前端面试题及答案(字节跳动)(二)
目录
· css 的动画(三种)
· 给一个ul下面插入100个li应该怎么插入,如何优化dom操作?
· 判断链表内是否存在环
· HTTP请求简单理解
· HTTP请求的常用方法(八个)
· GET和POST的区别和使用场景
· 浏览器缓存策略
· JS的数据类型及判断方法
· JS中异步操作有哪些
· async和await 的一些用法
· JS 常见的 6 种继承方式
· Java中创建链表,实现链表的尾部插入
· html 的 dom 树如何生成的
· 小程序和 pc 页面有什么差异
· 任务队列算法题
· Java中将一个数组里的值复制到另一个数组中
· 前端打包工具-webpack和rollup的区别
· npm 的命令写在 package.json 的哪个字段(scripts 字段)
· webpack 的热更新
· 用 promise 实现一个定时器,每隔一秒输出数组中的一个数字
· 最长无重复子数组
· var 和 const 的区别
· 闭包
· 变量提升和函数提升
· 常用的npm包
· webpack之编写loader
· DNS 是基于 TCP 还是 UDP
· Vue 的响应式原理
· 简单介绍 node 事件循环机制
· css 的动画(三种)
①transition实现过渡动画,②transform转变动画,③animation实现自定义动画
-
transition 过渡动画
transition: property duration timing-function delay;
- transition-property: 规定设置过渡效果的 css 属性名称
- transition-duration: 规定完成过渡效果需要多少秒或毫秒
- transition-timing-function:指定过渡函数, 规定速度效果的速度曲线
- transition-delay: 指定开始出现的延迟时间
ease-in加速,ease-out减速,ease-in-out先加速后减速,linear匀速
transition: background 0.8s ease-in 0.3s, color 0.6s ease-out 0.3s;
-
transform 转变动画
(1)旋转 rotate
- 2D旋转
transform: rotate(45deg); // 顺时针旋转45度
- 3D旋转:围绕原地到(x,y,z)的直线进行3D旋转
transform: rotate(x,y,z,angle);
- x,y,z:分别表示 X、Y 和 Z 轴方向,都不能省略;
- angle:设置对象设置对象的旋转角度,不能省略;
- rotateX(angle),rotateY(angle),rotateZ(angle)沿着X、Y、Z轴进行3D旋转;
(2)缩放 scale
- 2D缩放
transform: scale(0.5); //水平和垂直同时缩放该倍率
transform: scale(0.5, 2); //水平方向缩放倍率,垂直方向的缩放倍率
- 3D缩放
transform: scale3d(x, y, z); //x、y、z为收缩比例
transform: scaleX(x);
transform: scaleY(y);
transform: scaleZ(z);
- 倾斜 skew
transform: skew(30deg); //水平倾斜角度
transform: skew(30deg, 30deg); //水平倾斜角度,垂直倾斜角度
//skew 的默认原点 transform-origin 是这个物件的中心点-
移动 translate
1. 2D移动
transform: translate(45px); //水平方向移动距离
transform: translate(45px, 150px); //水平方向移动距离,垂直方向移动距离
2. 3D移动
transform: translateX(100px); //仅仅是在X轴上移动
transform: translateY(100px); //仅仅是在Y轴上移动
transform: translateZ(100px); //仅仅是在Z轴上移动(注意:translateZ一般都是用px单位)
transform: translate3d(x,y,z); //在x,y,z轴上都移动
-
animation 关键帧动画
· 给一个ul下面插入100个li应该怎么插入,如何优化dom操作?
