图像重合度算法实验
目录
一:直方图算法
二,hash算法
三 ssim算法
一:直方图算法
目录
一:直方图算法
思想:先把两张图片切割,然后让第二张图片的切片去对比第一张图片的切片。
两张图片如下:


代码实践:image2Comparison.py
# -*- coding: utf-8 -*-
import cv2
import numpy as np
from skimage.metrics import structural_similarity as compare_ssim
import matplotlib.pyplot as plt
# 通过得到RGB每个通道的直方图来计算相似度
def classify_hist_with_split(image1, image2):
# 将图像分离为RGB三个通道,再计算每个通道的相似值
arr_image1 = cv2.split(image1)
arr_image2 = cv2.split(image2)
sub_data = 0
npart = 10 #纵向分割
x_arr = [i for i in range(npart)]#np.arange(npart)
y1_arr = []
y2_arr = []
y3_arr = []
wp1,wp2 = image1.shape[1]/npart,image2.shape[1]/npart
h_img2 = arr_image2[0][:,0:round(wp2)] #第二张图片的第一通道的第1片
for i in range(0,npart): #循环对比第一张图片
h_img1 = arr_image1[0][:,round(wp1*i):round(wp1*(i+1))]
idata = calculate(h_img2,h_img1)
y1_arr.append(idata)
print(idata)
print("-----------")
max1_index = y1_arr.index(max(y1_arr))
h_img2 = arr_image2[1][:,0:round(wp2)] #第二张图片的第二通道的第1片
for i in range(0,npart): #循环对比第一张图片
h_img1 = arr_image1[1][:,round(wp1*i):round(wp1*(i+1))]
idata = calculate(h_img2,h_img1)
y2_arr.append(idata)
print(idata)
print("-----------")
max2_index = y2_arr.index(max(y2_arr))
h_img2 = arr_image2[2][:,0:round(wp2)] #第二张图片的第三通道的第1片
for i in range(0,npart): #循环对比第一张图片
h_img1 = arr_image1[2][:,round(wp1*i):round(wp1*(i+1))]
idata = calculate(h_img2,h_img1)
y3_arr.append(idata)
print(idata)
max3_index = y3_arr.index(max(y3_arr))
#plt.plot(x_arr,y1_arr,"r:x")
plt.plot(x_arr,y1_arr,"r:x",
x_arr,y2_arr,"b-D",
x_arr,y3_arr,"y--_")
plt.savefig(r"c123.png",dpi=75)
plt.show()
print("-----------")
print("%d,%d,%d" % (max1_index,max2_index,max3_index))
sub_data = (max1_index+max2_index+max3_index+3)/(npart*3)
return sub_data
# 计算单通道的直方图的相似值
def calculate(image1, image2):
hist1 = cv2.calcHist([image1], [0], None, [256], [0.0, 255.0])
hist2 = cv2.calcHist([image2], [0], None, [256], [0.0, 255.0])
# 计算直方图的重合度
degree = 0
for i in range(len(hist1)):
if hist1[i] != hist2[i]:
degree = degree + (1 - abs(hist1[i] - hist2[i]) / max(hist1[i], hist2[i]))
else:
degree = degree + 1
degree = degree / len(hist1)
return degree
def main():
img1 = cv2.imread(r'D:\data\real\Thumbnails\0.JPG')
img2 = cv2.imread(r'D:\data\real\Thumbnails\1.JPG')
n = classify_hist_with_split(img1, img2)
print('三色直方图算法相似度:', n)
if __name__=="__main__":
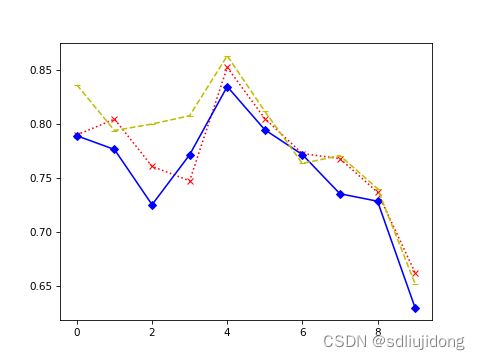
main()运行结果(npart=10):三色直方图算法相似度: 0.5
运行结果绘图:
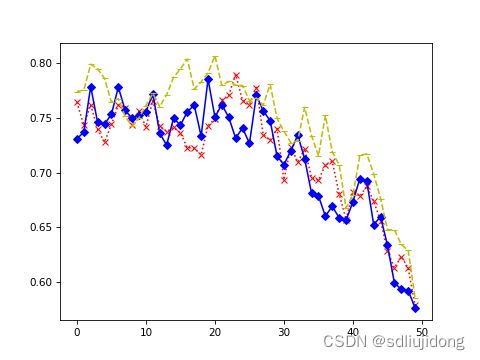
运行结果(npart=50时):三色直方图算法相似度: 0.43333333333333335
运行结果图片:
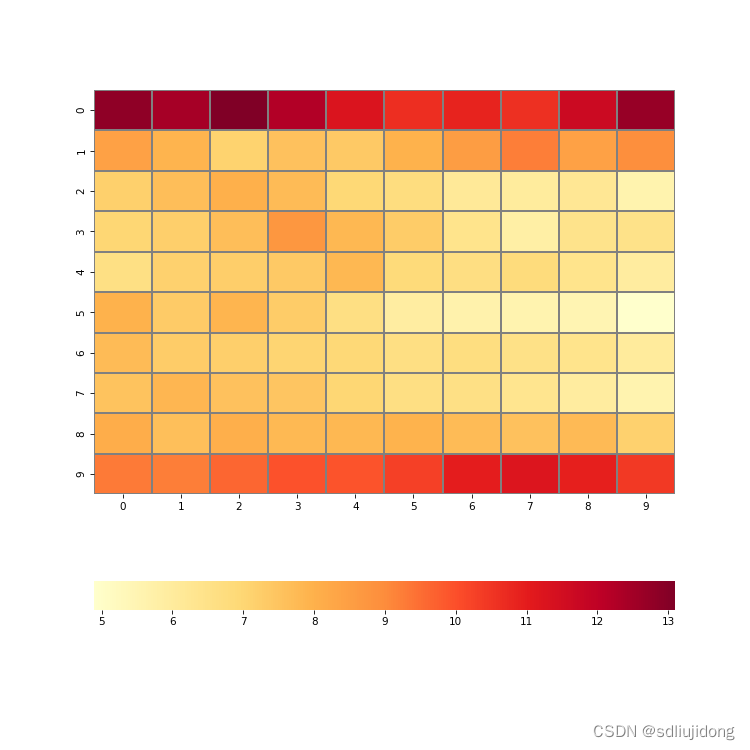
二,hash算法
思想:分别切割两个图片(10x10)
代码(平均hash算法):
# -*- coding: utf-8 -*-
import cv2
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
def classify_with_split(image1, image2):
npart = 10
#每张图片分割成10x10份
hd1,wd1 = image1.shape[0]/npart,image1.shape[1]/npart
hd2,wd2 = image2.shape[0]/npart,image2.shape[1]/npart
#分别算每张割片的hash值
hash_arr1 = np.zeros((npart,npart,100))
hash_arr2 = np.zeros((npart,npart,100))
for i2 in range(0,npart):
for j2 in range(0,npart):
p_img2 = image2[round(i2*hd2):round((i2+1)*hd2) , round(wd2*j2):round(wd2*(j2+1))]
hash_arr2[i2,j2] = pHash(p_img2)
for i1 in range(0,npart):
for j1 in range(0,npart):
p_img1 = image1[round(i1*hd1):round((i1+1)*hd1) , round(wd1*j1):round(wd1*(j1+1))]
hash_arr = pHash(p_img1)
print("[%d,%d]=%s" % (i1,j1,hash_arr))
hash_arr1[i1,j1] = hash_arr
#第二张图片的第1张割片,去匹配第一张图片的所有割片,并创建热力图
match_arr = np.zeros((npart,npart))
# for x in np.nditer(hash_arr1):
# match_arr.append(cmpHash(x,hash_arr2[0][0]))
# match_arr = match_arr.reshape(npart,npart)
for i in range(len(hash_arr1)):
for j in range(len(hash_arr1[i])):
match_arr[i,j]=cmpHash(hash_arr1[i][j],hash_arr2[0][0])
print(match_arr)
#绘图
f, ax = plt.subplots(figsize=(10, 10))
sns.heatmap(match_arr, ax=ax,cmap='YlOrRd',linewidths=0.1,linecolor="grey",cbar_kws={"orientation":"horizontal"})
plt.savefig(r"hash.png",dpi=75)
plt.show()
pos_max = np.unravel_index(np.argmax(match_arr),match_arr.shape)
rate = (npart-pos_max[0])*(npart-pos_max[1])/(npart * npart)
return rate
# Hash值对比
def cmpHash(hash1, hash2,shape=(10,10)):
n = 0
# hash长度不同则返回-1代表传参出错
if len(hash1)!=len(hash2):
return -1
# 遍历判断
for i in range(len(hash1)):
# 相等则n计数+1,n最终为相似度
if hash1[i] == hash2[i]:
n = n + 1
return n/(shape[0]*shape[1])
def main():
img1 = cv2.imread(r'D:\data\real\Thumbnails\0.JPG')
img2 = cv2.imread(r'D:\data\real\Thumbnails\1.JPG')
n = classify_with_split(img1, img2)
print('hash算法相似度:', n)
if __name__=="__main__":
main()运行结果:hash算法相似度: 0.45
运行图片: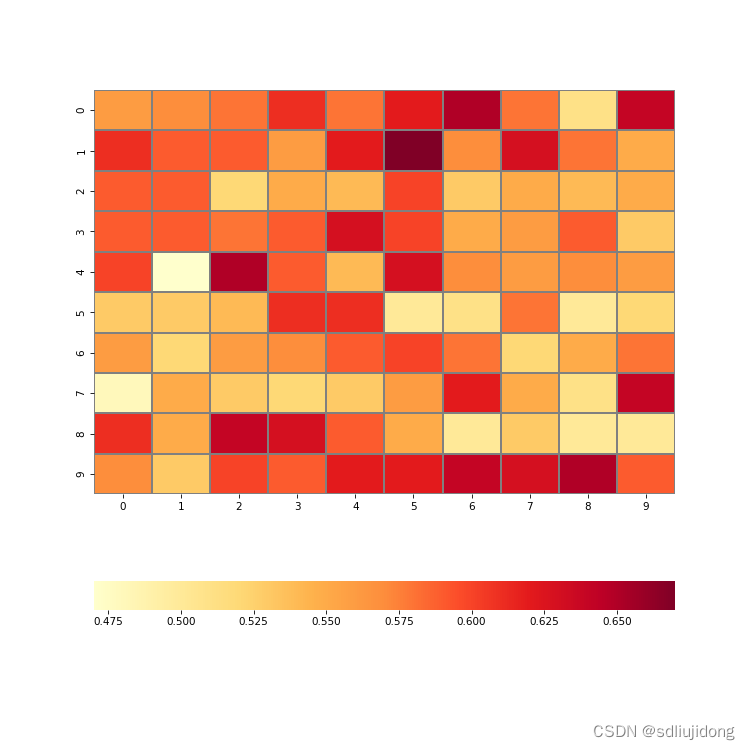
三 ssim算法
思想:同上
代码:
import cv2
import numpy as np
from skimage.metrics import structural_similarity as compare_ssim
import matplotlib.pyplot as plt
import seaborn as sns
def classify_with_split(image1, image2):
npart = 10
#每张图片分割成10x10份
hd1,wd1 = image1.shape[0]/npart,image1.shape[1]/npart
hd2,wd2 = image2.shape[0]/npart,image2.shape[1]/npart
#分别算每张割片的hash值
hash_arr1 = np.zeros((npart,npart,100))
hash_arr2 = np.zeros((npart,npart,100))
#第二张图片的第1张割片,去匹配第一张图片的所有割片,并创建热力图
match_arr = np.zeros((npart,npart))
for i1 in range(0,npart):
for j1 in range(0,npart):
p_img1 = image1[round(i1*hd1):round((i1+1)*hd1) , round(wd1*j1):round(wd1*(j1+1))]
p_img2 = image2[0:round(hd2) , 0:round(wd2)]
ssimRate = compare_ssim(p_img1, p_img2, multichannel=True)
match_arr[i1,j1]=ssimRate
print("[%d,%d]vs[%d,%d]=%.2f"%(0,0,i1,j1,ssimRate))
print(match_arr)
#绘图
f, ax = plt.subplots(figsize=(10, 10))
sns.heatmap(match_arr, ax=ax,cmap='YlOrRd',linewidths=0.1,linecolor="grey",cbar_kws={"orientation":"horizontal"})
plt.savefig(r"ssim.png",dpi=75)
plt.show()
pos_max = np.unravel_index(np.argmax(match_arr),match_arr.shape)
print(pos_max)
rate = (npart-pos_max[0])*(npart-pos_max[1])/(npart * npart)
return rate
def main():
img1 = cv2.imread(r'D:\data\real\Thumbnails\0.JPG')
img2 = cv2.imread(r'D:\data\real\Thumbnails\1.JPG')
n = classify_with_split(img1, img2)
print('ssim算法相似度:', n)
if __name__=="__main__":
main()运行结果:hash算法相似度: 0.8
运行结果图片:
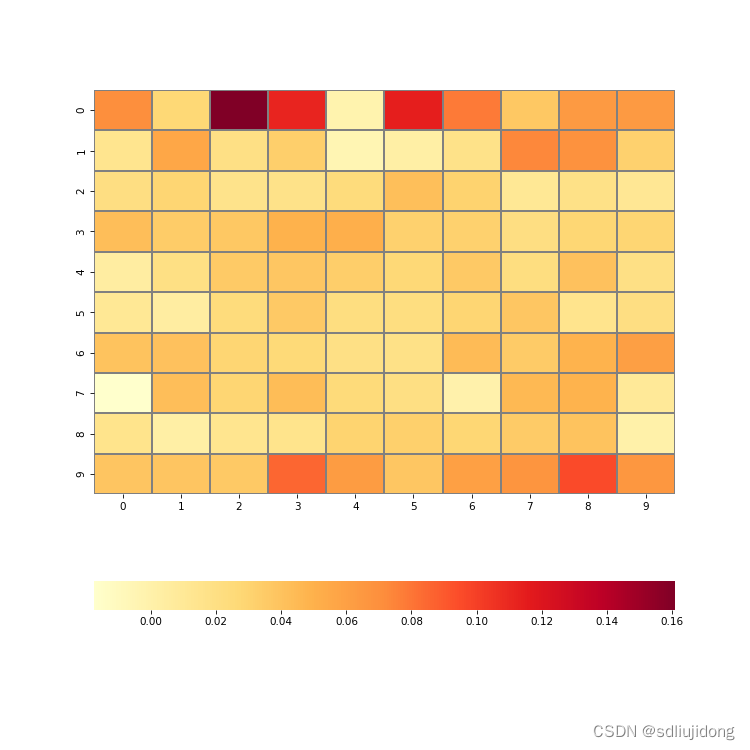
四:PSNR算法
代码:
def PSNR(img1, img2):
mse = np.mean((img1/255. - img2/255.) ** 2)
if mse == 0:
return 100
PIXEL_MAX = 1
return 20 * math.log10(PIXEL_MAX / math.sqrt(mse))运行结果:
(0, 2)
目录
一:直方图算法
二,hash算法
三 ssim算法
四:PSNR算法
hash算法相似度: 0.8
运行结果图: