python爬虫教程(五):解析库bs4及爬取实例
大家好,今天分享的是解析库中的bs4,本文章的目的是让你知道如何使用bs4,并且附带爬取实例。
目录
一、bs4简介
二、安装及初始印象
1.安装
2.解析器
3.初始印象
三、选择元素的方法
1.方法一
2.方法二:
3.方法三:
4.方法四:
三、获取元素信息
1.获取文本信息:
2.获取属性信息:
四、bs4爬取爬虫抓取实例
1.爬取说明
2.实现过程
一、bs4简介
BS4全称是Beatiful Soup,它提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为tiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码,不需要考虑编码方式。
bs4的4种对象:
·Tag对象:是html中的一个标签,用BeautifulSoup就能解析出来Tag的具体内容,具体的格式为‘soup.name‘,其中name是html下的标签。
·BeautifulSoup对象:整个html文本对象,可当作Tag对象。
·NavigableString对象:标签内的文本对象。
·Comment对象:是一个特殊的NavigableString对象,如果html标签内存在注释,那么它可以过滤掉注释符号保留注释文本。
最常用的还是BeautifulSoup对象和Tag对象。
二、安装及初始印象
1.安装
bs4是一个第三方库,需要安装。如果使用的是默认的IDE,可以在命令行下敲下:
pip install bs4如果是其它的话,建议百度或在论坛上寻找方法。
2.解析器
对于bs4这个库来说,我们主要使用的是BeautifulSoup对象,使用方法如下:
# 导包
from bs4 import BeautifulSoup
# 创建对象
soup = BeautifulSoup()
print(type(soup))
# 结果为:
# 而BeautifulSoup在解析网页的时候依赖于其他的解析器,如我们之前讲解过的lxml等等。下面给出常见的四种解析器:Python标准库、lxml解析器、xml解析器、html5lib解析器。上面四种解析器各有优点也有缺点,其中最常用的就是lxml,因为其解析速度和容错性都比较好。
这里解释一下,什么是容错性。我们有时候传给BeautifulSoup的网页源代码并不完整,或者说格式不标准,其中常见的如:table标签的写法,table标签现在一般都采取的简写的方式,而不是标准的写法。这时,不同的解析器就有不同的容错性,或者说对于修正性。
下面给出四种解析器的优缺点:
| 解析器 | 优点 | 缺点 |
|---|---|---|
| Python标准库 | python内置标准库,执行速度适中,文档容错强 | python2.x与python3.2.2之前的版本容错能力差 |
| lxml | 速度快、容错能力强 | 需要安装C语言库 |
| xml | 速度快,唯一支持XML文档的解析器 | 需要安装C语言库 |
| html5lib | 最好的容错性 | 速度慢 |
3.初始印象
下面给出bs4的一个小小例子,让大家有一个印象:
from bs4 import BeautifulSoup
text = '''
'''
soup = BeautifulSoup(text,'lxml') # 需要安装lxml库哦
# 提取出 所有类名
tag_list = soup.find_all('a')
for tag in tag_list:
print(tag.text)结果如下:
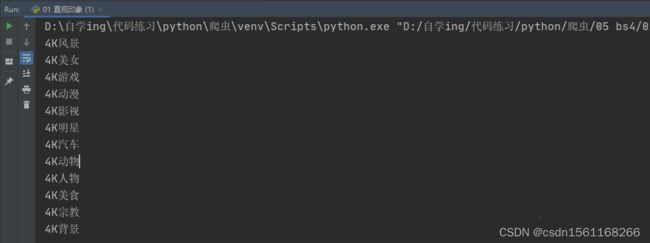
三、选择元素的方法
1.方法一
from bs4 import BeautifulSoup
text = '''
'''
soup = BeautifulSoup(text,'lxml') # 需要安装lxml库哦
# 方法一
result = soup.div
print(type(result))
print('-'*50)
print(result)结果如下:

可见,这种方法的语法形式为:xxx.Tag_name。这种选择还支持嵌套选择,如下:
# 为了大家方便,省略了相同的代码,下面只给出需要修改的代码
# 修改之前:result = soup.div
# 修改之后:
result = soup.div.a结果如下:

可见,当有多个符合条件的标签时,选择第一个符合的标签。
缺点:选择性很低,无法增加附加条件进行更深层次的筛选。
示例:
# 记住: 接着选择
from bs4 import BeautifulSoup
text = '''
'''
soup = BeautifulSoup(text,'lxml') # 需要安装lxml库哦
# 方法一
result = soup.div
print(result)
print('-'*50)
result_two = result.a
print(result_two)结果如下:
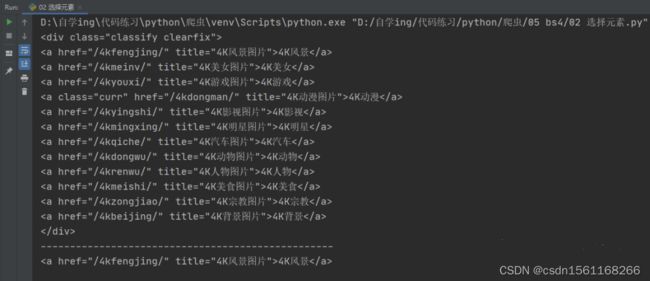
2.方法二:
方法二主要依靠一些属性来获取,如:contents、children、descendants等等。下面一一讲解其作用:
1>子节点:
属性:contents、children
作用:获取目标的直接子节点
示例:
from bs4 import BeautifulSoup
text = '''
'''
soup = BeautifulSoup(text,'lxml') # 需要安装lxml库哦
# 方法二
print(type(soup.div.contents))
for child in soup.div.contents:
print(child)结果如下:

注意:contents返回的是列表,而children返回的是生成器。
2>子孙节点:
属性:descendants
作用:获取目标的所有子孙元素
返回值:生成器
示例:
from bs4 import BeautifulSoup
text = '''
'''
soup = BeautifulSoup(text,'lxml') # 需要安装lxml库哦
# 方法二
print(type(soup.ul.descendants))
for child in soup.ul.descendants:
print(child) 动漫女孩 黑发 露肩 4k壁
动漫女孩 黑发 露肩 4k壁
 古风 美少女 伞 长发 女
古风 美少女 伞 长发 女
 下午 趴在桌子的女孩4k动
下午 趴在桌子的女孩4k动
结果如下:

下面的属性将不给出案例,如果想要实验,可以使用上面代码套用
3>父节点:
属性:parent
作用:获取目标节点的父节点
4>祖先节点:
属性:parents
作用:获取目标节点的所有祖先节点
返回值:生成器
5>兄弟节点:
属性1 :next_sibling
作用:获取下一个兄弟节点
属性2 :previous_sibling
作用:获取上一个兄弟节点
属性3:next_siblings
作用:获取下面的所有兄弟节点
属性4:previous_siblings
作用:获取之前的所有兄弟节点
6>优缺点:
相比于方法一,方法二多了一些选择形式,但是还是不够,没有办法精准的选出我们想要的标签。
3.方法三:
1>find_all()方法:
作用:查询出所有符合条件的元素
常用参数:name、attrs、text
参数讲解:
name :想要获取的节点的节点名字
attrs:想要获取的节点的属性,根据这个属性来筛选
text:可以指定正则表达式或者字符串,去匹配元素的内容
示例一:name 和 attrs 的配合使用
from bs4 import BeautifulSoup
text = '''
'''
soup = BeautifulSoup(text,'lxml') # 需要安装lxml库哦
# 筛选出白菜
result_list = soup.find_all('a',attrs={'class':'white'})
print(type(result_list))
print('-'*50)
for result in result_list:
print(result)结果如下:

总结:name 是以字符串的形式来写标签的名字;attrs则是附加属性筛选。
示例二:text的使用
import re
from bs4 import BeautifulSoup
text = '''
'''
soup = BeautifulSoup(text,'lxml') # 需要安装lxml库哦
# 筛选出白菜
result_list = soup.find_all(text=re.compile(r'白菜'))
for result in result_list:
print(result)
结果如下:

下面的方法用法参数同find_all()一样,只给出其作用,就不给示例了^_^
2 >find()方法:
作用:返回第一个匹配成功的元素
3>find_parents()和find_parent():
find_parents():返回所有的祖先节点
find_parent():返回直接父节点
4>find_next_siblings()和find_next_sibling():
find_next_siblings(): 返回后面所有的兄弟节点
find_next_sibling(): 返回下一个兄弟节点
5>find_previous_siblings()和find_previous_sibling():
find_previous_siblings():返回之前的所有的兄弟节点
find_previous_sibling():返回上一个兄弟节点
上面几个比较常用,还有些不常用就不做介绍
4.方法四:
如果你学过css,那么你也可以采取css来写,不过我建议你选择pyquery模块来写css。
写法:
xxx.select('css代码 ')
作用:
返回所有符合css条件的元素
示例:
from bs4 import BeautifulSoup
text = '''
'''
soup = BeautifulSoup(text,'lxml') # 需要安装lxml库哦
# 筛选出白菜
result_list = soup.select('.white')
for result in result_list:
print(result)结果如下:

三、获取元素信息
元素筛选成功后,我们需要获取元素的一定信息,如:文本信息、属性信息等等。
1.获取文本信息:
方法一:xxx.string:
用来获取目标路径下第一个非标签字符串,得到的是个字符串。
方法二:xxx.stings:
用来获取目标路径下所有的子孙非标签字符串,返回的是个生成器。
方法三:xxx.stripped_strings:
用来获取目标路径下所有的子孙非标签字符串,会自动去掉空白字符串,返回的是一个生成器。
方法四:xxx.get_text()
用来获取目标路径下的子孙字符串,返回的是字符串(包含HTML的格式内容)。
上面四个示例如下:
from bs4 import BeautifulSoup
text = '''
'''
soup = BeautifulSoup(text,'lxml') # 需要安装lxml库哦
# 筛选出白菜
tag = soup.find('li')
print(tag.string)
print(list(tag.strings))
print(list(tag.stripped_strings))
print(tag.get_text())结果如下:

2.获取属性信息:
方法一:xxx.attrs['属性名字']
方法二:xxx['属性名字']
示例如下:
from bs4 import BeautifulSoup
text = '''
'''
soup = BeautifulSoup(text,'lxml') # 需要安装lxml库哦
# 筛选出白菜
tag_list = soup.find_all('a')
tag_attr_list_one = [tag.attrs['class'] for tag in tag_list]
tag_attr_list_two = [tag['class'] for tag in tag_list]
print(tag_attr_list_one)
print('-'*50)
print(tag_attr_list_two)结果如下:

四、bs4爬取爬虫抓取实例
1.爬取说明
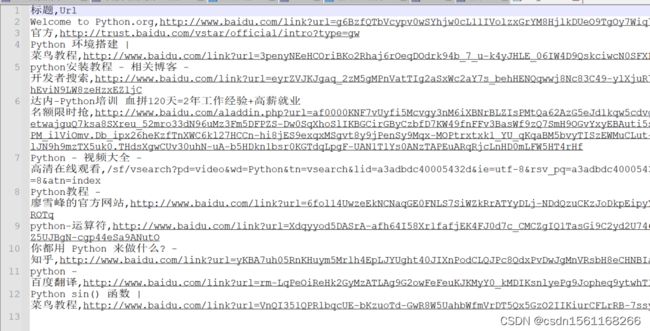
Python网络爬虫代码,用来获取某度关键词和链接,今天我们将使用bs4来进行实现。
2.实现过程
# -*- coding: utf-8 -*-
# @Time : 2022/4/20 18:24
# @Author : 皮皮:Python共享之家
# @File : demo.py
import requests
from bs4 import BeautifulSoup
import time
import pandas as pd
# 从element里面进行分析,可以知道百度会给一个自己加密的Url
def convert_url(url):
resp = requests.get(url=url,
headers=headers,
allow_redirects=False
)
return resp.headers['Location']
#
# 获取url
def get_url(wd, num):
s = requests.session()
total_title = []
total_url = []
total_info = []
# 第1页为小于10的数字 10为第2页,20为第三页,30为第四页,以此类推
num = num * 10 - 10
for i in range(-10, num, 10):
url = 'https://www.baidu.com/s' # 点击界面第二页可以看到网页变化截取关键部分 https://www.baidu.com/s?wd=python&pn=10
params = {
"wd": wd,
"pn": i,
}
r = s.get(url=url, headers=headers, params=params)
print("返回状态码:", r.status_code) # 可以看对应Js 正常网页访问时候 status状态码 为200
soup = BeautifulSoup(r.text, 'lxml')
for so in soup.select('#content_left .t a'):
# g_url = convert_url(so.get('href')) # 对界面获取的url进行进行访问获取真实Url
g_url = so.get('href') # 对界面获取的url进行进行访问获取真实Url
g_title = so.get_text().replace('\n', '').strip() # 根据分析标题无对应标签 只能获取标签内文字 去掉换行和空格
print(g_title, g_url)
total_title += [g_title]
total_url += [g_url]
time.sleep(1 + (i / 10))
print("当前页码:", (i + 10) / 10 + 1)
try:
total_info = zip(total_title, total_url)
df = pd.DataFrame(data=total_info, columns=['标题', 'Url'])
df.to_csv(r'./web_data.csv', index=False, encoding='utf_8_sig')
print("保存成功")
except:
return 'FALSE'
if __name__ == '__main__':
while True: # 循环
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0",
"Host": "www.baidu.com",
}
wd = input("输入搜索内容:")
num = int(input("输入页数:"))
get_url(wd, num)运行之后结果如下:

在本地也会自动地生成csv存储文件,内容如下: