《数据挖掘与机器学习》复习
根据复习阶段遇到的题型列出比较可能考的知识点
第1章 绪论
这部分基本概念了解即可
第2章 数据预处理
光滑噪声数据的方法——分箱
分箱的方法:有4种:等深分箱法、等宽分箱法、最小熵法和用户自定义区间法。
数据平滑方法:有3种按平均值平滑、按边界值平滑和按中值平滑。
分箱
等深分箱
统一权重,也成等深分箱法,将数据集按记录行数分箱,每箱具有相同的记录数,每箱记录数称为箱子的深度。这是最简单的一种分箱方法。
等宽分箱
统一区间,也称等宽分箱法,使数据集在整个属性值的区间上平均分布,即每个箱的区间范围是一个常量,称为箱子宽度。
例子、客户收入属性income排序后的值(人民币元):
800 1000 1200 1500 1500 1800 2000 2300 2500 2800 3000 3500 4000 4500 4800 5000,分箱的结果如下。
采用等深分箱
统一权重:设定权重(箱子深度)为4,分箱后
【就是每个箱子都是装4个数值】
箱1:800 1000 1200 1500
箱2:1500 1800 2000 2300
箱3:2500 2800 3000 3500
箱4:4000 4500 4800 5000
采用等宽分箱
统一区间:设定区间范围(箱子宽度)为1000元人民币,分箱后
如果,设定箱子宽度为W。那么(结合本例)
第一个:800--800+W;第二个:2000--2000+W;第三个:3500--3500+W;第四个:4800--4800+W
箱1:800 1000 1200 1500 1500 1800
箱2:2000 2300 2500 2800 3000
箱3:3500 4000 4500
箱4:4800 5000
无论是等深还是等宽分箱第一步均是要对给定数据进行排序的
数据平滑
数据平滑方法:按平均值平滑、按边界值平滑和按中值平滑。
例子:
price 的排序后数据(美元): 4, 8, 9, 15, 21, 21, 24, 25, 26, 28, 29, 34
划分为(等深的)箱:
-箱1: 4, 8, 9, 15
-箱2: 21, 21, 24, 25
-箱3: 26, 28, 29, 34用箱平均值平滑:
-箱1: 9, 9, 9, 9
-箱2: 23, 23, 23, 23
-箱3: 29, 29, 29, 29用箱边界值平滑:
-箱1: 4, 4, 4, 15
-箱2: 21, 21, 25, 25
-箱3: 26, 26, 26, 34⑴按平均值平滑 :对同一箱值中的数据求平均值,用平均值替代该箱子中的所有数据。
⑵按边界值平滑 :用距离较小的边界值替代箱中每一数据。

⑶按中值平滑 :取箱子的中值,用来替代箱子中的所有数据。
分箱和数据平滑,尊重知识产权
数据规范化
最小最大规范化(要注意的是规范目标在0~1之间这种特殊情况)


z-score规范化

按小数定标规范

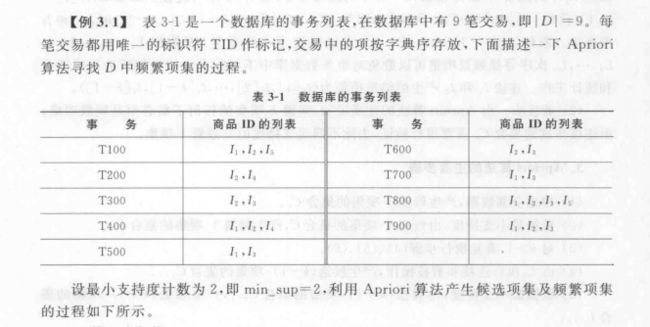
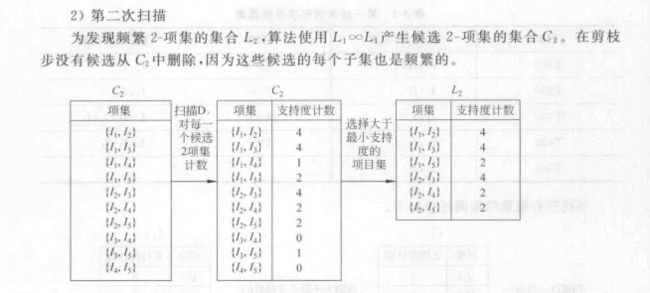
第3章 关联规则挖掘(感觉必考)
Apriori算法的流程

