推荐系统-召回-概述(一):内容为王
大家在访问京东或者淘宝等电商系统时,会发现当看了某件商品或者买了某件商品时,电商系统会马上推荐很多相似的商品;当在百度上搜索某个新闻时,信息流马上推荐类似的新闻,这些是怎么做到的呢?这就涉及到我们今天要讲解的基于内容的召回。
为什么需要基于内容的召回
无论是协同过滤,还是深度学习模型,当下最流行的推荐系统几乎都是以用户与物品交互行为为核心,来构建其召回体系的,但无论何时,基于内容的推荐仍然能够保留其一席之地,这是因为:其一、对于处于发展启动期的推荐系统来说,用户的内容交互量相对较少,需要有以内容召回为核心的召回机制来保证召回数量;其二、即便是成熟的大平台,每天新增的大量内容也存在冷启动问题,如抖音、快手、小红书等UGC(用户创造内容)平台,出于对作者的保护,一般都会对新内容进行保护性分发,但新内容缺乏交互,如果只存在协同过滤这类靠用户交互行为来召回的策略,则新发布的内容很难得到曝光的机会;第三、内容推荐的可解释性非常强;第四、通过用户交互行为挖掘出的内容,大部分具有一定的爆款相,即用户交互越多的物品,越容易变成热门,也越容易被召回,推荐给用户后会进一步增大其曝光量,形成了热门内容的闭环。从某种角度讲,内容的过度流行化会不利于系统多样性,过分地推荐爆款内容,长远地看也容易令用户产生疲劳感。而内容召回则能从一定程度弥补这一不足,根据用户与物品的标签匹配程度进行推荐,会更有利于系统的个性化。
基于内容的召回都有哪些手段
基于内容的召回只是一个框架,其方法是多样的。大体上可以分为显式标签召回和隐式向量召回。
标签召回
当内容的标签与用户标签相一致时,便可以为用户推荐此类内容。标签召回的基本流程是:1、为物品打标签;2、构建标签及物品的倒排索引;3、根据用户标签,将线上的标签倒排拉取出来进行推荐。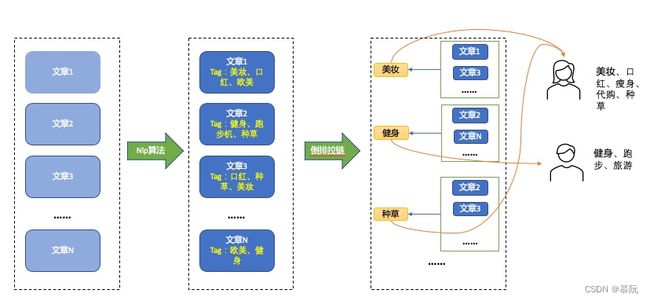
内容标签提取
内容标签的构建方式有多种。最常见的一类标签就是内容类目。
今日头条的类目
-
类目获取:类目的标定,既可以由产品引导用户在填充内容时自行选择类目,也可以在用户上传内容后由算法预测相关类目,类目预测涉及到NLP中的文本分类问题,实践中,常用的是Facebook的fasttext来进行文本分类。
-
关键词提取:文本关键词是另一大类常用标签。关键词提取的常见算法有如下两种:
-
TF-IDF:词频-逆文档频率。TF-IDF的主要思想是,如果某个词在一篇文章出现频率高(如“军舰”),在其他文章出现频率低(所有文章都常出现词为无意义词,如“人们”,“我的”),则认为该词语能较好代表文章含义。公式化的表达即为:
T F ( 词 频 ) = 词 w 在 文 档 中 出 现 的 次 数 文 档 的 总 词 数 I D F ( 逆 文 档 频 率 ) = l o g ( 语 料 库 的 文 档 总 数 包 含 词 w 的 文 档 数 + 1 ) T F I D F = T F ∗ I D FTF(词频)=词w在文档中出现的次数文档的总词数IDF(逆文档频率)=log(语料库的文档总数包含词w的文档数+1)TFIDF=TF∗IDFTF(词频)=词w在文档中出现的次数文档的总词数IDF(逆文档频率)=log(语料库的文档总数包含词w的文档数+1)TFIDF=TF∗IDF
TF(词频)=文档的总词数词w在文档中出现的次数IDF(逆文档频率)=log(包含词w的文档数+1语料库的文档总数)TFIDF=TF∗IDF
在对文本(文章/商品描述/视频描述等)进行分词(一般使用jieba或hanlp分词)及去除停用词之后,再应用TF-IDF,在每篇文章中抽取出权重较高的关键词,排序后取头部关键词,可作为文本的标签。
TF-IDF对于高频热门进行惩罚,从而能凸显出个性化重点关键词的思想非常有趣。它在整个推荐系统中会被反复体现,我们后面还会提到它。 -
TextRank:TextRank的理念来自于PageRank,PageRank是Google用于进行搜索结果排序的重要算法,其核心思想是:数量上,若一个网页被越多其他网页链接,则该网页越重要,其PR(PageRank)值会越高;质量上,若一个网页被一个越高权值的网页所链接,则表明这个网页越重要,即一个网页的PR值若很高,则它所链接的其他网页的PR值会随之提高。
TextRank则将文章中的词看作网页,设置一个窗口长度(比如5),当两个词在同一文章中出现且在同一个窗口内时(距离在5以内),则认为这两个词存在链接(双边链接)。算法的大体流程如下:
-
将文章进行分词,每个词赋予初始权重1;
-
统计每个词的出入度,同一窗口内的词之间发生链接,与pagerank不同,在这里,词之间的链接没有方向性。即一个词的出度与入度完全相等;
-
计算每个词的重要性,采用如下公式::
S ( V i ) = ( 1 − d ) + d ∗ ∑ V j ∈ I n ( V i ) 1 ∣ O u t ( V j ) ∣ S ( V j ) S(V_i) = (1-d) + d * \sum_{V_j \in In(V_i)} \frac{1}{|Out(V_j)|} S(V_j)S(Vi)=(1−d)+d∗Vj∈In(Vi)∑∣Out(Vj)∣1S(Vj)
其中d是阻尼系数,防止在反复迭代中出现Dead Ends(无外链词)最终权重全部归0的问题。该公式传达的理念是:每个词的权重与指向它的那些词相关,而指向它的词权重越高,且这些词的对外链接词越少,则被计算的词权重越高。 -
检查是否收敛(即词的权重较上一轮不再变化,或变化值小于给定阈值),或达到最大指定迭代次数;否则,重复第三个步骤,直至收敛或迭代次数到达。
下图为TextRank示例:假设A、B、C、D四个词组成文章。四个词的共现频次如下:A B C D A 1 0 B 1 1 C 0 1 D 0 1 1
可以看出,B与其他词关联最多。假设阻尼系数d = 0.85,则通过TextRank迭代后每个词权重结果如下:
权重 初始 第一次迭代 第二次迭代 第三次迭代 第十次迭代 第十一次迭代 A 1 0.433 0.674 0.504 0.568 0.564 B 1 1.85 1.248 1.606 1.462 1.47 C 1 0.858 1.039 0.945 0.985 0.983 D 1 0.858 1.039 0.945 0.985 0.983 可以看出,到第十次迭代的时候,权重变化已经很小,可以停止迭代了。
相较于TF-IDF,TextRank在单篇文章内训练,且对词之间的关联性进行了更为充分的利用,但由于缺乏充分的语料支持,该算法较易受到高频词的影响。
-
-
此外,还有一些产品化的标签提取方式,如:通过用户搜索时输入query来关联内容,通过对用户收藏夹标签的提取来为物品打标,引导用户为物品打标签;等等;虽然推荐系统是一个强算法驱动的业务,但是我们在处理各类问题时,应该打开自己的思路,不要把思维仅仅局限在算法上,而是充分利用整个产品生态来解决问题。
-
-
知识图谱:除了关键词析取,知识图谱也是内容结构化的一个方案。知识图谱通过构建实体与属性之间的关联(如实体为鞋子,属性含有品牌、尺码、生产国家等),从而构建出实体之间的关系网。知识图谱可以提供实体间的隐性关联,从而可以扩大召回的范围。但是知识图谱的构建是极其耗时耗力的,其难点在于NLP,需要机器来理解海量信息。一般需要专门的团队来完成这一工作。推荐团队一般不会专门为了召回而去构建知识图谱。事实上,知识图谱在搜索领域的应用性会更强一些。
给用户打标签
基于内容的推荐的其中一个重要思路是对物品标签及用户标签进行匹配,那么该如何为用户打标签呢?首先要明确的是,用户的兴趣标签是动态改变的,因为人的兴趣长期看是广泛稳定的,但短期则是多变难以预测的。为用户打标签,最为直观的想法,就是将用户所观看过、浏览过、点赞过、收藏过的那些物品标签直接应用于用户身上。
