异构文档的表格检测
摘要:在文档图像中检测表是很重要的,因为不仅表包含重要信息,而且大多数布局分析方法在文档图像中存在表时都失败了。现有的表检测方法主要集中在检测单列文本中的表,在不同布局的文档上工作不可靠。本文提出了一种实用的表检测算法,该算法对不同布局的文档(公司报告、报纸文章、杂志页面等)具有较高的准确性。. 该算法的开源实现作为Tesseract OCR引擎的一部分提供。该算法对公开的UNL V数据集的文档图像进行了评估,与商业OCR系统的表检测模块相比,显示出具有竞争力的性能。
关键词:页面分割、表格检测、文档分析
1、介绍
纸质文档自动转换为可编辑的电子表示依赖于光学字符识别(OCR)技术。一个典型的OCR系统包括三个主要步骤。首先,执行布局分析以定位文档图像中的文本行text-lines并确定其阅读顺序。然后,字符识别引擎处理文本行图像,并通过识别文本行图像中的单个字符生成文本字符串。最后,语言建模模块使用字典或语言模型对文本字符串进行更正。
由于布局分析是该过程的第一步,因此所有后续阶段都依赖于布局分析才能正确工作。布局分析面临的主要挑战之一是检测表区域。表检测是一个困难的问题,因为表的布局有很大的变化。现有的开源OCR系统缺乏表检测能力,其布局分析模块在存在表区域时失效。在这个阶段应该区分表检测和表识别[8]。表检测处理在页面图像中查找表边界的问题。另一方面,表识别侧重于通过查找所检测到的表的行和列来分析表,并试图提取表的结构。本文的重点是表检测问题。
表检测和识别的先驱工作之一是Kieninger等人[11,10,12]。他们开发了一种被称为T-Recs的表定位和结构提取系统。系统依赖于单词包围框作为输入。通过构建“分割图”,将这些词框以自底向上的方法聚为区域。如果满足一定的条件,则将这些区域指定为候选表区域。该方法的主要局限性是仅基于单词框,不能非常准确地处理多列布局。因此,它只适用于单列页面。
Wang等[20]对表检测问题采用了统计学习方法。给定一组候选文本行,将根据连续单词之间的间隙识别候选表行。然后,将具有大间距的垂直相邻行和水平相邻单词组合在一起,以生成表实体候选。最后,采用基于统计的学习算法对候选表进行优化,减少误报。他们假设最大栏数为2,设计了3种页面布局模板(单栏、双栏、混合栏)。他们应用列样式分类算法来找出页面的列布局,并将此信息作为发现表区域的先验知识。这种方法只能处理经过训练的那些布局。此外,训练算法需要大量的标记数据。
Hu等人[6]提出了一种从扫描的页面图像或纯文本文档中检测表的系统。他们的系统假设一个单列输入页面,可以很容易被分割成单独的文本行(例如通过水平投影)。然后,表检测问题被提出为一个优化问题,其中属于表的开始和结束文本行通过优化一些质量函数来识别。与以前的方法一样,这种技术不能应用于多列文档。
在[7]中,Hu等人在UW-III数据集[5]上使用地真区域信息(为每个地真区域确定它是否是表)评估了他们的表检测算法。这种评估是不实际的,因为将表划分为单个区域实际上是表检测系统中比较困难的部分。这更接近于文档区域分类的方向[21,9],其目标是将每个分割的文档区域分配到一组预定义的类中(文本、数学、表格、半色调……).
Cesarini等[2]提出了一种通过检测平行线来定位表区域的系统。以这种方式形成的表格假设,然后通过在平行线之间的区域中定位垂直线或空白来验证。但是,仅仅依靠水平线或垂直线进行表检测限制了系统的范围,因为不是所有的表都有这样的直线。最近在表检测方面的工作由Gatos等[4]和Costa e Silva[3]报道。Gatos等[4]专注于定位同时具有水平和垂直规则的表,并找到它们的交点。然后,通过绘制连接所有交点对的相应水平线和垂直线来实现表重构。该系统适用于目标文档,但当表的行/列没有被划线分隔时,就不能使用了。Costa e Silva[3]的工作重点是使用隐马尔可夫模型(hmm)从PDF文档中提取表区域。他们使用pdftotext Linux实用程序从PDF中提取文本。提取文本中的空格用于计算特征向量。显然,这种方法不适用于文档图像。
总结表检测技术的现状,我们可以看到现有方法的明显局限性。这些方法不能很好地处理多列文档图像。这可能是由于大多数现有的方法都集中在表识别上,以提取表的结构(行、列、单元格),因此对表检测部分做了一些简化的假设。当必须处理一些具有简单布局的特定文档图像类时,这种方法非常有效。但是,在处理异构文档集合时,需要更健壮的表检测算法。在本文中,我们试图弥补这一差距。我们的目标是在复杂的异构文档(公司报告、期刊文章、报纸、杂志等)中准确地发现表区域。. 一旦发现表区域,就可以使用现有的表识别技术之一(例如[10])来提取表的结构。
本文的其余部分组织如下。首先,我们在第2节中描述了Tesseract的布局分析模块[18,19],它将被用作我们的表检测算法的基础。然后,我们的表检测算法在第3节中进行了说明。第4节介绍了用于评估系统的不同性能指标。第5节给出实验结果和讨论,第6节给出结论。
2、通过制表符停止检测进行布局分析
Tesseract的布局分析是开源OCR系统[19]的最新版本。它基于在文档图像中检测制表符停止的思想。在输入文档时,制表符是文本对齐的位置(左、右、中心、十进制……). 因此,制表符停止符可以作为文本块开始或结束位置的可靠指示。通过制表符停止检测来查找页面的布局,如下所示(参见图1):

- 首先,执行文档图像预处理步骤,以识别水平和垂直的标线或分隔符,并定位文档中的半色调或图像区域。然后,根据文本组件的大小和笔画宽度,执行连接组件分析以识别候选文本组件。
- 过滤后的文本组件被评估为位于制表符停止位置的候选文本。这些候选对象被分组到垂直的行中,以找到垂直对齐的制表符停止位置。作为最后一步,对连接的制表符行进行调整,使它们在相同的y坐标处结束(参见图1(a))。在此阶段,垂直制表行标记文本区域的开始和结束。
- 根据选项卡行,推断页面的列布局,并将连接的组件分组到column Partitions中。列分区是一个连接的组件序列,这些组件不跨越任何制表行,并且具有相同的类型(文本、图像……). 文本列分区可以视为文本行的初始候选(参见图1(b))。
- 最后一步创建列分区流,以便将相同类型的相邻列分区分组到同一个块中(图1(c))。具有不同字体大小和行间距的文本列分区被分组到不同的块中。然后,确定这些块的读取顺序。块的边界表示为等线多边形(所有边都平行于轴的多边形)。
3、发现表格
我们的表检测算法建立在布局分析模块的两个组件之上:1. 列分区2。列布局
列分区为我们提供了按类型分组的连接组件,这些组件不跨越制表符停止行。因此,文本列在文档中划分近似的文本行。半色调区域和水平黑线(规则)报告为“图像”和“水平线”类型的列分区。除了列分区之外,列布局还提供了特定列分区是完全位于一列内还是跨越多列的信息。如图2所示,在存在表区域时,列分区和列布局都可能给出错误的结果。
对存在表区域的布局分析结果的进一步分析显示了两种主要场景。在第一种情况下,表列被报告为页面列,从而破坏了页面的柱状结构。这种情况在表单元对齐得很好的情况下尤其会发生。对齐导致检测到大量的制表符停止,因此制表符行足够强,可以报告列的存在。因此,表中的每个单元格都报告为一个单列分区。在第二种情况下,由于单元格没有很好地对齐,系统会忽略表列。因此,可以正确识别页面的柱状结构。在这种情况下,列分区跨越表的不同列。这两种情况都在图2的示例图像中进行了说明。基于此分析,我们的表检测算法设计如下。

3.1识别表分区
我们的算法的第一步确定可以属于表区域的文本列分区,称为表分区。根据上一段中提到的观察结果,有三种类型的分区被标记为表分区:(1)在其连接的组件之间至少有一个大间隙的分区,(2)仅由一个单词组成的分区(组件之间没有明显的间隙) (3)沿y轴与同一列内其他分区重叠的分区。第一种情况标识了将表中不同列的单元格合并到一个分区中的表分区。第二种情况检测由单个数据单元组成的表分区。第三种情况标识位于一列中但由于存在强选项卡行而没有连接在一起的表分区。
