机器学习名称解释
目录
监督学习
非监督学习
半监督学习
强化学习
假设空间
模型
策略
1.经验风险函数:
常用的损失函数(代价函数):
2.结构风险函数:
算法:
训练误差:
测试误差:
过拟合:
正则化:
Lp范数
泛化能力
泛化误差
泛化误差上界
模型评估方法
留出法
分层采样:保留类别比例的采样方法
交叉验证
1.S折交叉验证
2.留一交叉验证
3.留存交叉验证
自助法
生成模型
判别模型
分类问题
标注问题
回归问题
聚类
错误率
精度
查准率(精确率)、查全率(召回率)、F1
F1度量
Fβ度量
ROC与AUC
偏差与方差
监督学习
利用已知类别或结果的样本对模型进行学习的过程
学习过程中需要注意:权衡偏差和方差
非监督学习
半监督学习
强化学习
假设空间
输入空间到输出空间的映射的集合
模型属于假设空间
学习的目的在于找到最好的映射,即模型
统计学习三要素:模型、策略、算法
模型
指根据数据学习出来的模型,如贝叶斯的条件概率、决策树、线性回归的的系数等
策略
指学习的准则,即选择使用的经验风险函数或结构风险函数(一般通过选择的损失函数求和计算出来)
1.经验风险函数:
指模型f关于训练数据集的平均损失,其平均损失由选择的损失函数得到
期望损失函数公式:
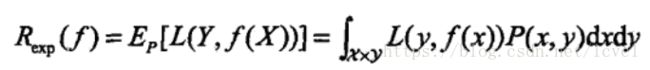
因为x,y联合分布无法直接得出,所以使用经验风险近似期望损失
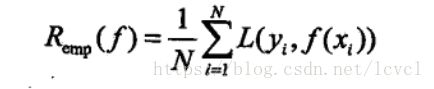
L代表所选择的损失函数
常用的损失函数(代价函数):

2.结构风险函数:
防止出现过拟合情况,引入正则化项的经验风险函数
结构风险函数公式:

![]() 为正则化项,一般为系数的L1范数(会使某系数为0,使得特征更加稀疏)
为正则化项,一般为系数的L1范数(会使某系数为0,使得特征更加稀疏)
策略将模型的求解转化为求解最优解的问题,也就是
求解最优化问题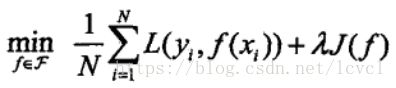
算法:
指用于求解最优化问题的算法
一般有:坐标下降、梯度下降、拟牛顿法等
训练误差:
模型关于训练数据集的平均损失,也就是期望损失函数
测试误差:
模型关于测试集的平均损失(真实结果-根据模型计算出来的结果,的平均值)
测试误差小的模型的性能更好,说明模型泛化能力更强
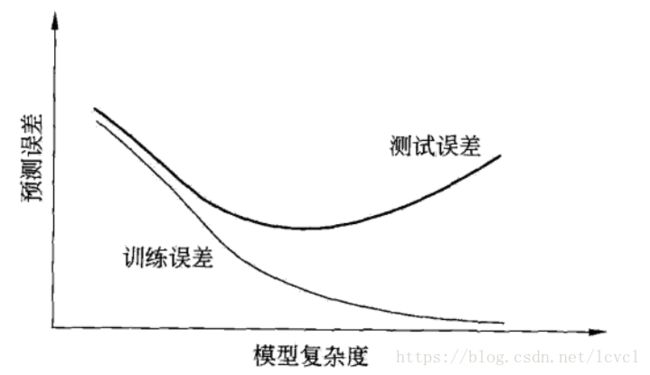
过拟合:
将训练集特有的特征,学习成数据集整体的特征
学习时选择模型所包含的参数过多(训练模型使用的特征过多)
对已知数据预测的很好,未知数据预测的很差

M为系数的数量,在特征和系数一对一时亦为特征数量
训练误差、测试误差与模型复杂度之间的关系
正则化:
详细解释
一般形式:
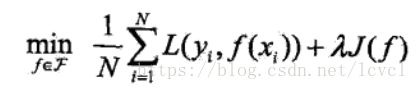
经验风险函数+正则化项,lamade大于等于0用于调整二者之间的关系
正则化项一般使用Lp范数,一般使用模型参数(线性回归中x的系数)的L1范数和L2范数
上述提到的范数指p-范数
Lp范数
若给定
那么
L1范数:║x║1=│x1│+│x2│+…+│xn│
L2范数:║x║2=(│x1│2+│x2│2+…+│xn│2)1/2
L∞范数:║x║∞=max(│x1│,│x2│,…,│xn│)
泛化能力
指由该方法学习到的模型对未知数据的预测能力
泛化误差
泛化误差实际上就是所学习到的模型的期望风险
泛化误差上界
学习方法的泛化能力分析往往是通过研究泛化误差的概率上界确定
性质:
1.是样本容量的函数,样本容量增加时,泛化上界趋于0
2.是假设空间的函数,假设空间容量越大(输入到输出映射的集合大),模型越难学(模型是映射集合中最好的那个),泛化误差上界越大
模型评估方法
无法直接获得泛化误差,一般使用测试误差作为泛化误差的近似
留出法
将数据集划分成训练集和测试集,划分时要保持数据划分的一致性。
分层采样:保留类别比例的采样方法
分层采样容易划分出不同的训练集和测试集(数据不同,比如前一百个样本和后一百个样本)
需要进行若干次随机划分取平均值
交叉验证
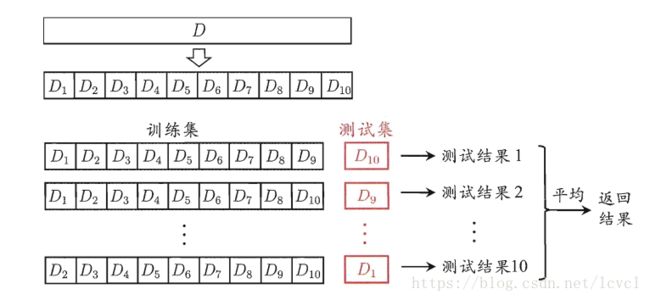
1.S折交叉验证
缺点:估计偏差
使用分层采样将样本集随机分成S个互不相交、大小相似的子集
使用S-1的数据进行模型的训练,使用剩下的数据集进行测试,这一过程有S种组合
将S种组合全部测评,最终结果为S次测试的平均值
S一般取5、10、20
以S=10为例
2.留一交叉验证
优点:评估结果准确
缺点:计算复杂度高
S折交叉验证的特殊情况,S与样本数量相等
若数据集中样本数量为N,则S=N,使用N-1个样本进行训练,留下一个样本进行测试
3.留存交叉验证
随机选择样本集的一部分作为训练集,剩余部分作为测试集
自助法
可应用于数据集较小、难以有效的划分训练集/测试集时,常用于集成训练
缺点:会引入估计偏差,所有训练集大时不适用
以自助采样法(有放回采样)为基础
每次随机从样本集中选择一个样本,拷贝进新的数据集D中,而后将样本放回原始样本集,使得其可以在下次采样时仍然可能被选择
重复m次,得到包含m个样本的数据集D
m次采样中样本不被选择的概率为:

生成模型
由生成方法所学习到的模型
通过数据学习x,y的联合概率分布P(X,Y),继而求出条件概率分布P(Y|X)作为预测的模型
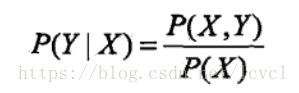
生成法关心的是输入x产生输出y的生成关心
如:朴素贝叶斯、隐马尔可夫模型
优点:收敛速度快,存在隐变量的时候仍然可以使用
判别模型
由判别方法所学习到的模型
由数据直接学习决策函数f(X)或条件概率P(Y|X)作为预测的模型
判别法关心的时对给定的输入x,应该预测什么样的y
如:k近邻、感知机、决策树、逻辑斯特回归、最大熵模型、支持向量机、提升方法、条件随机场
优点:准确率高、简化学习问题
分类问题
在监督学习中,输出变量y取有限个离散值时,预测问题为分类问题。
输入变量可以时离散的也可以时连续的
如:k近邻、感知机、决策树、逻辑斯特回归、支持向量机、朴素贝叶斯
标注问题
输入是一个观测序列,输出是一个标记序列或状态序列
如:隐马尔科夫模型、条件随机场
回归问题
预测输入x和输出y之间的关系(映射)
回归问题的学习等价于函数拟合:选择一条函数曲线,使其很好的拟合已知数据,很好的预测未知数据
常用的损失函数为平方损失函数
聚类
错误率
分类错误的样本占样本总数的比例
精度
分类正确的样本占样本总数的比例
查准率(精确率)、查全率(召回率)、F1
对于二分类而言,将类别分为正例和反例
预测结果统计为4种分别为:
TP:将正例预测为正例数
FN:将正例预测为反例数
FP:将反例预测为正例数
TN:将反例预测为反例数
简言之,总结分为两位
第一位预测的结果是否正确:T代表正确,F代表错误
第二位表示模型预测的结果:P代表正例,N代表反例