兴趣必然有强有弱,那么该如何计算用户所拥有的每个标签权重呢?一般来说,用户的标签可以采用如下公式:
用 户 标 签 权 重 = 行 为 类 型 权 重 ∗ 行 为 频 次 ∗ 时 间 衰 减 ∗ T F − I D F 标 签 重 要 度 用户标签权重 = 行为类型权重 * 行为频次 * 时间衰减 * TF-IDF标签重要度用户标签权重=行为类型权重∗行为频次∗时间衰减∗TF−IDF标签重要度
我们分别来看每一项的计算方式:
-
行为类型权重和行为频次可以统一看成行为权重,采取如下公式:
W o r g i j = ∑ k ∈ I u ∑ T ∈ a c t i o n s A i k T ∗ F k j ∗ C i k T Worg_{ij} = \sum_{k \in I_u} \sum_{T \in actions} A_{ikT} * F_{kj} * C_{ikT}Worgij=k∈Iu∑T∈actions∑AikT∗Fkj∗CikT
W o r g i j Worg_{ij}Worgij表示用户i对标签j的原始兴趣权重,A i k A_{ik}Aik表示用户i对物品k进行了类型为T的行为,该行为类型的权重;F k j F_{kj}Fkj表示物品k拥有标签j的权重,可以使用TF-IDF或TextRank值来表示;C i k T C_{ikT}CikT表示用户i对物品k进行类型为T的行为频次。行为类型权重根据具体业务场景定制,一般来说,收藏、点赞的权重要大于点击浏览,对于视频类物品,可根据观看时长占总时长的比例来设定权重。例如:action_type weight 点击 1 搜索 2 点赞/收藏 3 取消收藏 -5 -
时间衰减考虑的是用户兴趣随着时间的推移会不断减弱。时间衰减因子可以套用牛顿冷却定律。公式如下:
W ′ o r g i j = W o r g i j ∗ e − α ∗ △ T W'org_{ij} = Worg_{ij} * e^{-\alpha * \bigtriangleup{T}}W′orgij=Worgij∗e−α∗△T
其中,W o r g i j Worg_{ij}Worgij指用户i对标签j上一次的兴趣权重,α \alphaα是冷却系数,△ T \bigtriangleup{T}△T是上一次兴趣计算结束距离现在的时间长度,通常是指小时。这里面只要设定好α \alphaα便可以计算了。设定α \alphaα的方式通常使用指定半衰期的方法,比如假定用户在15天(15*24小时)后兴趣衰减了一半,那么就有0.5 = e − α ∗ 15 ∗ 24 0.5 = e^{-\alpha * 15 * 24}0.5=e−α∗15∗24,解出α \alphaα带入公式,即可进行计算。 -
TF-IDF值借鉴了TF-IDF算法的思路,对热门标签进行惩罚,公式如下:
W i j = W ′ o r g i j ∑ k ∈ I n ( U i ) W ′ o r g i k ∗ l o g ( 用 户 总 数 打 过 标 签 j 的 用 户 数 + 1 ) W_{ij} = \frac{W'org_{ij}}{\sum_{k \in In(Ui)}{W'org_{ik}}}* log(\frac{用户总数}{打过标签j的用户数+1})Wij=∑k∈In(Ui)W′orgikW′orgij∗log(打过标签j的用户数+1用户总数)
In(Ui)表示用户i的兴趣标签集合。最终的Wij即为用户i对于标签j的兴趣权重。
此外,对于冷启动的用户,通过注册引导让用户勾选相关兴趣点,也是常用的方案。
物品拉链排序
通过用户的兴趣标签权重,结合每个标签下的物品倒排拉链,可以为用户选出相应的物品。
物品选出后,需要根据权重排序,最终的权重系数可以采用兴趣权重*商品的标签权重(TFIDF或TextRank值)即可。
向量表示召回
除了通过标签显示表示物品和用户兴趣,对物品和用户进行隐式的向量化表达,可以发掘用户潜在兴趣,扩大物品的召回。向量化表达物品常用的方案为LDA、Doc2vec等。
LDA
LDA是两个常用模型的简称:线性判别分析(Linear Discriminant Analysis)和隐含狄利克雷分布(Latent Dirichlet Allocation),自然语言分析里说的LDA是指后者。
LDA将文档分解成文档->主题->词,通过构建文章与主题矩阵,以及主题与分词矩阵,将一篇文章进行分解(这里的主题并非是实际意义上的主题,而是概率表示)。即:一篇文章可以做如下表示:
p ( 词 语 | 文 档 ) = ∑ 主 题 p ( 词 语 | 主 题 ) ∗ p ( 主 题 | 文 档 ) p(词语|文档) = \sum_{主题}p(词语|主题) * p(主题|文档)p(词语|文档)=主题∑p(词语|主题)∗p(主题|文档)
使用矩阵表示即为: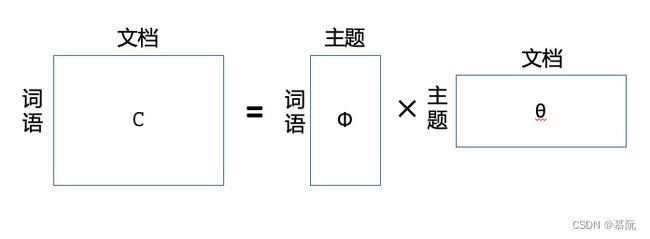
其中”文档-词语”矩阵表示每个文档中每个单词出现的概率;”主题-词语”矩阵表示每个主题中每个单词的出现概率;”文档-主题”矩阵表示每个文档中每个主题出现的概率。通过对左边矩阵的迭代,可以求解出右边两个矩阵,这样,一篇文章就可以转化为一个稠密的主题向量(其中,向量的长度为模型参数,表达的是主题个数。一般来说维度大一点意味着预设的主题更丰富,效果会更好一些)。
LDA从应用角度看是比较简单的,本地训练可以使用python中gensim包中的LdaModel接口,分布式训练可以使用spark中mllib的LDA接口。
lda = gensim.models.ldamodel.LdaModel(\
common_corpus,
num_topics=50,
alpha='auto',
eval_every=5
)
- 1
- 2
- 3
- 4
- 5
- 6
common_corpus为输入数据,通过调用gensim下的Dictionary.doc2bow将原始文本转化为需要的输入格式;num_topics为主题个数,即最终向量长度;其他参数见API文档。
但是,LDA背后的数学原理其实是比较复杂的,涉及到狄利克雷分布,多项式分布及Gibbs采样等统计学知识,感兴趣的读者可以翻阅文献二来深究LDA的数学原理。
Doc2Vec
说到Doc2Vec,就有必要先来聊一下Word2Vec。Word2Vec可以说开创了向量化表达事物的先河。如今推荐系统常用Embedding对文本、用户、物品等进行向量化表示,框架虽不一样,但思路都是源于Word2Vec。
word2vec目标是想让一个词语能够使用计算机可处理的方式表达出来,这里的计算机可处理,是指两个词可以通过数值方式计算相似度,词语之间可以像数值一样加减(经典例子是“国王“ - “男人” + “女人” = “王后”)。word2vec实现机制是一个单层神经网络,其中,输入层所有单词使用one-hot编码表示,隐藏层为稠密向量(长度为参数),输出层为预测出的每个单词的概率。
word2vec的训练任务给出上下文,掩盖住一个词,让其他词共同预测一个掩盖词。模型通过不断迭代网络参数,使得输出对全量词库的预测结果中,掩盖词的概率最高。从而得到word2vec网络模型。在预测阶段,任一单词都可以通过该网络得到对应的其在隐藏层的向量。这是word2vec经典的CBOW模型。word2vec还有另一种训练方式,叫Skip-gram,它与CBOW模式相反,是给出一个词,用它来预测上下文。具体想了解word2vec原理的读者可查阅文献【三】,此处不再赘述。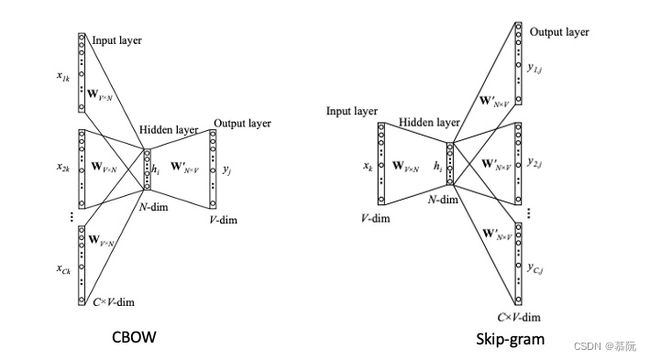
Doc2Vec从思路到做法都复用了Word2Vec,只是在输入中额外加入了paragraph id,理论上表达的是段落(每个段落拥有自己独特的id)的主旨,隐藏层中则额外加入对应pargraph id的一个向量,这样在训练的时候同时训练了段落对应的向量。预测时,如果有新的paragraph加入,则固定已训练好的word相关的参数及隐藏层与输出层参数,仅迭代pargraph id相关的矩阵参数,这样轻量级迭代可以很快完成,继而产生新的pargraph向量。Doc2Vec如上思路被称为DM模型(类比word2vec的CBOW),同样它也有类似skip-gram的模型,称为PV-DBOW,具体参见文献【4】。
Doc2Vec的应用并不复杂,python中的gensim包包含了Doc2Vec模型的封装,可以直接调用进行文章的预测和训练。
model_dm = gensim.models.doc2vec.Doc2Vec(\
documents,
window=2,
size = size,
min_count=1,
workers=4
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
x_train为输入数据,注意调用gensim.models.doc2vec.TaggedDocument先对文档进行id化标识,转化成训练需要的格式;size为最终的向量长度;其他参数可查阅API文档。
向量检索
当用户与物品都可以通过向量来表示时,便可以使用相似向量召回的方式来对物品进行检索。相似度计算方面,一般采用欧式距离或余弦距离(后续会有专门文章介绍机器学习中的相似度计算)。计算上通常有两大类方案:离线计算与在线召回。
离线计算
由于物品数量巨大(电商、视频、笔记等虽然业务不同,但一般一定体量公司物品至少是千万上亿级别),即使采用离线计算,两两向量计算相似度仍然不现实。一般采用近似最近邻搜索ANN(Approximate Nearest Neighbor)的方式。ANN业界的开源实现非常之多,有基于树,基于图的,比较常用的是基于哈希的。LSH(Locality Sensitive Hash,局部敏感哈希)是较为著名的一个算法。它的思想是:当相近的高维向量(通常为几十到几百维)通过一些哈希算法映射到低维度空间后,映射后的点大概率也是相近的,当两个高维向量映射到低维度空间的同一个桶(bucket)里时,则认为这两个向量为近邻向量。因此,一个向量的近邻向量可以通过查阅低维空间的同一个桶内向量而获得。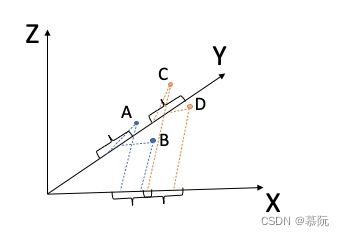
如图所示,三维空间中,A、B点在X轴和Y轴上投影距离均很近,可以认为是空间相似点;A和C在X投影上虽然在一个bucket中,但是在Y轴投影上却相距很远,因此不能认为是相近点。
LSH算法可以通过调用spark中mllib下的BucketedRandomProjectionLSH来使用。检索思路通常有两种:i2i召回或u2i召回。i2i召回是对用户近期交互过的物品,通过相似向量查找,直接召回与它们相似的物品;u2i召回则是用用户深度交互过的物品(点击、点赞、收藏、观看等)的向量加权平均值(权重可以使用牛顿冷却定律,结合交互时间来计算)来表示用户,再以用户向量为基础,寻找向量相似度较高的物品。
在线召回
在线召回对响应性能要求较高,业界通常使用的ANN的开源实现中,比较常见的有Facebook的Faiss,或者国内的开源项目Milvus,后者支持分布式架构,具有高可复用性,且用户易上手,社区强大,因此获得了许多公司的青睐,百度飞桨、搜狐、小米、贝壳等公司都有应用。检索思路与离线召回类似,可以选择i2i召回或u2i召回方案。
向量的计算和召回在如今的深度学习中大量地被使用。在后续文章里还会详细地进行阐述。
内容从何而来
推荐系统的主体内容一般是基于产品所有的物品(新闻、商品、视频、笔记等),但如果能获取更多有关物品的补充信息,对推荐精准度的提升,是大有裨益的。通常内容获取有以下方案:
- 物品本身的信息。通过对物品数据的解析和多表关联,获取足够丰富的内容信息。比如书籍信息,不仅仅包含书名、作者、简介等,还可以包含在产品平台上的用户评价星级、销量等内容。
- 算法获取的结构化数据。如通过商品评论获取商品主题,通过搜索query获取文章标签等。
- 其他部门交叉数据。许多大公司业务体系丰富,往往各部门数据间有交叉往来,灵活地跨部门引入数据进行补充,是常见思路。如店铺信息获取地图相关数据作补充,站内广告获取自然搜索结果上下文做补充。事实上,有些公司会有专门的数据中台部门来满足这样的需求。
- 产品运营引导型数据。通过运营或产品设计,让用户补充足够的信息,如收藏夹使用标签、发布信息引入主题标签等。
- 爬虫爬取的第三方平台信息。可以进一步补充物品特征内容。如在豆瓣上获取书籍、电影等的打分,小红书上获取商品的评价,电商平台上获取标品(电子产品、美妆、鞋子等)的细节补充信息等。
- 众包平台的使用。通过公众标注,可以对内容实现标注。最有名的案例便是验证码系统reCAPTCHA(Completely Automated Public Turing Test To Tell Computers and Humans Apart,区分人机的全自动图灵测试系统)了。它通过在验证码中加入纸质典籍的扫描文字,让用户识别那些年代已久的文字,再通过交叉验证来完成纸质文字的数字化。当然,大部分众包平台还是付费的,百度、阿里都有自己的众包平台可以发布标注任务。
- 第三方数据购买。一般商业价值比较高的内容类数据都是非热门行业的数据,购买时需要关注数据的法律、安全等风险。
内容推荐该向哪儿去
内容推荐如前所述,具有高度匹配用户兴趣、可解释性强、便于冷启动等特点,因此是召回策略中不可或缺的一部分。但除了推荐系统,内容召回由于其本身可解释的特征,还可以有更广泛的产品形式应用,如主题推荐等。我们日常使用的产品中都可以找到内容推荐的案例:京东的主题推荐、微博的话题整合,豆瓣的音乐标签云等。
同主题/话题/标签下的内容可以极大程度增加用户粘性,对电商来说则可以增加用户下单的概率。
内容推荐的不足
内容推荐尽管有着种种优势,但也存在一定的不足,主要问题如下:
- 内容推荐范围有限,内容推荐尽管脱离大量用户交互行为,但依然需要指定用户做出一些行为,对冷启动的用户,或者用户行为较少的情况,无法召回足够的内容;
- 内容推荐无法挖掘用户的潜在兴趣,且推荐的结果缺乏多样性和新颖性,无法给用户带来惊喜;当然,基于知识图谱的召回,如果使用长线关联,也可以扩展召回范围,但知识图谱的构建本身成本是非常高的。
- 内容推荐的前期处理相对复杂,涉及到文本、图片、视频等,且需要较强的领域知识。
由于以上种种原因,内容推荐可以作为召回系统的兜底策略,但任何一个推荐系统,都不会仅仅只有内容推荐,基于用户交互行为的推荐策略,会和内容推荐一起,组成丰富多彩的多路召回体系。
这里给各位读者留一个思考题:你还在哪些在日常使用的各类网站及APP中见过内容推荐呢?
深入浅出推荐系统(二):召回:内容为王_慕阮的博客-CSDN博客_基于内容召回
参考文献:
【1】基于内容的推荐算法。https://zhuanlan.zhihu.com/p/80068528
【2】LDA数学八卦。https://bloglxm.oss-cn-beijing.aliyuncs.com/lda-LDA%E6%95%B0%E5%AD%A6%E5%85%AB%E5%8D%A6.pdf
【3】word2vec Parameter Learning Explained
Xin Rong,https://arxiv.org/abs/1411.2738
【4】Distributed Representations of Sentences and Documents. Quoc Le, Tomas Mikolov. 2014.
【5】https://milvus.io/cn/docs/v2.0.0,Milvus文档