求出频繁项集后关联规则的求取(这点感觉不难,但不知道原理的时候可能无从下手)

上图圈出的部分是重点,告诉了我们已知频繁项集的前提下求关联规则的两个步骤:1. 求出指定频繁项集的真子集;2. 对不同真子集之间求符合指定最小置信度的关联规则,切忌关联规则的前置项和后置项不能有交集。
举个小例子说明一下
比如最后求出的频繁项集中有一个频繁项集{T, M, P}。求这个频繁项集中是否有强关联规则。
解法:
求出频繁项集的真子集{T, M, P, TM, TP, MP, TMP}
求不同真子集间的关联(切忌前置项和后置项不能有交集)
T => M(或T => P, T => MP)(这几个时合法的关联规则,再根据最小置信度判断是否为强关联规则)。
非法的关联:T => TM, T => TP, T => TMP。为啥子不合法?因为它们前后项有交集呀。
其他的合法关联以此类推。
Apriori算法的优缺点
优点

缺点


实例分析


第4章 决策树分类算法
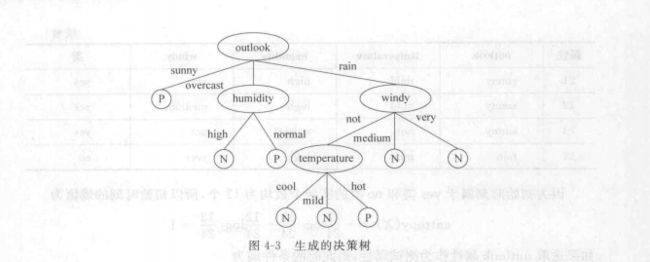
基本的决策树生成流程(结合实现过程不难理解)

ID3算法
基本思路


生成一个节点需要了解的三个基本关系
根据熵增理论,当熵值越大其不确定越大。
-
训练样本集的期望信息(熵)

-
属性划分的期望信息。 3. 信息增益

ID3实例分析



ID3算法的优缺点
优点

缺点

C4.5 与 ID3算法的区别

C4.5 算法的判断标准——信息增益比


第5章 贝叶斯分类算法
贝叶斯定理和贝叶斯决策准则
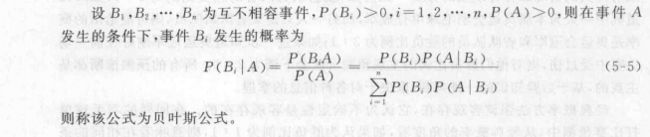

朴素贝叶斯分类器
核心公式
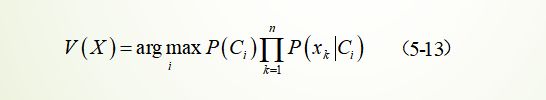

朴素贝叶斯分类的工作流程



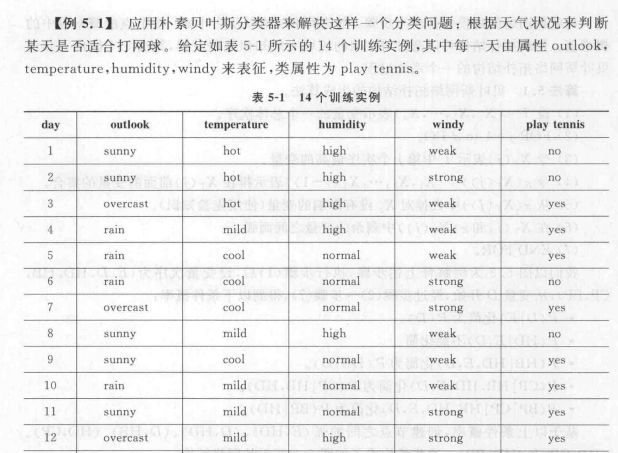
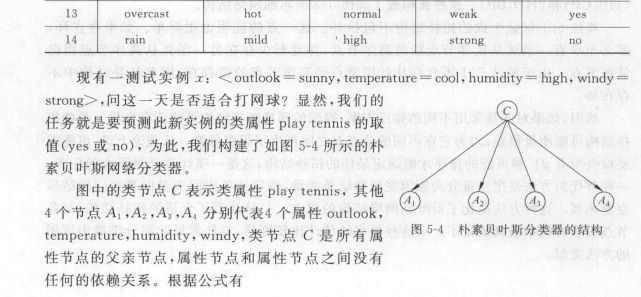
朴素贝叶斯分类器的实例分析