var ul = document.getElementById("ul");
for (var i = 0; i < 20; i++) {
var li = document.createElement("li");
li.innerHTML = "index: " + i;
ul.appendChild(li);
}优化dom操作:使用DocumentFragment,它是没有父节点的最小的文档对象,用于存储HTML和XML片段
var ul = document.getElementById("ul");
var fragment = document.createDocumentFragment();
for (var i = 0; i < 20; i++) {
var li = document.createElement("li");
li.innerHTML = "index: " + i;
fragment.appendChild(li);
}
ul.appendChild(fragment);· 判断链表内是否存在环
题目描述 :给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
如果链表中存在环,则返回 true 。 否则,返回 false 。
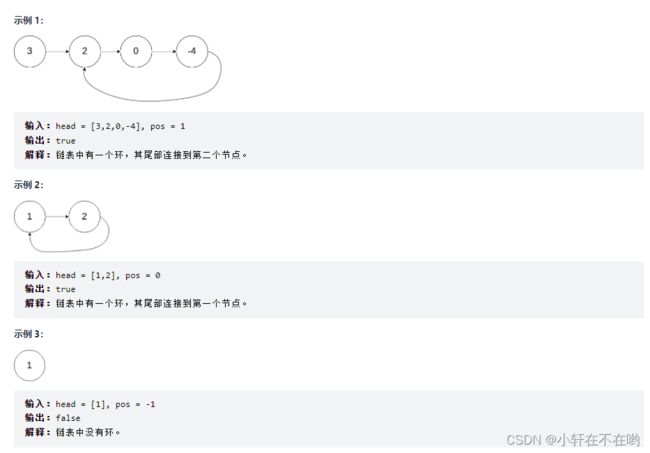
算法思路 :

环形链表:链表最后一个尾节点里面的地址引用到前面的某个节点形成回环称为环形链表(如图)
解题步骤 :
1. 定义两个引用 (快慢指针)一个一次走两步 一个一次走一步 (思考:为什么快的那个一次不能走三步或者其他 原因:如果一个走三步 一个走一步 在某些链接中有可能永远追不上 相遇不了 )
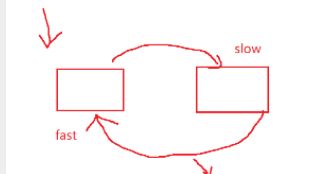
就像图中举列,要是一个走三步,一个走一步,就会造成永远追不上的情况
2. 因为一个快一个慢,当两个引用进入到环中,慢的那个引用就一定可以被快的那个引用追上 证明回环
代码如下:
public class Solution {
public boolean hasCycle(ListNode head) {
ListNode slow=head;
ListNode fast=head;
while(fast!=null && fast.next!=null){
fast=fast.next.next;
slow=slow.next;
if(slow==fast){
return true;
}
}
return false;
}
}
· HTTP请求简单理解
HTTP是超文本传送协议 (HTTP) 是一种通信协议,HTTP请求是指从客户端到服务器端的请求消息,包含三部分 请求行 请求头 请求体
- 请求行:method(get/post) + request-URI + http-version
(主要作用是发送的时候证明自己一个什么请求(就比方HTTP请求的时候,它会告诉请求的地址说自己是个HTTP请求))
- 请求头:User-Agent:产生请求的浏览器类型(key:value)
(主要作用是发送请求的时候携带参数 key(就像登录的时候 需要把账号跟密码一起传到后端))
- 请求体:参数体,get没有请求体(只有post和put请求有请求体),post方法中,会把数据以key value形式发送请求,一般为JSON字符串形式
· HTTP请求的常用方法(八个)
1、GET方法;2、POST方法;3、HEAD方法;4、PUT方法;5、DELETE方法;6、CONNECT方法;7、OPTIONS方法;8、TRACE方法
- GET请求
主要用作于获取资源,我客户端请求什么,你服务器就原样给我返回什么
- POST请求
主要用来传输实体的主体,客户端需要向服务器传输一些东西
- HEAD请求
主要用来获取报文首部,和GET方法一样,只不过不返回报文的主体部分
- PUT请求
主要用来传输文件, 就像FTP协议的文件上传一样
- DELETE请求
主要是用来删除某个资源,是和PUT完全相反的方法
- CONNECT方法
主要用来建立到给定URI标识的服务器的隧道
- OPTIONS请求
主要是用来查询,请求的指定资源都支持什么http方法
- TRACE方法
主要用于沿着目标资源的路径执行消息环回测试 ,它回应收到的请求
· GET和POST的区别和使用场景
GET和POST都是将数据送到服务器,最直观的区别就是GET把参数包含在URL中,POST通过request body传递参数
- 区别
- GET在浏览器回退时是无害的,而POST会再次提交请求
- GET产生的URL地址可以被Bookmark,而POST不可以
- GET请求会被浏览器主动cache,而POST不会,除非手动设置
- GET请求只能进行url编码,而POST支持多种编码方式
- GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留
- GET请求在URL中传送的参数是有长度限制的,而POST么有
- 对参数的数据类型,GET只接受ASCII字符,而POST没有限制
- GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息
- GET参数通过URL传递,POST放在Request body中(最直观)
- 使用场景
-
Get, 它用于获取信息,注意,他只是获取、查询数据,也就是说它不会修改服务器上的数据,从这点来讲,它是数据安全的,而稍后会提到的Post它是可以修改数据的,所以这也是两者差别之一了。
-
