机器学习系列|基于随机森林的生存分析模型-R实战
机器学习系列|基于随机森林的生存分析模型-R实战

随机生存森林
随机生存森林通过训练大量生存树,以表决的形式,从个体树之中加权选举出最终的预测结果。
构建随机生存森林的一般流程为:
Ⅰ. 模型通过“自助法”(Bootstrap)将原始数据以有放回的形式随机抽取样本,建立样本子集,并将每个样本中37%的数据作为袋外数据(Out-of-Bag Data)排除在外;
Ⅱ. 对每一个样本随机选择特征构建其对应的生存树;
Ⅲ. 利用Nelson-Aalen法估计随机生存森林模型的总累积风险;
Ⅳ. 使用袋外数据计算模型准确度。
案 例
以美国梅奥诊所在1974—1984年间收集的原发性胆汁性胆管炎(primarybiliarycholangitis,PBC)数据为例,通过构建随机生存森林模型来探究D-青霉胺(DPCA)治疗对于原发性胆汁性胆管炎生存的影响。同时,也探讨其他主要临床指标是否也对PBC的生存有影响。原始数据共有总计418例患有PBC的研究对象,其中时间(time)的单位为生存天数,在此换算为生存年数。由于只考虑单次复发的情况,原始数据“status”变量中的事件重新分组为“0”(删失)和“1”(事件)。
随机生存森林的构建:
通过“randomForestSRC”包中的rfsrc函数构建随机生存森林模型。
#建立随机生存森林模型rfsrc_pbcmy <- rfsrc(Surv(days, status) ~ ., data = data_train, nsplit = 10, na.action = "na.impute", tree.err = TRUE, importance = TRUE)
结果如下,包括模型的一些默认参数设置等信息:
| 变量 | 输出值 |
|---|---|
| Sample size | 312 |
| Number of deaths | 121 |
| Was data imputed | yes |
| Numberoftrees | 1000 |
| Forest terminal node size | 15 |
| Average no. of terminal nodes | 15.779 |
| No. of variables tried at each split | 5 |
| Total no. of variables | 17 |
| Resampling used to grow trees | swor |
| Resample size used to grow trees | 197 |
| Analysis | RSF |
| Family | surv |
| Splitting rule | logrankrandom |
| Number of random split points | 10 |
| Error rate | 19.85% |
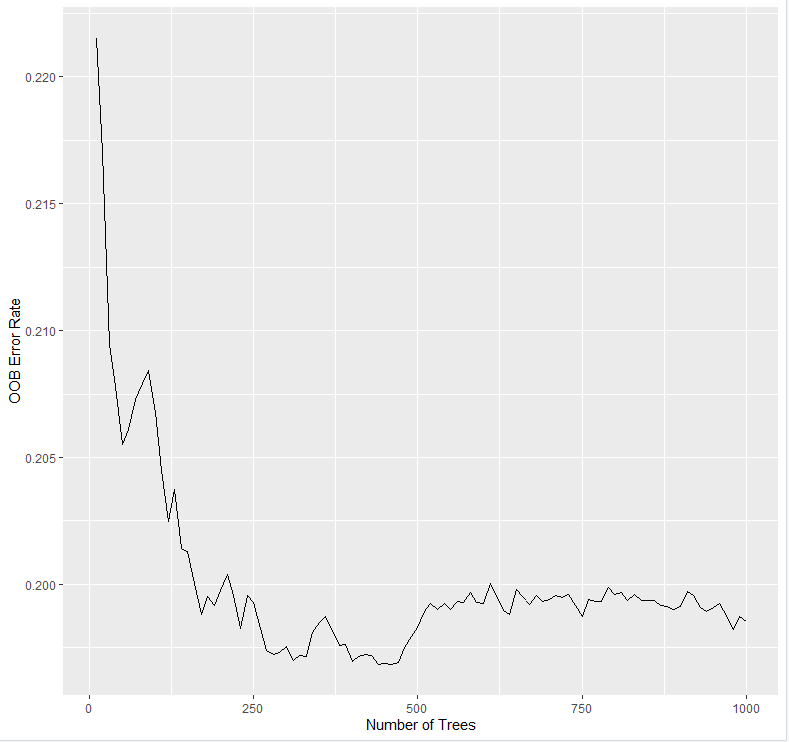
随机生存森林使用了Harrell的一致性指数(concordance index)来计算其准确度。从上表可以看出模型的C-index约为1-Error rate = 1-19.85% = 0.8。模型默认生成了1000个二元生存树,从下图可以看出当生存树增加到一定数量后,错误率(Error rate)曲线趋于平稳(19.85%),说明树的棵数是合适的。
#袋外数据错误率与生存树数量关系的可视化rfsrc_error <- gg_error(rfsrc_pbcmy)rfsrc_error <- na.omit(rfsrc_error)plot(rfsrc_error)
变量筛选和结论
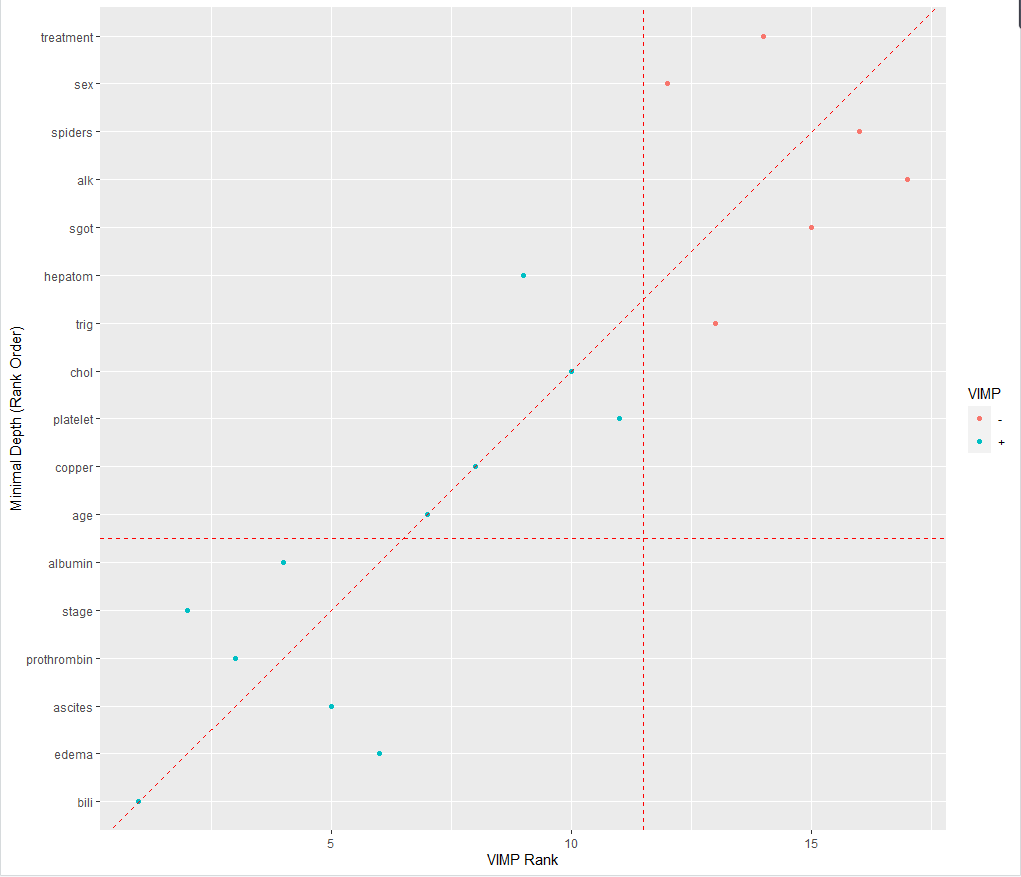
随机生存森林可以对变量重要性进行排名,VIMP法和最小深度法是最常用的方法:变量VIMP值小于0说明该变量降低了预测的准确性,而当VIMP值大于0则说明该变量提高了预测的准确性;最小深度法通过计算运行到最终节点时的最小深度来给出各变量对于结局事件的重要性。
下图为综合两种方法的散点图,其中,蓝色点代表VIMP值大于0,红色则代表VIMP值小于0;在红色对角虚线上的点代表两种方法对该变量的排名相同,高于对角虚线的点代表其VIMP排名更高,低于对角虚线的点则代表其最小深度排名更高。
**相较于Cox比例风险回归模型等传统生存分析方法,随机生存森林模型的预测准确度至少等同或优于传统生存分析方法。**随机生存森林模型的优势体现在它不受比例风险假定、对数线性假定等条件的约束。同时,随机生存森林具备一般随机森林的优点,能够通过两个随机采样的过程来防止其算法的过度拟合问题。除此之外,随机生存森林还能够对高维数据进行生存分析和变量筛选,也能够应用于对竞争风险(competing risk)的分析。因而,随机生存森林模型有着更为广泛的研究空间。
**但是随机生存森林也存在缺陷:易受离群值的影响。**分析中有离群值数据时,预测准确度会稍劣于传统生存分析方法。Cox比例风险回归模型对于生存数据的分析不仅仅用于预测,还可以较为便捷地给出各变量与生存结局的关系,所以随机生存森林模型应该和传统生存分析相结合应用,并不能完全替代传统生存分析模型。
参考文献:
[1]陈哲,许恒敏,李哲轩,等.随机生存森林:基于机器学习算法的生存分析模型[J].中华预防医学杂志,2021,55(01):104-109.
[2]KayR.Goodnessoffitmethodsfortheproportionalhazardsregressionmodel:areview[J].RevEpidemiolSantePublique,1984,32(3-4):185-198.IshwaranH,KogalurUB,BlackstoneEH,etal.Randomsurvivalforests[J].AnnApplStat,2008,2(3):841-860.DOI:10.1214/08-aoas169.
[3]ZhouY,McArdleJJ.RationaleandApplicationsofSurvivalTreeandSurvivalEnsembleMethods[J].Psychometrika,2015,80(3):811-833.DOI:10.1007/s11336-014-9413-1.
[4]CuzickJ.Countingprocessesandsurvivalanalysis.ThomasR.FlemingandDavidP.Harrington,Wiley,NewYork,1991[J].StatisticsinMedicine,1992,11(13):1792-1793.DOI:10.1002/sim.478011131