LevelDB简介
LevelDB简介
-
- 综述
- leveldb整体架构
- 提供接口
-
- db.h
- 技术
-
- memtable
- WAL
- sstable
- Manifest
- cache
- LRU cache
-
- LRU的优缺点
- filter
- levelDB初始化
- compaction
-
- compaction的触发
- 参考链接
综述
level是使用lsm tree作为单机数据结构的存储引擎
内存中的 MemTable 写满后,会转换为 Immutable MemTable,然后被后台线程 compact 成按 key 有序存储的 SSTable(顺序写)。 SSTable 按照数据从新到旧被组织成多个层次(上层新下层旧),点查询(Get)的时候从上往下一层层查找,所以 LevelDB 的读操作可能会有多次磁盘 IO(LevelDB 通过 table cache、block cache 和 bloom filter 等优化措施来减少读操作的 I/O 次数)。 后台线程的定期 compaction 负责回收过期数据和维护每一层数据的有序性。在数据局部有序的基础上,LevelDB 实现了数据的(全局)有序遍历。
leveldb整体架构
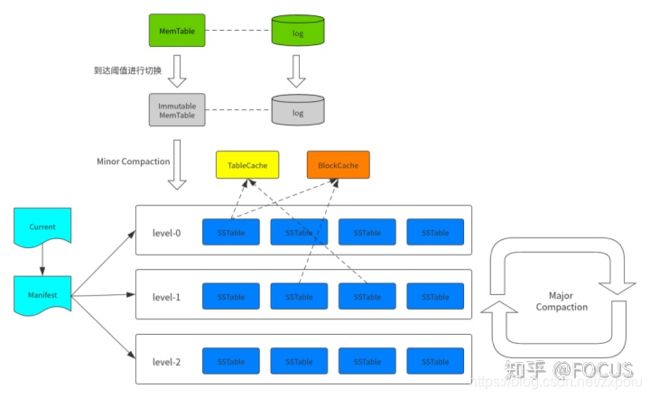
MemTable:内存数据结构,具体实现是 SkipList。 接受用户的读写请求,新的数据会先在这里写入。Immutable MemTable:当 MemTable 的大小达到设定的阈值后,会被转换成 Immutable MemTable,只接受读操作,不再接受写操作,然后由后台线程 flush 到磁盘上 —— 这个过程称为 minor compaction。Log:数据写入 MemTable 之前会先写日志,用于防止宕机导致 MemTable 的数据丢失。一个日志文件对应到一个 MemTable。SSTable:Sorted String Table。分为 level-0 到 level-n 多层,每一层包含多个 SSTable,文件内数据有序。除了 level-0 之外,每一层内部的 SSTable 的 key 范围都不相交。Manifest:Manifest 文件中记录 SSTable 在不同 level 的信息,包括每一层由哪些 SSTable,每个 SSTable 的文件大小、最大 key、最小 key 等信息。Current:重启时,LevelDB 会重新生成 Manifest,所以 Manifest 文件可能同时存在多个,Current 记录的是当前使用的 Manifest 文件名。TableCache:TableCache 用于缓存 SSTable 的文件描述符、索引和 filter。BlockCache:SSTable 的数据是被组织成一个个 block。BlockCache 用于缓存这些 block(解压后)的数据。
提供接口
include
└── leveldb
├── c.h => c binding
├── cache.h => cache接口
├── comparator.h => 比较器接口
├── db.h => DB接口
├── env.h => 为跨平台准备的env接口
├── filter_policy.h => fliter策略,用于缓存,请看到文档及相应实现
├── iterator.h => 迭代器,用于遍历数据库中存储的数据
├── options.h => 包含控制数据库的Options,控制读的WriteOptions,ReadOptions
├── slice.h => Slice的接口
├── status.h => leveldb中大多接口返回的Status接口
├── table.h => immutable接口
├── table_builder.h => 用于创建table的构建器接口
└── write_batch.h => 使多个写操作成为原子写的接口
db.h
db.h是使用leveldb时最经常include的头文件.在这个头文件中提供了DB的接口的定义,也是我们需要的部分.在db.h中,定义了Snapshot,Range,DB三个接口.Range为一个Slice对,定义了[start,end).符合C++的习惯.Snapshot为DB的某个特定状态.由于其只读,因此多线程访问并不需要锁.DB则提供了经常使用的几个方法:
class LEVELDB_EXPORT DB {
public:
// Open the database with the specified "name".
// Stores a pointer to a heap-allocated database in *dbptr and returns
// OK on success.
// Stores nullptr in *dbptr and returns a non-OK status on error.