Post,它是可以向服务器发送修改请求,从而修改服务器的,比方说,我们要在论坛上回贴、在博客上评论,这就要用到Post了,当然它也是可以仅仅获取数据的。
-
Delete,删除数据。可以通过Get/Post来实现。
-
Put,增加、放置数据,可以通过Get/Post来实现。
一般对于登录、注册等表单请求,不建议用GET方式请求,一般用POST,因为一些参数信息暴露出来会不安全。另外,对于博客、论坛、数据的上传下载等也最好用POST,因为论坛或者上传下载等前后都可能会产生数据的变化,故用POST。 而一般对于有响应速度要求,并且对信息相对不敏感的,比如查询、搜索等,可以使用GET。
· 浏览器缓存策略
浏览器缓存策略分为两种:强缓存和协商缓存。都是由服务器返回的响应报文中的头字段决定的。
- 强缓存
强缓存:客户端再次请求资源时,不会向服务器发送请求,而是直接从缓存中读取资源
两种实现方式:
- Expires方法(设置过期时间)
- Cache-Control方法(设置过期时间)
-
协商缓存
协商缓存:客户端再次请求资源时时,会向服务器发送请求验证当前资源的有效性
两种实现方式:
- Last-Modified(根据文件修改时间来决定是否从缓存取数据)
- Etag方法(根据文件内容是否修改来决定是否从缓存取数据)
· JS的数据类型及判断方法
- 数据类型
Undefined、Null、String、Number、Boolean、Symbol(ES6 新增,表示独一无二的值)、BigInt(ES6 新增)、Object(普通对象,数组,正则,日期,Math数学函数)共8种

- 判断方法:typeof、instanceof (推荐使用)、constructor、Object.prototype.toString.call()
- 数据分成两大类的本质区别:基本数据类型和引用数据类型它们在内存中的存储方式不同
- 基本数据类型是直接存储在栈中的简单数据段,占据空间小,属于被频繁使用的数据
- 引用数据类型是存储在堆内存中,占据空间大。引用数据类型在栈中存储了指针,该指针指向堆中该实体的起始地址,当解释器寻找引用值时,会检索其在栈中的地址,取得地址后从堆中获得实体
- Symbol是ES6新出的一种数据类型,这种数据类型的特点就是没有重复的数据,可以作为object的key。不可枚举 使用getOwnPropertySymbols获取
let key = Symbol('key');
let obj = { [key]: 'symbol'};
let keyArray = Object.getOwnPropertySymbols(obj); // 返回一个数组[Symbol('key')]
obj[keyArray[0]] // 'symbol'· JS中异步操作有哪些
- 定时器都是异步操作
- 事件绑定都是异步操作
- AJAX中一般我们都采取异步操作(也可以同步)
- 回调函数可以理解为异步(不是严谨的异步操作)
· async和await 的一些用法
- async
async写在函数前,返回一个promise对象
当返回值不是一个promise对象时,会被强转成promise对象
async function demoFunc () {
return new Promise((resolve, reject) => {
resolve('hello world')
})
}-
await
await操作只能用在async函数中,否则会报错
arg = await awaitFunc //awaitFunc可以是任何值,通常是一个promise-
async和await基本使用
function printName(name) {
return new Promise((resolve, reject) => {
setTimeout(() => {
resolve(name)
}, 2000)
})
}
async function getName() {
let name = await printName('jack')
console.log('hello ', name)
}
getName() // 2s后 输出hello jack · JS 常见的 6 种继承方式
- 原型链继承
涉及的构造函数、原型和实例,三者之间存在着一定的关系,即每一个构造函数都有一个原型对象,原型对象又包含一个指向构造函数的指针,而实例则包含一个原型对象的指针
function Parent1() {
this.name = 'parent1';
this.play = [1, 2, 3]
}
function Child1() {
this.type = 'child2';
}
Child1.prototype = new Parent1();
console.log(new Child1());-
构造函数继承(借助 call)
function Parent1(){
this.name = 'parent1';
}
Parent1.prototype.getName = function () {
return this.name;
}
function Child1(){
Parent1.call(this);
this.type = 'child1'
}
let child = new Child1();
console.log(child); // 没问题
console.log(child.getName()); // 会报错- 组合继承(前两种组合)
function Parent3 () {
this.name = 'parent3';
this.play = [1, 2, 3];
}
Parent3.prototype.getName = function () {
