pytorch学习笔记4 - 模型训练
模型训练example
参考https://www.bilibili.com/video/BV1hE411t7RN?p=27
训练一个十分类器
数据集
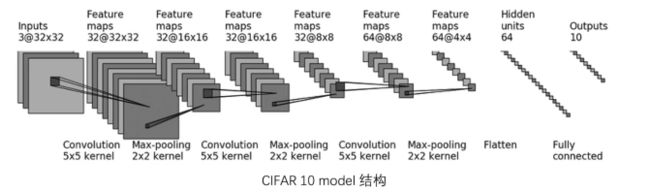
model
from torch import nn
class TenClassifier(nn.Module):
def __init__(self):
super(TenClassifier, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, inputs):
outputs = self.model(inputs)
return outputs
train
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from simple_modelue import TenClassifier
train_data = torchvision.datasets.CIFAR10("dataset", train=True,
download=True, transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.CIFAR10("dataset", train=False,
download=False, transform=torchvision.transforms.ToTensor())
train_data_length = len(train_data)
test_data_length = len(test_data)
print("the length of train dataset is:{}".format(train_data_length))
print("the length of test dataset is:{}".format(test_data_length))
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
ten_classifier = TenClassifier()
loss_fn = nn.CrossEntropyLoss()
learning_rate = 1e-2
optimizer = torch.optim.SGD(ten_classifier.parameters(), lr=learning_rate)
total_train_step = 0
total_test_step = 0
epoch = 20
writer = SummaryWriter("train_logs")
for i in range(epoch):
print(" ---------- training round: {} ---------- ".format(i))
# training part
ten_classifier.train()
for data in train_dataloader:
imgs, targets = data
outputs = ten_classifier(imgs)
loss = loss_fn(outputs, targets)
# optimizing
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 128 == 0:
print("trained {} steps, loss = {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# testing part
ten_classifier.eval()
total_test_loss = 0.0
total_hits = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = ten_classifier(imgs)
loss = loss_fn(outputs, targets)
total_test_loss += loss.item()
total_hits += (outputs.argmax(1) == targets).sum()
total_test_accuracy = total_hits / test_data_length
print("total test data loss: {}".format(total_test_loss))
print("total test data accuracy: {}".format(total_test_accuracy))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test accuracy", total_test_accuracy, total_test_step)
total_test_step += 1
torch.save(ten_classifier, "ten classifier_{}.pth".format(i))
print("round {} model saved".format(i))
writer.close()
解释各个部分
参数设置, lr是学习速率, 太大模型可能不收敛, 太小训练速度太慢, 一般设置平衡的数值
learning_rate = 1e-2
optimizer = torch.optim.SGD(ten_classifier.parameters(), lr=learning_rate)
优化, 先置梯度为0, 然后反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
测试集代码, 声明这两行代码, 让模型不再训练, 参数不变, 进行测试集测试
ten_classifier.eval()
...
with torch.no_grad():
...
计数准确率, 用argmax(1)统计输出结果的每一行的最大值的位置; 用argmax(0)统计每一列最大值的位置, 然后和目标进行比对, 得到bool数组, 用.sum()统计true的个数, 得到模型对测试集数据目标值的预测效果
total_hits += (outputs.argmax(1) == targets).sum()
total_test_accuracy = total_hits / test_data_length
运行效果
程序输出
---------- training round: 0 ----------
trained 128 steps, loss = 2.2856922149658203
trained 256 steps, loss = 2.284637451171875
trained 384 steps, loss = 2.2166197299957275
trained 512 steps, loss = 2.018079996109009
trained 640 steps, loss = 2.1644251346588135
trained 768 steps, loss = 2.0875608921051025
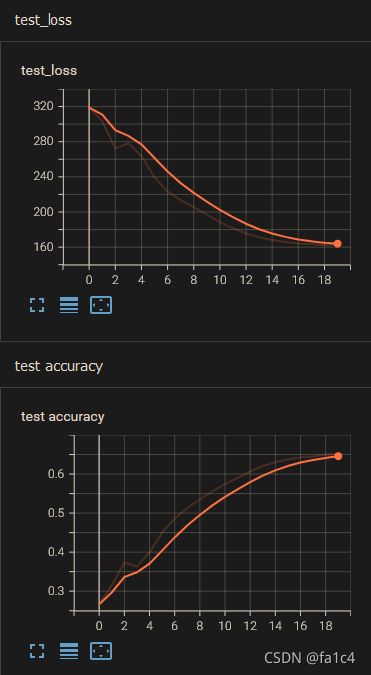
total test data loss: 319.3484115600586
total test data accuracy: 0.2662000060081482
round 0 model saved
---------- training round: 1 ----------
trained 896 steps, loss = 1.7513002157211304
trained 1024 steps, loss = 1.9080729484558105
trained 1152 steps, loss = 1.7573105096817017
trained 1280 steps, loss = 1.9202975034713745
trained 1408 steps, loss = 1.6094510555267334
trained 1536 steps, loss = 1.84885835647583
total test data loss: 303.25305140018463
total test data accuracy: 0.3149000108242035
round 1 model saved
...
---------- training round: 8 ----------
trained 6272 steps, loss = 1.0096434354782104
trained 6400 steps, loss = 1.1246448755264282
trained 6528 steps, loss = 1.118976354598999
trained 6656 steps, loss = 1.1078855991363525
trained 6784 steps, loss = 1.0187700986862183
trained 6912 steps, loss = 1.2796574831008911
total test data loss: 205.44455313682556
total test data accuracy: 0.5349000096321106
round 8 model saved
---------- training round: 9 ----------
trained 7040 steps, loss = 1.1556426286697388
trained 7168 steps, loss = 1.0041574239730835
trained 7296 steps, loss = 1.0641087293624878
trained 7424 steps, loss = 1.0743132829666138
trained 7552 steps, loss = 1.244107723236084
trained 7680 steps, loss = 1.3376758098602295
trained 7808 steps, loss = 1.0064146518707275
total test data loss: 197.09006261825562
total test data accuracy: 0.555899977684021
round 9 model saved
...
---------- training round: 18 ----------
trained 14080 steps, loss = 0.6787946820259094
trained 14208 steps, loss = 0.6274951696395874
trained 14336 steps, loss = 1.0212754011154175
trained 14464 steps, loss = 1.19745671749115
trained 14592 steps, loss = 0.8659899830818176
trained 14720 steps, loss = 0.6931119561195374
trained 14848 steps, loss = 0.8850951790809631
total test data loss: 162.3791747689247
total test data accuracy: 0.6498000025749207
round 18 model saved
---------- training round: 19 ----------
trained 14976 steps, loss = 0.7280789017677307
trained 15104 steps, loss = 1.1314042806625366
trained 15232 steps, loss = 0.6901586055755615
trained 15360 steps, loss = 0.6962088942527771
trained 15488 steps, loss = 0.7361246943473816
trained 15616 steps, loss = 0.6771916747093201
total test data loss: 162.47013890743256
total test data accuracy: 0.6523000001907349
round 19 model saved
loss曲线和accuracy曲线
gpu加速
做图像的训练, 自然要用GPU, 大概可以加快10倍的速度
方法一
在上面的代码基础上, 总共需要在4个地方调用.cuda()
(1) 神经网络模型本身
if torch.cuda.is_available():
ten_classifier.cuda()
(2) 损失函数
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
(3) dataloader读出来的数据对象
和
(4) dataloader读出来的目标对象
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
另外注意, 用gpu训练的模型, 和cpu的不能直接共用
需要调用.to(device)改变模型格式, 这样gpu训练的模型也能在cpu上使用
就是下面的第二种调用gpu加速的方法
方法二
定义训练的设备
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
改变对象的格式
ten_classifier = ten_classifier.to(device)
...
loss_fn = loss_fn.to(device)
...
imgs = imgs.to(device)
targets = targets.to(device)
开源项目
记录读开源项目源码的一些 insights
待补充…
后边读开源代码的时候应该会来补充(