OpenMMLab 实战营打卡 - 第 三 课
图像分类代码实战与超算平台介绍
目录
一、图像分类工具包MMClassification
1.MMClassification介绍
(1)Python推理API
(2)推理工具&训练工具
(3)使用MIM工具实现训练和测试
2.软件环境
二、北京超级云计算中心
1.中心介绍
2.平台简介
三、花卉分类
1.环境搭建
(1)加载 anaconda ,创建⼀个 python 3.8 的环境。
(2)torch安装
(3)安装mmcv-full模块
(4)安装 openmmlab/mmclassification 模块
(5)总结环境信息
(6)准备shell脚本,将环境预先保存在脚本中。
2.数据集
3.MMCls配置文件
4.提交计算
总结
前言
第三堂课:计算机视觉之图像分类代码教学,你想了解的环境配置和代码实操都在链接里啦!第三堂课程链接:3 图像分类代码实战与超算平台介绍_哔哩哔哩_bilibili
一、图像分类工具包MMClassification
1.MMClassification介绍
MMClassification实际上是专门针对图像分类做的代码库,所有代码都放在github上面(代码仓库:open-mmlab/mmclassification: OpenMMLab Image Classification Toolbox and Benchmark (github.com)),也有对应的文档(文档教程:Welcome to MMClassification’s documentation! — MMClassification 0.25.0 documentation)。MMClassification提供丰富的模型,也支持很多数据集以及训练的策略,同时提供大量应用的工具以及预训练的模型。我们可以拿一些预训练的模型做推理的任务,比如实现预测图像的信息,集成到系统。也可以定义自己的网络或者数据,基于MMClassification里面的工具或策略去训练自己的模型。当然MMClassification还有其他的辅助功能,比如包括对模型可解释性的分析。整个代码库遵循MMClassification体系的模块化设计,可以按照模块找寻相应代码去定制、debug,可以抠代码出来放入自己的代码库。

(1)Python推理API
一行代码可以下载一个预训练的模型和权重$ mim download mmcls --config mobilenet-v2_8xb32_in1k --dest,然后写几行Python实现简单的图像分类的推理,如下图所示会告诉我们图像内容是什么、对应预测的概率。
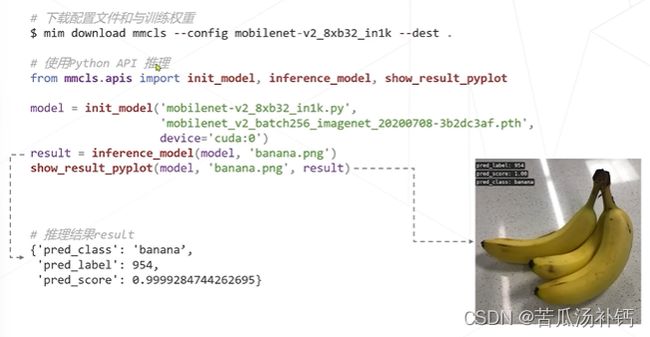
(2)推理工具&训练工具
推理工具和训练工具都需要源码安装。
推理工具使用说明:Getting Started — MMClassification 0.25.0 documentation
#单张图推理
python demo/image_demo.py ${IMAGE_FILE} ${CONFIG_FILE} ${CHECKPOINT_FILE}
#在测试集上测试
#单卡
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--metrics ${METRICS}] [--out
${RESULT_FILE}]
#多机多卡
./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [--metrics ${METRICS}] [--out
${RESULT_FILE}]训练工具使用说明:Getting Started — MMClassification 0.25.0 documentation
#单卡训练
python tools/train.py ${CONFIG_FILE} [optional arguments]
#单机、多机多卡训练
./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments]
#使用任务调度器 Slurm 启动任务
[GPUS=${GPUS}] ./tools/slurm_train.sh ${PARTITION} ${JOB_NAME} ${CONFIG_FILE} ${WORK_DIR}
#从 checkpoint 恢复训练
增加 --resume-from ${CHECKPOINT_FILE} 参数
(3)使用MIM工具实现训练和测试
MIM 为所有 OpenMMLab 工具提供了统一的命令行接口。
下载配置文件和预训练模型:
mim download mmcls --config mobilenet-v2_8xb32_in1k --dest .
训练(支持单卡、多卡、Slurm任务管理器)
mim train mmcls {参数同 mmcls 自己的 train.py}
mim train mmcls {参数同 mmcls 自己的 train.py} -G 4 –g 4 –p ${PARTITION} --launcher slurm
测试
mim test mmcls {参数同 mmcls 自己的 test.py} --gpus 4 --launcher pytorch
2.软件环境
通常这个软件的环境底层是我们的硬件,可以支持在CPU、GPU,然后操作系统支持Windows和Linux,基于python和pytorch(一定要安装)。OpenMMLab自己的东西主要是最底层的基础库MMCV,基于MMCV搭建了不同任务的库,以及MIM工具(用于管理)三部分。
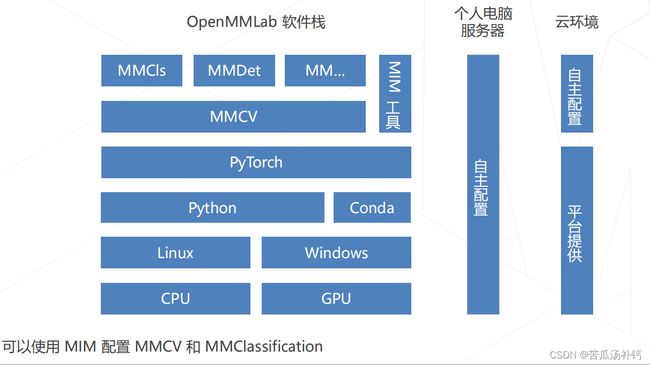
二、北京超级云计算中心
1.中心介绍
北京超级云计算中心(简称“北京超算”),2011年11月在北京怀柔综合性国家科学中心—怀柔科学城奠基成立,是由北京市人民政府主导、院市共建的“北京超级云计算和国家重要信息化基础平台”。是一家面向科学计算、工业仿真、气象海洋、新能源、生物医药、人工智能等重点行业应用领域,提供随需供应的超级云计算服务提供商。
北龙超云负责运营的北京超级云计算中心于2020年、2021年、2022年连续三年获得中国HPCTOP100排行榜“通用CPU算力性能第一名”。同时在2021年AI Perf5O0榜单中,北京超级云计算中心共计10套AI算力系统上榜,获得总量份额第一名。

2.平台简介
北京超算网站:北京超级云计算中心 (blsc.cn)
下载客户端并登录,可以看见云桌面有许多应用。快传,平台与本地的一个传输通道。SSH,在Linux上使用的一种终端工具。

三、花卉分类
1.环境搭建
打开北京超算SSH,根据 mmclassification 的环境要求,需要⽤ anaconda、cuda、gcc 等基础环境模块。在 N26分区(因为我的超算账号在26分区,也可使用30分区),可以使⽤ module avail 命令可以使⽤模块信息。

(1)加载 anaconda ,创建⼀个 python 3.8 的环境。
由于我在26分区,所以anaconda只有2020.11这个版本,人工你是在30分区那么你还可以选择加载anaconda2021.05。
# 加载 anaconda/2020.11
module load anaconda/2020.11
# 创建 python=3.8 的环境
conda create --name opennmmlab_mmclassification python=3.8
# 激活环境
source activate opennmmlab_mmclassification
激活环境后,安装torch。
(2)torch安装
torch 参考官⽹需求。注意在 RTX3090 的GPU上,cuda 版本需要 ≥ 11.1 。 如下安装的 torch 是 1.10.0+cu111 。
# 加载 cuda/11.1
module load cuda/11.1
# 安装 torch
pip install torch==1.10.0+cu111 torchvision==0.11.0+cu111 torchaudio==0.10.0 -f
https://download.pytorch.org/whl/torch_stable.html使⽤ pip 安装的torch 不包括 cuda,所以需要使⽤ module 加载 cuda/11.1 模块。安装时间根据不同网络情况有所不同。
(3)安装mmcv-full模块
mmcv-full 模块安装时候需要注意 torch 和 cuda 版本,参考这⾥ 。
pip install mmcv-full==1.7.0 -f
https://download.openmmlab.com/mmcv/dist/cu111/torch1.10/index.html(4)安装 openmmlab/mmclassification 模块
建议通过下载编译的⽅式进⾏安装;安装该模块需要 gcc ≥ 5, 使⽤ module 加载⼀个 gcc ,例如 module load gcc/7.3 。
# 加载 gcc/7.3 模块
module load gcc/7.3
# git 下载 mmclassification 代码
git clone https://github.com/open-mmlab/mmclassification.git
# 编译安装
cd mmclassification
pip install -e .
(5)总结环境信息
可以使⽤ module list 查看当前环境中加载的依赖模块。
$ module list
(6)准备shell脚本,将环境预先保存在脚本中。
#!/bin/bash
# 加载模块
module load anaconda/2020.11
module load cuda/11.1
module load gcc/7.3
# 激活环境
source activate opennmmlab_mmclassification2.数据集
flower 数据集包含 5 种类别的花卉图像:雏菊 daisy 588张,蒲公英 dandelion 556张,玫瑰 rose 583张,向⽇葵 sunflower 536张,郁⾦⾹ tulip 585张。
3.MMCls配置文件
构建配置⽂件可以使⽤继承机制。模型配置文件,可以使用任何模型,数据配置,学习率,加载预训练模型,微调。
4.提交计算
总结
以上就是今天笔记打卡的内容,本文仅仅简单介绍了图像分类代码实战和北京超算的使用。