我的2022和2023(技术总结、开发工具简介和未来展望)
文章目录
- 前言
- 1. 常用网址的总结
- 2. 技术总结
-
- 2.1 网络方面的总结
-
- 2.1.1 Segmentation:Unet++
- 2.1.2 Segmentation:SegFormer
- 2.1.3 Segmentation:HRNetV2_OCR
- 2.1.4 Segmentation: HorNet
- 2.1.5 Detection: CenterNet
- 2.1.6 Detection: YoloV5
- 2.2 MMCV框架
- 2.3 Onnx部署以及MMDeploy框架的使用
- 2.4 Opencv总结
- 2.5 C++的学习总结
- 2.6 CUDA的学习总结
- 2.7 其他学习总结
- 3. 开发工具简介
-
- 3.1 PyCharm
-
- 3.1.1 调试方法分享
- 3.1.2 远程服务器操作流程
- 3.1.3 远程Github操作流程
- 3.2 Termius
- 3.3 FileZilla
- 3.4 NotePad++
- 3.5 screen
- 4. 个人总结
-
- 4.1 技术总结
- 4.2 工作总结
- 5. 未来规划
- 最后,提前祝大家新年快乐!
前言
写在前面:
2022年是我自2021年毕业以后工作的第一年。这一年个人觉得在技术方面的进步不是很大,但是勉强比刚毕业的我强了一些。例如:刚毕业的我只会人脸分类,但在工作后我接触到目标检测和语义分割这两个新领域,并学会了一些对应领域的网络模型,更是学习了一些模型部署的方法(onnx和docker)。在数据方面也学会了如何筛选、清洗和标注图像。
但是仍然感觉自己进步的太慢,因此从2022年5月份自己开始写博客,通过这种方式不断的逼自己进行学习总结。2022年这半年时间我共写了12篇文章,文章涉及网络模型,深度学习技巧和python技巧。我对这半年的博客工作感到相对满意,明年还会继续撰写新内容,并且由于个人基础知识薄弱,我会更加关注深度学习基础知识方面的学习总结。
新的一年,新的开端。通过这篇文章的编写,我将总结2022年学习到的新技术,并且分享在工作中常用的开发工具,然后在技术方面和工作方面进行全面总结,最后分析下明年的学习方向。
本篇文章的内容如下,具体内容可通过目录进行跳转:
1.常用网址的总结
2.技术总结
2.1 网络方面的总结
2.1.1 Segmentation:Unet++
2.1.2 Segmentation:SegFormer
2.1.3 Segmentation:HRNetV2_OCR
2.1.4 Segmentation: HorNet
2.1.5 Detection: CenterNet
2.1.6 Detection: YoloV5
2.2 MMCV框架
2.3 Onnx部署以及MMDeploy框架的使用
2.4 Opencv总结
2.5 C++的学习总结
2.6 CUDA的学习总结
2.7 其他学习总结
3.开发工具简介
3.1 PyCharm
3.1.1 调试方法分享
3.1.2 远程服务器操作流程
3.1.3 远程Github操作流程
3.2 Termius
3.3 FileZilla
3.4 NotePad++
3.5 screen
4.个人总结
4.1 技术总结
4.2 工作总结
5.未来规划
1. 常用网址的总结
在我工作当中有一些网址会经常性的使用。每次都得重新寻找特别麻烦,因此通过这次机会,我将这些网址进行总结,方便后续直接使用。
-
下载包的网址(有些可通过修改网址进行选择性查找)
- pypi检索(python package index):https://pypi.org/
- torch(whl文件):https://download.pytorch.org/whl/torch_stable.html
- torchvision(whl文件):https://download.pytorch.org/whl/torchvision/
- torchaudio(whl文件):https://download.pytorch.org/whl/torchaudio/
- matplotlib(whl文件):https://mirrors.aliyun.com/pypi/simple/matplotlib/
- opencv-python(whl文件):https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple/opencv-python/
- scipy(whl文件):https://mirrors.aliyun.com/pypi/simple/scipy/
- window下的非官方python扩展包下载(Archived: Unofficial Windows Binaries for Python Extension Packages):https://www.lfd.uci.edu/~gohlke/pythonlibs/
- MMCV(可修改网址来找到指定版本):https://download.openmmlab.com/mmcv/dist/cpu/torch1.10.0/index.html
- opencv 4.x 官方文档:https://docs.opencv.org/4.x/
- GDAL的whl文件:https://sourceforge.net/projects/gdal-wheels-for-linux/files/
-
Nvidia相关
- Nvidia驱动:https://www.nvidia.com/download/index.aspx?lang=en-us
- CUDA(需要登陆才能下):https://developer.nvidia.com/cuda-toolkit-archive
- cudnn(需要登陆才能下):https://developer.nvidia.com/cudnn
-
清华园镜像官网:https://mirrors.tuna.tsinghua.edu.cn/help/pypi/
-
查看最新的网络:https://paperswithcode.com/sota
2. 技术总结
2.1 网络方面的总结
在这一年多的时间里,跑了很多网络模型,但是经过细致学习的网络模型只有6个,其中4个是语义分割网络模型,2个是目标检测网络模型。在这6个网络模型中,总结成博客的有3篇,分别是SegFomer,HRNetV2_OCR和HorNet。这6个网络模型的总结如下面章节所示。
2.1.1 Segmentation:Unet++
Unet++,提出在 2018年的会议DLMIA上,作者周纵苇,文章链接:UNet++: A Nested U-Net Architecture for Medical Image Segmentation
这是我在语义分割任务中学习的第一个网络模型。值得庆幸的是,这个网络模型有作者亲自书写的博客来解读,里面有作者从UNet网络如何一步一步的设计成UNet++网络的全部思考过程。强烈推荐有兴趣的读者朋友进行阅读,作者博客链接:
- 研习U-Net:https://zhuanlan.zhihu.com/p/44958351。
本章节我就简单介绍下作者的创建该网络的思路:
作者是通过提出一个个问题来逐步设计出UNet++网络,其中第一个问题是:
UNet网络中的4次下采样是不是最优的网络层数?
作者通过使用不同数据集来对不同下采样层的UNet进行测试,可以得出结论,UNet的下采样层数并不是4层是最优的,而是根据数据集的不同而不同。实验见下图
(图片节选自作者的知乎解读:研习U-Net :https://zhuanlan.zhihu.com/p/44958351,后面的图片同理)

下采样层其实就是一个特征提取器,浅层特征提取器可以捕获图像的一些简单的特征,比如边界,颜色,而深层结构因为感受野大了,而且经过的卷积操作多了,能抓取到图像的一些抽象的深度特征,其中浅层特征有浅层的侧重,深层特征有深层的侧重。由于在一些数据集中对于浅层特征和深层特征侧重不同,所以不同数据集对于下采样层数的需求就不同。例如一些简单的数据集,采用浅层特征就可以很好的识别,而采用深层特征有可能会导致过拟合,从而降低精度。
那么该如何确定UNet的网络层数呢?
显然最简单的方法就是训练很多个不同下采样层数的UNet网络,但是这种方法太过笨拙,参数太大。因此,何不将UNet不同层之间公用一个特征提取器!于是就提出了如下网络:
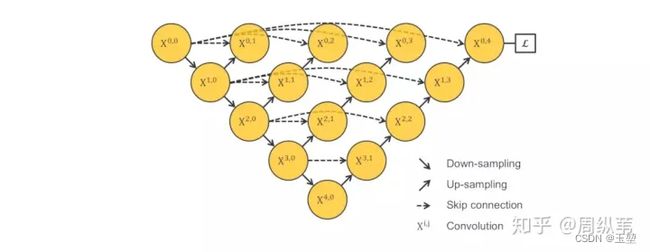
但是该网络存在一个问题,无法进行反向传播?

可以看到如果进行反向传播,上图中三角区域是没法进行梯度更新的,因此,可以显而易见的想到短链接的方式,如下图:
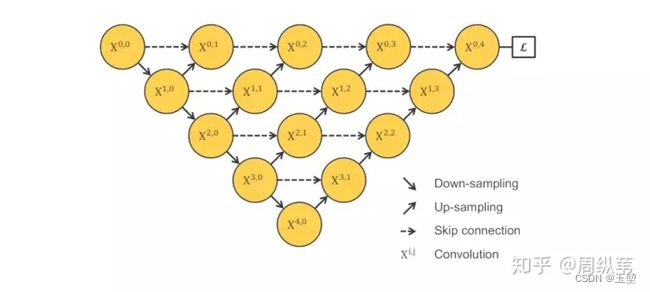
但是短链接的方式,丧失了UNet当中的长连接,该如何优化?
作者认为:U-Net中的长连接是有必要的 ,它联系了输入图像的很多信息,有助于还原降采样所带来的信息损失,在一定程度上,它和残差的操作非常类似,也就是residual操作,x+f(x)。因此,作者进一步改进了上述网络结构。

此时,我们捋一捋上面思路,为了寻找适应数据集的最优下采样层数,而训练多个不同下采样层的UNet。为了减少计算量,而共用一个特征提取器。为了网络可以训练,而增加了长短连接。此时,为了网络的反向传播,以及同时利用不同下采样层的输出结果,而添加了deep supervision。UNet++的网络结果如下所示:
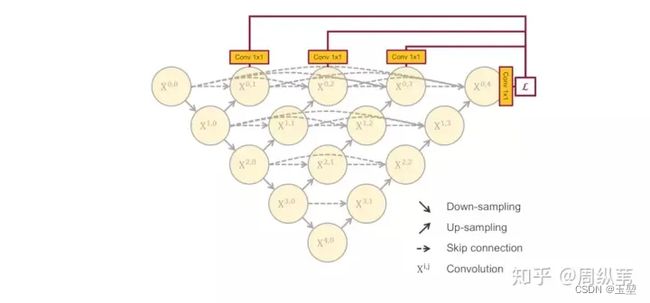
UNet++网络最大的优势其实是下面要介绍的剪枝,那么UNet++为什么可以剪枝?
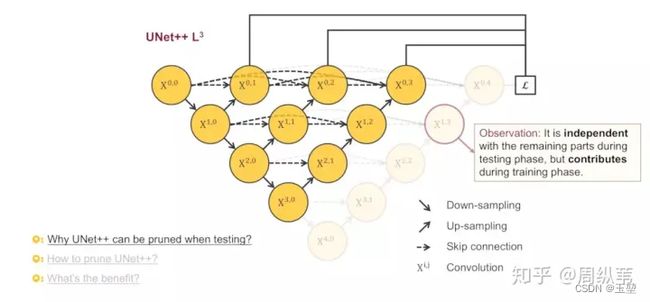
从下图中可以得出两个结论:
1.在测试中,如果剪掉最后一层的输出L4,是不影响前面的三层输出L1,L2,L3的。
2.在训练中,剪掉最后一层对前面网络的权重是有影响的。
从这两个结论中,我们发现,在测试过程中,可以通过deep supervision实现网络的减枝操作。从下图中可以看到,我们通过计算不同深度下的输出损失,来使得每个层的结果都接近于真实值。如果某一层的结果最优,则可以删掉后面的下采样层,而对于结果完全不影响,这样可以极大的减少网络的参数量。
同时也要注意,必须是在测试时剪枝,而不能在训练时剪枝,因为训练时剪枝会影响网络的学习能力。引用作者的知乎解读:研习U-Net:https://zhuanlan.zhihu.com/p/44958351的一个评论来理解,评论作者是:LaLaLand。

为什么这么大篇幅的来讲UNet++网络,因为我认为这个作者的解读太好了。作者并不是那种直接列出网络结构和创新点,并实验论证的方式,而是通过由浅入深的细细分析,犹如抽丝剥茧般的捋清网络中层层的设计思路。这种解读方式,不仅让我学习到了这个UNet++网络,还给我展现了一个网络设计的思路过程。他的文章读完让我有种酣畅淋漓的感觉,我这种拙劣的总结感觉无法描述清楚作者的思路,强烈建议读者朋友去阅读一下原文。
2.1.2 Segmentation:SegFormer
SegFormer,提出在 2021年的会议CVPR上,作者谢恩泽,论文链接:SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
SegFormer是我近一年来用的最多的网络,该网络在许多数据集上的表现的都相对较好。
该模型的主要有两个创新,分别是提出了一种分层的Transformer结构和轻量级的MLP解码器,其中分层的Transformer结构可以有效提取不同尺度的特征,并且通过卷积的方式实现不同patch的感受野交互,来实现扩大感受野的操作。轻量级MLP解码器降低了解码时的计算复杂度。
具体网络细节内容可以详见我的文章:
- Transformer:SegFormer个人总结
补充,我感觉这篇文章比较重要的一点是论证了Transformer编码器的感受野大于CNN编码器的感受野。
2.1.3 Segmentation:HRNetV2_OCR
HRNetV2_OCR,提出在2020年的会议ECCV上,作者Yuhui Yuan,论文链接:Object-Contextual Representations for Semantic Segmentation
HRNetV2_OCR其实可以分成两个部分,分别是HRNetV2部分和OCR部分,其中HRNetV2的主要创新是并行保持不同尺度的分辨率图像,充分挖掘不同尺度图像上的信息,OCR部分则是通过计算每个像素和所有类别的相关性,来加强所属类别的表示(思想类似于注意力机制)。
具体网络细节内容可以详见我的文章:
- Segmentation:HRnetv2+OCR 个人总结
2.1.4 Segmentation: HorNet
HorNet,提出在2022年的会议CVPR上,作者Yongming Rao,论文链接:HorNet: Efficient High-Order Spatial Interactions with Recursive Gated Convolutions
HorNet网络是我目前训练结果精度最高的网络了,但是权重也大了好多。该网络的的主要创新是通过设计gConv模块来实现高阶空间交互。作者在文中论述讲述目前Transformer大行其道的原因有三个,分别是输入自适应权重生成策略,远距离空间建模能力和高阶空间交互作用。目前,大多数网络都集中在输入自适应权重生成策略,远距离空间建模能力上,忽略了高阶空间交互上的作用。因此,作者通过设计gConv模块实现高阶空间交互。该模块有三个特性,分别是有效性,可扩展性和平移等变性。作者基于gConv模块设计了一个通用的网络HorNet。
具体网络细节可以详见我的文章:
- Segmentation:HorNet 学习总结
2.1.5 Detection: CenterNet
CenterNet,提出在2019年的会议CVPR上,作者Xingyi Zhou,论文链接:Objects as Points
这是我第一个使用的目标检测网络。也是我第一个接触到Anchor-free网络。该网络检测的目标主要通过三个输出值来进行表示,第一个是热点图,用来预测目标位置;第二个是宽高值,用来预测目标框的宽高;第三个是位置偏差值,用来预测热点图中的目标位置和原始图像中目标位置偏差大小。该网络主打轻量级,其性能和yolov3相当。
2.1.6 Detection: YoloV5
Yolo-v5是我接触的另一个目标检测代码,虽然常用yolov5s来跑一些模型。但是说来惭愧,原理文章我看了不少,但是基于我对CSPNet,SPPNet的了解不多,所以没有理解网络的优势。后续会补充学习。
2.2 MMCV框架
这个框架是商汤研发的,我主要使用是语义分割部分,即MMSegmentation。这也是我这一年来使用最多的框架了。该框架兼容了目前大部分的优秀网络模型,并且可以通过配置参数的方式自由搭配模型,数据以及训练方式。
linux下载mmcv和mmsegmentation非常简单,只需要用过 pip install mmcv-full就可以下载,mmsegmentation同理。但是windows下载则复杂很多,需要进行编译处理。具体流程,我是参考博客我真的爱发明的文章:Windows10下面安装MMCV全过程图文详解来完成下载的。
mmcv框架主要包含如下文件。
由于个人了解的不是很深,因此只列出主体文件和部分从属文件。并指对部分了解的文件进行解释说明。
|—config(folder)
| |—__base__(folder)
| | |—dataset(folder):包含读取数据的配置文件。
| | |—models(folder):基本的模型的配置文件
| | |—schedules(folder):包含学习率,优化器,周期等参数的配置文件
| | |—default_runtime.py(file)
|—mmcv(folder)
|—mmseg(folder)
| |—apis(folder)
| |—core(folder)
| | |—evaluation(folder)
| | | |—metrics.py(file):包含指标计算文件。
| |—datasets(folder):
| | |—pipines(folder)
| | | |—loading.py(file):读取数据和标签的脚本文件。
| | |—voc.py(file)
| | |—ade.py(file)
| | |—…自定义数据,需要修改对应数据集格式脚本中的类别和颜色。
| |—models(folder):
| | |—backbones(folder):包含各种backbones网络
| | |—decode_heads(folder):包含各种解码器。
| | |—loss(folder):包含各种损失函数。
| |—ops(folder)
| |—utils(folder)
| |—__init__.py(file)
| |—version.py(file):规定了MMCV的最大版本和最小版本。
|—tools(folder)
| |—train.py(file):训练文件
| |—test.py(file):测试文件
2.3 Onnx部署以及MMDeploy框架的使用
今年总结了一篇通过MMDeploy框架进行Onnx转化的文章,里面以HorNet为例详细介绍了转化的具体过程,并总结了转换过程中遇到的问题。
我的文章链接如下:
- 基于MMdeploy实现HorNet(GF)模型到ONNX转化的流程记录
此处,我也简单总结下转化Onnx时,遇到的一些问题和解决方法。
1. onnx中无法支持的算子,可以通过使用其他的方式进行替换。比如说HorNet中fft_rfft2在最新的onnx=1.13中都没有被支持。我通过使用numpy包的相关函数替换实现了onnx的成功转换。
2. torch对于onnx中opset的支持版本有范围限制,可以通过查看torch/onnx/symbolic_helper.py里面进行查找。torch的github地址
3. onnxruntime有cpu版本和gpu版本,下载时需要注意,并且onnxruntime-gpu必须根据CUDA版本来进行选择版本。可以参考博客onnxruntime版本和CUDA版本的对应。
4. 基于MMsegmentation框架下的算法有时候通过torch.onnx.export无法直接进行转化,但是可以通过商汤自己研发的MMDeploy框架进行转化。
2.4 Opencv总结
在今年我开启了Opencv的学习总结,把常用数字图像处理方法和对应函数进行总结,并且附上python和C++示例。这件事在其他公司实习时,就做过一遍,但是那个时候总结的不太到位,并且只有python示例。这次则重新总结一遍,并添加C++的示例。
写这个系列主要的目的是建立一个函数使用手册,方便随时查用函数,并且根据代码案例来了解函数的使用方式。
目前已经完成了5篇文章,其中4篇是介绍Opencv的相关函数,另一篇是介绍Opencv的项目案例。具体博客的参考链接如下:
函数系列:
- OpenCV函数简记_第一章数字图像的基本概念(邻域,连通,色彩空间)
- OpenCV函数简记_第二章数字图像的基本操作(图像读写,图像像素获取,图像ROI获取,图像混合,图形绘制)
- OpenCV函数简记_第三章数字图像的滤波处理(方框,均值,高斯,中值和双边滤波)
- OpenCV函数简记_第四章数字图像的形态学处理和图像金字塔。(腐蚀、膨胀、开,闭运算、形态学梯度、顶帽和黑帽以及图像金字塔)
应用系列:
- OpenCV函数应用:基于二值图像的三种孔洞填充方法记录(附python,C++代码)
明年则继续更新Opencv函数系列文章。争取早日写完。
2.5 C++的学习总结
今年简单学习了下C++的基本语法,并且通过编写Opencv示例以及CUDA编程来进行巩固。但是由于缺乏实际项目需求,长时间不使用导致又忘了一些。明年打算重新过一遍,并且着重学习进阶语法。将一些重要的内容总结成博客文章。
2.6 CUDA的学习总结
今年学习了樊哲勇老师的书《CUDA编程 基础与实践》,并且也学习了CSDN的CUDA学习。但是也是缺乏实际项目需求,长时间不使用导致忘了一些内容。明年打算开CUDA总结系列,帮我重新回顾CUDA编程的内容。
最后补充一下:樊哲勇老师的《CUDA编程 基础与实践》我个人感觉很好,书籍整体很薄,内容不多,但是深入浅出,浅显易懂,并且每个章节都列出了代码案例(C++),很适合CUDA编程的入门。如果有对CUDA编程感兴趣的,可以看一看这本书。
2.7 其他学习总结
今年也总结了一些有关深度学习和python的知识。有关深度学习方面有两篇文章,分别是:
第一篇介绍了注意力机制和自注意力机制的原理和区别。随着越来越多的Transformer模型开始展露头角,为了更深入的了解Transformer中自注意力机制原理,我对注意力机制和自注意力机制进行全面总结。
大概结论如下面几点:
- 注意力可以分为两种方式分别是自主提示和非自主提示。其中非自主提示是键,自主提示是查询,物体原始向量是值。键和值是一一对应的。
- 注意力机制其实就是自主提示对非自主提示的相关性建模,生成一组注意力权重,最后进行在原始向量上进行加权和的过程,更形象的解释可以理解为软寻址。
- 注意力机制和自注意力机制的区别在于,注意力机制的查询和键属于不同组的特征,如在英译中翻译中,查询是英文,键是中文,而自注意力机制的查询和键始于同组特征,即查询和键都是中文。
- 如果查询和键是同一组内的特征,并且相互做注意力机制,则称为自注意力机制或内部注意力机制。
- 注意力机制的评分函数可以对查询和键进行关系建模,获取查询和键的相似度匹配。其方法分为两种:加性注意力和点积注意力。常用的是点积注意力。
- 多头注意力机制的多头表示对每个Query和所有的Key-Value做多次注意力机制。做两次,就是两头,做三次,就是三头。这样做的意义在于获取每个Query和所有的Key-Value的不同的依赖关系。
- 自注意力机制的优缺点简记为【优点:感受野大。缺点:需要大数据。】
具体细节可以参考我的文章:
- Transformer:注意力机制(attention)和自注意力机制(self-attention)的学习总结
这也是我今年写的最火的一篇文章了。
第二篇总结了常用的目标检测指标,包含IoU、TP、FP、TN、FN、Precision、Recall、F1-score、P-R曲线、AP、mAP、 ROC曲线、TPR、FPR和AUC。
具体细节参考我的文章:
- Detection:目标检测常用评价指标的学习总结(IoU、TP、FP、TN、FN、Precision、Recall、F1-score、P-R曲线、AP、mAP、 ROC曲线、TPR、FPR和AUC)
有关python方面有一篇文章,主要是介绍了python闭包,装饰器的原理,以及大部分框架中的注册机制原理。
具体细节参考我的文章:
- 【python】Python闭包(closure),装饰器(Decorator)和注册机制(Registry)的学习笔记。
3. 开发工具简介
这些是我目前工作用的工具,感觉用的满顺手的,推荐给大家。
3.1 PyCharm
官网地址:https://www.jetbrains.com/pycharm/
我主要使用的语言是python,以PyCharm作为开发环境。PyCharm吸引我的主要有3点,分别是调试方便,可以远程服务器使用(需要专业版),可以连接github。下面则分别介绍一下这三点功能。
3.1.1 调试方法分享
关于调试方面,我就介绍两个常用的调式操作。
第一个主要和我之前有使用过matlab有关系,我非常喜欢matlab中在代码编辑区下方的命令行窗口,这个命令行窗口可以让我在代码运行到断点时,对代码中变量进行额外的编辑操作,而不需要终止代码运行。PyCharm也有同样的功能,具体操作如下:
需要注意:请不要轻易的修改代码中变量的值,因为该操作的修改会影响后续代码的运行
(1)运行代码到断点处,点击下方的Console按钮。
(2)点到Console界面下,再双击下图中指向的图标。
(3)双击该图标后,就进入到类似于matlab中命令行窗口了。
(4)在这个命令行窗口下就可以对变量进行编辑操作了。如下图所示,我将变量data_val[0]进行图像显示。