return this.name;
}
function Child3() {
// 第二次调用 Parent3()
Parent3.call(this);
this.type = 'child3';
}
// 第一次调用 Parent3()
Child3.prototype = new Parent3();
// 手动挂上构造器,指向自己的构造函数
Child3.prototype.constructor = Child3;
var s3 = new Child3();
var s4 = new Child3();
s3.play.push(4);
console.log(s3.play, s4.play); // 不互相影响
console.log(s3.getName()); // 正常输出'parent3'
console.log(s4.getName()); // 正常输出'parent3'-
原型式继承
ES5 里面的 Object.create 方法,这个方法接收两个参数:一是用作新对象原型的对象、二是为新对象定义额外属性的对象(可选参数)
let parent4 = {
name: "parent4",
friends: ["p1", "p2", "p3"],
getName: function() {
return this.name;
}
};
let person4 = Object.create(parent4);
person4.name = "tom";
person4.friends.push("jerry");
let person5 = Object.create(parent4);
person5.friends.push("lucy");
console.log(person4.name);
console.log(person4.name === person4.getName());
console.log(person5.name);
console.log(person4.friends);
console.log(person5.friends);-
寄生式继承
使用原型式继承可以获得一份目标对象的浅拷贝,然后利用这个浅拷贝的能力再进行增强,添加一些方法,这样的继承方式就叫作寄生式继承
let parent5 = {
name: "parent5",
friends: ["p1", "p2", "p3"],
getName: function() {
return this.name;
}
};
function clone(original) {
let clone = Object.create(original);
clone.getFriends = function() {
return this.friends
};
return clone;
}
let person5 = clone(parent5);
console.log(person5.getName());
console.log(person5.getFriends());-
寄生组合式继承(相对最优)
function clone (parent, child) {
// 这里改用 Object.create 就可以减少组合继承中多进行一次构造的过程
child.prototype = Object.create(parent.prototype);
child.prototype.constructor = child;
}
function Parent6() {
this.name = 'parent6';
this.play = [1, 2, 3];
}
Parent6.prototype.getName = function () {
return this.name;
}
function Child6() {
Parent6.call(this);
this.friends = 'child5';
}
clone(Parent6, Child6);
Child6.prototype.getFriends = function () {
return this.friends;
}
let person6 = new Child6();
console.log(person6);
console.log(person6.getName());
console.log(person6.getFriends());· Java中创建链表,实现链表的尾部插入
package test;
class Node_5{
private String data;
public Node_5 nextNode;
public void setData(String indata){
this.data=indata;
}
public String getData(){
return this.data;
}
public void setNextNode(Node_5 newNode){
this.nextNode=newNode;
}
public Node_5 getNextNode(){
return this.nextNode;
}
public void addData(String indata){
setData(indata);
Node_5 node_5=new Node_5();
Node_5 head=node_5;
if(node_5.getData()==null){
node_5.setData(indata);
System.out.println(node_5.getData());
}
else{
node_5.setNextNode(node_5);
node_5.setData(indata);
System.out.println(node_5.getData());
}
}
}
public class T_5 {
public static void main(String[] args) {
// TODO Auto-generated method stub
Node_5 node_5=new Node_5();
for(int i=1;i<=3;i++){
node_5.addData("第"+i+"结点");
}
}
}· html 的 dom 树如何生成的
HTML DOM 是 HTML 的标准对象模型和编程接口, 是关于如何获取、更改、添加或删除 HTML 元素的标准。
首先树构建器接收到标签解析器发来的起始标签名后,会加入到栈中,图1是解析到标签的栈中压入的内容,共有
三个标签,此时还未向DOM树中添加任何结点(图中黑色实线框代表开始标签,红色虚线框代表结束标签,结束标签不会入栈)
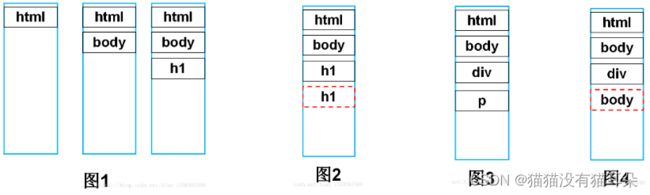
继续向下解析,接收到一个结束标签,此时查询栈顶元素,如果和传入的结束标签属于同种类型的p标签(如图2),则将栈顶元素弹出,向DOM树中加入此节点,然后继续向下解析(如图3)如果遇到的是没有封闭标签的元素如,则直接加入DOM树中即可,无需入栈。依次向下解析,当栈为空,即根节点也加入到DOM树中,DOM树构建完毕。
· 小程序和 pc 页面有什么差异
- 两者运行环境不同
- 开发成本不同
- 给予用户的体验感不同
- 策略定位不同
- 基本元素不一样,小程序加载更快
- 打开渠道不一样,网页应用范围更广
- 安全性不一样,小程序相对更安全
· 任务队列算法题
设计一个任务队列,有on,trigger和off方法,分别完成注册事件触发回调,触发当前事件全部回调,和取消当前事件的任务队列的功能
function EventsQ(){
this._events = {}
}
EventsQ.prototype.on = function(fn){
this._events[fn] = fn
}
EventsQ.prototype.trigger = function(){
for(let fn in this._events){
this._events[fn]()
}
}
EventsQ.prototype.off = function(fn){
delete this._events[fn]
}
var e = new EventsQ()
e.on(()=>{
console.log(111)
})
e.on(()=>{
console.log(222)
})
var a = function(){
console.log('aaa')
}
e.on(a)
e.off(a)
e.trigger()· Java中将一个数组里的值复制到另一个数组中
int[] a = new int[] {18, 62, 68, 82, 65, 9};
int[] b = new int[3]; //分配了长度为3的空间,但没有赋值
//通过数组赋值把 a数组的前3位赋值到b数组
//方法一:for循环
for (int i = 0; i < b.length; i++){
b[i] = a[i];
}
//方法二: System.arraycopy(src, srcPos, dest, destPos, length)
//src: 源数组
//srcPos: 从源数组复制数据的起始位置
//dest: 目标数组
//destPos: 复制到目标数组的起始位置
//length: 复制的长度
System.arraycopy(a, 0, b, 0, 3); //将a从0下标开始长度为3的元素复制给b从0开始长度为3的元素· 前端打包工具-webpack和rollup的区别
- 特性
- webpack 拆分代码, 按需加载;
- Rollup 所有资源放在同一个地方,一次性加载,利用 tree-shake 特性来剔除项目中未使用的代码,减少冗余,但是webpack2已经逐渐支持 tree-shake
- 资源
webpack 相对来说拥有更大的社区支持,资源更加齐全,文档更加完整,有更完整的插件库,如热更新及web-server等。
- 结论
对于应用使用 webpack,对于类库使用 Rollup
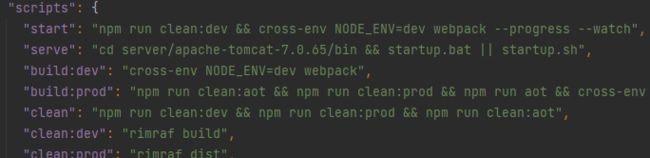
· npm 的命令写在 package.json 的哪个字段(scripts 字段)
· webpack 的热更新
webpack-dev-server启动的时候会做三件事情
- 启动webpack,生成compiler实例,compiler实例的功能很多,比如用来启动webpack的编译工作,监听文件变化等
- 使用Express启动一个本地服务,使得浏览器可以访问本地服务
- 启动websocket服务,用于浏览器和本地node服务进行通讯
· 用 promise 实现一个定时器,每隔一秒输出数组中的一个数字
- 利用promise结合数组的rduce方法
let arr = [1, 2, 3];
arr.reduce((pre, cur) => {
return pre.then(() => {
return new Promise(r => {
setTimeout(() => {
r(console.log(cur))
}, 1000);
})
})
}, Promise.resolve())· 最长无重复子数组

import java.util.*;
