图像视频降噪的现在与未来——从经典方法到深度学习

Photo by Jason Rosewell on Unsplash
噪声是图像与视频中的一种常见失真类型,也是腾讯多媒体实验室以及腾讯云提供的多种失真处理能力之一。本分享总结了噪声产生的几个原因,从理论上分析降噪的基本原理,并介绍了使用传统方法和深度学习进行单帧降噪、多帧降噪和视频降噪的技术。
文 / 李松南
整理 / LiveVideoStack
1. 简介
1.1 腾讯多媒体实验室
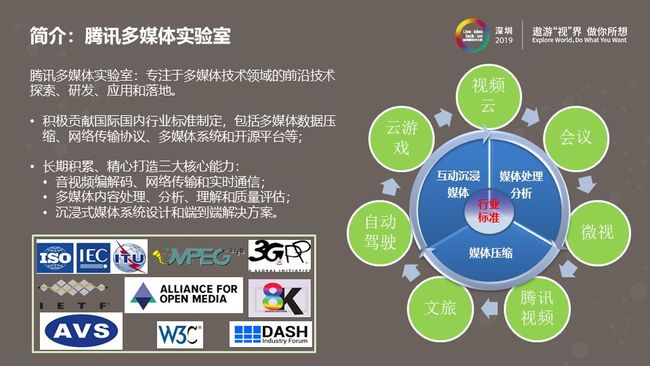
大家好,我是来自腾讯多媒体实验室的李松南,本次分享将为大家介绍传统降噪和深度学习降噪方法,以及降噪技术未来的发展趋势。腾讯多媒体实验室专注于多媒体技术领域的前沿技术探索、研发、应用和落地,在长期积累中精心打造出三大核心能力,分别是:音视频编解码、网络传输和实时通信;多媒体内容处理、分析、理解和质量评估;沉浸式媒体系统设计和端到端解决方案。本次分享中的内容就属于多媒体内容处理的一部分。
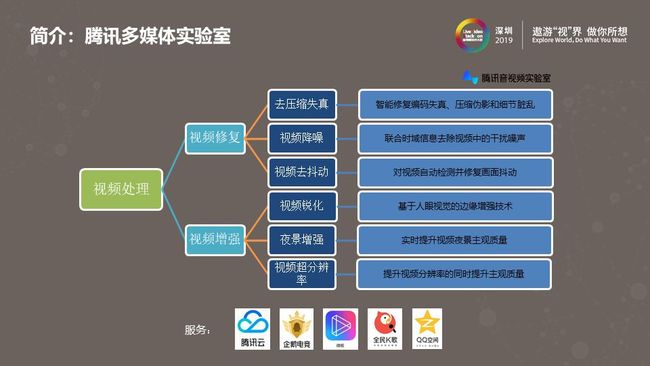
上图是腾讯多媒体实验室常年积累起来的视频处理能力,包括视频降噪、去压缩失真、视频去抖动、夜景增强、视频超分、视频锐化等,这些能力已经应用于腾讯的许多产品,比如腾讯云、全民K歌、企鹅电竞、微视、QQ空间等。目前团队正在向腾讯云推出画质修复功能,已经开发和计划开发的技术,包括视频超分、去伪影、去抖动、去划痕与雪花、插帧、HDR,还有下面主要介绍的视频降噪技术。
1.2 噪声的来源

图像、视频从采集到播放的整个生命周期中会经历各种各样的处理过程,比如采集、剪辑、编码、转码、传输、显示等,每个处理过程都会引入失真。“噪声”就是在信号采集过程中引入的一种普遍失真。降低噪声强度可以使图像主观效果更好。另外,在图像、视频压缩时也不必浪费码率在编码噪声上。同时,会使得视频编码中的运动估计更准确、熵编码速度更快。

噪声的来源有多种,其中最主要的部分来自光子散粒噪声。上图描述的是从感光元器件收集到光子,一直到生成数字图像的过程。首先感光元器件把光子转换成电子,电子形成电压,电压放大后量化,最终形成数字图像。光子散粒噪声在感光元器件接收光子时就发生了。
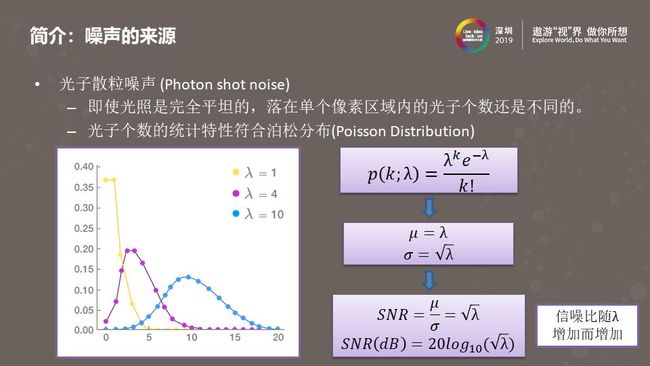
即使光线是完全平坦的,感光元器件每个像素接受到的光子个数也是不同的。像素接收到光子个数的分布,符合一个经典的离散概率分布模型—泊松分布。上图中右侧是泊松分布的数学公式,他的均值是λ,标准差是√λ,而均值和标准差分别对应了信号以及噪声的强度。均值和标准差的比值就是信噪比。可以看到,信噪比是随λ增加而增加的,信噪比越高意味着主观感受到的噪声越小,这里的λ可以理解为每个像素接收到的光子个数。因此,我们可以通过提高单位像素面积内接受到的光子个数来降低人眼感知到的噪声强度。不论是硬件降噪或是软件降噪,很多降噪方法都利用到了这个原理。

除了光子散粒噪声外,噪声来源还包括暗电流噪声、热点噪声、固定模式噪声以及读出噪声。这些噪声或者与电路热扰动释放的电子有关,或者与感光元器件在制造过程中产生的缺陷有关。其中,暗电流噪声和热点噪声与曝光时间有关,曝光时间越长,这两类噪声的强度越大。上图中左下部分给出的是关于信号和噪声强度的一个更精确的公式。
1.3 硬件降噪方法

通常的硬件降噪方法都是通过增加单位像素接收到的光子个数来增加图像的信噪比的。比如,增加感光元器件的尺寸,在像素个数固定的情况下,每个像素的面积增大了,单位时间内接收到的光子个数就变多了。另外还可以增大光圈,通过增加进光亮,使得感光元器件上接收到的光子个数增加。背照式和堆栈式的CMOS通过将感光元器件的处理电路下移,减少电路对光线的反射和吸收,增加感光区域的实际占比。有些感光元器件为了接收到更多的光子去掉了彩色滤光片,这样可以在暗光下有更好的噪声表现,但缺点是只能拍摄灰度图像,需要结合正常摄像头一起使用。最后是像素融合,如右上图所示,在光线较暗的情况下,可以将四个像素当作一个像素使用,这样每个像素接受的光子数就增多了。
2. 传统降噪方法
2.1 单帧降噪
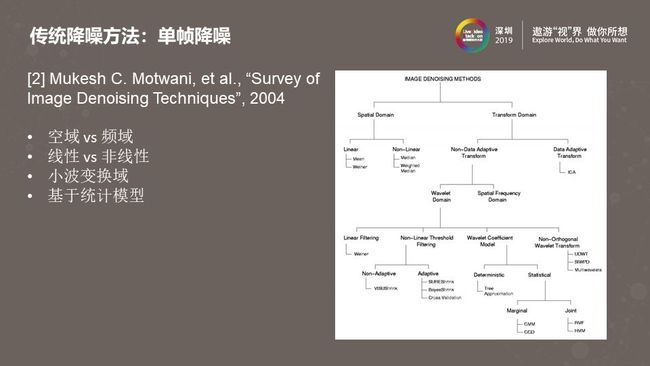
分析完硬件降噪之后,我们来看看对单幅图像的传统降噪方法。上图来自于2004年的一篇综述文章,可以看到单帧降噪算法可以做很多种不同的分类,比如线性/非线性、空域/频域,频域又包括小波变换域、傅里叶变换域或其他变换域。从图中可以看到,在小波域中做单帧降噪算法的种类是比较多的,小波域结合统计建模是当时比较流行的研究方法。

上图简单粗暴的将单帧降噪方法归类为速度快的和效果好两种类型。这样的分类方法虽然并不科学,但大致反映了实际情况:单帧降噪算法往往需要在速度和效果之间权衡,使用纯软件的方式很难实现出既快又好的单帧降噪方法。

上面的PPT中包含了双边滤波和小波变换的示意图。通常我们会拿双边滤波和高斯滤波进行对比。对于高斯滤波来说,在处理当前像素的过程中会用到当前像素附近的像素做加权平均,权重取决于当前像素和周围像素的距离,距离越远则权重越小。双边滤波除了考虑距离之外,还会考虑当前像素和周围像素颜色的差异,对距离近但颜色差异大的像素会分配一个小的权重,这样做就不会模糊了边界,实现了保持边界的滤波。右侧是小波变换的示意图,在小波变换之后信号被分解到不同频带,同时每个频带还保留了一定的空域信息。通过对这些小波系数做阈值处理、滤波或者基于统计建模的处理,再反变换回空域,可以实现有效的降噪效果。
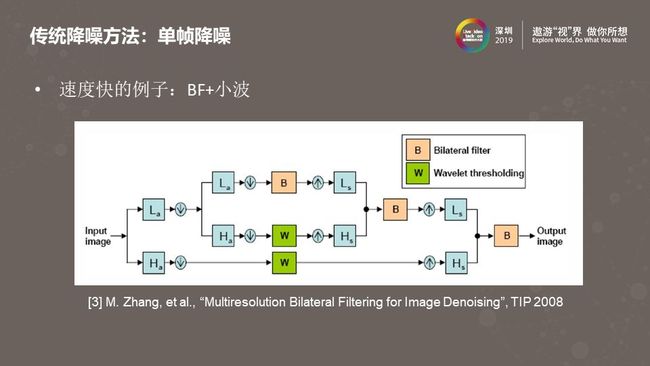
上图来自2008年的一篇文章,它结合了小波变换和双边滤波两种方法,对低频信号做双边滤波,对高频信号做阈值处理,结合之后生成低频信号再做双边滤波,如此反复。这个方法的优势是可以针对不同的频带调节降噪的强度,同时保持了边界。适用范围广,可以针对不同的摄像头模组调节降噪参数,所以很多基于硬件的单帧降噪模块使用的就是小波变换结合双边滤波的方法。
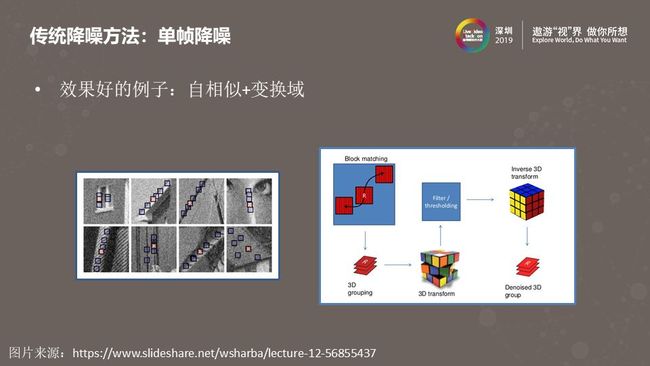
上图给出了一个“效果好”的例子,自相似结合变换域。左边的图解释的是自相似的概念,对每个块在图像内进行搜索,找到与之相似的一系列块。经典的非局部平均(Non-Local Means)降噪算法会将这些相似块在空间域做加权平均。如果更近一步,将这些相似块变换到频域,在频域做一些滤波和阈值处理之后再转换回空间域,就是自相似与变换域结合的方法,比如经典的单帧降噪算法BM3D利用的就是这样的原理。类似的,还有自相似结合稀疏编码、自相似结合低秩等,都可以实现很好的单帧降噪效果。
2.2 多帧降噪

接下来介绍一下传统的多帧降噪方法。在光线比较暗的情况下,我们用手机拍照按下快门的时刻,会记录下多张图像,算法会将这些图像做对齐、融合,形成一张图像。这样做相当于延长了曝光时间,使得感光元器件接收到了更多的光子,增加了信噪比,同时又不会因为手持相机和曝光时间过长而导致图像模糊。如果对四张图像做对齐融合,则相当于每个像素多采集到了四倍数量的光子,换算成信噪比有6分贝的提升,这对于图像质量来说是一个非常可观的数字。多帧降噪的主要步骤有两个:对齐和融合。对齐就是找到多个图像中像素(块)的对应关系;融合是将这些对应的像素(块)在空域或者频域做加权平均。为了确定加权平均的权重值,我们需要知道像素(块)之间的差异是由于对齐不准造成的还是因为噪声造成的,因此需要估计噪声强度。一个准确的噪声强度估计算法,对多帧降噪的效果会起到至关重要的作用。
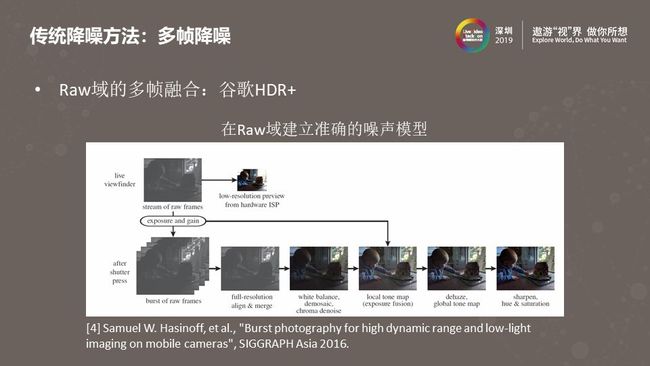
上图是谷歌在2016年发表的一篇手机图像质量增强的文章,介绍的是HDR+算法,用在了谷歌手机上。HDR+有很多图像处理模块,其中就包括了刚才介绍的多帧降噪。HDR+的多帧降噪实现在Raw域,由于Raw域的图像没有经过后续非线性图像处理模块的影响,所以可以在Raw域中对图像中的噪声进行比较精确地建模,有了噪声建模的结果之后就可以对噪声强度做估计并运用到多帧降噪算法中去。
2.3 视频降噪
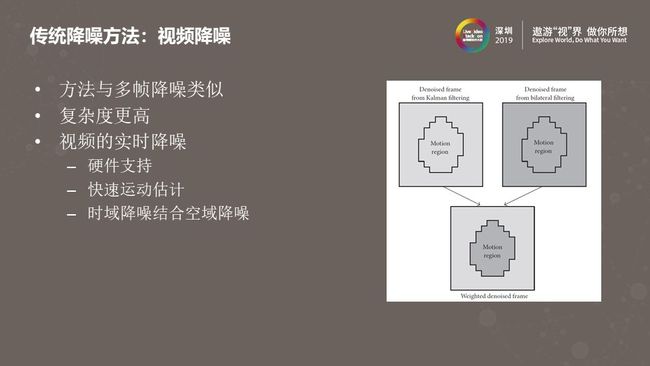
视频降噪与上面介绍的多帧降噪类似,为了达到更好的降噪效果也会用到临近帧的信息,把临近帧中相似的像素块做融合处理。在手机端对视频的每一帧做这样的操作,又要保持实时性是很困难的。因此需要硬件的支持,使用快速的对齐算法,或者用运动检测代替运动估计,根据检测到的运动强度,对时域滤波和空域滤波的结果做加权平均。
3. 深度学习降噪方法

基于深度学习的降噪通常会使用图像到图像的卷积网络。右边的示例图给出的是图像到标签和图像到图像卷积网络的对比,可以看出图像到标签的网络在处理大分辨率的图像时,可以先做缩放,把图像分辨率缩小后再输入网络。而对于图像到图像的卷积网络,输入通常是原始分辨率的图像,输出也是同样分辨率的,对于像超分这样的应用,输出的分辨率甚至更大,所以即使卷积层的层数非常少,计算复杂度仍然是很高的,对显存的需求也高。另外,基于深度学习的降噪方法通常需要使用含有真实噪声的训练数据才能达到比较好的处理效果。
3.1 单帧降噪网络结构
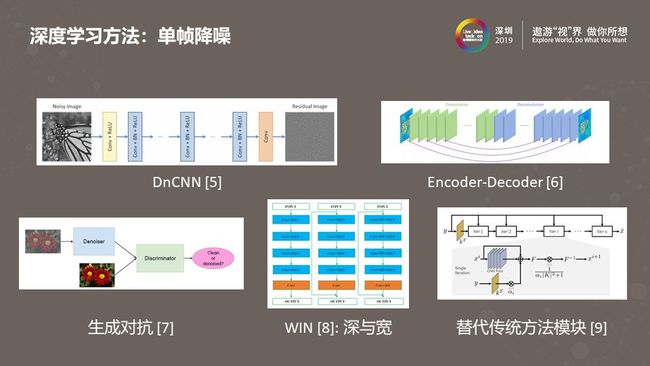
上图列举了几个用于降噪的深度学习算法。参考文献[5]是最早使用深度模型做降噪的文章之一,带有噪声的图像经过一系列的卷积处理,最后生成一张只包含噪声的残差图。参考文献[6]使用自编码结构,编码端由卷积层构成,解码端由反卷积层构成,编码端与解码端有一系列的跳过连接。参考文献[7]使用了生成对抗网络,通过对降噪网络和判别网络做联合优化,提升降噪网络的处理效果。参考文献[8]研究网络的“深”与“宽”对降噪效果的影响,它得出的结论是网络宽一些(更多的通道数、更大的卷积核)会使降噪效果更好。参考文献[9]使用传统方法结合深度学习进行图像处理。这里的传统图像处理方法是一个循环迭代的优化过程,其中的每一步迭代都可以用深度模型替代其中的部分处理过程。
3.2 视频降噪

这里介绍几个使用深度学习做视频降噪的例子。参考文献[10]是DVDNet,它会对当前帧和临近帧做空域上的卷积降噪,然后通过光流网络将临近帧与当前帧对齐,最后在对齐后的图像上做时域降噪。参考文献[11]是DVDNet的加速版,为了提高处理速度,它舍弃了光流对齐,直接把临近帧输入到一个两级的深度网络中做降噪。参考文献[12]提出了EDVR网络,它介于上述两种方法之间,没有用现成的光流对齐方法,也没有完全去掉对齐的过程,而是在一个叫做PCD(Pyramid Cascading Deformable convolution)的模块里将卷积处理后得到的特征图进行对齐。需要指出的是,EDVR并不是用来做降噪的,而是用来做超分和去模糊的,但这样的处理方式同样可以用来做降噪。
3.3 真实噪声数据库

使用深度学习做降噪,训练的过程最好可以使用包含真实噪声的数据库。上图右侧的列表给出了一些包含真实噪声的数据库,每个数据库提供的图像个数并不多。为了训练深度模型,数据库需要提供“无噪声”的图像作为Ground Truth (GT),获得GT的方法主要有两种,一种是使用低ISO长曝光的图像作为GT,另外一种是融合多张高ISO短曝光的图像作为GT。不管使用哪种方法,噪声图像与GT之间还是会存在对齐不准、颜色不匹配的情况,因此还需要做后处理(左下图)才能得到更准确的训练图像对。
3.4 模拟真实噪声
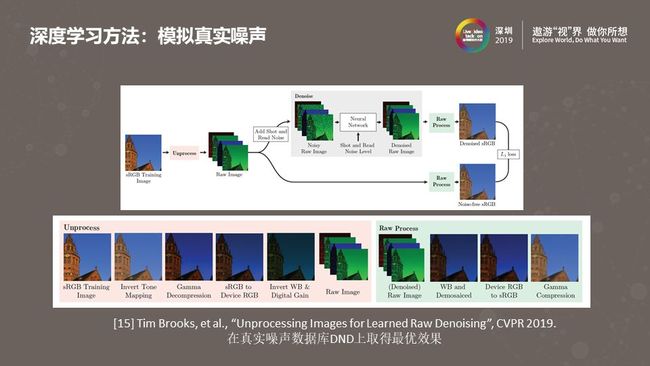
很多早期基于深度学习的降噪方法会使用模拟的噪声图像进行训练。他们会在sRGB空间的“无噪声”图片中加入高斯白噪声或者柏松噪声。用这些方式加入的噪声很不真实,所以训练出的降噪模型效果不好。上图是2019年CVPR发表的一篇文章,文中使用的噪声数据也是模拟出来的,但更精确的模拟了噪声的形态。它模拟ISP的处理过程,对“无噪声“的图像做了一个ISP”反处理“,将图像从sRGB空间变换到Raw域,在Raw域加入光子散粒噪声、读噪声。由于这种方法可以更好的模拟真实拍摄到的噪声图像,学习出的深度降噪模型在DND真实噪声数据集上取得了非常好的效果。
4. 发展趋势
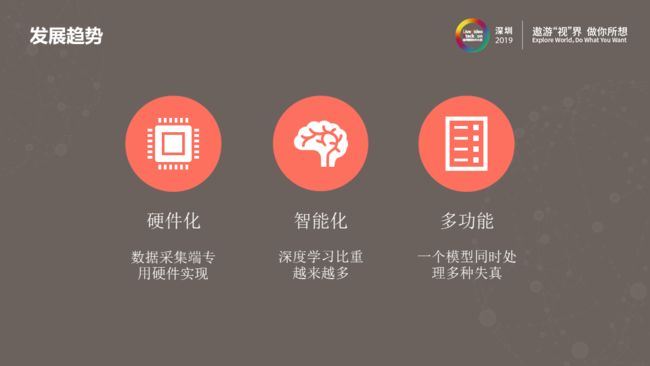
最后我想与大家分享我个人对于降噪技术发展趋势的判断。首先手机上的降噪将逐渐硬件化。目前,手机上的图像降噪效果有很大一部分是软件实现的,比如,之前多数手机是不支持硬件多帧降噪的。而现在越来越多的高、中端手机平台芯片都开始支持多帧降噪、基于运动补偿的视频降噪等。另外一个发展趋势是智能化,既越来越多的使用深度模型进行图像处理。如上所述,深度模型做图像、视频处理速度慢,资源消耗高。但随着终端设备计算能力的不断增强,异构计算平台的发展,以及模型压缩技术的进步,在终端使用深度学习做图像处理会变的越来越多。最后一个趋势是多功能,一个深度模型同时处理多个任务,比如同时实现降噪、超分、增强等功能。硬件化、智能化和多功能将是未来降噪技术的三个发展趋势。
参考文献


LiveVideoStackCon 2020 讲师招募
2020年LiveVideoStackCon将持续迭代,4月在上海,9月在北京,11月在旧金山。欢迎将你的技术实践、踩坑与填坑经历、技术与商业创业的思考分享出来,独乐不如众乐。请将个人资料和话题信息邮件到 [email protected] 或点击【阅读原文】了解成为LiveVideoStackCon讲师的权益与义务,我们会在48小时内回复。