朴素贝叶斯的特点


第6章 人工神经网络算法
这一章想彻底弄懂要花时间呀,本人就只是了解个大概应付考试罢了
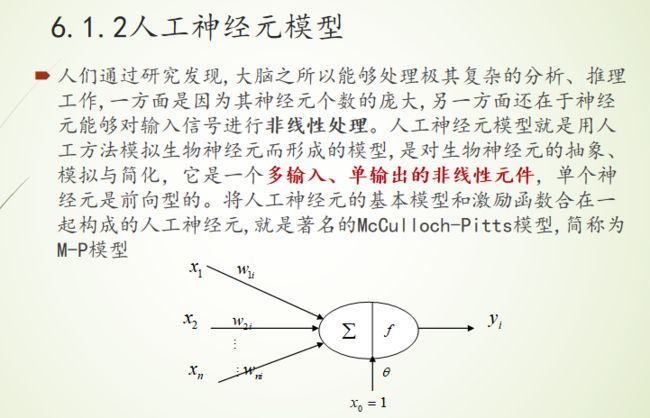
人工神经元模型
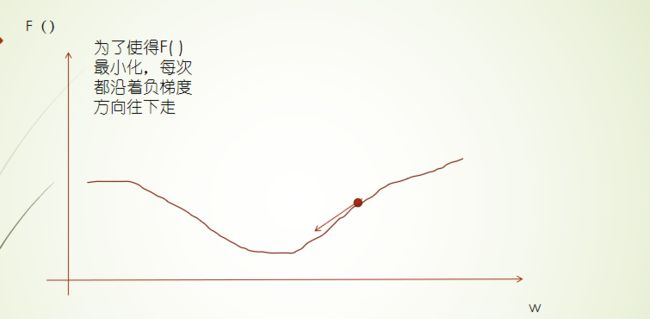
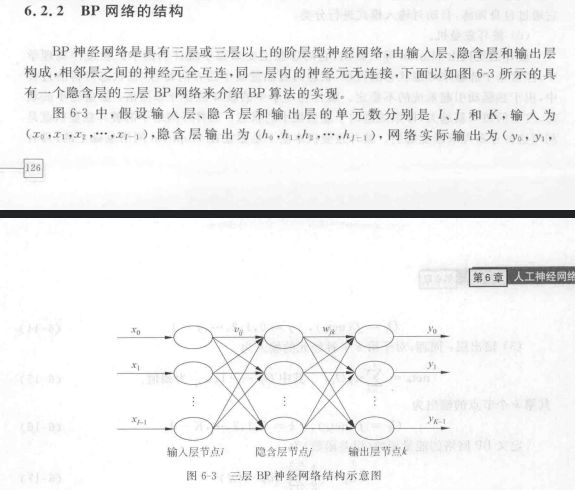
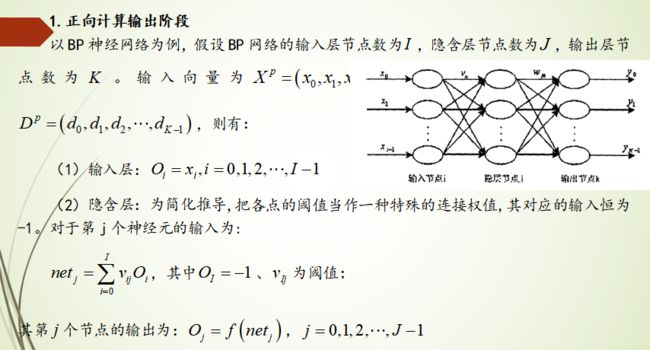
BP神经网络的原理