这个阶段非常积极地尝试寻找表分区候选。这样做的好处是,即使很小的表存在的证据也不会丢失,因为在这个阶段丢失的任何表将无法在后面的阶段恢复。这种激进方法的缺点是可能会产生一些错误警报,例如单个单词的节标题、页眉和页脚、编号的方程、边缘噪声中的一小部分文本单词以及划线区域。平滑过滤器用于检测上面或下面没有其他表分区邻居的隔离表分区。这些分区将从候选表分区列表中删除。示例图像的候选表分区如图3(a)所示。
3.2 检测页列分割
下一步是检测由于表的存在而导致页面列布局中的分裂。当表的单元格非常好地对齐时,就会发生这种分裂。为了检测这种情况,我们将页面划分为列,并找出每列中表分区的比例。被错误地报告为页列的表列很容易被检测出来,因为与正常的文本分区相比,它们具有较高的表分区比例。然而,在这个阶段需要特别注意撤销列分割(即合并两列),因为错误的决定会导致合并两个文本列,从而导致页面布局分析本身出现大量错误。因此,我们只在如下情况下撤消页列分割:出现了足够数量的跨越两列的文本分区并且列中的分割从表分区开始。
当页面中没有流动文本时,这种额外的注意可以防止合并全页表中的表列。
从布局分析错误的角度来看,错误决策的代价非常高,因此我们选择防御性地执行这一步。
3.3定位表格列
这一步的目标是将表分区分组到表列中。为此,将垂直相邻的表分区的运行分配给单个表列。如果遇到“水平规则”类型的列分区,则继续运行。当找到任何其他类型的分区时,到目前为止获得的表列就结束了。如果一个表列仅由一个表分区组成,则将其作为假警报删除。示例图像的标识表列如图3(b)所示。
3.4定位表区域
以上步骤中获取的表列可以很好地提示该区域中是否存在表。我们在这里做一个简单的假设:在单个页面列中,流动文本不与沿y轴的表共享空间。这一假设适用于我们在实践中遇到的大多数布局,因为如果一个表格与流动文本垂直共享空间,就很难看到文本是否属于表格。基于这个假设,我们水平地将表列的边界扩展到包含它们的页列。因此,我们为每个页列获得内入列表区域。
在此阶段,将正确识别在一列中布局的表。但是,跨多个页列的表是过度分段的。尽管如果相邻页列中的两个表区域的开始位置和结束位置对齐,则可以合并它们,但这可能会错误地合并这两列中的不同表。因此,只有当至少有一个任何类型的列分区(文字、表、水平线)被发现与两个表重叠时,才执行合并。没有包含在任何表中并且在x轴上有较大重叠的表区域的正上方或正下方的表分区和水平规则分区也包含在相邻表中。由此为示例图像获得的表区域如图3(c)所示。
3.5消除虚假告警
虽然在之前的阶段中,大部分来自正常文本区域的假警报已经被删除,但其他假警报来源,如边缘噪声[17]和数字仍然存在。
因此,标识的表区域将通过一个简单的有效性测试:一个有效的表应该至少有两列。由单列组成的假警报通过分析它们在x轴上的投影来去除。有效表在x轴上的投影应该至少有一个零谷值大于页面的全局x高度中值。因此,在其垂直投影中没有零谷的候选表将被删除。
4. 性能指标
文献中已经报道了用于评估表检测算法的不同性能指标。这些范围从简单的基于精度和召回的措施[6,13]到更复杂的措施,如检测表结构提取是否完整的算法[8]。在本文中,由于我们只关注表发现,所以我们使用标准措施来进行文档图像分割,重点关注表区域。因此,根据[13,14,16,20],我们使用几个度量来定量评估我们的表发现算法的不同方面。
我们的算法检测到的表和ground-truth/真实表都由它们的包围框表示。设Gi代表文档图像中第i个ground-truth表的包围框,Dj代表文档图像中第j个检测到的表的包围框。两者之间的重叠量定义为:

其中,分子的交集表示两个区域的交的面积,|Gi|, |Dj|代表ground-truth和检测表的个别区域。区域重叠A的数量将在0到1之间变化,这取决于地面真实表Gi和检测表Dj之间的重叠。如果两个表完全不重叠A = 0,并且如果两个表完全匹配,即|Gi∩Dj| = |Gi| = |Dj|,则A = 1。
-
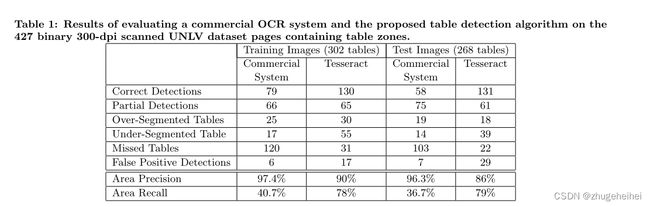
- 正确检测:这些是与检测到的表之一有较大重叠(a≥0.9)的ground-truth/有效正确的表的数量。
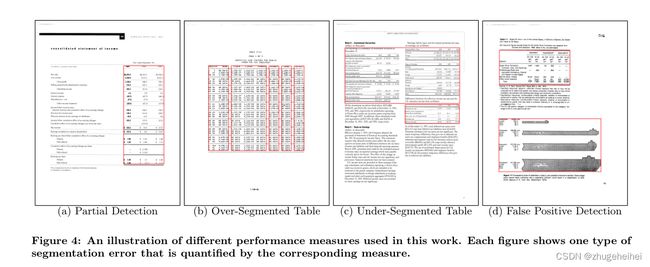
