MATLAB机器学习方法之朴素贝叶斯算法
朴素贝叶斯分类算法的核心算法是:
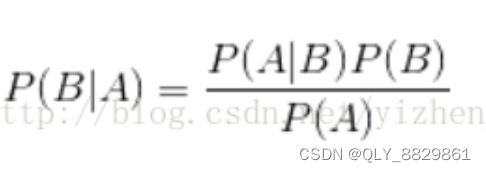
或

而如果所有特征都相互独立的话,P(特征|类别k)可以看作:
P(特征1|类别k)*P(特征2|类别k)*P(特征3|类别k)*……*P(特征n|类别k)
那么分别计算P(特征|类别1)、P(特征|类别2)、P(特征|类别3)……P(特征|类别n),取他们之中的最大值即为待分类样本所归附的类别。
MATLAB代码实现:
%朴素贝叶斯算法
train=[1,1,4;1,4,2;3,4,1;2,2,3;1,3,1;2,3,4;3,3,1;2,3,2];%8组训练数据,三个
%属性,第一个分三级,后面两个均分四级。
trainclass=[2 1 1 2 1 2 2 2];%分组
test=[3,3,1];%测试数据组
c=0;
classnum=zeros(1,length(unique(trainclass)));%创建记录每个组分别出现次数的矩阵
a=unique(trainclass);%a记录组号,length(a)记录组数
p=zeros(length(classnum),length(test));%创建概率矩阵
for i=1:length(trainclass)
j=trainclass(i);
classnum(j)=classnum(j)+1;
end%记录每组出现的次数
for k=1:length(test)
for j=1:length(a)
for i=1:length(trainclass)
if(trainclass(i)==a(j))
if(train(i,k)==test(k))
c=c+1;
p(j,k)=c/classnum(j);
end
end
end
c=0;
end
end%计算所有的概率
p1=ones(1,length(a));%创建最终概率的矩阵
for i=1:length(a)
p1(i)=classnum(i)/length(trainclass);
end%先计算p(类别)
for i=1:length(classnum)
for j=1:length(test)
p1(i)=p1(i)*p(i,j);
end
end%由于两个式子的p(特征)一致,故分母不用参与计算
m=max(p1);
for i=1:length(classnum)
if(m==p1(i))
break;
end
end%找出最大概率对应的组别
fprintf('该测试数据属于类 %d\n',i);
%code end
其合理性可以用一个实例说明:路上走过来一个黑人,旁边人问你他是哪里来的,你十有八九回答从非洲来的,这是因为黑人中非洲人的比例最高。
此算法的特点:
(1)简单、高效、健壮。
(2)相关属性可能会降低朴素贝叶斯分类器的性能,因为对这些属性,条件独立的假设已不成立。