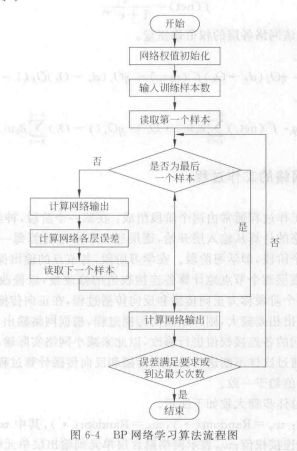
优缺点
优点

缺点

第7章 支持向量机
这一章想彻底弄懂要花时间呀,本人就只是了解个大概应付考试罢了
支持向量机原理





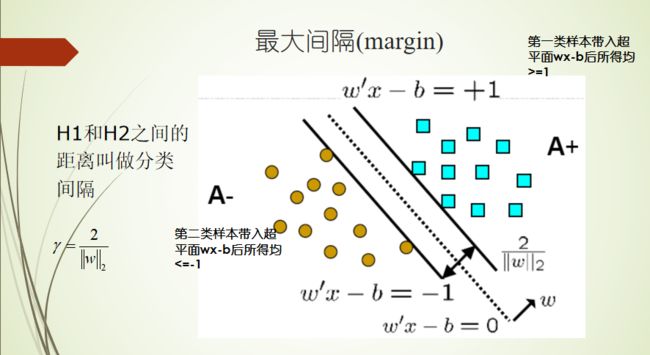



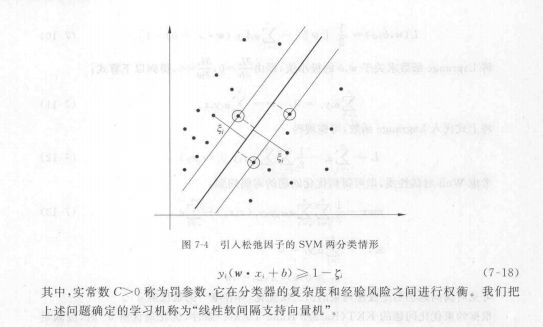
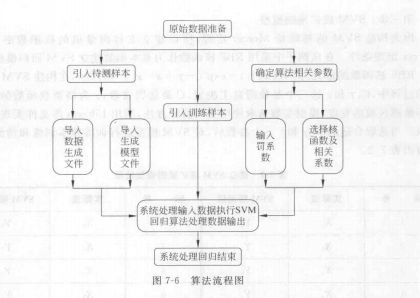
核函数

支持向量机的优缺点
优点

缺点

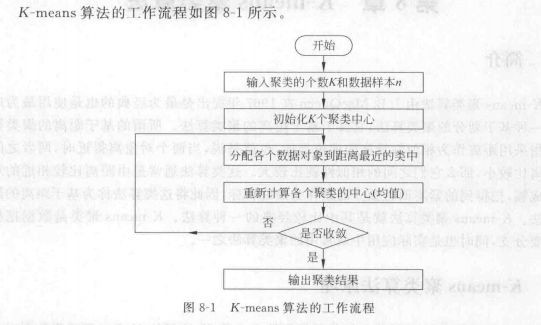
第8章 K-means聚类算法
K-means聚类算法流程


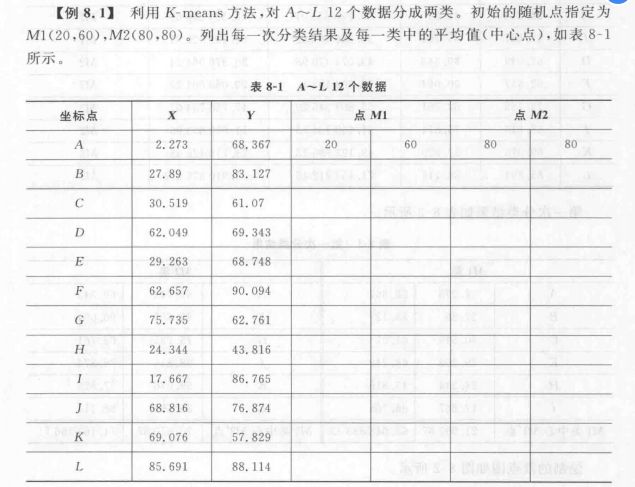
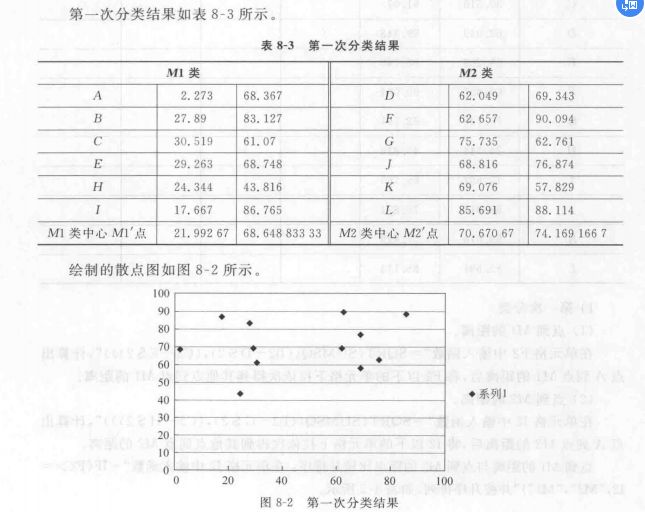
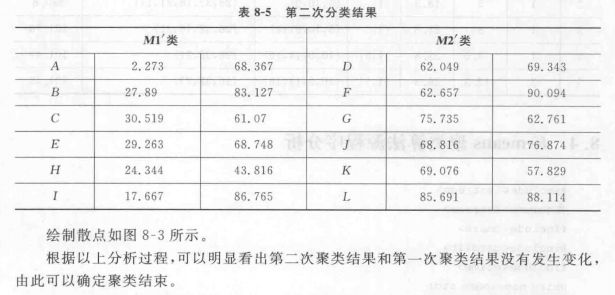
算法实例



K-means的优缺点
优点

缺点

K值的确定


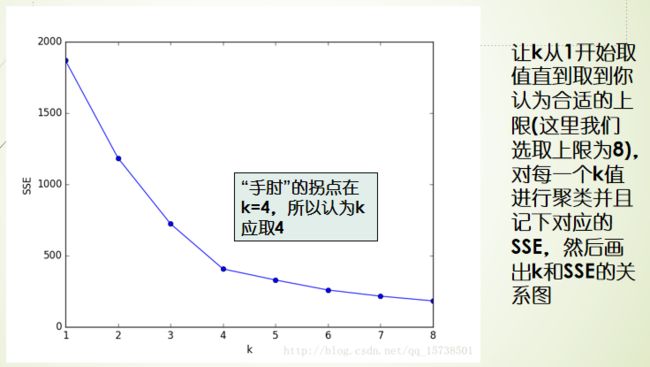
第9章 K-中心聚类算法
K-中心聚类算法流程
非中心点替换中心点的代价分析

四种情况的统一规律便是:指点样本点到新中心点的距离 - 指定样本点到旧中心点的距离。
流程(和K-means类似的流程图)

实例分析


K-中心聚类算法优缺点
优点

缺点

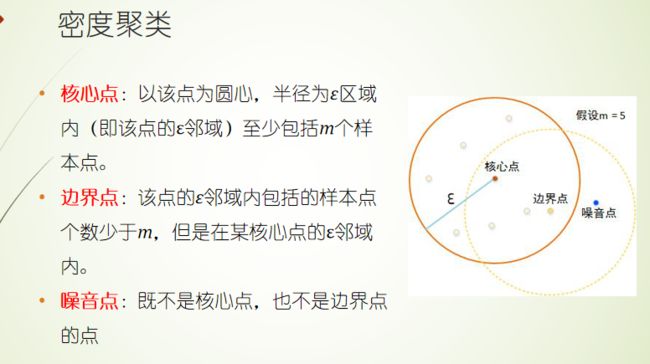
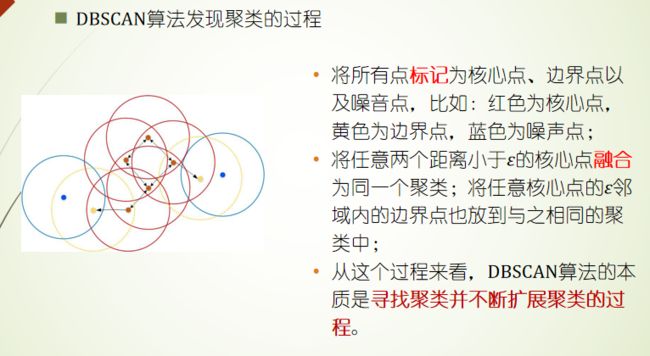
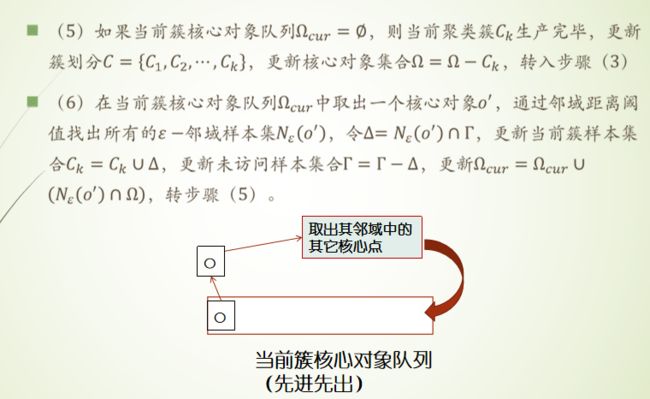
密度聚类DBSCAN