- 部分检测:这些是与被检测表一一对应的真实表的数量,但是重叠的数量不够大(0.1 < a < 0.9),不能被归类为正确的检测(见图4(a))。
- 过分段表:这些是与多个检测到的表有主要重叠(0.1 < a < 0.9)的基本真实表的数量。这表明,ground-truth表的不同部分被检测为单独的表(参见图4(b))。
- 分段下表(Under-Segmented Tables):这些是与一个检测到的表有主要重叠(0.1 < a < 0.9)的ground-truth表的数量,但相应的检测到的表也与其他groundtruth表有主要重叠。这表明检测算法合并了多个表(可能相邻),并将其报告为单个表(参见图4(c))。
- 缺失表:这些是与任何检测到的表没有主要重叠的groundtruth表的数量(a≤0.1)。这些表被检测算法视为漏检。
- 假阳性检测:这些是检测到的表的数量,这些表与任何基本真相表都没有重大重叠(a≤0.1)。这些表被认为是假阳性检测,因为系统将一些非表区域误认为是表(参见图4(d))。
- 区域精度:虽然上面定义的度量有助于理解表检测算法产生了哪些类型的错误,但该度量的目标是通过测量被检测到的表区域实际上属于groundtruth图像中的表区域的百分比来总结算法的性能。当对表区域的存在做出非常保守的决定时,可以获得很高的精度。
- 区域召回(Area Recall):该测量方法评估了由算法标记为属于一个表的ground-truth表区域的百分比。精度和召回度量的概念类似于它们在信息检索社区[13]中的使用。
5、试验和结果
为了评估我们的表检测算法的性能,我们选择了UNL V数据集[1]。UNL V数据集包含各种各样的文件,从技术报告和商业信件到报纸和杂志。该数据集专门用于分析UNLV年度OCR精度[15]测试中领先的商业OCR系统的性能。它包含10,000多张不同分辨率的扫描页和1000份传真文件。扫描的页面分为双色调文档和灰度文档。双色调文档再次分组为不同的扫描分辨率(200、300和400 dpi)。对于每一页,都提供了手动键入的ground-truth文本,以及手动确定的区域信息。区域根据其内容(文本、表格、半色调等)进一步标记。. 我们在实验中选择了300 dpi类的双色调文档,因为这代表了扫描文档的最常见设置。在这些图像中,有427个包含表区域的页面被选中。这些页面图像被进一步分为213张图像的训练集和214张图像的测试集。在算法的开发中使用了训练图像,并在这些图像上对算法的不同步骤进行了广泛的评估。最后用测试图像对整个系统进行了评价。
我们的表检测算法对来自UNLV数据集的一些样本图像的结果如图5所示。表1和图6给出了该算法的详细评估及其与最先进的商用OCR系统的比较。应该注意的是,UNLV数据集提供的地面真相表区域还包括区域内的表标题。由于表标题不是一个表格结构,它被所有OCR系统排除在表之外。因此,我们通过手动标记所有文档中的表标题区域来编辑ground-truth信息。然后将该区域从数据集提供的ground-truth表区域中排除。这是通过缩小ground-truth表区域来紧紧包围所有不属于表标题的前景像素来实现的。实验结果表明,该系统能够在测试数据上识别出86%的表区域。召回率也相当高(79%),显示出精度和召回率之间的良好妥协。另一方面,商用OCR系统的召回率较低(37%),但精度较高(96%)。
我们的算法所产生的一些错误如图4所示。对结果的分析表明,错误的主要来源是整页的表格。在这些情况下,列查找算法报告几列文本。由于报纸也有几个文本栏,不使用关于文件类型的先验知识(报告,报纸,…)很难检测到大量的列是由于整页表造成的。一个典型的例子是包含“目录”的页面。这些页面被标记为UNL V数据集提供的基本真实信息中的表区域。然而,我们的算法将它们视为常规文本页面,因此要么完全丢失这些“表”,要么部分检测到它们。
分析了该算法的假阳性检测结果。我们注意到我们算法的一个有趣的副作用。由于许多图形区域内的文本是间隔的,因此这些区域也被标记为表格。尽管这样的情况被报告为错误警报,但在某些情况下,额外发现图形区域也可能是有益的。其他虚假警报的情况源于表格方程。在纯文本区域,假警报相当罕见。


6、结论
本文提出了一种表检测算法,作为Tesseract开源OCR系统的一部分。所提出的算法使用Tesseract的布局分析模块的组件来定位具有各种布局的文档中的表。对来自UNLV数据集的不同类别的文档(公司报告、期刊文章、报纸文章、杂志页面)的实验结果表明,我们的表检测算法与商业OCR系统相比具有更高的召回率和略低的精度。我们计划在未来将这项工作扩展到表结构提取的方向。