另一个调试比较常用的是计算表达式窗口(Evaluate Expression),可以计算输入的代码结果。我常用来计算一行代码中的部分代码,如下所示:
需要注意:请不要轻易的修改代码中变量的值,因为该操作的修改会影响后续代码的运行
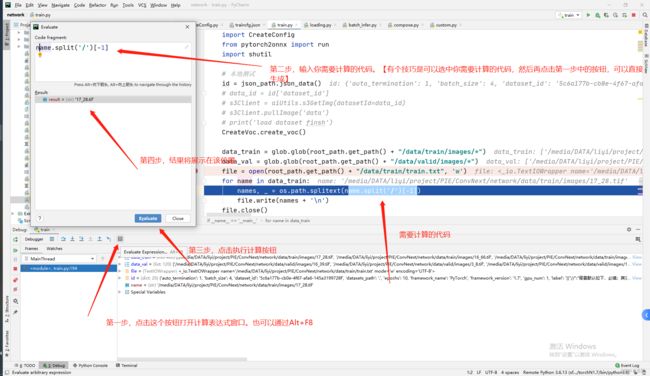
3.1.2 远程服务器操作流程
这个需要PyCharm专业版才可以使用该功能。至于怎么装专业版,由于本人装的时间太早了,忘记怎么装了,只能麻烦各位读者朋友自行安装。
针对远程服务器操作,我仅分享一下如何配置远程操作环境。配置远程操作环境主要分为两个主要步骤,分别是配置deployment环境和python interpreter环境,其中配置deployment环境的目的在于本地和远程服务器的文件同步,配置python interpreter环境是为了能在本地使用服务器中的python interpreter的运行环境。具体操作如下:
值得注意的是,PyCharm的远程操作和vsCode不一样,vsCode是直接在服务器上对代码进行操作,而PyCharm则是在本地进行修改文件,然后同步到服务器上,也就是说PyCharm在本地和服务器中都有一套相同的代码。
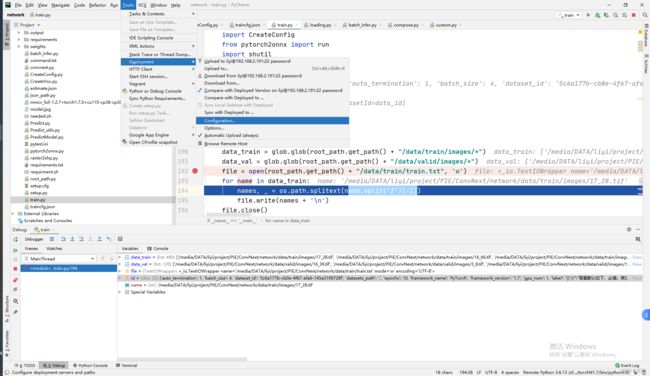
(1)配置deployment环境
1)从PyCharm最上边的菜单栏中选择tools,在里面选择Deployment,再选择Configuration即可进入Deployment配置窗口,如下图:
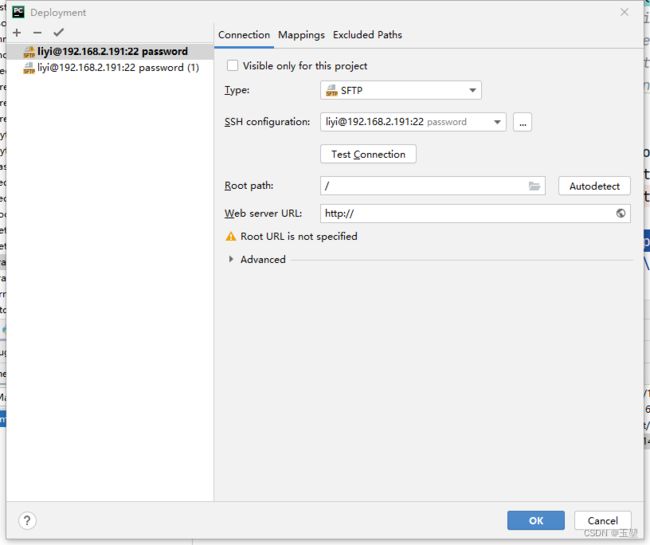
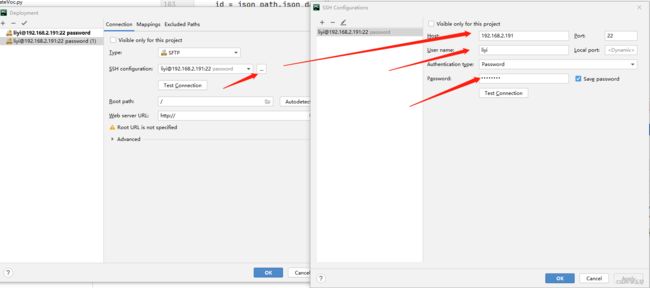
2)然后配置远程服务器的IP,账号密码。如下图:
其中第二步的远程服务器配置如下图所示:
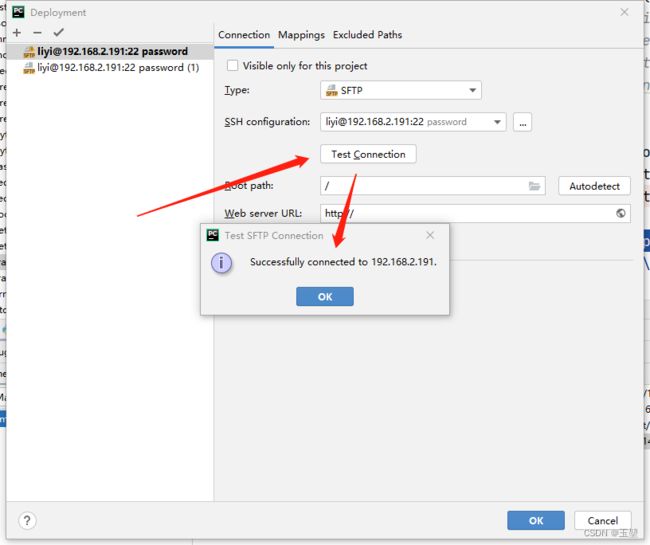
配置完后,通过test configuration来测试是否配置正确,如下图:
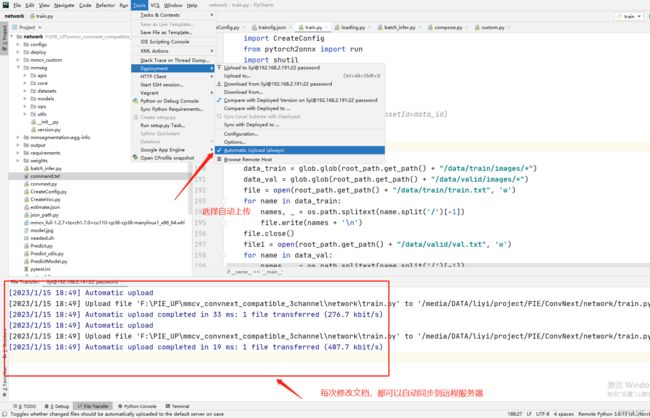
3)配置完服务器后,配置本地路径和远程服务器路径的映射。如下图
完成后,我一般会选择自动上传文件选项。也就是你对文档进行修改后,会自动上传到远程服务器。


(2)接下来是Python Interpreter的配置方法:
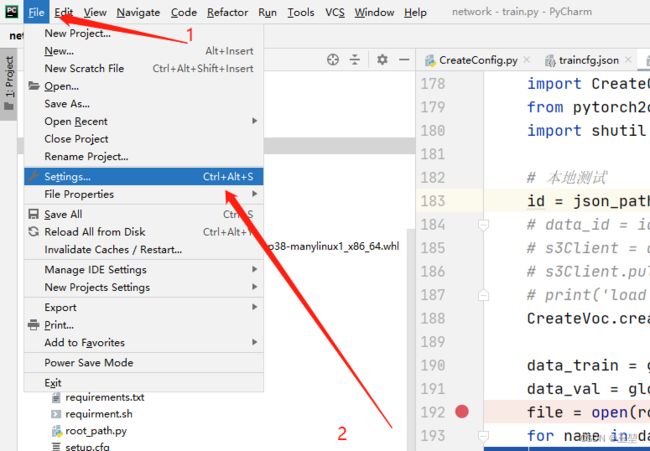
1)打开设置,方式如下图:
2)找到Python Interpreter
3)然后按照下图的步骤添加远程Python Interpreter:
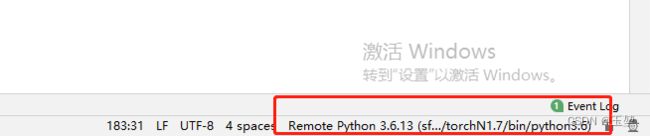
此时python interpreter就配置成功了,在PyCharm的右下角可以看到远程python interpreter的内容。








3.1.3 远程Github操作流程
PyCharm可以支持github进行版本管理。此处简略介绍下配置远程github的流程。
1)打开设置,方式如下图:
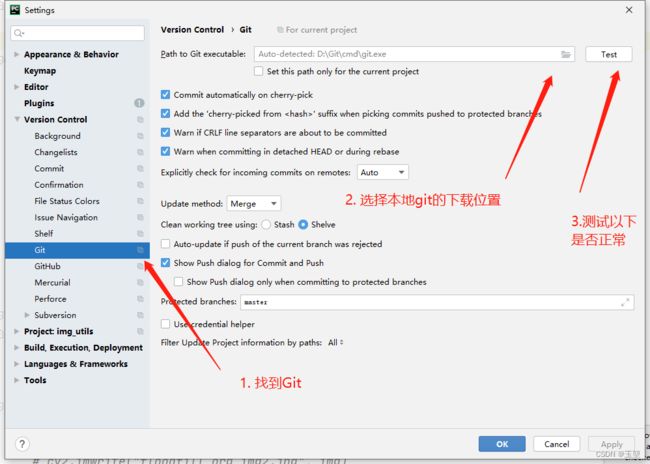
2)配置Git,如下图:
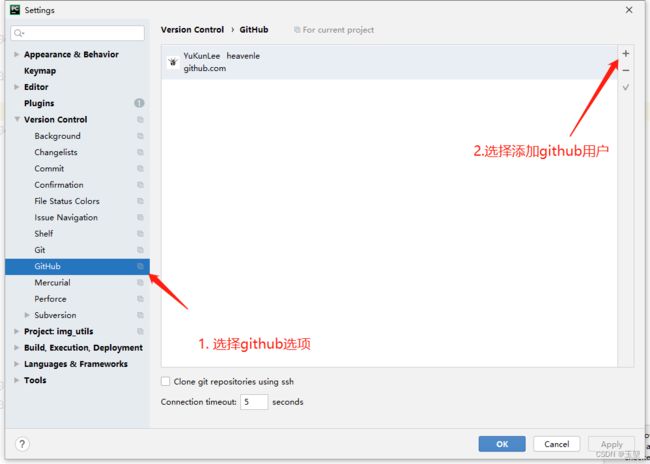
3)配置github配置:
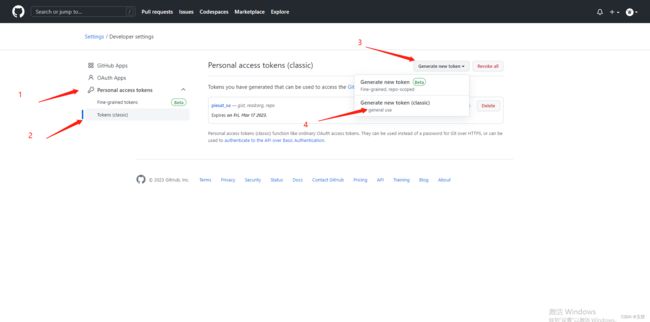
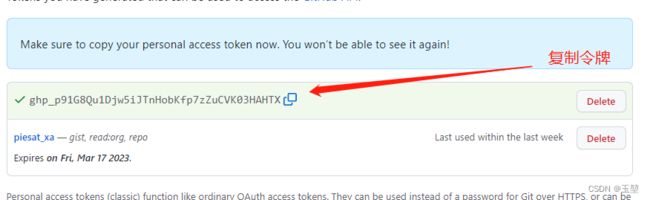
4)在你的github上生成token。流程如下图:
5)填写token到PyCharm上,流程如下图:
6)创建你的项目。






3.2 Termius
官方网址:https://termius.com/
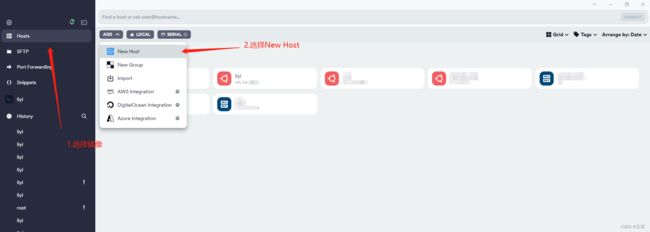
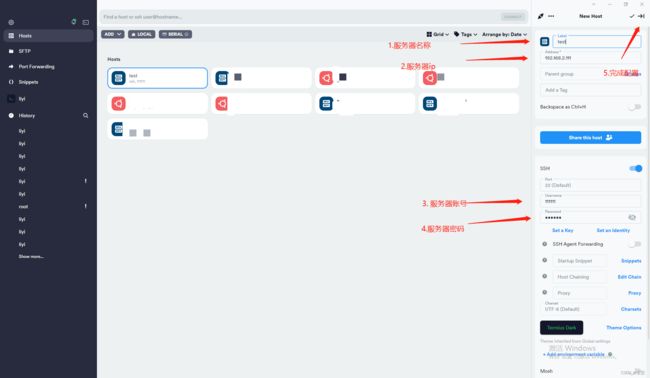
Termius是主要用来进行远程服务器的模拟终端软件。基础功能是免费的,升级功能是收费的。但是目前从我使用的情况来看,基础功能足够我用了。该软件需要先进行注册,才能使用。下面,我将分享配置服务器的流程和一些常用操作。
配置远程服务器参数的流程如下图所示:
(1)配置服务器:
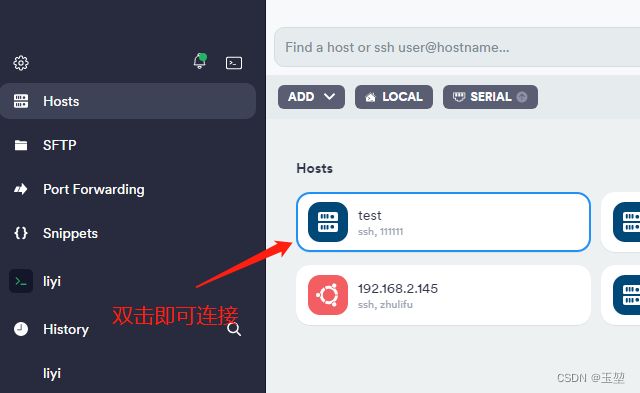
(2)界面展示如下:
常用操作:
放大字体:‘crtl’ + ‘+’
缩小字体:‘ctrl’ + ‘-’
复制内容:‘ctrl’ + ‘shift’ + ‘c’
粘贴内容:‘ctrl’ + ‘shift’ + ‘v’

3.3 FileZilla
官方网址:https://filezilla-project.org/
FileZilla是一款可以给远程服务器进行传输文件的免费软件,传输速度的感觉还可以,经过之前实习以及这1年的工作,整体使用起来也挺方便。下面就是分享远程服务器配置流程,如下图所示。

这个软件非常简单,需要传输只需要把文件拖到本地或者服务器目录下即可。
3.4 NotePad++
这个是很好用的文本编辑器,我打开文本都用它,甚至编写一些简单的代码。该软件具有自动补全变量,高亮文本,代码块缩放等功能,十分推荐。下图是其界面展示:

3.5 screen
screen是一款多视窗管理软件,可以实现关闭当前终端会话后不会中断网络训练,并且可以通过会话窗口恢复来重新查看原来的终端窗口内容。
更详细的介绍如下
(节选自知乎作者Mintimate终端命令神器–Screen命令详解。助力Unix/Linux使用和管理):
screen的功能大体有三个:
- 会话恢复:只要Screen本身没有终止,在其内部运行的会话都可以恢复。这一点对于远程登录的用户特别有用——即使网络连接中断,用户也不会失去对已经打开的命令行会话的控制。只要再次登录到主机上执行screen -r就可以恢复会话的运行。同样在暂时离开的时候,也可以执行分离命令detach,在保证里面的程序正常运行的情况下让Screen挂起(切换到后台)。这一点和图形界面下的VNC很相似。
- 多窗口:在Screen环境下,所有的会话都独立的运行,并拥有各自的编号、输入、输出和窗口缓存。用户可以通过快捷键在不同的窗口下切换,并可以自由的重定向各个窗口的输入和输出。
- 会话共享:Screen可以让一个或多个用户从不同终端多次登录一个会话,并共享会话的所有特性(比如可以看到完全相同的输出)。它同时提供了窗口访问权限的机制,可以对窗口进行密码保护。
常用指令:
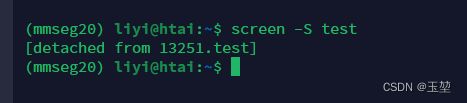
(1) 创建会话:screen -S name
此时处于创建的会话中:


(2) 临时退出会话:‘ctrl’ + ‘A’+ ‘D’
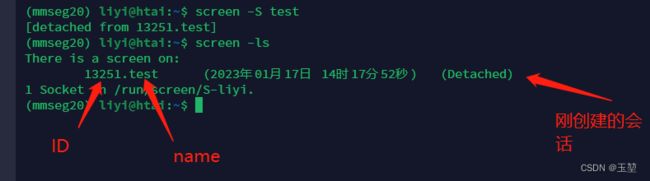
(3) 查看有多少会话:screen -ls
(4) 恢复会话:screen -r name/ID
重新进入之前的会话中。


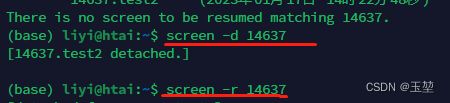
(5) 如果不能恢复会话:先screen -d name/ID, 再screen -r name/ID
当由于异常退出后,原本的会话出现Attached状态,即表明会话正在打开。此时无法通过screen -r 恢复会话。
此时通过先screen -d name/ID, 再screen -r name/ID来重新进入。

(6) 删除会话: screen -S name/ID -X quit
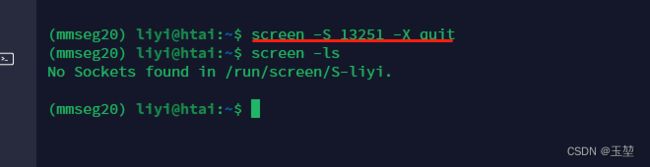
(7)在会话中,无法通过鼠标滚轮进行翻页,需要先同时按住’ctrl’ + ‘A’ + '['键。此时看到会话下方出现下图中红色框的内容时,就可以通过鼠标滚轮进行翻页了。如果要退出此时状态,则连点3次’Enter’键即可。

4. 个人总结
4.1 技术总结
- 写博客确实有助于提醒自己时刻保持学习。
- 在深度学习中,数据是重中之重,如果数据很好的情况下,大部分模型都可以跑到很好的结果。算法模型的选择对于最终的指标提升远不如调整数据。
- 我个人对于超参数的调整非常少(几乎是不调整),大部分都是沿用作者给出的配置文件。我个人认为作者给出的参数配置都是在复杂数据上选出的最优配置,对于本地数据的具有一定兼容性。如果想大幅度的提高指标,最先应该调整的是数据。最后,才是模型的超参数调整。
- 对于多类目标,样本平衡很重要,最好是对原始数据调整,其次是模型采样策略,最后是损失函数调整。
4.2 工作总结
- 尽量选择以AI为主要业务的公司,不要选择把AI作为边缘部门的公司。如果在边缘部门会使自己学不到一些新技术,并且会随时抽调去其他部门当壮丁。
- 在领导和同事面前,不要太过于谦虚,这样会使自己的能力被看轻,要适当的表现自己的能力。当然不是要打肿脸充胖子,打铁还需自身硬。
- 可以在有领导的会议上,适当夸奖你的同事,会有助于后续的相处合作。
- 工作中及时沟通很重要,并且如果有自己的需求或者发现一些小问题不要觉得不好意思,及时提出来,可以避免后续的返工。
- 不要过于轻信任何人的承诺,要有自己独立的判断。
5. 未来规划
对于未来的工作方向:
经过这1年的工作,我发现修改和优化模型结构需要很强的数学基础和计算机基础,这种事还是交给那些顶端研究性人才来干。我更应该关注的是模型的落地以及部署。因此,后续的发展我会更注重模型的推理速度,稳定性以及跨平台部署能力。
对于2023年的规划:
- 2023年要更多学习C++语言。
- 继续学完今年剩下的CUDA编程内容,并总结博客,至少2篇博客。
- 学习一些剪枝量化方法,至少2篇博客总结。
- 学习3个新网络模型,并总结博客。
- 针对计算机基础,2023年要学完买的《数据结构》书。
- 每月一篇博客的约定要完成。