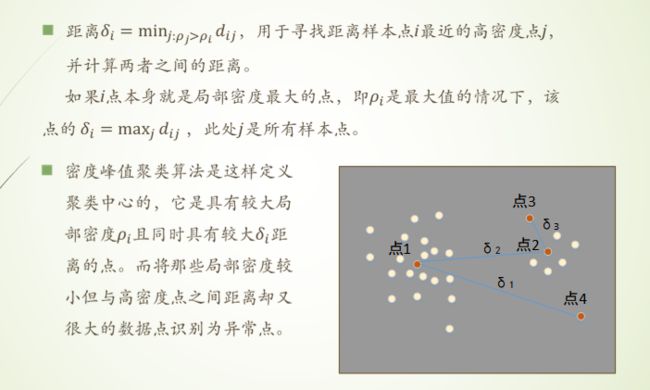
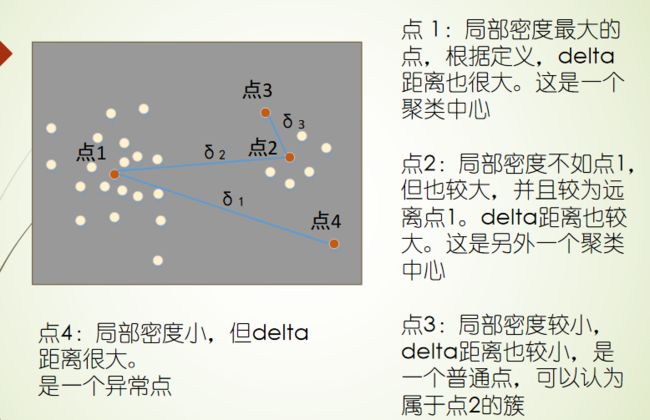
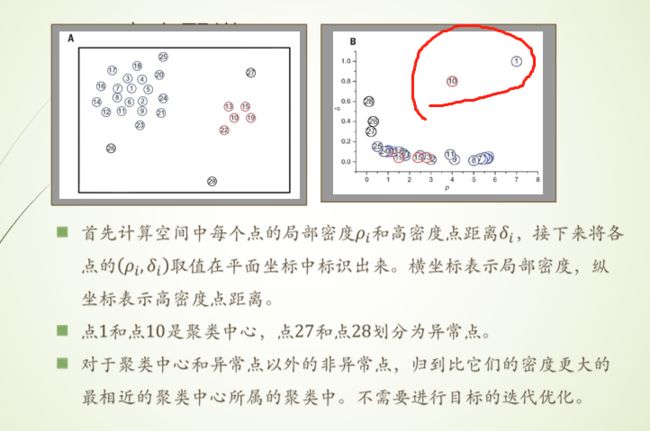
密度峰值聚类
局部密度的定义:就是找和中心点距离在指定距离 dc以内点的个数

距离的定义:对于样本点求和他最近的样本点的距离。对于最大密度的中心点找离他最远的的样本点。因为中心点要在第一象限的右上角的部位,而且越偏右上角约是有可能成为中心点。
第10章 SOM神经网络聚类方法
这一章想彻底弄懂要花时间呀,本人就只是了解个大概应付考试罢了
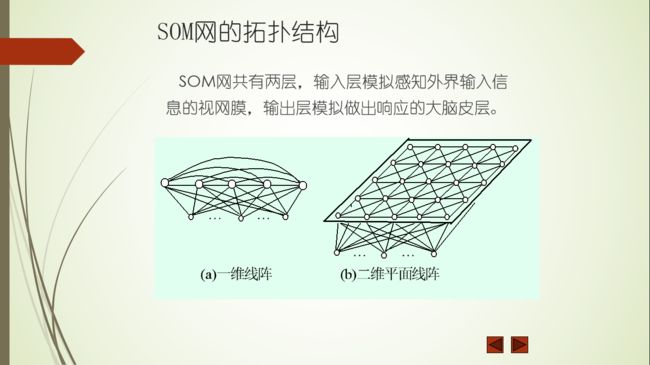
SOM网络的拓扑结构

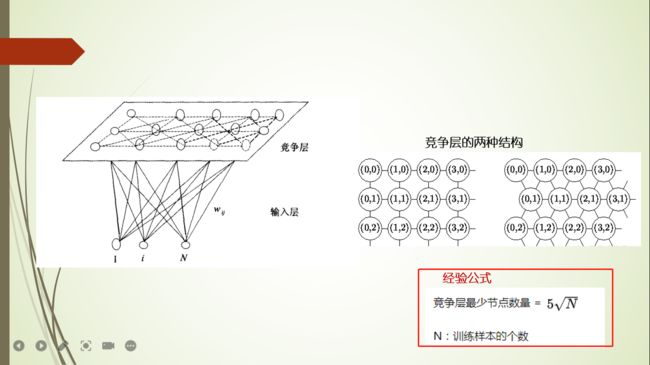
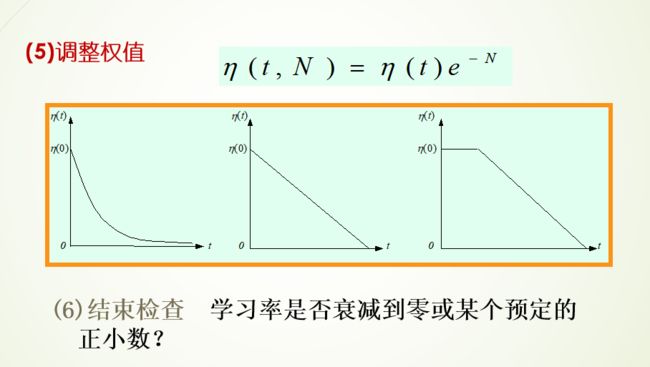
SOM网络的学习算法


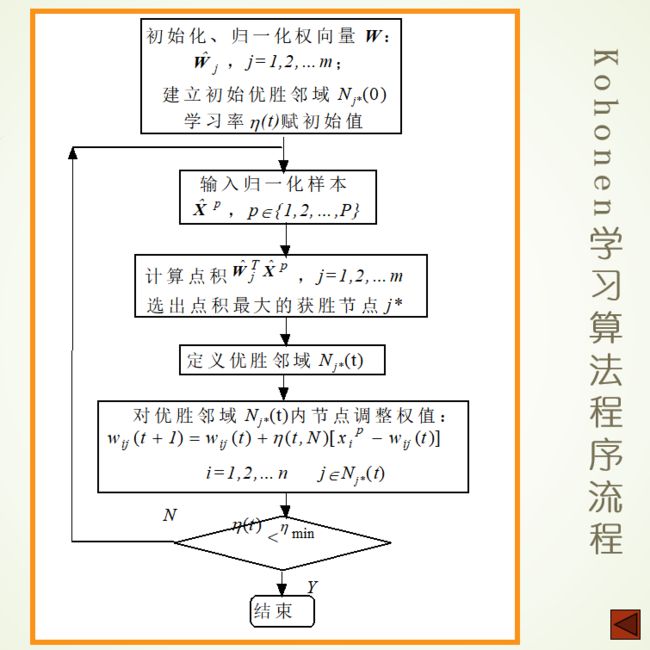
SOM优缺点
