趣谈什么是深度学习
趣谈什么是深度学习
- 1. 从感知器说起
- 2. 多层感知器神经网络
- 3. 神经网络的困惑
- 4. 深度学习诞生
-
- (1)更深的网络结构
- (2)海量的数据驱动
- (3)强大的计算平台
- 5. 深度学习的分类
-
- (1)破译图像的密码——卷积神经网络
- (2)洞悉语言的内涵——循环神经网络
- (3)棋逢对手,伯仲之间——生成对抗网络
- (4)纸上得来终觉浅,绝知此事须躬行——深度强化学习
- 6. 总结
近年来人工智能迅速发展,其中的核心技术就是深度学习,所以我们通俗介绍一下什么是深度学习。
1. 从感知器说起
为了实现模拟人类的学习,科学家们首先设计了构成神经网络的基本结构神经元(感知器模型),然后再由大量的神经元构成复杂的,能够实现各种功能的神经网络。这种模式和超能陆战队中的磁力机器人很像,大量的磁力机器人可以构成各种形态,完成各种复杂的任务。

感知器模型的原型来自于生物学上的神经元,我们可以看到生物学上的神经元能够抽象成树突,轴突和细胞体三部分。其中树突接收来自其他神经元的信号,因此它的分布范围可代表该神经元接受刺激的范围。细胞体综合所有树突的信号,轴突则是自细胞体发出的一条突起,传递来自细胞体发出的信号给下一个神经元。
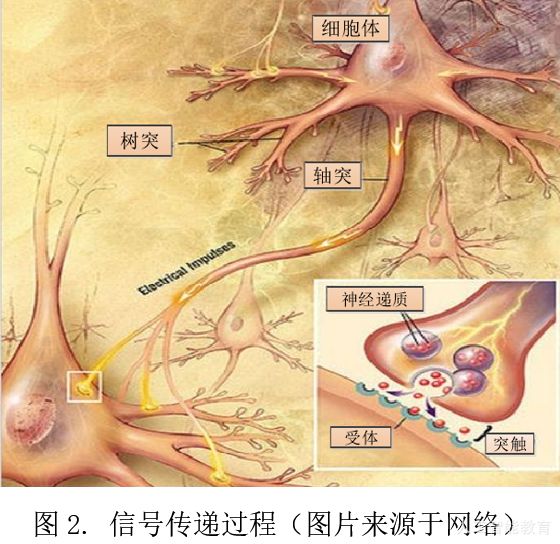
将以上过程进行抽象以后,就可以得到神经元(感知器)的基本模型: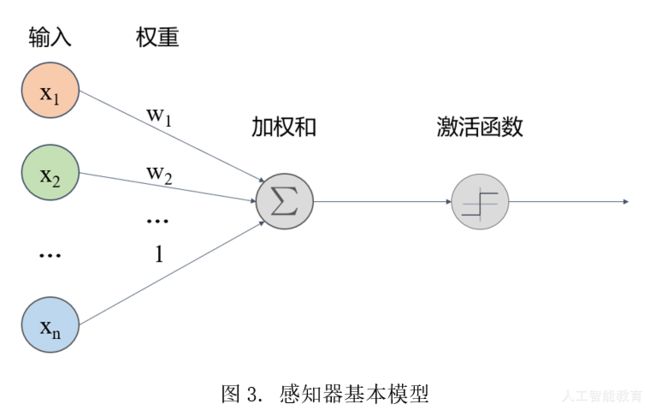
由上图可知,感知器可以描述为一个基本的学习结构,例如如果我们需要培养一个德智体美劳全面发展的小孩,每个感知器就可以相当于其中一个课程方面的学习。假如我们需要学习语文,输入x就相当于课文中的每一个词语,权值w相当于我们对词语的熟悉程度,最终对所有词语的加权后我们理解整个句子,再通过激活函数把句子里的重点划出来(激活函数相当于突出关键点),一次基本的学习行为就完成了。
2. 多层感知器神经网络
我们进一步参考生物学上的神经结构,大量的外部信号刺激树突,并传导到神经元,神经元综合外部信号后通过轴突输出。无数神经元一起构成神经中枢,并综合各个神经元轴突的输出信号进行判断。这种传导和判断的过程反复进行,直到形成最终的判断结果,人体根据神经中枢的判断结果对外部刺激做出最终反应,这个过程就是我们的神经网络。