// Caller should delete *dbptr when it is no longer needed.
static Status Open(const Options& options, const std::string& name,
DB** dbptr);
DB() = default;
DB(const DB&) = delete;
DB& operator=(const DB&) = delete;
virtual ~DB();
// Set the database entry for "key" to "value". Returns OK on success,
// and a non-OK status on error.
// Note: consider setting options.sync = true.
virtual Status Put(const WriteOptions& options, const Slice& key,
const Slice& value) = 0;
// Remove the database entry (if any) for "key". Returns OK on
// success, and a non-OK status on error. It is not an error if "key"
// did not exist in the database.
// Note: consider setting options.sync = true.
virtual Status Delete(const WriteOptions& options, const Slice& key) = 0;
// Apply the specified updates to the database.
// Returns OK on success, non-OK on failure.
// Note: consider setting options.sync = true.
virtual Status Write(const WriteOptions& options, WriteBatch* updates) = 0;
// If the database contains an entry for "key" store the
// corresponding value in *value and return OK.
//
// If there is no entry for "key" leave *value unchanged and return
// a status for which Status::IsNotFound() returns true.
//
// May return some other Status on an error.
virtual Status Get(const ReadOptions& options, const Slice& key,
std::string* value) = 0;
// Return a heap-allocated iterator over the contents of the database.
// The result of NewIterator() is initially invalid (caller must
// call one of the Seek methods on the iterator before using it).
//
// Caller should delete the iterator when it is no longer needed.
// The returned iterator should be deleted before this db is deleted.
virtual Iterator* NewIterator(const ReadOptions& options) = 0;
// Return a handle to the current DB state. Iterators created with
// this handle will all observe a stable snapshot of the current DB
// state. The caller must call ReleaseSnapshot(result) when the
// snapshot is no longer needed.
virtual const Snapshot* GetSnapshot() = 0;
// Release a previously acquired snapshot. The caller must not
// use "snapshot" after this call.
virtual void ReleaseSnapshot(const Snapshot* snapshot) = 0;
// DB implementations can export properties about their state
// via this method. If "property" is a valid property understood by this
// DB implementation, fills "*value" with its current value and returns
// true. Otherwise returns false.
//
//
// Valid property names include:
//
// "leveldb.num-files-at-level" - return the number of files at level ,
// where is an ASCII representation of a level number (e.g. "0").
// "leveldb.stats" - returns a multi-line string that describes statistics
// about the internal operation of the DB.
// "leveldb.sstables" - returns a multi-line string that describes all
// of the sstables that make up the db contents.
// "leveldb.approximate-memory-usage" - returns the approximate number of
// bytes of memory in use by the DB.
virtual bool GetProperty(const Slice& property, std::string* value) = 0;
// For each i in [0,n-1], store in "sizes[i]", the approximate
// file system space used by keys in "[range[i].start .. range[i].limit)".
//
// Note that the returned sizes measure file system space usage, so
// if the user data compresses by a factor of ten, the returned
// sizes will be one-tenth the size of the corresponding user data size.
//
// The results may not include the sizes of recently written data.
virtual void GetApproximateSizes(const Range* range, int n,
uint64_t* sizes) = 0;
// Compact the underlying storage for the key range [*begin,*end].
// In particular, deleted and overwritten versions are discarded,
// and the data is rearranged to reduce the cost of operations
// needed to access the data. This operation should typically only
// be invoked by users who understand the underlying implementation.
//
// begin==nullptr is treated as a key before all keys in the database.
// end==nullptr is treated as a key after all keys in the database.
