关于YOLO2的学习
https://www.bilibili.com/video/BV1Q64y1s74K?from=search&seid=14147522030581958530&spm_id_from=333.337.0.0https://www.bilibili.com/video/BV1Q64y1s74K?from=search&seid=14147522030581958530&spm_id_from=333.337.0.0 https://www.bilibili.com/video/BV1Q64y1s74K?from=search&seid=14147522030581958530&spm_id_from=333.337.0.0
https://www.bilibili.com/video/BV1Q64y1s74K?from=search&seid=14147522030581958530&spm_id_from=333.337.0.0
 经过一年半的时间,到2016年年末,yolo2出世。其目的旨在解决yolo1存在的几个问题:
经过一年半的时间,到2016年年末,yolo2出世。其目的旨在解决yolo1存在的几个问题:
1.mAP比不上两阶段的目标检测算法
2.定位性能比较差。对于高IoU指标,其效果明显低于RCNN
3.recall比较低,即将全部目标全部检出的能力相对较弱
4.因为检测框数量上的限制,对于小目标和密集目标的检测能力比较弱

yolo2采取一系列措施来解决yolo1存在的缺陷:
1.批归一化
2.更高分辨率的分类器
3.通过聚类实现的anchor机制
4.维度聚类(没看懂)
5.直接定位预测(也没看懂)
6.细粒度的特征。做细分,对数据集的要求更高了
7.多尺度融合训练
我认为相当重要得就是这个anchor机制,在我们自己进行VOC数据集上的yolo模型的训练时,出现了不符合anchor固定宽高比得结果,生成的检测框总是会在某一个方向上和原图像的框一致,这是个非常奇怪的bug

这里提到了BN层,那趁此机会提出一些之前就感到疑惑的问题
1.当存在batchsize的时候,我们知道是训练了batchsize个样本之后,模型迭代一次。那么神经元到底需要输出多少个值呢??
从上面这张图的说法来看,对于每个输入的样本,全连接层的每个神经元都会有一个输出值,这个值需要保存下来。最终,全连接层的每个神经元都会有batchsize个输出值。包括说输出层的每个神经元也有batchsize个输出值。这些值在一轮迭代中全部都要保存下来,这也是估算内存占用的依据。
2.接着问题一,那么卷积网络部分feature map是不是也要做批归一化呢??
在全连接层做批归一化的目的是将神经元的输出值处理到激活函数梯度敏感的区间,最终是为了更好的收敛loss.feature map并不需要这样的操作,卷积网络的目的是提取有足够强的表征能力的卷积特征。因此我认为feature map是不需要的

这张图也就佐证了我在上面的判断
BN、dropout、激活函数都只是针对神经元输出的一个操作而已,但操作也是有先后顺序的
这里引出一个问题:BN层和dropout层为什么不能协同工作,反而会降低模型的性能??
那么批归一化就要将每个神经元的batchsize个输出值进行处理,处理成一个值。这样处理之后会使全连接层的每个神经元的输出值都在0附近,这是sigmoid的梯度敏感区。处理完成之后,就可以完成误差的反向传播,即一次迭代。
3.说到sigmoid激活函数的梯度敏感区,那么对于像relu这样的非饱和激活函数,是否还需要做BN操作??
在回答这个问题之前,我认为应该先回答我们为什么要做batchsize这样的划分,为什么要经过batchsize个样本才进行一次迭代。
BN的出现其实是针对Alexnet提出的LRN,局部响应归一化,出自《BN inception》这篇论文。batchsize就来自于BN的batch.γ用于缩放,β用于平移。对于relu,毫无疑问缩放对他没什么作用,因为他是分段线性函数。但是平移的作用是明显的,因为他分段。
BN层增加了两个超参数,γ和β,他们与其他超参数一样需要进行初始化,有可能不是统一初始化,迭代估计是和其他参数的迭代一样的。

这张图就很清晰地呈现了BN层的效果是什么

对于双峰分布这种原数据,BN层至少可以让原数据向0的方向聚拢

4.BN层有什么作用??
产生作用得核心都来自于他将神经元的输出限定在了激活函数梯度敏感得区域。一方面,可以提升学习率,进而提高训练速度。另一方面,整体上提高了分类得准确率。因为在最大程度上保留了原始数据的分布特征。
high resolution classfier-高分辨率分类器
相较于YOLO1,YOLO2解决了从小分辨率图像向大分辨率图像的平滑过渡问题。

他放弃了在小分辨率图像上进行分类预训练的操作,而是直接在448*448的大分辨率图像上进行预训练
具体的训练过程:在224*224图像上训练少量的epoch,再在448*448图像上训练10个epoch,最后在检测数据集上进行fine tune
anchor机制,dimension cluster, direct location prediction-维度聚类,直接定位预测
anchor机制是咱们的老朋友了,应该说知道yolo5都仍然在使用anchor机制。但是后面的很多目标检测算法都是anchor free的。

YOLO2增加了grid cell和先验框的数量,grid cell变成了13*13,每个grid cell都包含了5个先验框
我现在对anchor有个疑问,虽然我已有判断:anchor机制固定的是预测框的大小还是宽高比,还是其他情况??
当然,我倾向于不可能固定预测框的大小,非如此,在自由度上竟下降了

这张预测的图片不就佐证了我上面的判断吗,anchor机制肯定没有固定预测框的大小
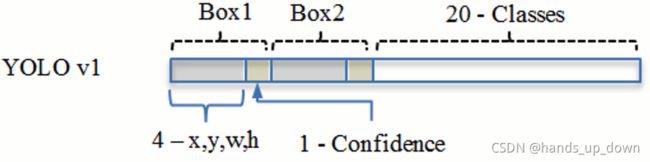
yolo1每一个gridcell有两个bbox,其输出如上
到了yolo2,每个gridcell有5个anchor

输出的主体结构还是一样的,像YOLO1 FC最终输出的是一个7*7*30 = 1470维的向量
那么yolo2 FC最终输出的就是13*13*25*5 = 21125维的向量
不同于faster RCNN以及SSD这样的手工选择先验框宽高比的方案,yolo2使用聚类方法分析数据集得到anchor


这里可以看到不同方案的anchor在性能上的差别,如果有9个anchor,按照yolo2的方案,那么就应该产生1521个先验框,这已经快赶上RCNN了
但即便如此,YOLO的性能肯定也是远远高于RCNN的,毕竟是一阶段模型
和yolo1一样,yolo2在收敛先验框位置的早期,仍然会出现属于某个grid cell的预测框远离所属grid cell的情况,但不同的是,yolo2的anchor是不需要将中心点限定在grid cell中的

yolo2为了避免这个情况,对预测框相对anchor的偏移量做了限制

1.首先是将grid cell的尺寸归一化,变成1*1。本来每个grid cell的大小是32*32。那么上图中anchor中心点所在的grid cell的坐标就应该是(1,1)
2.预测框中心位置相对于anchor中心位置的偏移量做一个sigmoid处理,sigmoid函数会将这个偏移量限制在0,1之间
3.从这个公式也能看出来,anchor机制没有对grid cell的宽高做限制。预测框的宽高比和anchor的宽高比服从exp的关系,并不是固定的

接下来就是重中之重,yolo2的loss function








fine grained features -细粒度特征

细粒度特征体现在两个操作上:
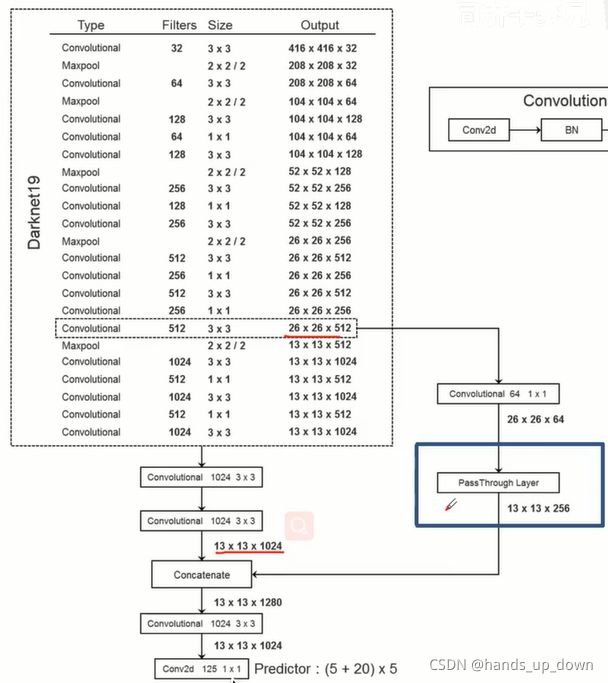
1.对于倒数第二个卷积操作得到的feature map,一方面让他去正常的池化-卷积-池化,另一方面将这个feature map拆分成4个小的feature map, 然后保持不变
2.将上述步骤生成的两个特征进行叠加
这样一来,一组特征却来自与两个不同的阶段,这有助于小目标的识别
这个拆分的passthrough是如何操作的??


在yolo2具体的代码结构中,是这样操作的


这个结构图当中的每个convolutional都包含有3个操作,卷积,BN,激活
也不是之前我判断的那种操作顺序,不是从倒数第二个卷积生成的feature map开始算起,这之后还进行了多次卷积操作
但是从26*26*512变成4*13*13*512这个过程着实没有看懂????

multi scale trainning:多尺度训练
在这里,尺度特指图像的尺寸,MST表示模型允许输入不同尺寸的图像,同时还不需要修改模型
要理解这一点,必须先问,为什么之前的模型不允许输入不同尺度的图像???
卷积池化是不要求输入图像的尺寸的,但是卷积网络最终的输出的尺寸是和输入相关的。如果网络包含FC层的话,FC层输入层的特征是固定的,如果卷积网络输出的尺寸变了,那么就会出现和FC层不匹配的问题。
因此,总结下来是包含FC层的卷积网络模型不允许输入不同尺度的图像。像Alexnet, yolo1,RCNN都是这样的结构
那么yolo2通过什么措施改变了这一点??
yolo2在最后使用了全局平均池化层,global average pooling用以调整卷积网络的输出的尺寸
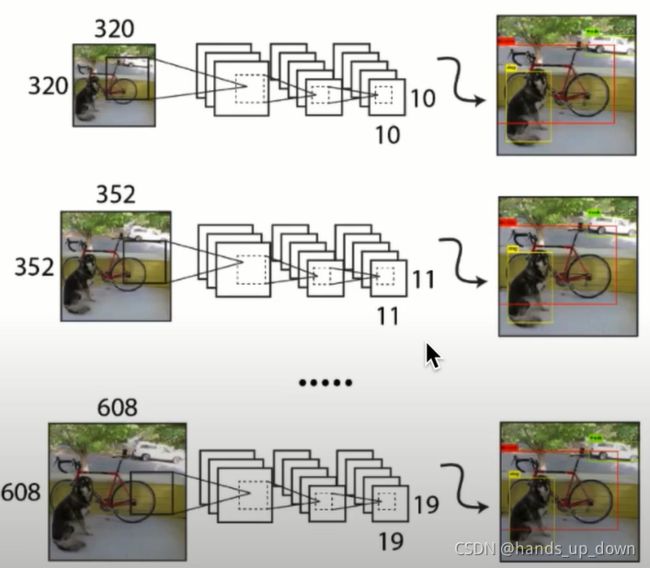
从上图可以看出,训练的不同阶段使用了多尺度的图像。最终在mAP上获得了1.5的提升
 这张图也是挺经典的,以30帧为界限,yolo确实能打,中科院提出的SSD也不赖嘛
这张图也是挺经典的,以30帧为界限,yolo确实能打,中科院提出的SSD也不赖嘛
 不同尺度数据下yolo2的性能,至少从上图来看,性能和尺度是正相关的
不同尺度数据下yolo2的性能,至少从上图来看,性能和尺度是正相关的
 这张图可以看到,通过对yolo1逐步增加trick,其性能是在逐步提升的
这张图可以看到,通过对yolo1逐步增加trick,其性能是在逐步提升的
加了anchor之后,map反而下降了,但是recall获得了巨大的提升,recall升了,自然precision就会下降。在预测后处理的时候,会有对应的措施减小precision降低带来的影响

这张图是对采用不同骨干网络的模型的速度的评估
较之yolo1的darknet8,yolo2的darknet19在浮点运算量上减少了34%
什么是骨干网络,backbone???
【深度学习】CNN 的骨干网络 backbone_小苏打的学习博客-CSDN博客_cnn骨干网络
CNN Backbone往往是各种CNN模型的一个共享结构,这是属性
常用的backbone包括AlexNet、VGG、GoogleNet、Residual Network、DenseNet
RCNN就是将alexnet作为她的骨干网络
这个共享结构除了结构性的超参(总深度、总宽度)以外,反复使用了多种技巧,其中包括:
- Residual(残差): 直接elementwise加法。
- Concat(特征拼接): 直接对特征深度作拼接。
- Bottleneck(特征压缩): 通过Conv(1,1)对稀疏的或者臃肿的特征进行压缩
- Grouping(分组): fc-softmax分类器从1个观察点把不同类靠空间球心角分离开,不同类放射状散开不符合高斯假设。分组改善了这一点。
- Fractal(分形模式): 结构复用,可能带来好处
- High-Order(高阶): 在非分组时,可能带来好处
- Asymmetric(非对称): Conv(1,3),Conv(1,5),Conv(1,7)属于非对称结构,这个技巧在OCR处理长宽非1:1的字体有用

这里将某些卷积层定义为bottleneck,什么是bottleneck???
深度学习之Bottleneck Layer or Bottleneck Features_mjiansun的专栏-CSDN博客_bottleneck
就是通过1*1的卷积来大幅度改变通道数的操作,在残差网络中就是为了能减少训练参数,能加深网络层数
1*1卷积之前就已经遇到过,当时是说什么可以用来降维还是什么
还有什么bottleneck layer, bottleneck features, bottleneck block这样的说法,意思就是输入输出维度差距较大,就像一个瓶颈一样,上窄下宽亦或上宽下窄
有篇文章是这样描述bottleneck block, In order to reduce the number of weights, 1x1 filters are applied as a "bottleneck" to reduce the number of channels for each filter",在这句话中,1x1 filters 最初的出处即"Network In Network",1x1 filters 可以起到一个改变输出维数(channels)的作用(elevation or dimensionality reduction)
子豪兄说上一张图是分类的网络结构,这一张是分类加定位的网络结构,我突然就想到之前说过的在分类数据集上做预训练,然后在目标检测数据集上做fine tune.那从这两张网络结构来看,是不是就意味着这两种训练虽然主体网络结构是一样的,但是还是需要修改以适应不同的任务。
比如可以看到,同一层在不同的任务下输出的feature map的尺寸是不同的。又比如说,全局平均池化只出现在分类任务的网络结构中
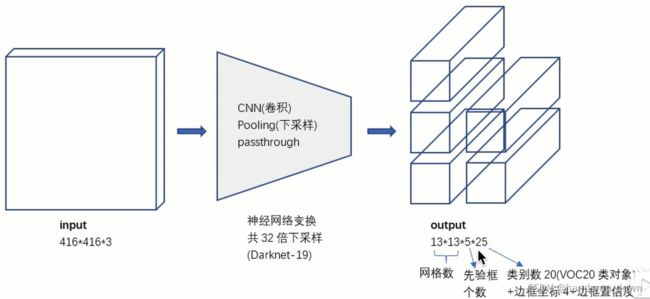
这里只提了416*416的输入,关于多尺度训练在什么时候可以使用。因为他需要全局平均池化,而全局平均池化只存在于分类的网络中,那是不是表示多尺度训练也仅仅存在于分类预训练中
YOLO2的健壮性
之前yolo2还出了一个yolo9000,号称可以检测9000个类别的物体。yolo2是否能做如此细粒度的检测任务呢??
像imagenet数据集

VOC, imagenet这样的数据集是不能直接组合的。一般使用的softmax假定了这些类别是互斥的
按照我之前的想法,要做更多的分类,一方面增加网络规模以学习更多的特征,另一方面增加FC层的输出层的神经元个数,和要进行分类的分类数保持一致
但文章告诉我们这样行不通,当分类数增加,需要对类别进行结构化
 比如说COCO数据集,纯粹扁平化的,80个类
比如说COCO数据集,纯粹扁平化的,80个类
 imagenet包含有22000个类,但仍然采用的是扁平化的结构
imagenet包含有22000个类,但仍然采用的是扁平化的结构

yolo2将两个数据集进行了合并,并且将合并之后的数据集进行了结构化
至于说为什么这样做,好像是出于softmax的需要,不太懂这个道理???


这个地方又提到当检测到数据的目标检测标签的时候,反向传播用的是目标检测误差
但检测到数据是分类标签的时候,反向传播用的是分类误差
这意味着什么??不可能说一个用于目标检测的模型还可以只输出分类的预测结果吧,一直以来也没听说过这回事啊?
类似的分类任务和检测任务的分离只在预训练和fine tune 的时候出现过,当模型训练好了之后,它只能用于目标检测任务,最终的输出肯定也是包含分类和定位。