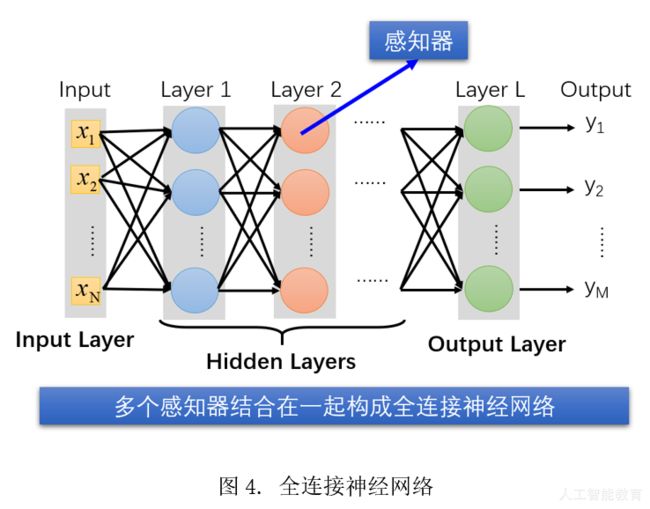
所以,通俗点说,多层神经网络类似于你爸妈想把你培养成德智体美劳全面发展的小孩,所以将多个课程学习的结构叠加在一起,增加你的学习内容,这样第一代鸡娃就产生了。更牛的是,后来科学家们居然证明了,这样叠加的神经网络是一个万能学习器,如果给予足够多的支持,可以学习好任何内容(在足够多的神经元下,可以无限逼近任何问题),于是教育内卷开始了。
3. 神经网络的困惑
神经网络是一个万能逼近器,所以从理论上来说,神经网络能够做任何有监督学习的任务。不过这就好像给一个小朋友一只笔,理论上他就可以画出达芬奇的素描一样,真的只是理论上可以。实际上神经网络在执行复杂任务时并不太给力,就好像每个人都觉得自己的小孩是个天才,但是当你真的教他读书时,你就会知道现实有多么残酷了。我们分析一下内在的原因啊:
(1)样本不足且不满足真实数据的分布。这就好像你家小孩学习就看看书上的内容,别人家的小孩还看了海淀试题和黄冈试题一样,多看题的小孩将会学习的更好。
(2)计算能力不足,难以适应大模型高强度的学习。这就好像你家小孩夏天在家里学习,电扇也没有,空调也没有,还要照看年幼的弟弟妹妹,环境恶劣。而别人家的小孩空调开着,好吃好喝端上来,心无旁骛,自然能够学习得更久。
(3)网络结构存在缺陷,存在梯度消失,陷入局部极值等问题。这就好像你家小孩没有人指导,完全就是按照自己的理解学习,因此很可能对知识的理解是错误的。而别人家的小孩有名师指导,一开始就教授了正确的学习方法,自然能够取得更好的学习效果。
所以家长们知道了,要想小孩学习好,光是逼他学习很多内容是没用的,还要有足够多的外部支持才行。同理,要想神经网络学习好,就和我们中国的鸡娃一样,要大量的数据(买大量的参考书,参加各种补习班),要充足的算力(提供良好的学习环境),优化网络结构和学习算法(找名师教导好的学习方法)。
4. 深度学习诞生
深度神经网络本质上和教育内卷没啥差别,首先外在条件需要大量的数据和充足的算力,然后内在条件在于有良好的学习方法和学习习惯。
(1)更深的网络结构
如何获得好的学习结果,直接的方法当然是增加神经网络的神经元数量以提高学习能力,那么同样在增加神经元数量的前提下,更深(deep)的神经网络和更胖(fat)的神经网络究竟哪个更好呢?

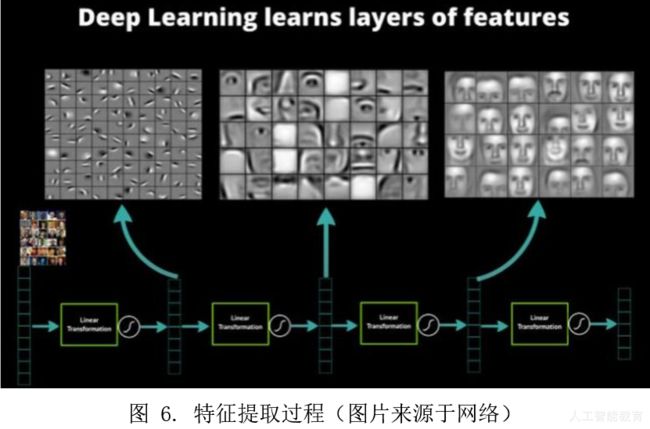
这就好像我们要一个小孩学习,是要他一天学习24个小时还是4天每天学习6小时一样,持续的有规律的学习似乎更加有效率一些。此外,科学家们进一步发现,深度学习的过程,实际上是一个特征逐渐提取和学习的过程,例如下图中为了进行人脸识别,神经网络首先学习了各种像素边缘的特征(左图),然后学习了各类组件的特征(例如眼睛、耳朵、鼻子等,中图),最后将特征组合起来形成了各类人脸特征(右图)。这与人类的学习习惯是非常相似的,因为人们也是从小学到初中到高中逐级依次学习的,学习的内容从简单到负责。深度神经网络的这种逐级的特征学习过程与人类的学习过程类似,所以深度学习更加符合人类的学习习惯。
最后给大家一个具体的概念吧:目前大型的GPT-3模型,模型的尺寸为1750亿参数,使用45TB数据进行训练。

(2)海量的数据驱动
近年来,移动互联网和物联网的发展,使得人们能够通过各种途径获得海量的数据。海量的数据就催生了大规模的数据集和对应的超大规模深度学习模型。下面稍微列几个大规模数据集给大家看看:
ImageNet(包含1400万的图像)
MirFlickr1M(包含100万的图像)
CoPhIR(包含1亿600万的图像 )
Large-Scale Image Annotation using Visual Synset(ICCV 2011)(包含2亿图像 )
这就好像学生还没有学习,我们就先给他准备了全面的学习资料,对于后期高效的学习显然是有利的。
(3)强大的计算平台
超大规模的模型和数据就意味着海量的计算,而海量的计算需要强大的计算平台支持。计算能力是推动深度学习的利器,计算能力越强,同样时间内积累的经验就越多、迭代速度也越快,深度学习的性能也就更高。
高速发展的计算平台(例如GPU平台、TPU平台和超级计算机等)使深度学习有了革命性的进步——计算能力这种对于深度学习的支撑与推动作用是不可替代的。
这就好像一个学生的家庭条件优越,只要他愿意学习,那么外部的物质条件会全力保障他的学习过程,并提高他的学习效率。
5. 深度学习的分类
深度学习发展至今,已经成为人类最接近通用智能的技术之一。传统的人工智能分成三个等级:“计算智能”表示能够实现快速计算、记忆与存储的能力,就好像一个高中生数理化学得特别好;“感知智能”表示识别处理语音、图像、视频的能力,就好像一个大学生能够根据所学的基础知识设计出图像识别系统、翻译系统等;“认知智能”指实现思考、理解、推理和解释的能力,就好像一位博士生能够思考专业问题并给出解释和分析的结论一样。因此人工智能发展的终极目标是赋予机器人类的智慧。目前在深度学习领域有以下几个重要的类别:
(1)破译图像的密码——卷积神经网络
传统的深度神经网络在处理二维或高维数据时(例如图像或视频)数据维度太高,会导致模型巨大,同时模型参数之间存在冗余,泛化能力不高,所以利用卷积把关键特征提取出来进行处理!通俗点说,就是相当于考试之前的复习划重点,把关键的知识点圈出来(通过卷积和池化),这些学习的效率就提高了。

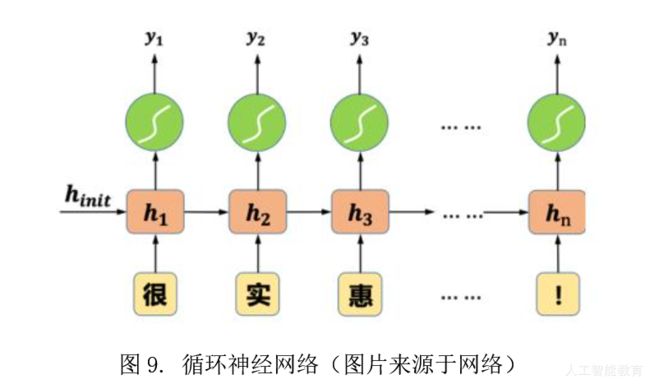
(2)洞悉语言的内涵——循环神经网络
传统的神经网络很少考虑输入信号在时间上的联系,但是现实中很多问题都是一个时序分析问题(例如语言文字分析问题)。例如语文中思考一个词在句子中的含义,那么必然要考虑上下文语境的影响。因此循环神经网络就是在传统神经网络的基础上加入了时序分析的能力,让神经网络能够处理时序分析问题。通俗点说,就是帮助学生将前面所学的知识点和现在所学的知识点放在一起分析,从而在时间上形成系统的知识体系。
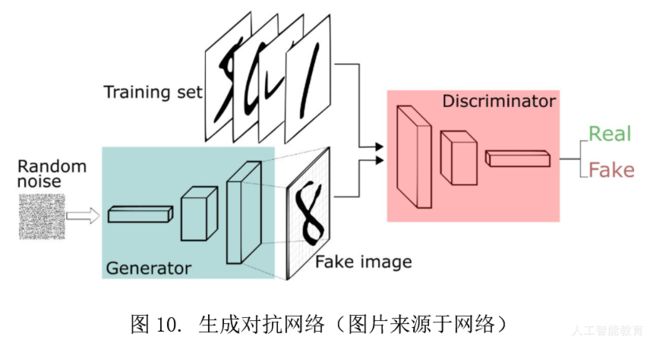
(3)棋逢对手,伯仲之间——生成对抗网络
生成对抗网络是在深度学习中产生的一种全新的学习框架。它包括了一位出题者(生成器)和解题者(判别器)。出题者希望出一道解题者无法解出来的难题,所以他需要不断学习,使得出的题目越来越难,而解题者也在不断学习,尽力解出出题者出的难题,两者不断博弈,出题者的水平越来越高,题目也越来越难,解题者也不断学习,结题的水平也在提高,最终两者共同进步,出题者(生成器)和解题者(判别器)的知识和能力都不断增强。
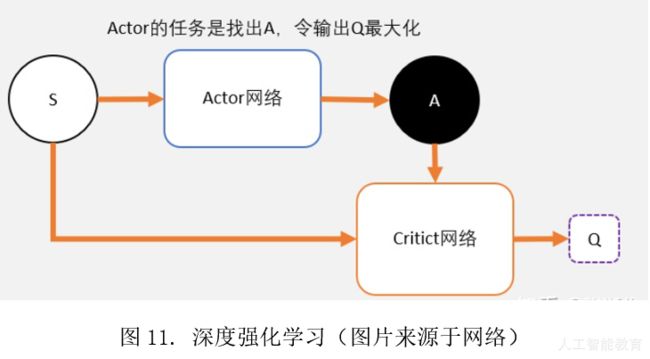
(4)纸上得来终觉浅,绝知此事须躬行——深度强化学习
深度强化学习是强化学习在策略行为上的增强。通过使用深度神经网络作为强化学习的策略体,强化学习能够进行更大规模的学习和更复杂的决策。具体而言,深度强化学习一般包括一名做题者和一名打分者,做题者根据自己的做题方法(策略)来解题获得答案,打分者根据做题者的答案来打分。做题者需要不断学习优化自己的做题方法,从而获得更好的答案并在打分者那里获得高分。通过不断的学习和优化,做题者的做题方法(策略)水平越来越高,获得的分数也就越来越高。
6. 总结
总结一下,深度学习是大数据、大算力和大模型共同演进发展的结果,目前代表了人工智能的最前沿发展方向。深度学习通过加深网络结构来增强网络的学习性能,符合人类的学习习惯,目前包含了卷积神经网络、循环神经网络、生成对抗网络和深度强化学习等四个主要方向。
以上内容是 “每天五分钟,精通深度” 系列教程中的部分精彩摘录,关注“人工智能教育”公众号,观看所有教程,并获得我们精选的机器学习教材和代码,谢谢!
