一次JSF上线问题引发的MsgPack深入理解,保证对你有收获
作者: 京东零售 肖梦圆
前序
某一日晚上上线,测试同学在回归项目黄金流程时,有一个工单项目接口报JSF序列化错误,马上升级对应的client包版本,编译部署后错误消失。
线上问题是解决了,但是作为程序员要了解问题发生的原因和本质。但这都是为什么呢?
第一个问题:为什么测试的时候没有发现问题呢?
首先预发环境中,所有项目中的JSF别名和client包都是beta,每天都有项目进行编译部署,这样每个项目获取的都是最新的client包,所以在预发环境测试没有发现
第二个问题:为什么会出现序列化问题?
JDer的开发们都知道JSF接口如果添加字段需要在类的最后进行添加,对此我检查了自己的代码发现我添加的代码也是在类的最后进行添加的,但是特殊之处在于这是一个父类,有子类进行继承
第三个问题:如果在父类上添加一个字段有什么影响呢?
说实话,猛的这么一问,我犹豫了,JDer们都知道JSF的默认序列化使用的是MsgPack,一直都是口口相传说如果client类添加字段必须在类的最后,但是也没人告诉父类添加字段咋办呀,父子类这种场景MsgPack是如何处理序列化和反序列化的?
第四个问题:MsgPack是什么?MsgPack的序列化和反序化是怎么实现的?
对此问题我坦白了,我不知道;是否有很多JDer跟我对于MsgPack的认识仅限于名字的吗,更别提是如何实现序列化和反序列化了
到此我已经积累了这么多问题了,是时候努力了解一下MsgPack了,看看什么是MsgPack,为什么JSF的默认序列化选择MsgPack呢?
msgpack介绍
官网地址: https://msgpack.org/
官方介绍:
It’s like JSON. but fast and small.
翻译如下:
这就像JSON,但更快更小
MessagePack 是一种高效的二进制序列化格式。它允许您在多种语言(如 JSON)之间交换数据。但是速度更快,体积更小。小整数被编码成一个字节,而典型的短字符串除了字符串本身之外只需要一个额外的字节。
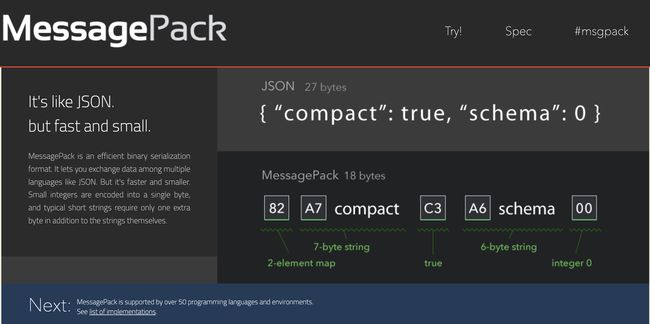
JSON格式占用27字节,msgpack只占用18字节
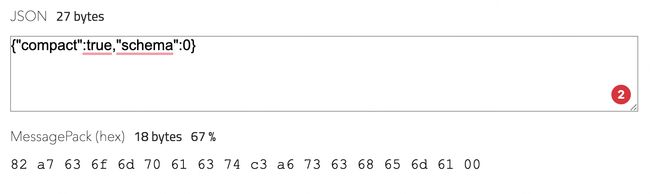
msgpack 核心压缩规范
msgpack制定了压缩规范,这使得msgpack更小更快。我们先了解一下核心规范:
| format name | first byte (in binary) | first byte (in hex) |
|---|---|---|
| positive fixint | 0xxxxxxx | 0x00 - 0x7f |
| fixmap | 1000xxxx | 0x80 - 0x8f |
| fixarray | 1001xxxx | 0x90 - 0x9f |
| fixstr | 101xxxxx | 0xa0 - 0xbf |
| nil | 11000000 | 0xc0 |
| (never used) | 11000001 | 0xc1 |
| false | 11000010 | 0xc2 |
| true | 11000011 | 0xc3 |
| bin 8 | 11000100 | 0xc4 |
| bin 16 | 11000101 | 0xc5 |
| bin 32 | 11000110 | 0xc6 |
| ext 8 | 11000111 | 0xc7 |
| ext 16 | 11001000 | 0xc8 |
| ext 32 | 11001001 | 0xc9 |
| float 32 | 11001010 | 0xca |
| float 64 | 11001011 | 0xcb |
| uint 8 | 11001100 | 0xcc |
| uint 16 | 11001101 | 0xcd |
| uint 32 | 11001110 | 0xce |
| uint 64 | 11001111 | 0xcf |
| int 8 | 11010000 | 0xd0 |
| int 16 | 11010001 | 0xd1 |
| int 32 | 11010010 | 0xd2 |
| int 64 | 11010011 | 0xd3 |
| fixext 1 | 11010100 | 0xd4 |
| fixext 2 | 11010101 | 0xd5 |
| fixext 4 | 11010110 | 0xd6 |
| fixext 8 | 11010111 | 0xd7 |
| fixext 16 | 11011000 | 0xd8 |
| str 8 | 11011001 | 0xd9 |
| str 16 | 11011010 | 0xda |
| str 32 | 11011011 | 0xdb |
| array 16 | 11011100 | 0xdc |
| array 32 | 11011101 | 0xdd |
| map 16 | 11011110 | 0xde |
| map 32 | 11011111 | 0xdf |
| negative fixint | 111xxxxx | 0xe0 - 0xff |
示例解读:
json串:{“compact”:true,“schema”:0}
对应的msgpack为:82 a7 63 6f 6d 70 61 63 74 c3 a6 73 63 68 65 6d 61 00
第一个82,查看规范表,落在fixmap上,fixmap的范围:0x80 - 0x8f,表示这是一个map结构,长度为2
后面一个为a7,查看规范表,落在fixstr的范围:0xa0 - 0xbf,表示是一个字符串,长度为7,后面7个为字符串内容:63 6f 6d 70 61 63 74 将16进制转化为字符串为:compact
往后一个为:c3,落在true的范围:oxc3
再往后一个为:a6,查看规范表,落在fixstr的范围:0xa0 - 0xbf,表示是一个字符串,长度为6,后面6个字符串内容为:
73 63 68 65 6d 61,将16进制转化为字符串为:schema
最后一个为:00,查看规范表,落在positive fixint,表示一个数字,将16进制转为10进制数字为:0

拼装一下{ “compact” : true , “schema” : 0 }
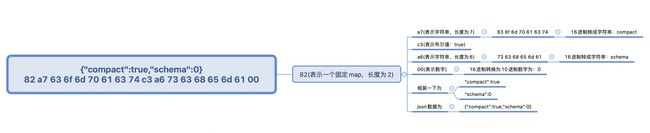
我们看一下官方给出的stringformat示意图:

对于上面的问题,一个长度大于15(也就是长度无法用4bit表示)的string是这么表示的:用指定字节0xD9表示后面的内容是一个长度用8bit表示的string,比如一个160个字符长度的字符串,它的头信息就可以表示为D9A0。
举一个长字符串的例子:
{“name”:“fatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfatherfather”,“age”:10,“childerName”:“childer”}
83 A4 6E 61 6D 65 DA 03 06 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 66 61 74 68 65 72 A3 61 67 65 0A AB 63 68 69 6C 64 65 72 4E 61 6D 65 A7 63 68 69 6C 64 65 72
一起解析一下看看
83:这个大家都已经知道了,一个固定的map,长度为3
A4:fixstr(长度4),然后找到后面四位
6E 61 6D 65:16进制转为字符串:name
DA:str 16 ,后面两个字节为长度
03 06:16进制转化为10进制:774
后面774个字节转化为字符串:

A3: fixstr(长度3),然后找到后面三位
61 67 65 :16进制转为字符串:age
0A :16进制转10进制:10
AB :fixstr(长度11),然后找到后面11位
63 68 69 6C 64 65 72 4E 61 6D 65 :16进制转为字符串:childerName
A7 : fixstr(长度7),然后找到后面七位
63 68 69 6C 64 65 72 :16进制转为字符串:childer
问题原因解析
先还原事件过程,我们在父类的最后添加一个字段,然后创建一个子类继承父类,然后进行模拟序列化和反序化,查找问题
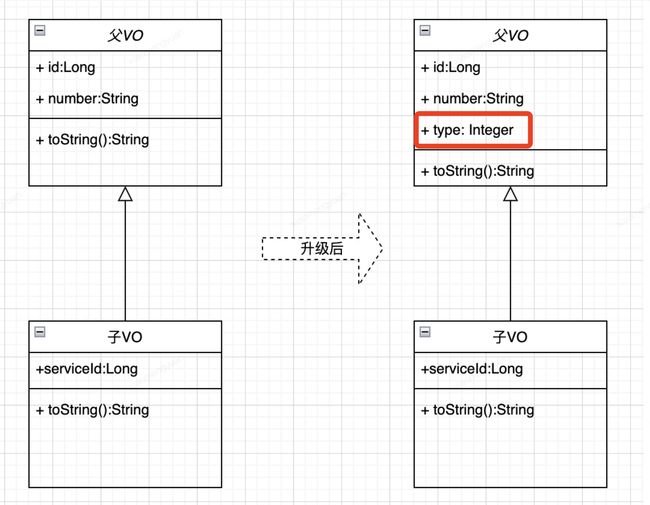
第一步:模拟父子类,输出16进制数据
先声明一个父子类,然后进行序列化
父类:
public class FatherPojo implements Serializable {
/**
* name
*/
private String name;
}
子类:
public class ChilderPojo extends FatherPojo implements Serializable {
private String childerName;
}
使用官方的序列化包进行序列化
org.msgpack
jackson-dataformat-msgpack
(version)
测试代码如下:
public class Demo {
public static void main(String[] args) throws JsonProcessingException {
ObjectMapper objectMapper = new ObjectMapper(new MessagePackFactory());
ChilderPojo pojo = new ChilderPojo();
pojo.setName("father");
pojo.setChilderName("childer");
System.out.println(JSON.toJSON(pojo));
byte[] bytes = objectMapper.writeValueAsBytes(pojo);
//输出16进制
System.out.println(byteToArray(bytes));
}
/**
* byte数组转化为16进制数据
*/
public static String byteToArray(byte[]data) {
StringBuilder result = new StringBuilder();
for (int i = 0; i < data.length; i++) {
result.append(Integer.toHexString((data[i] & 0xFF) | 0x100).toUpperCase().substring(1, 3)).append(" ");
}
return result.toString();
}
}
输入结果如下:
{“name”:“father”,“childerName”:“childer”}
82 A4 6E 61 6D 65 A6 66 61 74 68 65 72 AB 63 68 69 6C 64 65 72 4E 61 6D 65 A7 63 68 69 6C 64 65 72
拿着json数据去messagepack官网也获取一下16进制数据,跟如上代码输出的结果是一样的。

第二步:在父类的结尾增加一个字段,然后输出16进制数组
修改父类,增加一个age字段
public class FatherPojo implements Serializable {
/**
* name
*/
private String name;
/***
* age
*/
private Integer age;
}
修改测试代码,给父类的age赋值
public class Demo {
public static void main(String[] args) throws JsonProcessingException {
ObjectMapper objectMapper = new ObjectMapper(new MessagePackFactory());
ChilderPojo pojo = new ChilderPojo();
pojo.setName("father");
pojo.setChilderName("childer");
pojo.setAge(10);
System.out.println(JSON.toJSON(pojo));
byte[] bytes = objectMapper.writeValueAsBytes(pojo);
//输出16进制
System.out.println(byteToArray(bytes));
}
/**
* byte数组转化为16进制数据
*/
public static String byteToArray(byte[]data) {
StringBuilder result = new StringBuilder();
for (int i = 0; i < data.length; i++) {
result.append(Integer.toHexString((data[i] & 0xFF) | 0x100).toUpperCase().substring(1, 3)).append(" ");
}
return result.toString();
}
}
输入结果如下:
{“name”:“father”,“age”:10,“childerName”:“childer”}
83 A4 6E 61 6D 65 A6 66 61 74 68 65 72 A3 61 67 65 0A AB 63 68 69 6C 64 65 72 4E 61 6D 65 A7 63 68 69 6C 64 65 72
拿着json数据去messagepack官网也获取一下16进制数据,跟如上代码输出的结果是一样的。

先对比json数据
父类没加字段之前:{“name”:“father”,“childerName”:“childer”}
父类加字段之后: {“name”:“father”,“age”:10,“childerName”:“childer”}
对比一下前后两次16进制数组,我们进行对齐后进行对比一下
82 A4 6E 61 6D 65 A6 66 61 74 68 65 72 AB 63 68 69 6C 64 65 72 4E 61 6D 65 A7 63 68 69 6C 64 65 72
83 A4 6E 61 6D 65 A6 66 61 74 68 65 72 A3 61 67 65 0A AB 63 68 69 6C 64 65 72 4E 61 6D 65 A7 63 68 69 6C 64 65 72
对比发现在红色部分是多出来的一部分数据应该就是我们添加的age字段,现在我们进行解析对比一下。

拼装一下{ “name”: “father”, “childerName” : “childer” }

拼装一下{ “name”: “father”, “age”: 10 “childerName” : “childer” }
第三步:直接对二进制数据解包
1、先用正确的顺序解包
public static void analyze(byte[] bytes) throws IOException {
MessageUnpacker unpacker = MessagePack.newDefaultUnpacker(bytes);
int length = unpacker.unpackMapHeader();
String name = unpacker.unpackString();
String nameValue = unpacker.unpackString();
String age = unpacker.unpackString();
Integer ageValue = unpacker.unpackInt();
String childerName = unpacker.unpackString();
String childerNameValue = unpacker.unpackString();
System.out.println("{""+name+"":""+nameValue+"",""+age+"":"+ageValue+",""+childerName+"":""+childerNameValue+""}");
}
输出结果为:
{“name”:“father”,“age”:10,“childerName”:“childer”}
2、如果我们客户端没有升级client包版本,使用了错误的解包顺序
public static void analyze(byte[] bytes) throws IOException {
MessageUnpacker unpacker = MessagePack.newDefaultUnpacker(bytes);
int length = unpacker.unpackMapHeader();
String name = unpacker.unpackString();
String nameValue = unpacker.unpackString();
String childerName = unpacker.unpackString();
String childerNameValue = unpacker.unpackString();
System.out.println("{""+name+"":""+nameValue+"",""+childerName+"":""+childerNameValue+""}");
}
解析报错:反序列化失败

从上述案例中发现在父类中增加数据,相当于在子类中间增加数据导致子嘞反序列化失败。需要注意的是解包顺序必须与打包顺序一致,否则会出错。也就是说协议格式的维护要靠两端手写代码进行保证,而这是很不安全的。
JSF为什么选择MsgPack以及官方FAQ解释
为什么JSF会选择MsgPack作为默认的序列化
JDer的开发们用的RPC基本上都是JSF,在远程调用的过程中字节越少传输越快越安全(产生丢包的可能性更小), 咱们回过头去看看MsgPack; 我们了解了MsgPack的压缩传输可以看到,MsgPack序列化后占用的字节更小,这样传输的更快更安全;所以这应该就是JSF选择Msgpack作为默认序列化的原因了。我理解MsgPack是采用一种空间换时间的策略,减少了在网络传输中的字节数,使其更安全,然后在接到序列化后的数据后按照压缩规范进行反序列化(这部分增加了cpu和内存的使用,但是减少了网络传输中时间且提高了传输安全性)。
JSF对父子类序列化的FQA解释

是时候进行总结和说再见了
总结:
1、MessagePack 是一种高效的二进制序列化格式。 它允许您在多种语言(如 JSON)之间交换数据。 但是速度更快,体积更小。