// Therefore the following call will compact the entire database:
// db->CompactRange(nullptr, nullptr);
virtual void CompactRange(const Slice* begin, const Slice* end) = 0;
};
技术
memtable
MemTable,顾名思议,就是内存表。每个 LevelDB 实例最多会维护两个 MemTable: mem_ 和 imm_。mem_ 可以读写,imm_ 只读。LevelDB 的 MemTable 的主要功能是将内部编码、内存分配(Arena)和 SkipList 封装在一起。
在 LevelDB 中,最新写入的数据都会保存到 mem_ 中。当 mem_ 的大小超过 write_buffer_size 时,LevelDB 就会将其切换成 imm_,并生成新的 mem_。 LevelDB 的后台线程会将 imm_ compact 成 SSTable 保存在磁盘上。 如果前台的写入速度很快,有可能出现 mem_ 的大小已经超过 write_buffer_size,但是前一个 imm_ 还没有被 compact 到磁盘上,无法切换 MemTable,此时就会出现 stall write(阻塞写请求)。
WAL
为了防止宕机导致数据丢失,在将数据写入 MemTable 之前,会先将数据持久化到 log 文件中。
LevelDB采用这种定长块的方式保存日志呢。其明显的好处是:当日志文件发生数据损坏的时候,这种定长块的模式可以很简单地跳过有问题的块,而不会导致局部的错误影响到整个文件。
目前 LevelDB 没有对日志进行压缩。
sstable
SSTable 全称 Sorted String Table,顾名思义,里面的 key-value 都是有序保存的。除了两个 MemTable,LevelDB 中的大部分数据是以 SSTable 的形式保存在外存上。sstable是只读的,只有compaction才会更改其内容
在一个 SSTable 中,文件末尾的 Footer 是定长的,其他数据都被划分成一个个变长的 block:index block、metaindex block、meta blocks、data blocks。
meta blocks:目前 LevelDB 中只有一个 meta block,保存的是这个 SSTable 中的 key 组成的 bloom filter。布隆过滤器Data Block:存储的是实际的 key-value 数据。
levelDB SStable中的block使用了前缀压缩。前缀压缩利用了 key 的有序性(前缀相同的有序 key 会聚集在一起)对 key 进行压缩,每个 key 与前一个 key 相同的前缀部分可以不用保存。读取的时候再根据规则进行解码即可。
Manifest
Manifest 文件保存了整个 LevelDB 实例的元数据,比如:每一层有哪些 SSTable。LevelDB 用 VersionEdit 来表示一次元数据的变更。Manifest 文件保存 VersionEdit 序列化后的数据。
cache
根据功能的不同,LevelDB 中有两种 cache:
- Block cache:缓存解压后的 data block,可以加快热数据的查询。
- Table cache:缓存打开的 SSTable 文件描述符和对应的 index block、meta block 等信息。
在 LevelDB 中,block cache 和 table cache 都是基于 ShardedLRUCache 实现的。
LRU cache
LevelDB 的 LRUCache 的实现由一个哈希表和两个链表组成:
- 链表
lru_:维护 cache 中的缓存对象的使用热度。数据每次被访问的时候,都会被插入到这个链表最新的地方。 lru_->next 指向最旧的数据, lru_->prev 指向最新的数据。当 cache 占用的内存超过限制时,则从 lru_->next 开始清理数据。 - 链表
in_use_:维护 cache 中有哪些缓存对象被返回给调用端使用。这些数据不能被淘汰。 - 哈希表
table_:保存所有 key -> 缓存对象,用于快速查找数据。
LRUCache 的 Insert 和 Lookup 的时间复杂度都是 O(1)。
LRU的优缺点
LRU 是一种常用的缓存淘汰策略,因为大部分情况下,数据的访问都是具有局部性的——最近访问过的数据,短时间内还被访问的概率比较大;而比较久没被访问的数据,短时间内会被访问的概率比较小。
但是当热点数据比较集中时,LRU 的缓存命中率比较高。但是在某些场景下,LRU 的缓存命中率会急剧下降,比如批量遍历。
- LevelDB 在读参数 ReadOptions 提供了一个参数 fill_cache ,让上层控制是否要将 data block 放入到 block cache。
- MySQL 的 InnoDB 的 LRU 缓存实现为了避免扫描操作污染 cache,采用了两级的 LRU cache。数据会先进入第一级 cache,一段时间之后还有访问再放到第二级 cache。
filter
LevelDB 可以设置通过 bloom filter 来减少不必要的读 I/O 次数。
levelDB初始化
一个 LevelDB 实例初始化的主要任务包括:
- 从 Manifest 文件恢复各个 level 的 SSTable 的元数据。
- 根据 log 文件恢复 MemTable。
- 恢复 last_sequence_、next_file_numbe_等元信息。
compaction
compaction的触发
除了从外部调用 CompactRange,LevelDB 有几种情况会自动触发 compaction:
- 当 MemTable 的大小达到阈值时,进行 MemTable 切换,然后需要将 Immutable MemTable 刷到外存上 —— 一般称之为
Minor Compaction。 - 当 level-n 的 SSTable 超过限制,level-n 和 level-n+1 的 SSTable 会进行 compaction —— 一般称之为
Major Compaction。- level-0 是通过 SSTable 的数量来判断是否需要 compaction。
- level-n(n > 0) 是通过 SSTable 的大小来判断是否需要 compaction。

参考链接
- LevelDB 完全解析(0):基本原理和整体架构本文内容很多参考了这个专栏,两张图片也摘自此专栏。系列文章,讲的很详细
- LevelDB 完全解析(8):读操作之 Get
- leveldb接口
- leveldb接口概览
- LevelDB library documentation基本使用方法
- leveldb iterator 的 Prev 究竟比 Next 差在哪?MemTable是skiplist,next是O(1),prev是O(log(N)),sstable是index_block+data_block,每次反向遍历都需要重新定位index
- LevelDB 之 Compaction