, binary_map), dim=1)
return outputs
概率图标签的ground_truth会比真实的标签小一圈,原因是为了更好的区分两个相连较近的检测目标。
阈值图标签是为了让模型学习的时候可以更好的学习到边框的信息。
二值图标签是用概率图标签减去阈值图标签的值,然后放到类似sigmoid函数中,其目的是为了让损失可倒。这样损失就可以传递。

4.损失函数
论文中概率图,和二值图用的都是BCE损失。而阈值图用的是L1损失,都是很普通的方法。
但是在代码中二值图用的DiceLoss,可能是为了考虑到样本不平衡的关系。
@LOSSES.register_module()
class DiceLoss(nn.Module):
def __init__(self, eps=1e-6):
super().__init__()
assert isinstance(eps, float)
self.eps = eps
def forward(self, pred, target, mask=None):
pred = pred.contiguous().view(pred.size()[0], -1)
target = target.contiguous().view(target.size()[0], -1)
if mask is not None:
mask = mask.contiguous().view(mask.size()[0], -1)
pred = pred * mask
target = target * mask
a = torch.sum(pred * target)
b = torch.sum(pred)
c = torch.sum(target)
d = (2 * a) / (b + c + self.eps)
return 1 - d
总结
今天和大家分享一下MMOCR之DBNET文字检测。DBNET文字检测是一篇非常经典的文字检测方法,主要是在head层和运用了3种不同的标签,如何标注标签相对麻烦,大家感兴趣可以看一下源码。主要是为了提升模型的效果。其实直接用概率图标签就行,但是效果肯定差一点。文章相对比较简单,容易理解。
下一次是和大家分享MMOCR之文字识别。最后是关键信息抽取,都是一个完成的系列。
