ECCV 2022 Oral | 自监督学习与量化协同互助
关注公众号,发现CV技术之美
本文转载自旷视研究院。

论文已开源,点击文末“阅读原文”可以直达GitHub
Introduction
自监督学习由于可以从未标注的数据中学习到任务无关的通用表征[10], 成为近些年深度学习领域一个研究热点。特别是一系列基于对比学习工作的出现[3, 4, 6, 7], 使得自监督预训练模型在下游任务的表现与有监督学习之间的差异日益减小, 甚至实现超越。这些下游训练的模型经常要被部署到不同资源限制的设备(e.g. 服务器, 手机, 摄像头等)。
现有的常规做法往往是根据不同的部署平台去专门训练对应的模型(包括预训练模型的重训练), 这种方法费时费力且极大地影响了产品的推广。目前也有一些工作研究在有监督信号背景下通过一次训练获得不同大小的模型去适配不同资源的部署平台[2, 8], 但在无监督范式下如何实现可自适应根据设备资源调整模型大小仍然是个未经探索的挑战。
为了可以部署到资源受限的设备上, 模型量化[1, 5, 10]是一个常用技术。模型量化旨在将模型的权重和激活从全精度表示 (i.e. float32) 转化成低精度整数表示 (e.g. int8/uint8), 从而实现模型存储和计算量的双重减少. 但如 Fig 1所示, 当直接将现有的 SOTA 方法结果进行量化操作, 会发现它们在下游任务的表现随 bitwidth 的减少下滑得十分剧烈. 基于这个观察和上述提到的自适应调配需求, 我们提出一个问题:
“Can we learn a quantization-friendly representation such that the pretrained model can be quantized more easily to facilitate deployment when transferring to different downstream tasks?”
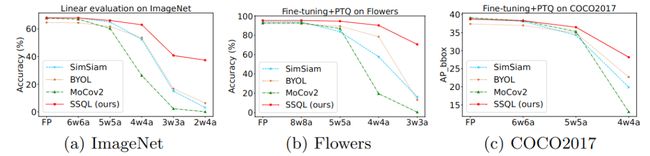
Fig 1
为解决上述提出的问题, 论文提出在自监督预训练过程中通过对比量化模型输出的表征和 float 模型输出的表征以实现为预训练模型赋予量化友好的性质, 使得在下游任务 fine-tuning 后的模型量化性能有显著提升。另外, 论文进一步观察到在大部分下游任务中, 模型的 float 结果也有不可忽视的涨点。故我们总结该现象为自监督学习与量化之间的协同互助。为进一步阐述协同互助现象, 论文也从理论角度证明这一现象的合理性。
Notice: 整个预训练过程并没有引入过多的训练开销, 仅有额外的前向量化操作, 并且我们最终保存的预训练模型的权重大小和类型仍与之前一致。
Method
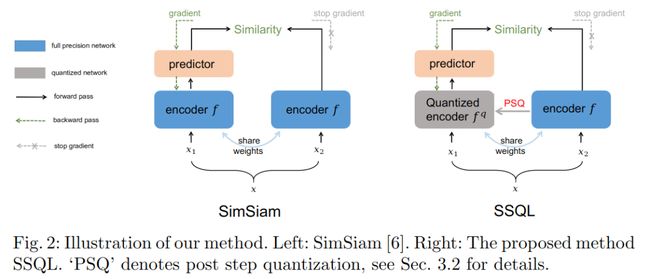
论文方法的概括图如 Fig 2 所示(不失一般性, 以 SimSiam[4] 举例, 但论文提出方法可应用于其他对比式工作)。其中, x1和 x2 来自于同一张图片 x 经过两次不同随机增广生成的两个 views. f 表示 encoder 部分, 通常由一个 backbone 和 projection MLP head 构成。h 是 predictor MLP head, 仅其中一个分支具备. 输出分别定义为 z1=f(x1) 和 p1=h(f(x1)) , x2 同理。对比学习的目标为拉近来源于同一张图片的表征距离, 疏远来源于不同图片的表征之间距离。
在 SimSiam 的基础上, 论文通过向具备 gradient 更新的分支中 encoder 引入量化操作, 使得该分支输出的结果为 zq 和 pq , 其中 q 为当前 step 指定的比特位宽。论文采用的量化操作为常见的均匀量化, 这可以根据需要进行替换。 为了获得同一预训练模型可以部署至不同资源限制的设备中(即要求模型可以被量化成不同的比特位宽且精度损失变化小), 在训练的每一次 step 会从位宽集合( e.g. w: 2~8; a: 4~16 )中挑选一个任意的位宽 q 供模型训练进行量化操作, 我们把这个操作称为 post step quantization (PSQ)。在具体训练过程中, 量化参数( i.e. scale, zero_point )会在 forward 中直接计算, 这个计算量几乎可以忽略, 在 backward 过程中, 我们通过 straight-through estimator (STE)[1]来实现量化梯度的反传, 生成的梯度会直接更新在 float weights 上面, 从而保证学习到的权重参数是量化友好的。
基于 SimSiam 中提到将其优化过程看成类 EM 算法, 可以把 SSQL 的优化过程也可以类比进行分析。SSQL 的损失函数如下式 11 所示, 对该公式进行进一步展开, 可以得到式 12~式 15。从式 14和式 15中, 我们可能看到 SSQL 的优化目标可以看成三项优化目标之和, 分别是: 量化项, 对比学习项, 交叉项. 其中, 基于量化噪声的随机性可以合理假定量化噪声与对比损失之间相关性很低(即内积值为0 ), 我们也从实验验证了该假设。
所以, SSQL 的优化过程可以认为是由量化项和对比学习项构成, 即一个实验同时满足量化部署和自监督学习两个学习目标, 即理论佐证 SSQL 实现自监督学习与量化协同互助。

Experiments
为了证明 SSQL 的有效性, 论文做了详尽的实验, 包括: 不同的评测方法( linear evaluation, fine-tuning ), 不同的量化范式( PTQ[10]/QAT[5] ), 不同的下游任务(分类, 检测), 详细的消融实验和直观的定性实验。限制于篇幅, 下面只列举有代表性的实验结果, 更详细的实验内容可以阅读论文获得。
Table 3 显示在 ImagNet-1k 的 linear evaluation 结果, 可以看出:
a. 相较于直接对 SOTA 算法的预训练模型进行量化, SSQL 在不同比特配置的结果均得到显著提升;
b. SimSiam-PACT[5] 是采用 QAT 的方法训练得到的 strong baseline, 因为针对每个不同的比特配置都需要进行单独训练, 不同于 SSQL 一次训练可量化至不同比特配置下的特性。即使如此, SSQL 仍然体现出了明显的优势, 在比特位宽>3 的所有情况。
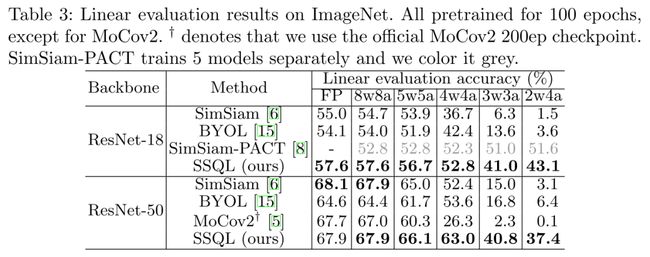
Table 5 记录由ImageNet数据集预训练得到的自监督模型在迁移到下游任务时的表现, 可以看出:
a. SSQL 在多数下游任务上, 进一步提升模型收敛结果;
b. 在不同的比特配置下, SSQL 均以显著的优势超过 SimSiam[4] 的量化结果。

Table 6表明 SSQL 预训练模型在迁移至下游检测任务上的表现, 可以看出:
在不同比特配置 SSQL 得到的下游模型 mAP 值均高于其他对比项结果, 且随着比特位宽降低, 优势进一步拉大。
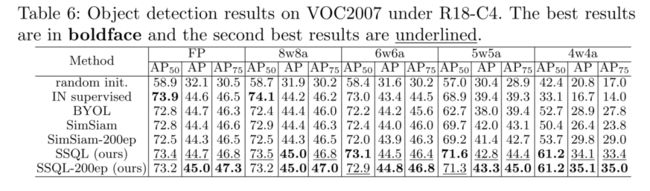
Fig 5 显示不同算法训练得到的 Resnet18 模型对应的个别层权重分布, 横轴为权重大小, 纵轴为元素个数,可以看出:
经过 SSQL 训练得到的权重分布范围更小(与其他两者有数量级差异, 详情可查论文), 权重分布具备更少的 outliers, 更加 uniform,即 SSQL 产出的模型权重被量化后的量化误差要远小于另外两者。

Conclusion
在论文中, 我们探索解决为预训练模型赋予部署友好性质的问题, 并取得明显的进展。具体地, 我们提出 SSQL 训练得到量化友好的预训练模型, 使得预训练模型可以根据下游任务的设备约束进行模型大小和计算量调节, 从而实现部署友好。为证明 SSQL 的有效性, 论文提供了理论公式和详尽的实验。该量化友好的预训练模型, 可以兼容 PTQ 和 QAT 两种量化范式。SSQL 相对于之前的对比学习, 仅有极小的计算开销的引入, 同时最终保存的模型大小与此前方法一致, 但该模型的权重可以适配不同比特配置的量化。
参考文献
[1] Bengio, Y., L´eonard, N., Courville, A.: Estimating or propagating gradi- ents through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432 (2013)
[2] Cai, H., Gan, C., Wang, T., Zhang, Z., and Han, S.: . Once-for-all: Train one network and specialize it for efficient deployment. In The International Conference on Learning Representations, 1–14. (2020)
[3] Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for con- trastive learning of visual representations. In: The International Conference on Machine Learning. pp. 1597–1607 (2020)
[4] Chen, X., He, K.: Exploring simple siamese representation learning. In: The IEEE Conference on Computer Vision and Pattern Recognition. pp. 15750–15758 (2021)
[5] Choi, J., Wang, Z., Venkataramani, S., Chuang, P.I.J., Srinivasan, V., Gopalakr- ishnan, K.: Pact: Parameterized clipping activation for quantized neural networks. In: The International Conference on Learning Representations. pp. 1–12 (2018)
[6] Grill, J.B., Strub, F., Altche, F., Tallec, C., H.Richemond, P., Buchatskaya, E., Do- ersch, C., Pires, B.A., Guo, Z.D., Azar, M.G., Piot, B., Kavukcuoglu, K., Munos, R., Valko, M.: Boostrap your own latent: A new approach to self-supervised learn- ing. In: Advances in neural information processing systems. pp. 21271–21284 (2020)
[7] He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. In: The IEEE Conference on Computer Vision and Pattern Recognition. pp. 9729–9738 (2020)
[8] Jin, Q., Yang, L., Liao, Z.: Adabits: Neural network quantization with adaptive bit- widths. In: The IEEE Conference on Computer Vision and Pattern Recognition. pp. 2146–2156 (2020)
[9] Liu, X., Zhang, F., Hou, Z., Wang, Z., Mian, L., Zhang, J., Tang, J.: Self-supervised learning: Generative or contrastive. arXiv preprint arXiv:2006.08218 (2020)
[10] Nagel, M., Amjad, R.A., van Baalen, M., Louizos, C., Blankevoort, T.: Up or down? adaptive rounding for post-training quantization. In: The International Conference on Machine Learning. pp. 7197–7206 (2020)

END
加入「计算机视觉」交流群备注:CV