public class Solution {
//核心思想就是记录最长连续不重复的,重复的会被去除就不是最长
public int maxLength (int[] arr) {
// write code here
LinkedList list = new LinkedList<>();
int res=0;
for(int i=0;i=0){
list.removeFirst();
}
}
//无重复,则添加进list
list.add(arr[i]);
//更新大小,如上面res=3,list.size()=2,res还是为3
res=Math.max(res,list.size());
}
return res;
}
} · var 和 const 的区别
-
var 声明的范围是函数作用域,let 和 const 声明的范围是块作用域
-
var 声明的变量会被提升到函数作用域的顶部,let 和 const 声明的变量不存在提升,且具有暂时性死区特征
-
var 允许在同一个作用域中重复声明同一个变量,let 和 const 不允许
-
在全局作用域中使用 var 声明的变量会成为 window 对象的属性,let 和 const 声明的变量则不会
-
const 的行为与 let 基本相同,唯一 一个重要的区别是,使用 const 声明的变量必须进行初始化,且不能被修改
| 关键字 | 变量提升 | 块级作用域 | 重复声明同名变量 | 重新赋值 |
|---|---|---|---|---|
| var | √ | × | √ | √ |
| let | × | √ | × | √ |
| const | × | √ | × | × |
· 闭包
闭包是一个函数定义和函数表达式位于另一个函数的函数体内(嵌套函数) ,内部函数会在外部函数返回后被执行,创建闭包的常见方式,就是在一个函数内部创建另一个函数。
- 闭包形成的原理
作用域链,当前作用域可以访问上级作用域中的变量
- 闭包带来的问题
由于垃圾回收器不会将闭包中变量销毁,于是就造成了内存泄露,内存泄露积累多了就容易导致内存溢出
- 闭包的应用
- 应用场景,设置私有变量的方法
- 能够模仿块级作用域,能够实现柯里化,在构造函数中定义特权方法、Vue中数据响应式Observer中使用闭包等
-
闭包的特点
-
函数嵌套函数
-
函数内部可以引用函数外部的参数和变量
-
参数和变量不会被垃圾回收机制回收
· 变量提升和函数提升
- 变量提升
在ES6之前,JavaScript没有块级作用域(一对花括号{}即为一个块级作用域),只有全局作用域和函数作用域。变量提升即将变量声明提升到它所在作用域的最开始的部分。全局变量提升到全局作用域的最开始,函数中的局部变量则提升到函数的最开始。
(注意:函数内部声明变量的时候,一定要使用var命令。如果不用的话,你实际上声明了一个全局变量!)
- 函数提升
js中创建函数有两种方式:函数声明式和函数字面量式。只有函数声明才存在函数提升!
· 常用的npm包
- Moment.js
moment是一个支持多语言的日期处理类库
- Day.js
Day.js可以为现代浏览器解析、验证、操作和显示日期和时间
- lodash.js
lodash.js是一个一致性、模块化、高性能的JavaScript实用工具库,Lodash的模块化方法非常适用于:遍历array、object 和 string 对值进行操作和检测,创建符合功能的函数
- Uuid
uuid是能够快速生成更为复杂的通用唯一标识符(UUID)
- Mock.js
Mock.js 是一个模拟数据生成器,可帮助前端开发和原型与后端进度分开,并减少某些单调性
· webpack之编写loader
loader加载器是webpack的核心之一,其用于将不同类型的文件转换为webpack可识别的模块,即用于把模块原内容按照需求转换成新内容,用以加载非js模块,通过配合扩展插件,在webpack构建流程中的特定时机注入扩展逻辑来改变构建结果,从而完成一次完整的构建
需要webpack loader来处理,帮助我们将一个非js文件转换为js文件,例如css-loader、ts-loader、file-loader等等。
· DNS 是基于 TCP 还是 UDP
DNS可以同时使用TCP和UDP传输协议。 但是由于其简单性和速度,一般使用基于UDP协议
DNS在区域传输的时候使用TCP协议,其他时候使用UDP协议
· Vue 的响应式原理
Vue响应式原理的核心之一就是发布订阅模式。它定义的是一种依赖关系,当一个状态发生改变的时候,所有依赖这个状态的对象都会得到通知
比较典型的就是买东西,比如A想买一个小红花,但是它缺货了,于是A就留下联系方式,等有货了商家就通过A的联系方式通知他。后来又来了B、C...,他们也想买小红花,于是他们都留下了联系方式,商家把他们的联系方式都存到小红花的通知列表,等小红花有货了,一并通知这些人。
· 简单介绍 node 事件循环机制
node 环境下的事件循环中的宏任务和浏览器的有点不一样,node 中的宏任务分成了几种不同的阶段:
- setTimeout 和 setInterval 属于 timers 阶段
- setImmdiate 属于 check 阶段
- socket.on('close', ...) 的关闭事件属于 close callbacks 阶段
- 其他所有的宏任务都属于 poll 阶段
- node 中只要执行到某个阶段,就会执行完该阶段的所有任务。
浏览器下,是在每个宏任务执行完后,接着清空微任务队列,然后才会执行下一个宏任务。
而 node 的 process.nextTick() 会在每个阶段的后面执行,但是会优先于微任务。