查准率P定义为:

查全率R定义为:

查准率与查全率相互矛盾,一般情况下一个高时另外一个就低
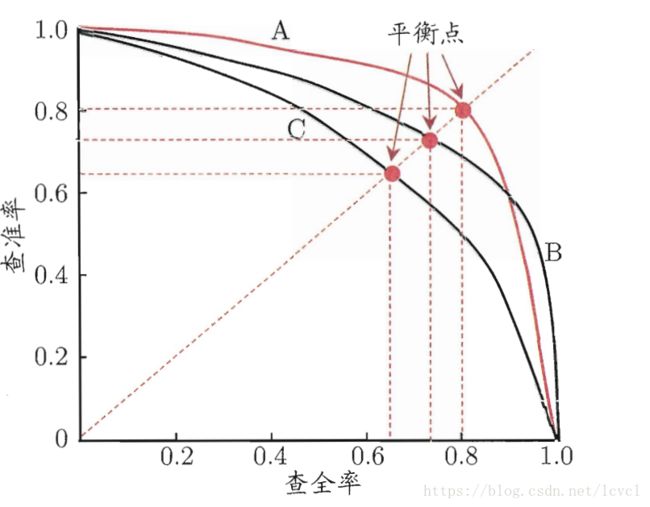
P-R曲线可以直观的表示出学习器在样本总体上的查全率和查准率
PR曲线可以对学习器的性能进行比较,如:
学习器A的PR曲线包裹住了C,说明A的性能优于C
A和B这种情况一般使用平衡点BEP(查全率=查准率的点)进行比较,图上情况认为A优于B
F1度量
使用平衡点不够准确提出F1度量
其为查准率和查全率的均值


![]()

Fβ度量
F1度量的一般形式
能让我们表达出对查准率、查全率的偏好

其中β>0,度量查全率与查准率重要性
β>1时偏好查全率
0<β<1时偏好查准率
ROC与AUC
ROC体现学习器的期望泛化性能,
使用ROC原因:当测试集的正反样本发生变化时ROC基本保持不变,但查准率与查全率会发生很大变化
纵轴为真正例率TPR
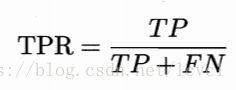
横轴为假正例率FPR



通过改变划分类别的阈值来对图像进行绘制,将阈值依次设置为样本点的预测值,而后对其进行统计计算横纵轴
若一个学习器的ROC曲线被另外一个包住,证明后者的性能优于前者。
AUC为ROC曲线的阴影面积,若两个学习器的ROC曲线相交则计算AUC作为判断依据,(实质为阴影部分面积大的性能好)
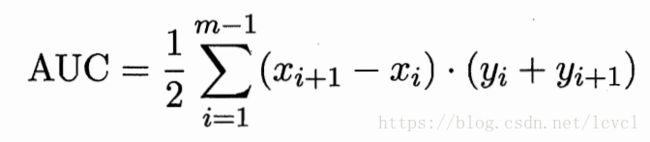
偏差与方差
偏差:期望输出与真实标记的差别,即
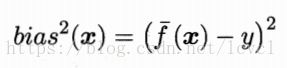
方差:同样大小的训练集的变动所导致的学习性能的变化
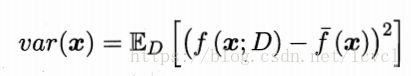
噪声:当前任务上任何学习算法所能达到的期望泛化误差的下界
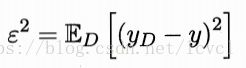
泛化误差可以分解为偏差、方差与噪声之和

偏差与方差相互矛盾
训练不足时偏差主导泛化误差,训练加深后方差主导
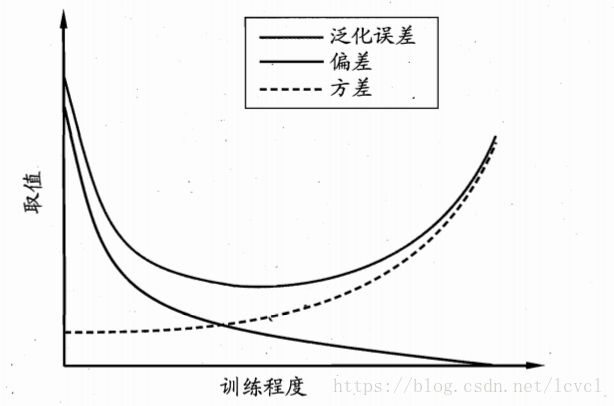
方差过高可能模型过拟合
偏差过高可能模型欠拟合