Java Web从入门到实战
??个人博客:www.hellocode.top??
所有文章均在上方博客首发,其他平台同步更新
??本文专栏:《Java Web从入门到实战》
??> 如没有Java基础,请先前往《Java零基础指南》专栏学习相应知识
如有问题,欢迎指正,一起学习~~
文章目录
-
- Linux
-
- 初识Linux
- Linux的安装和使用
-
- Vmware
- SecureCRT
- 目录和文件
- 时间同步
- 克隆与快照
- 系统与设置命令
-
- 账号管理
- 用户组
- 系统管理相关命令
- 进程相关命令
- 目录管理
- 文件基本属性
- 综合案例
- 文件管理
-
- touch
- vi/vim编辑器
- 文件查看
- echo命令
- awk命令
- 软连接
- 压缩命令
-
- 查找命令
- gzip命令
- gunzip命令
- tar命令
- zip命令
- unzip命令
- bzip2命令
- 网络与磁盘管理
-
- 网络管理
- 磁盘管理
- yum
- rpm
- shell
-
- 初识shell
- 注释和变量
- 数组
- 运算符
- 选择语句
- 循环语句
- 函数
- Nginx
-
-
- 概述
- 安装
- 发布项目
-
- JavaWeb核心
-
- 企业开发简介
-
- JavaEE规范
- WEB概述
- 系统结构
- tomcat
-
- 服务器
- Tomcat
- 基本使用
- Java WEB项目
- 配置文件
- HTTP协议
-
- 概述
- 协议的请求
- 协议的响应
- 发布资源案例
-
- Servlet介绍
- Servlet
-
- 概述
- 执行过程
- 实现方式
- 生命周期
- 线程安全问题
- 映射方式
- 创建时机
- 默认Servlet
- ServletConfig
-
- 配置方式
- 常用方法
- ServletContext
-
- 域对象
- 配置方式
- 常用方法
- 注解开发
-
- 自动注解开发
- 手动创建容器(了解)
- 学生管理系统1
- 请求对象
-
- 获取各种路径
- 获取请求头
- 获取请求参数信息
- 流对象获取请求信息
- 中文乱码问题
- 请求域
- 请求转发
- 请求包含
- 响应对象
-
- 常见状态码
- 字节流响应消息
- 字符流响应消息
- 响应图片
- 设置缓存
- 定时刷新
- 请求重定向
- 文件下载
- 学生管理系统2
- Cookie
-
- 会话
- 概述
- Cookie属性
- 方法
- 练习
- 注意事项
- Session
-
- 常用方法
- 对象获取
- 练习
- 注意事项
- JSP
-
- 快速入门
- 执行过程
- 语法
- 指令
- 注意事项
- MVC模型
- 学生管理系统3
- EL表达式
-
- 快速入门
- 获取数据
- 注意事项
- 运算符
- 隐式对象
- JSTL
-
- 核心标签
- Filter
-
- 概述
- FilterChain
- 过滤器使用
- 使用细节
- 生命周期
- FilterConfig
- 五种拦截行为
- Listener
-
- 监听器
- 监听器的使用
- 学生管理系统优化
-
- 解决乱码
- 检查登录
- 优化JSP页面
- MYSQL
-
- 基本概念
-
- 数据库
- Mysql
- 安装
- DDL
-
- 数据库、数据表、数据的关系
- SQL的介绍
- 查询和创建数据库
- 修改、删除、使用数据库
- 查询数据表
- 创建数据表
- 数据表的修改
- 数据表的删除
- DML
-
- 新增表数据
- 修改和删除表数据
- DQL
-
- 查询语法
- 查询全部
- 条件查询
- 聚合函数查询
- 排序查询
- 分组查询
- 分页查询
- 约束
-
- 主键约束
- 主键自增约束
- 唯一约束
- 非空约束
- 外键约束
- 外键级联操作(了解)
- 多表操作
-
- 一对一
- 一对多
- 多对多
- 多表查询
- 练习
- 视图
-
- 数据准备
- 创建和查询
- 修改和删除
- 数据库备份和恢复
- 存储过程和函数
-
- 创建和调用
- 查看和删除
- 变量
- if语句
- 参数传递
- while循环
- 存储函数
- 触发器
-
- 触发器的操作
- 查看和删除
- 事务
-
- 基本使用
- 提交方式
- 四大特征(ACID)
- 隔离级别
- 存储引擎
-
- 体系结构
- 存储引擎
- 基本操作
- 存储引擎的选择
- 索引
-
- 分类
- 创建和查询
- 添加和删除
- 索引的原理
- 设计原则
- 锁
-
- InnoDB共享锁
- InnoDB排他锁
- MyISAM 读锁
- MyISAM 写锁
- 悲观锁和乐观锁
- MyCat
-
- 安装
- 集群环境
- 主从复制
- 读写分离
- 分库分表
- JDBC
-
- 快速入门
- 功能类详解
- 案例
-
- 数据准备
- 需求实现
- 代码展示
- 工具类
-
- 抽取工具类
- 优化学生案例
- 注入攻击
- 事务管理
- 连接池
-
- 自定义数据库连接池
- 归还连接
- 动态代理
- 开源数据库连接池
- 连接池的工具类
- 框架
-
- 源信息
- update方法
- 查询功能
- Mybatis
- JavaScript
- jQuery
- AJAX
- Vue + Element
- Redis
- Maven基础
- Web项目实战-黑马页面
Linux
初识Linux
操作系统:管理计算机硬件与软件资源的计算机程序,同时也是计算机系统的内核与基石。
主流操作系统
- 桌面操作系统:Window系列、macOS、Linux
- 服务器操作系统:Linux、Windows Server
- 嵌入式操作系统:Linux
- 移动设备操作系统:Unix(Linux、ios)
Linux发展历程
- 1984年Minix(只用于教学)
- 1991年编写驱动程序,年底公开Linux内核源码
- 1994年Linux1.0(Linus Torvalds)
- 至此开始流行起来
Linux特点
- Linux是一套免费使用和自由传播的类Unix操作系统
- 是一个基于POSIX和Unix的多用户、多任务、支持多线程和多CPU的操作系统
- 它能运行主要的Unix工具软件、应用程序和网络协议。它支持32位和64位硬件
- 继承了Unix以网络为核心的设计思想,是一个性能稳定的多用户网络操作系统
- 两个基本思想
- 一切都是文件
- 每个软件都有确定的用途
- 完全兼容POSIX1.0标准
- 多用户、多任务
- 良好的界面
- 支持多种平台
Linux与其它操作系统的区别
- 开源情况
- 硬件适用
- 本质不同
- 系统界面
- 驱动程序
- 系统使用
- 软件与支持
Windows更适用于家庭个人使用
Linux更适用于企业服务器使用
Linux发行商和常见发行版
- Redhat公司--------Red Hat Linux(最著名的Linux版本、收费)-----免费的CentOS
- CentOS特点:主流、免费、更新方便
Linux的安装和使用
先安装虚拟机,再安装Centos
Vmware
Vmware简介
- 不需要分区或者重开机就能在同一台PC上使用两种以上的操作系统
- 完全隔离并且保护不同操作系统的环境以及所有的软件、资料
- 不同的操作系统之间还可以进行互动操作
- 有复原功能
- 能够设置并且随时修改操作系统的操作环境
- 常见虚拟机软件:VMware workstation、VirtualBox
Vmware下载:https://www.vmware.com/cn.html
CentOS镜像下载:https://www.centos.org/download/
高速下载地址
- http://mirrors.aliyun.com
- http://mirrors.sohu.com
- http://mirrors.163.com
- http://mirrors.cqu.edu.cn/CentOS
SecureCRT
简介:SecureCRT是一款支持SSH(SSH1和SSH2)的终端仿真程序,简单地说是Windows下登录Unix或Linux服务器主机的软件。
目录和文件
- Linux没有盘符这个概念,只有一个根目录/,所有文件都在他下面
- etc表示系统中的配置文件
- usr、usr/bin、usr/sbin都表示系统预设执行文件的放置目录
- var/log表示程序运行日志的存放目录
- 切换根目录:
cd / - 查看目录内容:
ls -l
时间同步
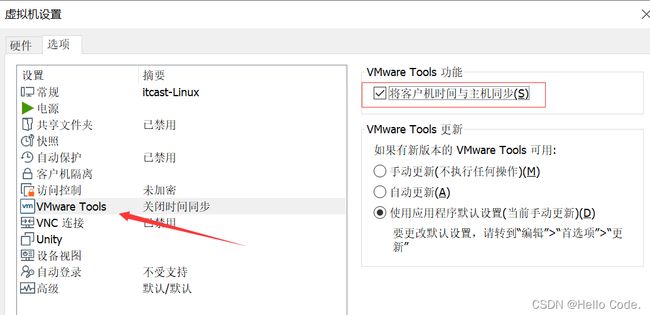
克隆与快照
克隆:将原系统完完全全的拷贝一份,原系统丢失后克隆的系统还能正常使用
- 占用空间大
- 原系统不存在,克隆体还能用
快照:记录系统当前状态,并不会把系统完整拷贝
- 占用空间小
- 原系统不存在,快照也就无法使用
克隆和拍摄快照时都需要关闭虚拟机
系统与设置命令
账号管理
与用户相关的命令,必须在管理员权限下才能执行
命令:
su root
- 创建用户:
useradd (选项) 用户名 - 用户口令:
passwd (选项) 用户名- 密码不能是一个回文
- 长度必须大于8位
- 必须是字母和数字的结合
在root权限下切换其它用户可直接切换,无需输入密码
- 修改用户:
usermod 选项 用户名

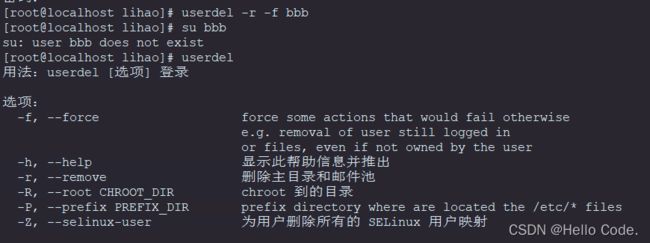
- 删除用户:
userdel (选项) 用户名
用户组
将用户分成小组,方便对用户的管理
-
创建用户组:
groupadd (选项) 用户组名 -
修改用户组:
groupmod (选项) 用户组名

-
查询用户所属组:
groups 用户名 -
删除用户组:
groupdel 用户组名 -
管理用户组内成员:
gpasswd (可选项) 组名gpasswd是Linux下的管理工具,用于将一个用户添加到组或者从组中删除
- -a:添加用户到组
- -d:从组中删除用户
- -A:指定管理员
- -M:指定组员和-A的用途差不多
- -r:删除密码
- -R:限制用户登入组,只有组中的成员才可以用newgrp加入该组

系统管理相关命令
- 日期管理:
date [参数选项]
参数选项:-d "字符串":显示字符串所指的日期与时间。字符串前后必须加上双引号-s "字符串":根据字符串来设置日期与时间。字符串前后必须加上双引号-u:显示GMT(北京时间为CST)--help:在线帮助--version:显示版本信息
- 显示登陆账号的信息:
logname - 切换用户:
su 用户名 - 查看当前用户详细信息(用户id、群组id、所属组):
id 用户名 - 提高普通用户的操作权限:
sudo [参数选项]
进程相关命令
实时显示process的动态 :top
pid:每个进程的id
user:进程是属于哪个用户
PR:进程的优先级
NI:进程优先级(负数为高优先级,正数为低优先级)
VIRT:当前进程占用虚拟内存的总量
S:当前进程的状态
- 实时显示所有进程信息(显示完整命令):
top -c - 实时显示指定进程的信息:
top -p PID - 结束实时监控:
q
查看当前正在运行的进程信息:ps
- 显示系统中所有的进程信息:
ps -A - 显示系统中所有的进程信息(完整信息):
ps -ef - 显示指定用户的进程信息:
ps -u 用户名
中断执行中的程序:kill PID
- 例如:
kill 1111表示杀死PID为1111的进程 kill -9 PID:强制杀死指定PID的进程killall -u 用户名:杀死这个用户中的所有进程kill -9 $(ps -ef|grep 用户名):杀死指定用户的所有进程kill -l:查看对应编号
关机命令:shutdown(延迟关机)
shutdown -h now:立即关机shutdown +1 "1分钟以后关机":延迟一分钟以后关机,并给出警告信息shutdown -r +1 "准备重启了":延迟一分钟以后重启,并给出警告信息shutdown -c:取消关机命令
重启命令:reboot(立即重启)
显示当前登录系统的用户:who
who -H:显示明细(标题)信息
校正服务器时间、时区:timedatectl
几个小概念
项目
说明
时区
因时区不同显示的时间不同,牵扯到夏令时和调整等问题,date命令可查看
系统时钟:System Clock
Linux OS的时间,date命令可查看
硬件时钟:RTC:Real Time Clock
主板上由电池供电的BIOS时间,hwclock -r可查看
NTP:Network Time Protocol
本机时间和实际的时间之间的经常会有差别,一般使用NTP服务器进行时间校准
timedatectl status:显示系统的当前时间和日期timedatectl list-timezones:查看所有可用的时区timedatectl set-timezone "Asia/Shanghai":设置本地时区timedatectl set-ntp false:禁用时间同步timedatectl set-time "2022-02-22 20:20:00":设置时间timedatectl set-ntp true:启用时间同步
清除屏幕:clear
目录管理
常见命令
作用
ls
列出目录
cd
切换目录
pwd
显示目前的目录
mkdir
创建新目录
rmdir
删除空目录
cp
复制文件或目录
rm
删除文件或目录
mv
移动文件或目录
修改文件或者目录的名字
-
ls命令相当于在Windows系统中打开文件夹,看到的目录以及文件的明细。
- 语法:
ls [参数选项] 目录名称 -a:显示所有文件或目录(包含隐藏)-d:仅列出目录本身,而不是列出目录内的文件数据(常用)-l:长数据串列出,包含文件的属性与权限等等数据(常用)
ls:显示不隐藏的文件与文件夹
ls -l:显示不隐藏的文件与文件夹的详细信息
ls -al:显示所有文件与文件夹的详细信息 - 语法:
-
pwd -P:查看当前所在目录 -
cd [相对路径或绝对路径]:切换目录cd ..:返回上一级目录
-
mkdirmkdir 文件夹的名字:创建单级目录- 创建多级文件夹,使用
mkdir -p aaa/bbb
-
rmdirrmdir 文件夹名字:删除空目录rmdir -p aaa/bbb:删除多级目录(先删bbb,如果删完aaa也为空,则aaa也一起删除)
-
rmrm 文件路径:删除文件rm -r 目录路径:删除目录和目录里面所有的内容(单级目录或多级目录都行)
-
touch 文件名.后缀名:创建一个文件 -
cpcp 数据源 目的地:文件复制(仅文件)cp -r aaa/* ccc:将aaa目录中的所有文件及目录拷贝到ccc中(*代指所有)
-
mvmv 数据源 目的地:改名(数据源和目的地相同)、移动文件或文件夹mv 文件名 文件名:将源文件名改为目标文件名mv 目录名 目录名:目标目录已存在,将源目录移动到目标目录;目标目录不存在则改名
文件基本属性
- 文件权限(共10位)
- 第一位为d表示是一个文件夹;是 - 表示是一个文件;| 表示是一个链接文档(快捷方式)
- r表示可读;w表示可写;x表示可执行; - 表示没有当前权限
- 2-4位表示属主权限(文件所属的用户可以做的事情)
- 5-7位表示属组权限(文件所在用户组可以对它做的事)
- 8-10位表示其它用户权限
chgrp命令(change group)chgrp [选项参数] [所属群组] [文件或目录...]:更改所属组chgrp root aaa:将aaa文件夹所属组更改为rootchgrp -v root aaa:将aaa的属组改为root(-v会多一句提示语)
chown命令chown 属主名 文件名:更改属主chown [参数选项] 属主名:属组名 文件名:更改属主和属组- -R:处理指定目录以及其子目录下的所有文件
chmod命令- 作用:修改属主、属组、其他用户的权限
- 数字方式语法:
chmod [参数选项] 数字权限 文件或目录 - 符号方式语法:
chmod u=rwx,g=rx,o=r a.txt - -R:对目前目录下的所有档案与子目录进行相同的权限变更(即以递回的方式逐个变更)
修改方式
-
数字方式
- r-----4
- w----2
- x----1
- -----0
设置时会把三个数字加在一起设置
例如:rwx则为7 -
符号方式
- user属主权限----u
- group属组权限----g
- others其它权限----o
- all全部身份----a
- +(加入)、-(除去)、=(设定)
- r(可读)、w(可写)、x(可执行)
综合案例
需求:一个公司的开发团队有三个用户:Java、erlang、golang
有一个文件目录tmp/work供他们开发,如何实现让这三个用户都对其具有写权限
思路
- 创建三个用户,并把他们加入到对应的用户组(dev-group)
- 将tmp/work文件夹所属组更改为dev-group
- 修改文件夹所属组的权限

文件管理
touch
-
语法:
touch [参数选项] 文件名如果文件不存在就创建文件,如果存在就修改时间属性
-
touch a{1..10}.txt:创建a1.txt一直到a10.txt共10个文件(批量创建空文件) -
stat a.txt:查看文件的详细信息
vi/vim编辑器
- vi编辑器:只能是编辑文本内容,不能对字体、段落进行排版
- 不支持鼠标操作
- 没有菜单
- 只有命令
- vim编辑器:vim是从vi发展出来的一个文本编辑器。
- 代码补全、编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用
简单来说:
vi是老式的文字处理器,不过功能已经很齐全了,但是还是有可以改进的地方
vim则可以说是程序员开发者的一项很好用的工具
-
vi/vim三种模式
- 阅读模式(命令模式)
- 编辑模式(编辑模式)
- 保存模式(末行模式)
命令模式下只能读不能写
在命令模式下输入i可以进入编辑模式,在编辑完成之后按下Esc又可以退出到命令模式
在命令模式下输入:可以进入末行模式,在保存完之后还可以按下两次Esc继续回退到命令模式 -
打开和新建文件
- 语法:
vim 文件名 - 如果文件已经存在,会直接打开文件(命令模式)
- 如果文件不存在,打开一个临时文件,在保存且退出后,就会新建一个文件
- 语法:
-
进入编辑模式
命令
英文
功能
常用
i
insert
在当前字符前插入文本
常用
I
insert
在行首插入文本
较常用
a
append
在当前字符后添加文本
A
append
在行末添加文本
较常用
o
在当前行后面插入一空行
常用
O
在当前行前面插入一空行
常用
-
进入末行模式保存文件
:q:当vim进入文件没有对文件内容做任何操作可以按“q”退出:q!:当vim进入文件对文件内容有操作但不想保存退出:wq:正常保存退出:wq!:强行保存退出,只针对于root用户或文件所有人
-
vim定位行
- 语法:
vim 文件名 +行数:查看文件并定位到具体行数 vim a.txt +5:查看a.txt文件并定位到第5行
- 语法:
-
异常处理
- 如果vim异常退出,在磁盘上可能会保存有交换文件
在修改一个文件时(a.txt),为保证文件安全,vim不会对源文件进行修改,会产生一个新的文件(a.txt.swp),并对该文件进行编辑
只有在保存的时候,才会将新文件写回到源文件中- 如果有交换文件,在下次使用vim编辑文件时,系统会提示是否对交换文件继续操作(将交换文件删除即可)
文件查看
命令
功能
cat 文件名
查看小文件内容
less -N 文件名
分屏显示大文件内容
head -n 文件名
查看文件的前一部分
tail -n 文件名
查看文件的最后部分
grep 关键字 文件名
根据关键字搜索文本文件内容
cat -n a.txt:可以加入参数选项-n显示行号- 只能阅读小文件
- 阅读大文件可能显示不完整
less 文件名:查看大文件- 加入
-N可显示行号 - ctrl + F :向前移动一屏
- ctrl + B :向后移动一屏
- ctrl + D :向前移动半屏
- ctrl + U :向后移动半屏
- j :向前移动一行
- k :向后移动一行
- G:移动到最后一行
- g:移动到第一行
- q/ZZ:退出less命令
- 加入
tail 文件名:默认查看文件最后10行内容tail -3 b.txt:查看文件最后3行内容tail -f b.txt:动态显示文件最后10行内容(ctrl + C停止)tail -n +2 b.txt:显示文件b.txt的内容,从第2行至文件末尾tail -c 45 b.txt:显示文件最后45个字符
head 文件名:查看文件前10行内容- 其它内容和tail类似
grep命令- 类似于Windows下打开文件后ctrl+F的查找功能
- 查找对应的进程
- 语法:
grep [参数选项] 关键字 文件:根据关键字,搜索文本文件内容 - -n:把包含关键字的行号展示出来
- -i:把包含关键字的行展示出来,搜索时忽略大小写
- -v:把不包含关键字的行展示出来
ps -ef | grep sshd:将进程中含有sshd的进程展示出来ps -ef | grep -c sshd:将进程中含有sshd的进程的个数展示出来
echo命令
echo 字符串:展示文本echo 字符串 > 文件名:将字符串写到文件中(覆盖文件内容)echo 字符串 >> 文件名:将字符串写到文件中(不覆盖原内容)cat 不存在的目录 &>> 存在的文件:将命令的失败结果追加到指定的文件的后面
awk命令
- AWK是一种处理文本文件的语言,是一个强大的文本分析工具(名字取自三位创始人名字中的字母)
- 语法:
awk [参数选项] '语法' 文件 - 过滤:
cat a.txt | awk '/zhang|li/':查看a.txt文件中包含zhang或者li的行 - 切割
选项
含义
-F ','
使用指定字符分割
$ + 数字
获取第几段内容
$0
获取当前行内容
OFS="字符"
向外输出时的段分割字符串
toupper()
字符转成大写
tolower()
字符转成小写
length()
返回字符长度
cat a.txt | awk -F ' ' '{print $1,$2,$3}':将a.txt中的内容按空格分割并打印第1-3列
cat a.txt | awk -F ' ' '{print toupper($1),$2,$3}':将a.txt中的内容分隔后并将$1中的内容转为大写字符后输出
cat a.txt | awk -F '' '{OFS="---"}{print $1,$2,$3}':将a.txt中的内容分隔后并用—重新分隔后输出
- 计算
命令
含义
awk
BEGIN{初始化操作}
{每行都执行}
END{结束时操作}
文件名
固定语法
BEGIN{这里面放的是执行前的语句}
{这里面放的是处理每一行要执行的语句}
END{这里面放的是处理完所有的行后要执行的语句}
文件名
cat a.txt | awk -F' ' 'BEGIN{}{totle=totle+$2}END{print totle}':将a.txt分割后把$2的值相加并输出
cat a.txt | awk -F' ' 'BEGIN{}{totle=totle+$2}END{print totle}':输出totle以及总人数(行数)
软连接
- 类似于Windows里面的快捷方式
- 语法:
ln -s 目标文件路径 快捷方式路径 ln -s aaa/bbb/ccc/ddd/eee/a.txt a.txt
压缩命令
查找命令
-
语法:
find [参数选项] <指定目录> <指定条件> <指定内容>:在指定目录下查找文件 -
参数选项
- -name filename:查找名为filename的文件
- -ctime -n或+n:按时间来查找文件,-n指n天以内,+n指n天以前
-
find . -name "*.txt":查找当前目录下所有以txt为后缀的文件 -
find . -ctime -1:当前文件夹下1天内操作过的文件将 . 替换为 / 则表示在全盘范围进行查找
gzip命令
- 语法:
gzip [参数选项] [文件]:压缩文件 gzip a.txt:将a.txt文件压缩gzip *:将当前目录下所有文件都进行压缩(已经压缩过的不能再次被压缩)gzip -dv 文件名:解压文件并显示详细信息
gunzip命令
- 语法:
gunzip [参数] [文件]:解压文件 gunzip 压缩文件:解压压缩文件gunzip *:解压当前目录下的所有压缩文件
tar命令
- 语法:
tar [必要参数] [选择参数] [文件]:打包、压缩和解压(文件/文件夹) - 注意:tar本身不具有压缩功能,它是调用压缩功能实现的
- 参数选项
- -c:建立新的压缩文件
- -v:显示指令执行过程
- -f <备份文件>:指定压缩文件
- -z:通过gzip指令处理压缩文件
- -t:列出压缩文件中的内容
- -x:表示解压
tar -cvf 打包文件名 文件名:打包文件并指定打包之后的文件名(仅打包不压缩)tar -zcvf b.gz b.txt:通过gzip指令将b.txt压缩为b.gz并显示过程(打包压缩)tar -zcvf aaa.gz aaa:将aaa文件夹压缩为aaa.gztar -ztvf aaa.gz:查看压缩文件中的内容tar -zxvf aaa.gz:解压aaa.gz文件
zip命令
- 语法:
zip [必要参数] [选择参数] [文件]:压缩 - 注意:zip是个使用广泛的压缩程序,文件经他压缩后会另外产生具有".zip"扩展名的压缩文件
- 参数选项
- -q:不显示指令执行过程
- -r:递归处理,将指定目录下的所有文件和子目录一并处理
zip -q -r 压缩文件名 文件/文件夹:压缩对应的文件/文件夹
unzip命令
- 语法:
unzip [必要参数] [选择参数] [文件]:解压 - 注意:只能解压".zip"扩展名的压缩文件
- 参数选项
- -l:显示压缩文件内所包含的文件
- -d <目录>:指定文件解压缩后要存储的目录
unzip -l aaa.zip:查看aaa.zip压缩文件所包含的文件unzip -d aaa aaa.zip:将aaa.zip压缩文件解压到aaa文件夹中(aaa文件夹可以不存在,会自动创建)
bzip2命令
- 语法:
bzip2 [参数选项] 文件:压缩文件 - 注意:使用新的压缩算法,和zip相比压缩后的文件比原来的要小,但花费时间变长
- 若没有加上任何参数,bizp2压缩完文件后会产生bz2的压缩文件,并删除原始文件
bzip2 a.txt:压缩并删除a.txt- bunzip2命令:
bunzip2 [参数选项] 文件:解压- -v:解压文件时,显示详细的信息
bunzip2 -v a.bz2:解压并显示详细信息
网络与磁盘管理
网络管理
- ifconfig命令
- 语法:
ifconfig [参数选项]:显示或配置网络设备的命令 ifconfig ens37 down:关闭ens37这张网卡ifconfig ens37 up:开启网卡ens37ifconfig ens37 192.168.23.199:将ens37网卡的ip更改为192.168.23.199ifconfig ens37 192.168.23.199 netmask 255.255.255.0:配置ip地址和子网掩码
- 语法:
- ping命令
- 语法:
ping [参数选项]:检测是否与主机联通 - -c <完成次数>:设置完成要求回应的次数
ping -c 2 www.baidu.com:指定接收包的次数
- 语法:
- netstat命令
- 语法:
netstat [参数选项]:显示网络状态 - -a:显示所有连线中的Socket
- -i:显示网卡列表
- 语法:
磁盘管理
-
lsblk命令
- 语法:
lsblk [参数选项]:列出硬盘的使用情况 - 理解为:list block的英文缩写
lsblk -f:显示系统信息
- 语法:
-
df命令
- 语法:
df [参数选项]:显示目前在Linux系统上,磁盘的使用情况 - –total:显示所有的信息
- -h:换算成KB,MB,GB等形式进行展示(方便阅读)
df:显示整个硬盘的使用情况df 文件夹:显示文件夹使用情况df --total:显示所有的信息df -h:将结果变成kb、mb、gb等形式展示,利于阅读
- 语法:
-
mount命令
- 语法:
mount [参数选项] 目录:用于挂载Linux系统外的设备 - 类似与Windows中的U盘,但在Linux中需要手动新建一个文件夹,并把该文件夹和U盘关联起来(挂载点和挂载)
注意:“挂载点”的目录需要以下几个要求:
目录事先存在,可以用mkdir命令新建目录
挂载点目录不可被其它进程使用到
挂载点下原有文件将被隐藏mount -t auto /dev/cdrom PPP:将光驱和PPP文件夹挂载umount PPP:卸载PPP文件夹所挂载的光驱
- 语法:
yum
- 在Linux中,如果我们需要查找、安装、下载或者卸载另外的软件,就需要通过yum来进行操作。英文全称为:Yellow dog Updater,Modified
- yum常用命令
- 列出所有可更新的软件清单命令:
yum check -update - 更新所有软件命令:
yum update - 仅安装指定的软件命令:
yum install - 仅更新指定的软件命令:
yum update - 列出所有可安装的软件清单命令:
yum list - 删除软件包命令:
yum remove - 查找软件包命令:
yum search - 清除缓存命令:
yum clean packages:清除缓存目录下的软件包yum clean headers:清除缓存目录下的headersyum clean oldheaders:清除缓存目录下旧的headersyum clean,yum clean all(= yum clean packages;yum clean oldheades):清除缓存目录下的软件包及旧的headers
- 列出所有可更新的软件清单命令:
- -y:在安装过程中,如果有选择提示,全部选择y
- 注意:使用yum必须联网且在root权限下
yum -y install tree:安装treetree:执行tree,展示当前目录结构yum remove tree:移除treeyum list tom*:查找以tom为开头的软件名称- yum源
- 在下载软件的时候,都是从yum源中获取的,默认是centos中默认的yum源(在国外,下载速度慢)
- 更换国内yum源
yum -y install wget:安装一个下载工具cd /etc/yum.repos.d/:进入yum的相关文件夹中mv CentOS-Base.repo CentOS-Base.repo.back:对原yum文件改名(备份)wget -O CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo:下载阿里yum源文件yum clean all:清理缓存,并重新加载yumyum makecache:为新yum源建立缓存文件yum search tomcat:查找软件,验证阿里云的yum源是否可以正常使用
rpm
- 在最初,RedHat Linux发行版专门用来管理Linux各种套件的程序
- 和yum的区别
- rpm只能安装已经下载到本地机器上的rpm包
- yum能在线下载并安装rpm包,能更新系统,且还能自动处理包与包之间的依赖问题,这个是rpm工具所不具备的
shell
初识shell
在计算机科学中,shell就是一个命令解释器
shell是位于操作系统和应用程序之间,是他们二者最主要的接口。
shell负责把应用程序的输入命令信息解释给操作系统,将操作系统指令处理后的结果解释给应用程序
一句话,shell就是在操作系统和应用程序之间的一个命令翻译工具。
Windows和Linux中的shell
- Windows系统:cmd.exe 命令提示字符
- Linux系统:sh / csh / ksh / bash(默认) / …
shell的使用方式
- 手工方式
手工敲击键盘,直接输入命令,按Enter后。
执行命令,显示命令执行的结果
重点:逐行输入命令,逐行进行确认执行
- 脚本方式
我们把手工执行的命令,写到一个文件中,然后运行这个文件,达到执行命令的效果。
这个文件就叫做脚本文件
编写第一个shell脚本
-
新建一个文件后缀名为sh
-
编写内容
#! /bin/bash #这是临时shell脚本 echo 'nihao' echo 'hello' -
执行
注释和变量
注释
-
单行注释
#!/bin/bash
这是单行注释
echo ‘hello world’
-
多行注释
#!/bin/bash
:< 多行注释
多行注释
!
echo ‘hello world’:<<字符
注释内容
字符
变量
- 定义变量
-
普通变量
- 方式一:
变量名=变量值(变量值必须是一个整体,中间没有特殊字符) - 方式二:
变量名='变量值'(单引号中的内容,原样赋值) - 方式三:
变量名="变量值"(如果双引号中有其它变量,会把变量的结果进行拼接,然后赋值)
习惯:数字不加引号,其它默认加双引号
- 方式一:
-
命令变量(将命令的结果赋值给变量)
- 方式一:变量名=`命令`(这里是反引号
) - 方式二:
变量名=$(命令)(常用)
- 方式一:变量名=`命令`(这里是反引号
-
- 使用变量
- 方式一:
$变量名(非标准写法,图省事) - 方式二:
"$变量名"(非标准写法,图省事) - 方式三:
${变量名}(在双引号里面要使用变量的值) - 方式四:
"${变量名}"(标准使用方式)
- 方式一:
- 只读变量:
readonly 变量名 - 删除变量:
unset 变量名
数组
定义数组
数组名=(值1 值2 … 值n)
arr=(1 2 3 4 5)
给数组的元素赋值
数组名[索引]=值
arr[0]=1
获取元素
${数组名[下标]}
${arr[0]}
获取长度
${#数组名[*]}
${#数组名[@]}
${#arr[*]}
${#arr[@]}
运算符
运算符
说明
举例
加法
expr $a + $b
-
减法
expr $a - $b
*
乘法
expr $a * $b
/
除法
expr $b / $a
%
取余
expr $b % $a
=
赋值
a=$b (把b变量的值赋给a变量)
++ / –
自增 / 自减
((a++))
注意点
- 原生的bash不支持简单的数学运算。可以通过其它命令实现:expr
- 表达式和运算符之间要有空格
- 完整的表达式要被反引号包含
- 乘法中不能直接使用*,需要在乘号前加转义
举例:`expr 2 + 2`
字符串运算符
运算符
说明
举例
=
检测两个字符串是否相等,相等返回true
[ $a = $b ]
!=
检测两个字符串是否不相等,不相等返回true
[ $a != $b ]
-z
检测字符串长度是否为0,为0返回true
[ -z $a ]
-n
检测字符串长度是否不为0,不为0返回true
[ -n $a ]
$
检测字符串是否为空,不为空返回true
[ $a ]
[]与里面的代码命令有个空格隔开,不能贴在一起
$?可以获取上一条语句的执行结果在shell中,0为真,1为假
${#字符串}获取字符串长度
关系运算符
运算符
说明
举例
-eq
检测两个数是否相等,相等返回true(equals)
[ $a -eq $b ]
-ne
检测两个数是否不相等,不相等返回true(not equals)
[ $a -ne $b ]
-gt
检测左边的数是否大于右边的,如果是,则返回(truegreater than)
[ $a -gt $b ]
-lt
检测左边的数是否小于右边的,如果是,返回true(less than)
[ $a -lt $b ]
-ge
检测左边的数是否大于等于右边的,如果是,则返回true(greater equals)
[ $a -ge $b ]
-le
检测左边的数是否小于等于右边的,如果是,则返回true(less equals)
[ $a -le $b]
关系运算符只支持数字,不支持字符串,除非字符串的值是数字
布尔运算符
运算符
说明
举例
!
取反运算
[ ! false ] 返回true
-o
或运算,有一个表达式为true 则返回true (or)
[ $a -lt 20 -o $b -gt 100 ]
-a
与运算,两个表达式都为true 才返回true(and)
[ $a -lt 20 -a $b -gt 100 ]
逻辑运算符
运算符
说明
举例
&&
逻辑的 AND
[[ true && true ]] 返回true
||
逻辑的 OR
[[ false || false ]] 返回false
选择语句
if语法
if[ 条件 ]
then
语句体
fi
if [ 条件 ]
then
语句体
else
语句体
fi
if [ 条件1 ]
then
语句体
elif [ 条件2 ]
语句体
else
语句体
fi
小练习
#!/bin/bash
# if语句
#if的第一种格式:
#查找一个进程,如果进程存在,就打印true
if [ $(ps -ef | grep -c "ssh") -gt 1 ]
then
echo "true"
fi
case语法
case 值 in
模式1 )
语句体1
;;
模式2 )
语句体2
;;
esac
v="hhxx"
case "${v}" in
"hhxx")
echo "好好学习"
;;
"ttxs")
echo "天天向上"
;;
esac
循环语句
for循环
for 变量 in 范围
do
循环体
done
for loop in A B C
do
echo $loop
done
while循环
while 条件
do
循环体
done
a=1
while [ "${a}" -le 10 ]
do
echo "${a}"
((a++))
done
函数
无参无返回值
函数名(){
函数体
}
test(){
echo "函数测试!"
}
echo "==========="
test
echo "============"
有参无返回值
method(){
echo "第一个参数$1"
echo "第二个参数$2"
}
method a b
有参有返回值
method(){
echo "接收到参数$1和$2"
return $(($1 + $2))
}
method 10 20
echo $?
小练习
read 变量名:表示把键盘录入的数据赋值给这个变量
#!/bin/bash
#在方法中键盘录入两个整数,并返回这两个整数和
method(){
echo "请录入第一个数:"
read num1
echo "请录入第二个数:"
read num2
echo "两个数分别为:${num1},${num2}"
return $(($num1 + $num2))
}
method
echo "两数之和为:$?"
Nginx
这部分应该是HTML + CSS + Nginx,因为HTML和CSS是之前学过的,当时并没有记笔记,这部分也相当简单些,如果有没学过的可以自行搜索资料学习一下~
概述
- Nginx是一款服务器软件
- 其核心功能是可以和服务器硬件相结合,从而可以将程序发布到Nginx服务器上,让更多用户浏览
安装
-
上传压缩包:
put nginx压缩包位置(CRT中按alt+p键进入sftp) -
解压压缩包:
tar -zxvf 压缩包名 -
进入解压目录:
cd nginx解压目录 -
安装依赖环境
yum -y install pcre pcre-develyum -y install zlib zlib-develyum -y install openssl openssl-devel
yum -y install gcc -
安装nginx
./configure
make
make install(安装完会在/usr/local/下有一个nginx目录) -
进入对应目录:
cd /usr/local/nginx/sbin -
启动nginx服务:
./nginx
停止:./nginx -s stop
重启:./nginx -s reload -
查看nginx服务状态:
ps -ef | grep nginx -
测试nginx服务:浏览器打开对应Linux服务器ip地址
最后这里在浏览器打开对应ip地址无法访问,解决方法:
第一步,对80端口进行防火墙配置:firewall-cmd --zone=public --add-port=80/tcp --permanent
第二步,重启防火墙服务:systemctl restart firewalld.service
然后重新在浏览器中访问你的ip,应该就可以访问了。
发布项目
-
在 /home 下创建一个web目录:
mkdir web -
将项目上传到该目录下:
put web项目压缩包 -
解压项目压缩包:
unzip web程序压缩包 -
编辑nginx配置文件:
vim /home/nginx-1.18.0/conf/nginx.conf
找到server的大括号范围,修改location的路径
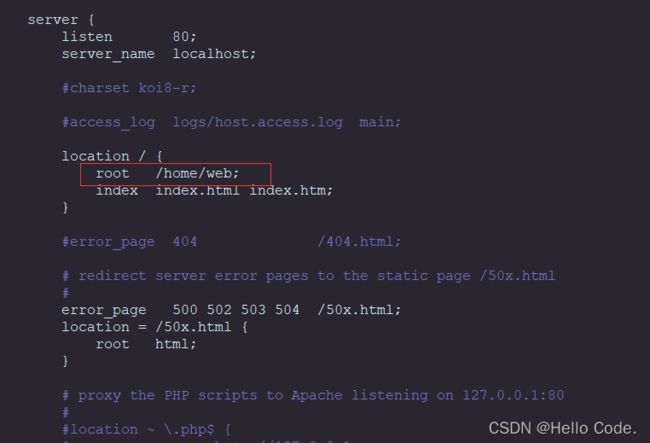
-
进入对应目录:
cd /usr/local/nginx/sbin -
关闭nginx服务:
./nginx -s stop -
启动nginx服务并加载配置文件:
/usr/local/nginx/sbin/nginx -c/home/nginx-1.18.0/conf/nginx.conf -
通过浏览器测试网站
JavaWeb核心
企业开发简介
JavaEE规范
- JavaEE(Java Enterprise Edition):Java企业版
- 它是由SUN公司领导、各个厂家共同制定并得到广泛认可的工业标准。
- JavaEE早期叫做J2EE,但是没有继续采用其命名规则。J2EE的版本从1.0开始到1.4结束。而JavaEE版本是从JavaEE 5 版本开始,目前最新的版本是JavaEE 8。
- JavaEE规范是很多Java开发技术的总称。这些技术规范都是沿用自J2EE的。一共包括了13个技术规范。
- 包括:JDBC, JNDI, EJB, RMI, IDL/CORBA, JSP, Servlet, XML, JMS, JTA, JTS, JavaMail, JAF。
WEB概述
概述
- WEB在计算机领域中代表的是网络。
- 像我们之前所用的WWW,它是World Wide Web 三个单词的缩写,称为:万维网
- 网络相关技术的出现是为了让我们在网络的世界中获取资源,这些资源的存放之处,我们把它叫做网站。
- 我们通过输入网站的地址(网址),就可以访问网站中提供的资源(不区分局域网或广域网)
资源分类
- 静态资源
网站中提供给人们展示的资源是一成不变的,也就是说不同人或者在不同时间,看到的内容都是一样的。
作为开发者来说,我们编写的HTML, CSS, JavaScript 都属于静态资源。 - 动态资源
网站中提供给人们展示的资源是由程序产生的,在不同的时间或者不同的人由于身份的不同,所看到的内容是不一样的。
作为网站开发者来说,我们编写的JSP、Servlet等都属于动态资源。
系统结构
在之前的学习中,开发的都是Java工程。这些工程在企业中称之为项目或者产品。都是有系统架构的!
- 基础结构划分
- CS结构:(Client Server)客户端+服务器的方式(把不同的应用直接安装在客户端上)
- BS结构:(Browser Server)浏览器+服务器的方式
- 技术选型划分
- Model1模型
- Model2模型
- MVC模型
- 三层架构 + MVC模型
- 部署方式划分
- 一体化结构
- 垂直拆分结构
- 分布式结构
- 微服务结构
tomcat
服务器
-
服务器是计算机的一种,它比普通计算机运行更快、负载更高、价格更贵。==服务器在网络中为其它客户机(如PC机、智能设备等)提供计算或者应用服务。==服务器具有高速的CPU运算能力、长时间的可靠运行、强大的I/O外部数据吞吐能力以及更好的扩展性。
-
而我们这里所说的服务器,其实是web服务器,或者应用服务器。它本质就是一个软件,通过和硬件相结合,从而达到帮助我们来发布应用的功能,让用户通过客户机访问我们的应用。
-
常用的应用服务器
服务器名称
说明
weblogic
实现了JavaEE规范,重量级服务器,又称为JavaEE容器
websphereAS
实现了JavaEE规范,重量级服务器
JBOSSAS
实现了JavaEE规范,重量级服务器,免费的
Tomcat
实现了jsp/servlet规范,是一个轻量级服务器,开源免费
Tomcat
- Tomcat是Apache软件基金会的Jakarta项目组中的一个核心项目,由Apache、Sun和其它一些公司及个人共同开发而成。由于有了Sun公司的参与和支持,最新的Servlet、JSP规范总能在Tomcat中得到体现。因为Tomcat技术先进、性能稳定,而且免费,所以深受Java爱好者的喜爱并得到了部分软件开发商的认可,成为目前比较流行的Web应用服务器。
- Tomcat官网:https://tomcat.apache.org/
- Tomcat各个版本所需要的支持

下载和安装
- 下载:官网下载
- 安装:直接解压即可
- 目录组成
- bin:一些二进制可执行文件
- conf:保存配置文件的路径
- lib:Tomcat在运行过程中所需要的jar包
- logs:日志文件
- temp:临时文件
- webapps:项目发布目录(一个文件夹代表一个web应用)(ROOT代表根项目)
- work:工作目录
基本使用
-
启动
startup.bat:Windows下启动执行文件
startup.sh:Linux下启动执行文件启动后浏览器访问:http://localhost:8080可以进入欢迎界面(Tomcat默认端口为8080)
-
停止
shutdown.bat:Windows下关闭执行文件
shutdown.sh:Linux下关闭执行文件 -
部署项目
在webapps目录下创建一个文件夹
将资源放到该文件夹中
启动tomcat,输入正确路径
常见问题
-
启动问题
启动窗口一闪而过:没有配置jdk环境变量
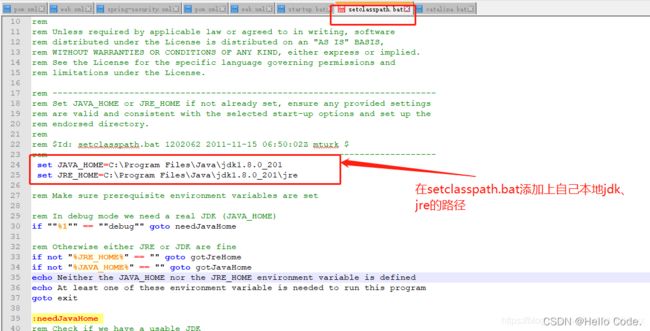
java.net.BindException:端口8080被占用
-
控制台乱码问题解决
conf-logging.properties
修改java.util.logging.ConsoleHandler.encoding = UTF-8Tomcat默认UTF-8,CMD命令窗口默认GBK,将UTF-8改为GBK即可解决乱码问题
IDEA集成Tomcat
- 点击Run -》 Edit Configurations
- 点击Defaults -》 Tomcat Servlet -》 Local
- 点击Configure -》Tomcat Home -》 选择tomcat所在路径
Linux下的安装
- 上传压缩包到/home路径:
put d:/apache-tomcat-9.0.58.tar.gz - 解压压缩包:
tar -zxvf 压缩包名 - 进入bin目录下:
cd apache-tomcat-9.0.58/bin - 启动tomcat服务:
./startup.sh - 使用浏览器测试:浏览器打开对应Linux服务器ip地址:8080
Java WEB项目
- 新建项目模型,选择Java Enterprise
确定JDK版本、Appalication Server版本 - 右键Add Framework Support…
- 勾选Web Appalication选项
项目组成详解
- src:存放Java源代码
- web:存放项目相关资源(html、css、js、jsp、图片等)
- WEB-INFO:存放相关配置的(web.xml等)
IDEA发布项目
- 点击Run -》 Edit Configurations
- 点击Tomcat Server -》 Deployment
Application Context是项目访问路径,/代表默认路径,多个项目中只能有一个默认路径 - 点击Tomcat Server -》 Server
设置关联浏览器
两个Update resources设置
设置JDK、端口号 - 启动Tomcat服务
- 验证结果(浏览器)
通过war包发布项目
- 在项目的web路径下打war包:
jar -cvf myweb.war . - 将打好的war包剪切到tomcat的webapps路径下
- 启动tomcat服务,自动解压war包
- 验证结果
配置文件
配置默认端口号
主配置文件server.xml
标签中,port属性代表Tomcat默认端口号(8080)

http协议默认端口号为80,Tomcat默认端口号与其不一致,所以每次访问网站需要加上端口号
如果是80端口,就不需要加端口号
真正发布网站的时候,都需要将tomcat默认端口号改为80,这样在访问网站的时候就不需要加端口号了
配置虚拟目录
- 作用:可以发布任意目录下的项目
-
编辑server.xml 配置文件,找到
-
加入以下内容

path:访问资源的虚拟目录名称(表示在浏览器地址栏中的访问路径)
docBase表示需要发布的项目的真实路径
配置虚拟主机
- 作用:可以指定访问路径的名称
- 编辑server.xml 配置文件,找到
- 加入以下内容

name:虚拟主机名称
appBase:项目所保存的根路径
unpackWARs:是否自动解压war包
autoDeploy:是否自动发布
Context:同虚拟目录
- 修改hosts文件
绑定IP地址和对应的域名
文件路径:c:WindowsSystem32driversetc

HTTP协议
概述
- HTTP(Hyper Text Transfer Protocol):超文本传输协议
- HTTP协议是基于 TCP/IP 协议的(安全)
- 超文本:比普通文本更加强大(还有图片、音频等等)
- 传输协议:客户端和服务端的通信规则(握手规则)
组成部分
- 请求:客户端发起请求到服务器
- 响应:服务器收到客户端的请求后发起响应给客户端
除了手动发起的请求外,JavaScript、CSS、图片等资源会自动发起请求
协议的请求
请求的组成部分
-
请求行:请求方式 提交路径(提交参数) HTTP/版本号
-
请求头
名称
说明
Accept
客户端浏览器所支持的MIME类型
Accept-Encoding
客户端浏览器所支持的压缩编码格式。最常用的就是gzip压缩
Accept-Language
客户端浏览器所支持的语言。一般都是zh_CN或en_US等
Referer
告知服务器,当前请求的来源
Content-Type
请求正文所支持的MIME类型
Content-Length
请求正文的长度
User-Agent
浏览器相关信息
Connection
连接的状态。Keep-Alive保持连接
If-Modified-Since
客户端浏览器缓存文件的最后修改时间
Cookie
会话管理相关,非常的重要
-
请求空行:普通换行,用于区分请求头和请求体
-
请求体:只有POST提交方式才有请求体,用于显示提交参数
请求的方式
GET

POST

只有POST请求方式存在请求体,GET请求方式没有请求体
get提交的参数在请求行中,post提交的参数在请求体中
协议的响应
响应的组成部分
-
响应行:请求方式 HTTP/版本号 状态码 状态描述
常见状态码状态码
说明
200
一切OK
302/307
请求重定向,两次请求,地址栏发生变化
304
请求资源未发生变化,使用缓存
404
请求资源未找到
500
服务器错误
-
响应头
名称
说明
Location
请求重定向的地址,常与302,307配合使用
Server
服务器相关信息
Content-Type
响应正文的MIME类型
Content-Length
响应正文的长度
Content-Disposition
告知客户端浏览器,以下载的方式打开响应正文
Refresh
定时刷新
Last-Modified
服务器资源的最后修改时间
Set-Cookie
会话管理相关,非常的重要
Expires:-1
服务器资源到客户端浏览器后的缓存时间
Catch-Control:no-catch
不要缓存
-
响应空行:普通换行,用于区分响应头和响应体
-
响应体:将资源文件发送给客户端浏览器进行解析
发布资源案例
发布静态资源
-
创建一个Java WEB项目
-
将静态页面所需资源导入到项目的web目录下
-
修改web.xml配置文件,修改默认主页
/路径/文件名.html -
将项目部署到tomcat中
-
启动tomcat服务
-
打开浏览器查看页面
Servlet介绍
- Servlet是运行在Java服务器端的程序,用于接收和响应来自客户端基于HTTP协议的请求。
- 如果想实现Servlet的功能,可以通过实现javax.servlet.Servlet接口或者继承它的实现类。
- 核心方法:service(),任何客户端的请求都会经过该方法。
发布动态资源
-
创建一个JavaWEB项目
-
将静态页面所需资源导入到项目的web目录下
-
修改web.xml配置文件,修改默认主页
-
在项目的src路径下编写一个类,实现Servlet接口
-
重写service方法,输出一句话即可
-
修改web.xml配置文件,配置servlet相关资源
自定义名称 java全类名(包名.类名) 和声明中的名称保持一致 /访问路径(浏览器地址栏要输入的访问路径) -
将项目部署到tomcat中
-
启动tomcat服务
-
打开浏览器测试功能
执行流程
- 通过浏览器访问到指定的资源路径
- 通过url-pattern找到对应的name标签
- 通过name找到对应的Servlet声明
- 在声明中找到对应的Java实现类
- 执行service方法
Servlet
概述
- Servlet是运行在Java服务器端的程序,用于接收和响应来自客户端基于HTTP协议的请求
- 是一个接口(javax.servlet.Servlet),常用实现类:GenericServlet、HttpServlet(继承自GenericServlet)
- 所有的客户端请求都会经过service方法进行处理
- 初始化会调用init方法,销毁时会调用destroy方法
执行过程
- 客户端浏览器向Tomcat服务器发起请求
- Tomcat服务器解析请求地址(URL)
- Tomcat根据地址找到对应的项目
- 找到项目中的web.xml文件
- 解析请求资源地址(URI)
- 找到项目的资源(对应的Java类)
- 执行service方法,响应给客户端浏览器
关系视图
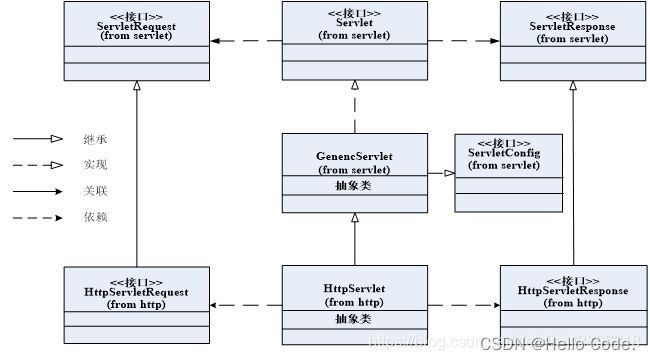
实现方式
- 实现Servlet接口,实现所有的抽象方法,该方式支持最大程度的自定义
- 继承GenericServlet抽象类,必须重写service方法,其他方法可选择重写。该方式让我们开发servlet变得简单。但是这种方式与HTTP协议无关
- 继承HttpServlet抽象类,需要重写doGet和doPost方法。该方式表示请求和响应都需要和HTTP协议相关
生命周期
- 对象的生命周期,就是对象从出生到死亡的过程。即:出生 =》活着 =》死亡。官方说法是对象创建到销毁的过程
- 出生:请求第一次到达Servlet时,对象就创建出来,并且初始化成功。只出生一次,将对象放到内存中
- 活着:服务器提供服务的整个过程中,该对象一直存在,每次都是执行service方法
- 死亡:当服务器停止时,或者服务器宕机时,对象死亡
出生对应的是
init方法
活着对应的是service方法(doGet和doPost方法)
死亡对应的是destroy方法
结论: Servlet对象只会创建一次,销毁一次。所以Servlet对象只有一个实例。如果一个对象实例在应用中是唯一的存在,那么就称他为单例模式
线程安全问题
- 由于Servlet采用的是单例设计模式,也就是整个应用中只有一个实例对象。所以我们需要分析这个唯一的实例对象中的类成员是否线程安全
- 模拟用户登录功能来查看Servlet线程是否安全
结论: 一个浏览器代表一个线程,多个浏览器代表多个线程。按理说应该是每个浏览器查看的都是自己的信息。但结果浏览器中数据混乱。因此,我们可以认为Servlet是线程不安全的!
解决: 定义类成员要谨慎。如果是共用的,并且只会在初始化时赋值,其它时间都是获取的话,那么是没问题的。如果不是共用的,或者每次使用都有可能对其赋值,那就要考虑线程安全的问题了,可以将其定义到doGet或doPost方法内或者使用同步功能即可
映射方式
-
具体名称的方式。访问的资源路径必须和映射配置完全相同 【常用】
Demo study.servlet.Demo Demo /Demo -
/开头 + 通配符的方式。只要符合目录结构即可,不用考虑结尾是什么Demo2 study.servlet.Demo2 Demo2 /Demo2/* -
通配符 + 固定格式结尾的方式。只要符合固定结尾格式即可,不用考虑前面的路径
Demo2 study.servlet.Demo2 Demo2 *.test
注意: 优先级问题。越是具体的优先级越高,越是模糊的 优先级越低。第一种 > 第二种 > 第三种
多路径映射
-
我们可以给一个Servlet配置多个访问映射,从而根据不同的请求路径来实现不同的功能
-
场景分析
如果访问的资源路径是/vip,商品价格打9折
如果访问的资源路径是/vvip,商品价格打5折
如果访问的资源路径是其它,商品价格不打折 -
采用第二种映射方式实现多路径映射(
/+ 通配符)package study.servlet;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.io.PrintWriter;public class Demo3 extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 获取浏览器路径
String requestURI = req.getRequestURI();
// 分隔路径
String path = requestURI.substring(requestURI.lastIndexOf(“/”));
// 路径判断,区分价格
if(path.equals(“/vip”)){
System.out.println(“100元”);
}else if(path.equals(“/vvip”)){
System.out.println(“200元”);
}else System.out.println(“300元”);
}@Override protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { doGet(req,resp); }}
创建时机
- 第一次访问时创建
- 优势:减少对服务器内存的浪费。提高了服务器启动的效率
- 弊端:如果有一些要在应用加载时就做的初始化操作无法完成
- 服务器加载时创建
- 优势:提前创建好对象,提高了首次执行的效率。可以完成一些应用加载时要完成的初始化操作
- 弊端:对服务器内存占用较多,影响了服务器启动的效率
- 修改Servlet创建时机。在
1
正整数代表服务器加载时创建,值越小,优先级越高。负整数或不写代表第一次访问时创建
默认Servlet
- 默认Servlet是由服务器提供的一个Servlet。它配置在 Tomcat 的 conf 目录中的 web.xml 中

- 它的映射路径是
/
ServletConfig
- ServletConfig 是Servlet 的配置参数对象,在Servlet 的规范中,允许为每一个Servlet 都提供一些 初始化的配置。所以,每个Servlet 都有一个自己的ServletConfig
- 作用:在Servlet 的初始化时,把一些配置信息(键值对的形式)传递给Servlet
- 生命周期:和Servlet 相同
配置方式
-
在
encoding UTF-8 desc This is ServletConfig
常用方法
返回值
方法名
说明
String
getInitParameter(String name)
根据参数名称获取参数的值
Enumeration
getInitParameterNames()
获取所有参数名称的枚举
String
getServletName()
获取Servlet的名称
ServletContext
getServletContext()
获取ServletContext对象
通过init方法,来对ServletConfig对象进行赋值
private ServletConfig config;
public void init(ServletConfig config) throws ServletException{
this.config = config;
}
枚举项遍历
Enumeration keys = config.getInitParameterNames();
while(keys.hasMoreElements()){
String key = keys.nextElement();
String value = config.getInitParameter(key);
System.out.println(key + "--" + value);
}
// ServletConfigDemo测试代码
package study.servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletContext;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.util.Enumeration;
public class ServletConfigDemo extends HttpServlet {
private ServletConfig config;
// 通过init方法对config赋值,获取ServletConfig对象
@Override
public void init(ServletConfig config) throws ServletException {
this.config = config;
}
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 根据name获取value
String encoding = config.getInitParameter("encoding");
System.out.println("encoding:" + encoding);
// 获取所有name并遍历
Enumeration names = config.getInitParameterNames();
while(names.hasMoreElements()){
String name = names.nextElement();
String value = config.getInitParameter(name);
System.out.println(name + "---" + value);
}
// 获取Servlet-name
String sname = config.getServletName();
System.out.println("Servlet-name:" + sname);
// 获取ServletContext对象
ServletContext servletContext = config.getServletContext();
System.out.println(servletContext);
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
doGet(req,resp);
}
}
ServletContext
- ServletContext 是应用上下文对象(应用域对象)。每一个应用中只有一个 ServletContext 对象
- 作用:可以配置和获得应用的全局初始化参数,可以实现Servlet 之间的数据共享
- 生命周期:应用一加载则创建,应用被停止则销毁
域对象
- 域对象指的是对象有作用域,也就是作用范围。域对象可以实现数据的共享。不同作用范围的域对象,共享数据的能力也不一样
- 在Servlet 规范中,一共有4个域对象。ServletContext 就是其中的一个。他也是web 应用中最大的作用域,也叫 application 域。它可以实现整个应用之间的数据共享
配置方式
-
在
常用方法
返回值
方法名
说明
String
getInitParameter(String name)
根据名称获取全局配置的参数
String
getContextPath()
获取当前应用的访问虚拟目录
String
getRealPath(String path)
根据虚拟目录获取应用部署的磁盘绝对路径
HttpServlet类继承自GenericServlet类
GenericServlet类中有getServletContext方法,可以直接获取ServletContext对象
返回值
方法名
说明
void
setAttribute(String name, Object value)
向应用域对象中存储数据
Object
getAttribute(String name)
通过名称获取应用域对象中的数据
void
removeAttribute(String name)
通过名称移除应用域对象中的数据
package study.servlet;
import javax.servlet.ServletContext;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.Enumeration;
public class ServletContextDemo extends HttpServlet{
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
ServletContext servletContext = req.getServletContext();
Enumeration names = servletContext.getInitParameterNames();
while(names.hasMoreElements()){
String name = names.nextElement();
String value = servletContext.getInitParameter(name);
System.out.println(name + "====" + value);
}
resp.setContentType("text/html;charset=UTF-8");
String contextPath = servletContext.getContextPath();
String realPath = servletContext.getRealPath(contextPath);
PrintWriter pw = resp.getWriter();
pw.write("虚拟目录为:" + contextPath + "
");
pw.write("真实目录为:" + realPath);
servletContext.setAttribute("use","lisi");
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
doGet(req,resp);
}
}
注解开发
Servlet3.0 规范
- 我们使用的是Tomcat 9版本。JavaEE规范要求是8.对应的Servlet 版本应该是4.x 版本。但是,在企业开发中,稳定要远比追求新版本重要。所以我们会降低版本使用,用的是Servlet 3.1版本。
- 其实我们之前的操作全部是基于 Servlet 2.5版本规范的,也就是借助于配置文件的方式。后来随着软件开发逐步的演变,基于注解的配置开始流行。而Servlet 3.0版本也就开始支持注解开发了
- Servlet 3.0版本既保留了2.5版本的配置方式,同时有支持了全新的注解配置方式。它可以完全不需要 web.xml 配置文件,就能实现 Servlet 的配置,同时还有一些其他的新特性。
自动注解开发
实现步骤
-
创建一个 web 项目
-
定义一个类,继承HttpServlet
-
重写 doGet 和 doPost方法
-
在类上使用@WebServlet 注解并配置Servlet
-
部署并启动项目
-
通过浏览器测试
@WebServlet(“/servletDemo”)
public class ServletDemo extends HttpServlet{}

手动创建容器(了解)
- Servlet 3.0 规范除了使用自动注解的配置方式外,还支持手动创建 Servlet 容器的方式。如果使用必须遵循其编写规范。在3.0 版本加入了一个新的接口:ServletContainerInitializer,需要重写onStartup方法
步骤
-
定义一个类,继承HttpServlet
-
重写 doGet 和 doPost方法
-
定义一个类,实现ServletContainerInitializer接口
-
在src 目录下创建一个META-INF的包
-
在 META-INF 包下创建一个services 的包
-
在 services 包下创建一个 javax.servlet.ServletContainerInitializer 的文件
-
文件中的内容为容器实现类的全类名
-
在容器实现类中的 onStartup 方法中完成注册 Servlet
public void onStartup(Set -
部署并启动项目
-
通过浏览器测试
学生管理系统1
- 需求:添加学生信息到Java服务器中的本地文件
步骤
- 创建一个 web 项目
- 创建一个用于保存学生信息的html文件
- 创建一个类,继承HttpServlet
- 重写doGet 和 doPost 方法
- 在web.xml 文件中修改默认主页和配置 Servlet
- 在doGet 方法中接收表单数据保存到文件中,并响应给浏览器结果
- 部署并启动项目
- 通过浏览器测试
获取表单数据
req.getParameter(name值):就可以通过HttpServletRequest 对象中的方法 通过表单的name属性获取到对应的表单数据响应数据
PrintWriter pw = resp.getWriter():通过 HttpServletResponse 对象中的方法获取输出流对象
pw.println("Save Success"):将指定内容响应到浏览器中
添加学生
/studentAdd.html
StudentServlet
studentServlet.add
StudentServlet
/add
// add.java
package studentServlet;
import studentServlet.bean.Student;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;
public class add extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 获取对应表单内容
String username = req.getParameter("username");
String age = req.getParameter("age");
String score = req.getParameter("score");
// 封装学生对象
Student stu = new Student(username, Integer.parseInt(age), Integer.parseInt(score));
// 保存到本地文件
BufferedWriter bw = new BufferedWriter(new FileWriter("E:\Java\code\StudentServlet\stu.txt",true));
bw.write(stu.getUsername() + "," + stu.getAge() + "," + stu.getScore());
bw.newLine();
bw.close();
// 响应给浏览器
resp.setContentType("text/html;charset=UTF-8");
PrintWriter pw = resp.getWriter();
pw.println("添加成功,将在3秒后跳转到首页!!!");
resp.setHeader("Refresh","3;url=/index.html");
pw.close();
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
doGet(req, resp);
}
}
请求对象
请求: 获取资源。在BS架构中,就是客户端浏览器向服务端发出询问。
请求对象: 就是在项目中用于发送请求的对象(ServletRequest和HttpServletRequest)
ServletRequest 和 HttpServletRequest 都是接口,但是Tomcat 服务器会帮我们处理好实现类的赋值等工作,我们不需要关心这些
获取各种路径
返回值
方法名
说明
String
getContextPath()
获取虚拟目录名称
String
getServletPath()
获取Servlet映射路径
String
getRemoteAddr()
获取访问者ip地址
String
getQueryString()
获取请求的消息数据
String
getRequestURI()
获取统一资源标识符
StringBuffer
getRequestURL()
获取统一资源定位符
package study.servlet;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.io.PrintWriter;
@WebServlet("/request")
public class RequestDemo extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
String contextPath = req.getContextPath();
String servletPath = req.getServletPath();
String remoteAddr = req.getRemoteAddr();
String queryString = req.getQueryString();
String requestURI = req.getRequestURI();
StringBuffer requestURL = req.getRequestURL();
PrintWriter pw = resp.getWriter();
pw.println("contextPath= " + contextPath);
pw.println("servletPath= " + servletPath);
pw.println("remoteAddr= " + remoteAddr);
pw.println("queryString= " + queryString);
pw.println("requestURI= " + requestURI);
pw.println("requestURL= " + requestURL);
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
doGet(req,resp);
}
}
获取请求头
返回值
方法名
说明
String
getHeader(String name)
根据请求头名称获取一个值
Enumeration
getHeaders(String name)
根据请求头名称获取多个值
Enumeration
getHeaderNames()
获取所有请求头名称
package study.servlet;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.Enumeration;
@WebServlet("/request2")
public class RequestDemo2 extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
System.out.println(req.getHeader("host"));
System.out.println(req.getHeader("user-agent"));
Enumeration headers = req.getHeaders("user-agent");
while(headers.hasMoreElements()){
String s = headers.nextElement();
System.out.println(s);
}
System.out.println("===============");
Enumeration names = req.getHeaderNames();
while(names.hasMoreElements()){
System.out.println(names.nextElement());
}
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
doGet(req,resp);
}
}
获取请求参数信息
返回值
方法名
说明
String
getParameter(String name)
根据名称获取数据
String[]
getParameterValues(String name)
根据名称获取所有数据
Enumeration
getParameterNames()
获取所有名称
Map
getParameterMap()
获取所有参数的键值对
package study.servlet;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.swing.*;
import java.io.IOException;
import java.util.Enumeration;
import java.util.Map;
import java.util.Set;
@WebServlet("/request3")
public class RequestDemo3 extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
System.out.println(req.getParameter("username"));
System.out.println("================");
for (String hobby : req.getParameterValues("hobby")) {
System.out.println(hobby);
}
System.out.println("===================");
Enumeration parameterNames = req.getParameterNames();
while(parameterNames.hasMoreElements()){
String name = parameterNames.nextElement();
for (String value : req.getParameterValues(name)) {
System.out.println(value);
}
}
System.out.println("===================");
Map parameterMap = req.getParameterMap();
for (String key : parameterMap.keySet()) {
String[] value = parameterMap.get(key);
System.out.println(key + " === " + value);
}
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
doGet(req,resp);
}
}
获取请求参数并封装对象
-
手动封装方式
成员变量名称和参数name属性值保持一致 -
反射封装方式
属性描述器:PropertyDescriptor(根据名称获取到对象中对应的get和set方法) -
工具类封装方式
beanutils工具类,populate方法
在发布之前,还需要进入File-Project Structure
package study.servlet;
import study.servlet.bean.Student;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.beans.IntrospectionException;
import java.beans.PropertyDescriptor;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
import java.util.Map;/*
- 封装对象------反射方式
- */
public class RequestDemo5 extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 获取所有数据
Map
// 封装学生对象
Student stu = new Student();
// 遍历集合
for(String name : map.keySet()){
String[] value = map.get(name);
try {
// 获取Student对象的属性描述器
PropertyDescriptor pd = new PropertyDescriptor(name, stu.getClass());
// 获取对应的set方法
Method writeMethod = pd.getWriteMethod();
// 执行方法
writeMethod.invoke(stu,value);
} catch (IntrospectionException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
doGet(req,resp);
}
}
package study.servlet;
import org.apache.commons.beanutils.BeanUtils;
import study.servlet.bean.Student;/*
- 封装对象------工具类方式
需要导包:BeanUtils - */
public class RequestDemo6 extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 获取所有数据
Map
// 封装学生对象
Student stu = new Student();
try {
BeanUtils.populate(stu, map);
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
doGet(req,resp);
}
}
流对象获取请求信息
返回值
方法名
说明
BufferedReader
getReader()
获取字符输入流
ServletInputStream
getInputStream()
获取字节输入流
用IO流获取请求信息时,不支持get方式,只支持post提交方式
获得到的流对象都不是自己new出来的,不需要close释放资源,会由请求对象处理并释放
package study.servlet;
import org.apache.commons.beanutils.BeanUtils;
import study.servlet.bean.Student;
import javax.servlet.ServletException;
import javax.servlet.ServletInputStream;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.BufferedReader;
import java.io.IOException;
import java.util.Map;
/*
* 流对象获取数据
* */
@WebServlet("/request7")
public class RequestDemo7 extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 字符流(必须是post请求方式)
BufferedReader br = req.getReader();
String line;
while((line = br.readLine()) != null) System.out.println(line);
// 字节流
ServletInputStream is = req.getInputStream();
byte[] arr = new byte[1024];
int len;
while((len = is.read(arr)) != -1){
System.out.println(new String(arr, 0, len));
}
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
doGet(req,resp);
}
}
中文乱码问题
-
GET方式
没有乱码问题,在Tomcat 8 版本后已经解决 -
POST方式
有乱码问题,可以通过 setCharacterEncoding() 方法来解决(编码格式要和页面编码格式一致)package study.servlet;
/*
- 中文乱码问题
- */
@WebServlet(“/request8”)
public class RequestDemo8 extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
req.setCharacterEncoding(“UTF-8”);
String name = req.getParameter(“name”);
System.out.println(name);
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
doGet(req,resp);
}
}
请求域
-
请求域(request域):可以在一次请求范围内进行共享数据。
-
一般用于请求转发的多个资源中共享数据
-
请求对象操作共享数据方法
返回值
方法名
说明
void
setAttribute(String name, Object value)
向请求域对象中存储数据
Object
getAttribute(String name)
通过名称获取请求域对象中的数据
void
removeAttribute(String name)
通过名称移除请求域对象中的数据
请求转发
- 请求转发:客户端的一次请求到达以后,发现需要借助其他 Servlet 来实现功能(浏览器请求,A发现做不了,转发给B去做)
- 特点
- 浏览器地址栏不变
- 域对象中的数据不丢失
- 负责转发的Servlet 转发前后的响应正文会丢失
- 由转发的目的地来响应客户端
返回值
方法名
说明
RequestDispatcher
getRequestDispatcher(String name)
获取请求调度对象
void
forward(ServletRequest req, ServletResponse resp)
实现转发(用请求调度对象调用)
package study.servlet.request;
/*
* 请求转发
* */
@WebServlet("/request9")
public class RequestDemo9 extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 设置共享数据
req.setAttribute("name","张三");
// 获取请求调度对象
RequestDispatcher rd = req.getRequestDispatcher("/request10");
// 请求转发
rd.forward(req, resp);
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
doGet(req,resp);
}
}
package study.servlet.request;
/*
* 转发目的
* */
@WebServlet("/request10")
public class RequestDemo10 extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 获取共享数据
System.out.println(req.getAttribute("name"));
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
doGet(req,resp);
}
}
请求包含
- 请求包含:可以合并其他Servlet 中的功能一起响应给客户端(浏览器请求,A只能做一半,另一半让B做)
- 特点
- 浏览器地址栏不变
- 域对象中的数据不丢失
- 被包含的 Servlet 响应头会丢失
返回值
方法名
说明
RequestDispatcher
getRequestDispatcher(String name)
获取请求调度对象
void
include(ServletRequest req, ServletResponse resp)
实现包含
package study.servlet.request;
/*
* 请求包含
* */
@WebServlet("/request11")
public class RequestDemo11 extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 设置共享数据
req.setAttribute("name","张三");
// 获取请求调度对象
RequestDispatcher rd = req.getRequestDispatcher("/request10");
// 请求转发
rd.include(req, resp);
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
doGet(req,resp);
}
}
响应对象
-
响应:回馈结果。在 BS 架构中,就是服务器给客户浏览器反馈结果
-
响应对象:就是在项目中用于发送响应的对象
ServletResponse(接口)
HttpServletResponse(继承自ServletResponse,基于http协议的接口)和请求对象一样,不需要我们去写实现类,在Tomcat 服务器创建好,在执行
doGet或者doPost方法时,服务器会把相应的实现类对象传递
常见状态码
状态码
说明
200
成功
302
重定向
304
请求资源未改变,使用缓存
400
请求错误,常见于请求参数错误
404
请求资源未找到
405
请求方式不支持
500
服务器错误
字节流响应消息
返回值
方法名
说明
ServletOutputStream
getOutputStream()
获取响应字节输出流对象
void
setContentType(“text/html;charset=UTF-8”)
设置响应内容类型,解决中文乱码问题
步骤:
- 获取字节输出流对象
- 定义一个消息(一个字符串)
- 通过字节流对象输出
获取到的字节输出流对象不需要close释放,会由响应对象处理并释放
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 获取字节输出流
ServletOutputStream os = resp.getOutputStream();
String s = "字节输出流响应消息";
os.write(s.getBytes());
}
未出现乱码问题:浏览器默认gbk编码,idea默认UTF-8编码;但是
getBytes方法在将字符串转为字节数组时,如果不传递参数指定编码,就会根据当前系统平台默认编码进行转换,Windows系统默认编码为gbk,和浏览器一致,故未出现乱码
// 统一编码格式为UTF-8并解决乱码问题
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 设置相应内容类型,并设置编码格式(告知浏览器应该采用的编码格式)
resp.setContentType("text/html;charset=UTF-8");
// 获取字节输出流
ServletOutputStream os = resp.getOutputStream();
String s = "字节输出流响应消息";
os.write(s.getBytes("UTF-8"));
}
字符流响应消息
返回值
方法名
说明
PrintWriter
getWriter()
获取响应字符输出流对象
void
setContentType(“text/html;charset=UTF-8”)
设置响应内容类型,解决中文乱码问题
步骤和上面字节流一样,同样不需要自己close释放资源
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 设置相应内容类型,并设置编码格式(告知浏览器应该采用的编码格式)
resp.setContentType("text/html;charset=UTF-8");
// 获取字符输出流对象
PrintWriter pw = resp.getWriter();
pw.write("字符输出流响应消息");
}
响应图片
-
通过文件的相对路径获取绝对路径(getRealPath)
-
创建字节输入流对象,关联读取的图片路径
-
通过响应对象获取字节输出流对象
-
循环读取和写出图片
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
String realPath = getServletContext().getRealPath(“/img/tx.png”);
// 创建字节输入流对象,关联图片
BufferedInputStream is = new BufferedInputStream(new FileInputStream(realPath));
// 获取字节输出流对象,响应图片
ServletOutputStream os = resp.getOutputStream();
// 循环读写
byte[] arr = new byte[1024];
int len;
while((len = is.read(arr)) != -1){
os.write(arr, 0, len);
}
// 释放资源
is.close();
}
设置缓存
- 缓存:对于不经常变化的数据,我们可以设置合理的缓存时间,以避免浏览器频繁请求服务器。以此来提高效率
返回值
方法名
说明
void
setDateHeader(String name,long time)
设置消息头添加缓存
例:
resp.setDateHeader("Expires",System.currentTimeMillis() + 1*60*60*1000);设置一个小时缓存时间
Expires 就是过期的意思
时间单位为毫秒,1秒等于1000毫秒
定时刷新
- 定时刷新:过了指定时间后,页面自动进行跳转
返回值
方法名
说明
void
setHeader(String name,String value)
设置消息头定时刷新
例:
resp.setHeader("Refresh","3;URL=要跳转的路径")
单位为秒
请求重定向
-
请求重定向:客户端的一次请求到达后,发现需要借助其他Servlet 来实现功能
-
特点:浏览器地址栏会发生改变,两次请求,请求域对象中不能共享数据,可以重定向到其他服务器
-
重定向实现原理
- 设置响应状态码为302:
resp.setStatus(302); - 设置响应的资源路径(响应到哪里去,通过响应消息头 location 来指定):
resp.setHeader("location","/response/responseDemo")
- 设置响应状态码为302:
-
响应对象重定向方法
返回值
方法名
说明
void
sendRedirect(String name)
设置重定向
文件下载
-
创建字节输入流,关联读取的文件
-
设置响应消息头支持的类型:
resp.setHeader("Content-Type","application/octet-stream")
Content-Type:消息头名称,代表所支持的类型
application/octet-stream:消息头参数,代表应用的类型为字节流 -
设置响应消息头以下载方式打开资源:
resp.setHeader("Content-Disposition","attachment;filename=下载的文件名称")
Content-Disposition:消息头名称,代表处理形式
attachment;filename=xxx:消息头参数,代表附件的形式进行处理,filename代表指定下载文件的名称 -
通过响应对象获取字节输出流对象
-
循环读写
-
释放资源
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 创建字节输入流,关联读取的文件
String realPath = req.getServletContext().getRealPath(“/img/tx.png”);
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(realPath));
// 设置响应消息头支持的类型
resp.setHeader(“Content-Type”, “application/octet-stream”);
// 设置响应消息头以下载方式打开资源
resp.setHeader(“Content-Disposition”,“attachment;filename=file.png”);
// 通过响应对象获取字节输出流对象
ServletOutputStream os = resp.getOutputStream();
int len;
byte[] arr = new byte[1024];
while((len = bis.read(arr)) != -1){
os.write(arr, 0, len);
}
// 释放资源
bis.close();
}
学生管理系统2
-
资源准备
- 创建一个 web 项目
- 在web 目录下创建一个 index.html,包含两个超链接标签(添加学生、查看学生)
- 在 web目录下创建一个 addStudent.html,用于实现添加功能的表单页面
- 在 src 下创建一个 Student 类,用于封装学生信息
// list.java
package studentServlet;import studentServlet.bean.Student;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.*;
import java.util.ArrayList;
@WebServlet(“/list”)
public class list extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
BufferedReader br = new BufferedReader(new FileReader(“E:\Java\code\StudentServlet\stu.txt”));
ArrayList list = new ArrayList<>();
String str;
while((str = br.readLine()) != null){
String[] split = str.split(“,”);
Student stu = new Student(split[0], Integer.parseInt(split[1]), Integer.parseInt(split[2]));
list.add(stu);
}
resp.setContentType(“text/html;charset=UTF-8”);
PrintWriter pw = resp.getWriter();
for(Student student : list){
pw.write(student.getUsername() + “,” + student.getAge() + “,” + student.getScore());
pw.write(“
”);
}
br.close();
}@Override protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { doGet(req,resp); }}
学生信息管理系统学生信息管理系统
添加学生信息 查看学生信息
Cookie
会话
- 会话:浏览器和服务器之间的多次请求和响应
- 为了实现一些功能,浏览器和服务器之间可能会产生多次的请求和响应,从浏览器访问服务器开始,到访问服务器结束(关闭浏览器、到了过期时间)。这期间产生的多次请求和响应加在一起就称之为浏览器和服务器之间的一次会话
- 会话过程所产生的一些数据,可以通过会话技术(Cookie 和 Session)保存。
概述
- Cookie: 客户端会话管理技术
把要共享的数据保存到客户端
每次请求时,把会话信息带到服务器端,从而实现多次请求的数据共享 - 作用:可以保存客户端访问网站的相关内容,从而保证每次访问时先从本地缓存中获取,以此提高效率
- 特点:
- 是一个普通的Java类
- 两个必须属性:name 和value
- 发送:
HttpServletResponse.addCookie(Cookie对象) - 每个网站最多20个Cookie,浏览器存储的Cookie总数不大于300个,每个Cookie大小限制在4kb
- 获取所有Cookie对象:
HttpServletRequest.getCookie()
Cookie属性
属性名
作用
是否重要
name
Cookie的名称
必须属性
value
Cookie的值(不支持中文)
必须属性
path
Cookie的路径
重要
domain
Cookie的域名
重要
maxAge
Cookie的存活时间(s)
重要
version
Cookie的版本号
不重要
comment
Cookie的描述
不重要
方法
方法名
作用
Cookie(String name, String value)
构造方法创建对象
属性对应的set和get方法
赋值和获取值(name有final修饰,无set方法)
- 向客户端添加Cookie:
void HttpServletResponse.addCookie(Cookie cookie) - 获取所有的Cookie:
Cookie[] HttpServletRequest.getCookies()
练习
-
需求说明:通过Cookie记录最后访问时间,并在浏览器上显示出来
-
最终目的:掌握Cookie的基本使用,从创建到添加客户端,再到从服务器端获取
-
实现步骤
- 通过响应对象写出一个提示信息
- 创建Cookie对象,指定name和value
- 设置Cookie最大存活时间
- 通过响应对象将Cookie对象添加到客户端
- 通过请求对象获取Cookie对象
- 将Cookie对象中的访问时间写出
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 通过响应对象写出一个提示信息
resp.setContentType(“text/html;charset=UTF-8”);
PrintWriter pw = resp.getWriter();
pw.write(“您的最后访问时间为:”);
pw.write(“
”);
// 创建Cookie对象,指定name和value
Cookie cookie = new Cookie(“time”, System.currentTimeMillis()+“”);
// 设置Cookie最大存活时间
cookie.setMaxAge(3600);
// 通过响应对象将Cookie对象添加到客户端
resp.addCookie(cookie);
// 通过请求对象获取Cookie对象
Cookie[] cookies = req.getCookies();
// 将Cookie对象中的访问时间写出
for(Cookie ck : cookies){
if(“time”.equals(ck.getName())){
String value = ck.getValue();
// 格式化时间
SimpleDateFormat sdf = new SimpleDateFormat(“yyyy-MM-dd HH:mm:ss”);
String lastTime = sdf.format(new Date(Long.parseLong(value)));
pw.write(lastTime);
}
}
}
注意事项
- 数量限制
每个网站最多只能用20个Cookie,且大小不能超过4kb,所有网站的Cookie总数不超过300个 - 名称限制
Cookie的名称只能包含ASCII码表中的字母、数字字符。不能包含逗号、分号、空格,不能以$开头。
Cookie的值不支持中文 - 存活时间限制:
setMaxAge()方法接收数字
负整数:当前会话有效,浏览器关闭则清除(默认)
0:立即清除
正整数:以秒为单位设置存活时间 - 访问路径限制
取自第一次访问的资源路径前缀
只要以这个前缀开头(包括子级路径)就能获取到,反之获取不到
设置路径:setPath()方法设置指定路径
Session
-
HttpSession:服务器端会话管理技术
本质也是采用客户端会话管理技术只不过在客户端保存的是一个特殊标识,而共享的数据保存到了服务器端的内存对象中。
每次请求时,会将特殊标识带到服务器端,根据这个标识来找到对应的内存空间,从而实现数据共享
是Servlet规范中四大域对象之一的会话域对象 -
作用:可以实现数据共享
域对象
功能
作用
ServletContext
应用域
在整个应用之间实现数据共享
ServletRequest
请求域
在当前的请求或请求转发之间实现数据共享
HttpSession
会话域
在当前会话范围之间实现数据共享
常用方法
返回值
方法名
说明
void
setAttribute(String name, Object value)
设置共享数据
Object
getAttribute(String name)
获取共享数据
void
removeAttribute(String name)
移除共享数据
String
getId()
获取唯一标识名称
void
Invalidate()
让session立即失效
对象获取
-
HttpSession 是一个接口,对应的实现类对象是通过HttpServletRequest 对象来获取
返回值
方法名
说明
HttpSession
getSession()
获取HttpSession对象
HttpSession
getSession(boolean create)
获取HttpSession对象,未获取到是否自动创建(默认true)
练习
-
需求说明:通过第一个Servlet 设置共享数据用户名,并在第二个Servlet 获取到
-
最终目的:掌握HttpSession 的基本使用,如何获取和使用
-
实现步骤
- 在第一个 Servlet 中获取请求的用户名
- 获取 HttpSession 对象
- 将用户名设置到共享数据中
- 在第二个 Servlet 中获取 HttpSession 对象
- 获取共享数据用户名
- 将获取到的用户名响应给客户端浏览器
// Session01
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 在第一个 Servlet 中获取请求的用户名
String username = req.getParameter(“username”);
// 获取 HttpSession 对象
HttpSession session = req.getSession();
// 将用户名设置到共享数据中
session.setAttribute(“username”,username);
}// session02
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
// 在第二个 Servlet 中获取 HttpSession 对象
HttpSession session = req.getSession();
// 获取共享数据用户名
Object username = session.getAttribute(“username”);
// 将获取到的用户名响应给客户端浏览器
PrintWriter pw = resp.getWriter();
pw.write(username+“”);
}
注意事项
- 唯一标识的查看:借助浏览器开发者工具
- 浏览器禁用Cookie
方式一:通过提示信息告知用户,大部分网站采用的解决方式【推荐】
方式二:通过resp.enconeURL方法实现url重写(地址栏拼接jsessionid)【了解】 - 钝化和活化
- 钝化:序列化。把长时间不用,但还不到过期时间的HttpSession进行序列化,写到磁盘上
- 活化:相反的状态
- 钝化时间
第一种情况: 当访问量很大时,服务器会根据getLastAccessTime 来进行排序,对长时间不用,但还没到过期时间的HttpSession进行序列化
第二种情况: 当服务器进行重启的时候,为了保持客户HttpSession 中的数据,也要对其进行序列化
HttpSession 的序列化由服务器自动完成,我们无需关心
JSP
- JSP(Java Server Pages):是一种动态网页技术标准
- JSP 部署在服务器上,可以处理客户端发送的请求,并根据请求内容动态的生成 HTML、XML 或其他格式文档的 Web网页,然后再响应给客户端。
- Jsp 是基于Java 语言的,它的本质就是 Servlet
类别
使用场景
HTML
开发静态资源,无法添加动态资源
CSS
美化页面
JavaScript
给网页添加一些动态效果
Servlet
编写Java 代码,实现后台功能处理
JSP
包含了显示页面技术,也具备Java代码功能
快速入门
-
创建一个web项目
-
在web 目录下创建一个 index.jsp 文件
-
在文件中写一句内容为:这是我的第一个jsp
-
部署并启动项目
-
通过浏览器测试
<%@ page contentType=“text/html;charset=UTF-8” language=“java” %>
Title 第一个jsp
执行过程
- 客户端浏览器发送请求到Tomcat 服务器
- Tomcat 服务器解析请求地址
- 找到具体的应用
- 找到对应的jsp文件
- 将jsp文件翻译为.java的文件
- 编译Java文件
- 响应给客户端
文件内容介绍
- 生成的Java 文件目录
继承自 HttpJspBase类,而HttpJspBase继承自 HttpServlet(JSP本质上就是一个 Servlet)
jsp显示页面本质上就是通过获取输出流对象并通过write写出
语法
- JSP注释:
<%-- 注释的内容 --%> - Java代码块:
<% Java代码 %> - JSP表达式:
<%=表达式%> - JSP声明:
<%! 声明变量或方法 %>
System.out.println():普通输出语句,输出在控制台上
out.println():JspWriter 对象,将内容输出在浏览器页面上,不会自动换行
<%="要输出的内容"%>就相当于out.println("要输出的内容")
在声明中,如果加!,代表声明的是成员变量;如果不加!,代表声明的是局部变量;如果是声明方法,就必须加!
指令
-
page 指令:
<%@ page 属性名=属性值 属性名=属性值... %>属性名
作用
contentType
响应正文支持的类型和设置编码格式
language
使用的语言,默认是Java
errorPage
当前页面出现异常后跳转的页面
isErrorPage
是否抓住异常,如果为true则页面中就可以使用异常对象,默认是false
import
导包 import= “java.util.ArrayList”
session
是否创建 HttpSession 对象,默认是true
buffer
设定 JspWriter 输出jsp内容缓存的大小,默认8kb
pageEncoding
翻译jsp时所用的编码格式
isEIgnored
是否忽略EL表达式,默认是false
-
include 指令:可以包含其他页面
<%@ include file=包含的页面 %> -
taglib 指令:可以引入外部标签库
<%@ taglib uri=标签库的地址 prefix=前缀名称 %>
注意事项
-
九大隐式对象(不用创建,可以直接使用)
隐式对象名称
代表实际对象
request
javax.servlet.http.HttpServletRequest
response
javax.servlet.http.HttpServletResponse
session
javax.servlet.http.HttpSession
application
javax.servlet.ServletContext
page
java.lang.Object
config
javax.servlet.ServletConfig
exception
java.lang.Throwable
out
javax.servlet.jsp.JspWriter
pageContext
javax.servlet.jsp.PageContext
-
PageContext 对象
- 是 JSP 独有的, Servlet 中没有
- 是四大域对象之一的页面域对象,还可以操作其他三个域对象中的属性
- 可以获取其他八个隐式对象
- 生命周期是随着 JSP 的创建而存在,随着 JSP 的结束而消失。每个JSP 页面都有一个 PageContext 对象
四大域对象
域对象名称
范围
级别
备注
PageContext
页面范围
最小,只能在当前页面使用
因范围太小,开发中用的很少
ServletRequest
请求范围
一次请求或当前请求转发用
请求转发之后,再次转发时请求域丢失
HttpSession
会话范围
多次请求数据共享时使用
多次请求共享数据,但不同的客户端不能共享
ServletContext
应用范围
最大,整个应用都可以使用
尽量少用,如果对数据有修改需要做同步处理
MVC模型
- M(Model):模型。 用于封装数据,封装的是数据模型
- V(View):视图。 用于显示数据,动态资源用 JSP页面,静态资源用 HTML 页面
- C(Controller):控制器。 用于处理请求和响应,例如 Servlet

学生管理系统3
登录功能
-
创建一个web目录
-
在web目录下创建一个index.jsp
-
在页面中获取会话域中的用户名,获取到了就显示添加和查看功能的超链接,没获取到就显示登录功能的超链接
-
在web目录下创建一个login.jsp。实现登录页面
-
创建 LoginServlet,获取用户名和密码
-
如果用户名为空,则重定向到登录页面
-
如果不为空,将用户名添加到会话域中,再重定向到首页
<%-- login.jsp --%>
登录
<%–
Created by IntelliJ IDEA.
User: lihao
Date: 2022/2/24
Time: 20:25
To change this template use File | Settings | File Templates.
–%>
<%@ page contentType=“text/html;charset=UTF-8” language=“java” %>学生信息管理系统--登录
用户名: 密码: 登录// login.java
package studentServlet;import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
import java.io.IOException;
@WebServlet(“/login”)
public class login extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
HttpSession session = req.getSession();
String username = req.getParameter(“username”);
String password = req.getParameter(“password”);
resp.setContentType(“text/html;charset=UTF-8”);
if(null == username || “”.equals(username)){
resp.getWriter().write(“账号不能为空,请重新输入(2s后返回…)”);
resp.setHeader(“Refresh”,“2;URL=/login.jsp”);
}else{
if(“admin”.equals(username) && “abc123”.equals(password)){
session.setAttribute(“username”,username);
resp.sendRedirect(“/index.jsp”);
}else{
resp.getWriter().write(“账号密码不正确,请重新输入(2s后返回…)”);
resp.setHeader(“Refresh”,“2;URL=/login.jsp”);
}
}
}@Override protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { doGet(req,resp); }}
<%-- index.jsp --%>
学生信息管理系统
<%–
Created by IntelliJ IDEA.
User: lihao
Date: 2022/2/24
Time: 19:58
To change this template use File | Settings | File Templates.
–%>
<%@ page contentType=“text/html;charset=UTF-8” language=“java” %>学生信息管理系统
<% if(session.getAttribute("username") == null){ %> 请登录 <% } else { %> 添加学生信息 查看学生信息 <% } %><%-- list.jsp --%>
查看学生 <% ArrayList students = (ArrayList) session.getAttribute("students"); for(Student stu : students){ %> <% } %>
<%@ page import=“java.util.ArrayList” %>
<%@ page import=“studentServlet.bean.Student” %>
<%–
Created by IntelliJ IDEA.
User: lihao
Date: 2022/2/24
Time: 20:30
To change this template use File | Settings | File Templates.
–%>
<%@ page contentType=“text/html;charset=UTF-8” language=“java” %>姓名 年龄 成绩 <%=stu.getUsername()%> <%=stu.getAge()%> <%=stu.getScore()%> // list.java
package studentServlet;import studentServlet.bean.Student;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.*;
import java.util.ArrayList;
@WebServlet(“/list”)
public class list extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
BufferedReader br = new BufferedReader(new FileReader(“E:\Java\code\StudentServlet\stu.txt”));
ArrayList list = new ArrayList<>();
String str;
while((str = br.readLine()) != null){
String[] split = str.split(“,”);
Student stu = new Student(split[0], Integer.parseInt(split[1]), Integer.parseInt(split[2]));
list.add(stu);
}
req.getSession().setAttribute(“students”,list);
resp.sendRedirect(“/list.jsp”);
}@Override protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { doGet(req,resp); }}
EL表达式
- EL(Expression Language):表达式语言
- 在 JSP 2.0 规范中加入的内容,也是 Servlet 规范的一部分
- 作用:在 JSP 页面中获取数据,让我们的 JSP 脱离 Java代码块和 JSP 表达式
- 语法:
${表达式内容}
快速入门
-
创建一个web 项目
-
在web 目录下创建 jsp文件
-
在文件中向域对象添加数据
-
使用三种方式获取域对象中的数据(Java代码块、JSP表达式、EL表达式)
-
部署并启动项目
-
通过浏览器测试
<%–
EL表达式快速入门 <% request.setAttribute("username","zhangsan"); %>
Created by IntelliJ IDEA.
User: lihao
Date: 2022/2/25
Time: 10:04
To change this template use File | Settings | File Templates.
–%>
<%@ page contentType=“text/html;charset=UTF-8” language=“java” %><%--java代码块--%> <% out.println(request.getAttribute("username")); %>
<%-- jsp表达式 --%> <%=request.getAttribute("username")%>
<%--EL表达式--%> ${username}
获取数据
-
获取基本数据类型的数据
${数据名} -
获取自定义对象类型的数据
${对象名.属性名}
这里获取到对象的成员变量的原理是通过调用get方法获取,所以不必担心private私有问题 -
获取数组类型的数据
${数组名[索引]} -
获取List 集合类型的数据
${集合[索引]} -
获取 Map 集合类型的数据
${集合.key值}:获取key对应的value<%@ page import=“study.servlet.bean.Student” %>
EL表达式获取数据 <% Student stu = new Student("张三",23); int[] arr = {1,2,3,4,5}; ArrayList list = new ArrayList<>(); list.add("aaa"); list.add("bbb"); list.add("ccc"); HashMap
<%@ page import=“java.util.ArrayList” %>
<%@ page import=“java.util.HashMap” %><%–
Created by IntelliJ IDEA.
User: lihao
Date: 2022/2/25
Time: 10:10
To change this template use File | Settings | File Templates.
–%>
<%@ page contentType=“text/html;charset=UTF-8” language=“java” %>
注意事项
- EL 表达式没有空指针异常
- EL 表达式没有索引越界异常
- EL 表达式没有字符串的拼接
使用细节
- EL 表达式能够获取到四大域对象的数据,根据名称从小到大在域对象中查找
- 还可以获取 JSP 其他八个隐式对象,并调用对象中的方法
运算符
-
关系运算符
运算符
作用
示例
结果
== 或 eq
等于
${5 == 5} 或 ${5 eq 5}
true
!= 或 ne
不等于
${5 != 5} 或 ${5 ne 5}
false
< 或 lt
小于
${3 < 5} 或 ${3 lt 5}
true
> 或 gt
大于
${3 > 5} 或 ${3 gt 5}
false
<= 或 le
小于等于
${3 <= 5} 或 ${3 le 5}
true
>= 或 ge
大于等于
${3 >= 5} 或 ${3 ge 5}
false
-
逻辑运算符
运算符
作用
示例
结果
&& 或 and
并且
${A && B} 或 ${A and B}
true / false
|| 或 or
或者
${A || B} 或 ${A or B}
true / false
! 或 not
取反
${!A} 或 ${not A}
true / false
-
其他运算符
运算符
作用
empty
1. 判断对象是否为null
2. 判断字符串是否为空字符串
3. 判断容器元素是否为0条件 表达式1 : 表达式2
三元运算符
隐式对象
隐式对象名称
对应JSP隐式对象
说明
pageContext
pageContext
功能完全相同
applicationScope
无
操作应用域对象数据
sessionScope
无
操作会话域对象数据
requestScope
无
操作请求域对象数据
pageScope
无
操作页面域对象数据
header
无
获取请求头数据
headerValues
无
获取请求头数据(多个值)
param
无
获取请求参数数据
paramValues
无
获取请求参数数据(多个值)
initParam
无
获取全局配置参数数据
cookie
无
获取Cookie对象
<%--
Created by IntelliJ IDEA.
User: lihao
Date: 2022/2/25
Time: 10:21
To change this template use File | Settings | File Templates.
--%>
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
隐式对象
<%--pageContext对象,可以获取其他三个域对象和JSP中八个隐式对象--%>
${pageContext.request.requestURL}
<%--applicationScope sessionScope requestScope pageScope 操作四大域对象中的数据--%>
${pageContext.setAttribute("username","zhangsan")}
${pageScope.username}
<%--header headerValues 获取请求头数据--%>
${header["connection"]}
${headerValues["connection"][0]}
${header.connection}
<%--param paramValues 获取请求参数数据--%>
${param.username}
${paramValues.hobby[0]}
<%--initParam 获取全局配置参数--%>
${initParam.globaldesc}
<%--cookie 获取cookie信息--%>
${cookie} <%--直接写cookie获取到的是一个map集合--%>
${cookie.JSESSIONID.value}
JSTL
- JSTL(Java Server Pages Standarded Tag Library):JSP 标准标签库
- 主要提供给开发人员一个标准通用的标签库
- 开发人员可以利用这些标签来取代 JSP 页面上的Java代码,从而提高程序的可读性,降低程序的维护难度
组成
作用
说明
core
核心标签库
通用的逻辑处理
fmt
国际化
不同地域显示不同语言
functions
EL 函数
EL 表达式可以使用的方法
sql
操作数据库
了解
xml
操作XML
了解
核心标签
标签名称
功能分类
属性
作用
<标签名:if>
流程控制
核心标签库
用于条件判断
<标签名:choose>
<标签名:when>
<标签名:otherwise>
流程控制
核心标签库
用于多条件判断
<标签名:forEach>
迭代遍历
核心标签库
用于循环遍历
使用步骤
-
创建一个 web 项目
-
在 web目录下创建一个 WEB-INF 目录
-
在 WEB-INF 目录下创建一个 libs 目录,将 JSTL 的 jar 包导入
-
创建 JSP 文件,通过 taglib 导入 JSTL 标签库
-
对流程控制和迭代遍历的标签进行使用
-
部署并启动项目
-
通过浏览器查看
<%@ page import=“java.util.ArrayList” %><%–
Created by IntelliJ IDEA.
User: lihao
Date: 2022/2/25
Time: 10:45
To change this template use File | Settings | File Templates.
–%>
<%@ page contentType=“text/html;charset=UTF-8” language=“java” %><%–导入核心库并起标签名–%>
JSTL【JSP标准标签库】 ${pageContext.setAttribute("score","A")}
<%@ taglib uri=“http://java.sun.com/jstl/core_rt” prefix=“c” %><%--对成绩进行判断--%>
<%--多条件判断--%>
<%--循环遍历--%> <% ArrayListlist = new ArrayList<>(); list.add("aaa"); list.add("bbb"); list.add("ccc"); list.add("ddd"); pageContext.setAttribute("list",list); %>
Filter
- 在程序中访问服务器资源时,当一个请求到来,服务器首先判断是否有过滤器与请求资源相关联,如果有,过滤器可以将请求拦截下来,完成一些特定的功能,再由过滤器决定是否交给请求资源。如果没有相关联的过滤器则像之前那样直接请求资源了。响应也是类似的
- 过滤器一般完成用于通用的操作,例如:登录验证、统一编码处理、敏感字符过滤等等…
概述
-
是一个接口。如果想实现过滤器的功能,必须实现该接口
-
核心方法
返回值
方法名
作用
void
init(FilterConfig config)
初始化方法
void
doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
对请求资源和响应资源过滤
void
destroy()
销毁方法
-
配置方式
方式一:配置文件(web.xml)
方式二:注解方式
FilterChain
-
FilterChain 是一个接口,代表过滤器链对象。由Servlet 容器提供实现类对象。直接使用即可
-
过滤器可以定义多个,就会组成过滤器链
-
核心方法
返回值
方法名
说明
void
doFilter(ServletRequest request, ServletResponse response)
放行方法
如果有多个过滤器,在第一个过滤器中调用下一个过滤器,依此类推。直到到达最终访问资源。
如果只有一个过滤器,放行时,就会直接到达最终访问资源
过滤器使用
-
需求说明:通过 Filter 过滤器解决多个资源写出中文乱码的问题
-
实现步骤
- 创建一个 web 项目
- 创建两个 Servlet 功能类,都向客户端写出中文数据
- 创建一个 Filter 过滤器实现类,重写 doFilter 核心方法
- 在方法内解决中文乱码,并放行
- 部署并启动项目
- 通过浏览器测试
package study.servlet.filter;
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import java.io.IOException;
@WebFilter(“/filter01”)
public class filter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
System.out.println(“filter执行了”);
// 处理乱码
servletResponse.setContentType(“text/html;charset=UTF-8”);
// 放行
filterChain.doFilter(servletRequest,servletResponse);
}
@Override
public void destroy() {}
}
使用细节
-
配置方式
注解方式:@WebFilter(拦截路径)
配置文件方式demo 全类名 demo /拦截路径 -
多个过滤器使用顺序
如果有多个过滤器,取决于过滤器映射的顺序
生命周期
- 创建
当应用加载时实例化对象并执行init初始化方法 - 服务
对象提供服务的过程,执行 doFilter 方法 - 销毁
当应用卸载时或服务器停止时对象销毁。执行 destroy 方法
FilterConfig
FilterConfig 是一个接口。代表过滤器的配置对象,可以加载一些初始化参数
核心方法
返回值
方法名
作用
String
getFilterName()
获取过滤器对象名称
String
getInitParameter(String name)
根据name获取 value
Enumeration
getInitParameterNames()
获取所有参数的key
ServletContext
getServletContext()
获取应用上下文对象
demo
全类名
username
zhangsan
五种拦截行为
Filter 过滤器默认拦截的是请求,但是在实际开发中,我们还有请求转发和请求包含,以及由服务器触发调用的全局错误页面。默认情况下过滤器是不参与过滤的,要想使用,就需要我们配置
拦截方式
demo
全类名
demo
/拦截路径
REQUEST
FORWARD
INCLUDE
ERROR
ASYNC
REQUEST:默认值,浏览器直接请求的资源会被过滤器拦截
FORWARD:转发访问资源会被过滤器拦截
INCLUDE:包含访问资源
ERROR:全局错误跳转资源
ASYNC:异步访问资源
全局错误页面配置
java.lang.exception
/error.jsp
404
/error.jsp
Listener
- 观察者设计模式,所有的监听器都是基于观察者设计模式的
- 三个组成部分
- 事件源:触发事件的对象
- 事件:触发的动作,封装了事件源
- 监听器:当事件源触发事件后,可以完成功能
- 在程序当中,我们可以对:对象的创建销毁、域对象中属性的变化、会话相关内容进行监听
- Servlet 规范中共计 8 个监听器,监听器都是以接口形式提供,具体功能需要我们自己来完成
监听器
监听对象的创建和销毁的监听器
ServletContextListener:用于监听 ServletContext 对象的创建和销毁
核心方法
返回值
方法名
作用
void
contextInitialized(ServletContextEvent sce)
对象创建时执行该方法
void
contextDestroyed(ServletContextEvent sce)
对象销毁时执行该方法
参数:ServletContextEvent 代表事件对象
事件对象中封装了事件源,也就是 ServletContext
真正的事件指的是创建或销毁 ServletContext 对象的操作
HttpSessionListener:用于监听 HttpSession 对象的创建和销毁
核心方法
返回值
方法名
作用
void
sessionCreated(HttpSessionEvent se)
对象创建时执行该方法
void
sessionDestroyed(HttpSessionEvent se)
对象销毁时执行该方法
参数:HttpSessionEvent 代表事件对象
事件对象中封装了事件源,也就是 HttpSession
真正的事件指的是创建或销毁 HttpSession 对象的操作
ServletRequestListener:用于监听 ServletRequest 对象的创建和销毁
核心方法
返回值
方法名
作用
void
requestInitialized(ServletRequestEvent sre)
对象创建时执行该方法
void
requestDestroyed(ServletRequestEvent sre)
对象销毁时执行该方法
参数:ServletRequestEvent 代表事件对象
事件对象中封装了事件源,也就是 ServletRequest
真正的事件指的是创建或销毁 ServletRequest 对象的操作
监听域对象属性变化的监听器
ServletContextAttributeListener:用于监听 ServletContext 应用域中属性的变化
核心方法
返回值
方法名
作用
void
attributeAdded(ServletContextAttributeEvent scae)
域中添加属性时执行该方法
void
attributeRemoved(ServletContextAttributeEvent scae)
域中移除属性时执行该方法
void
attributeReplaced(ServletContextAttributeEvent scae)
域中替换属性时执行该方法
参数:ServletContextAttributeEvent 代表事件对象
事件对象中封装了事件源,也就是 ServletContext
真正的事件指的是添加、移除、替换应用域中属性的操作
HttpSessionAttributeListener:用于监听 HttpSession 会话域中属性的变化
核心方法
返回值
方法名
作用
void
attributeAdded(HttpSessionBindingEvent se)
域中添加属性时执行该方法
void
attributeRemoved(HttpSessionBindingEvent se)
域中移除属性时执行该方法
void
attributeReplaced(HttpSessionBindingEvent se)
域中替换属性时执行该方法
参数:HttpSessionBindingEvent 代表事件对象
事件对象中封装了事件源,也就是 HttpSession
真正的事件指的是添加、移除、替换会话域中属性的操作
ServletRequestAttributeListener:用于监听 ServletRequest 请求域中属性的变化
核心方法
返回值
方法名
作用
void
attributeAdded(ServletRequestAttributeEvent srae)
域中添加属性时执行该方法
void
attributeRemoved(ServletRequestAttributeEvent srae)
域中移除属性时执行该方法
void
attributeReplaced(ServletRequestAttributeEvent srae)
域中替换属性时执行该方法
参数:ServletRequestAttributeEvent 代表事件对象
事件对象中封装了事件源,也就是 ServletRequest
真正的事件指的是添加、移除、替换请求域中属性的操作
监听会话相关的感知型监听器
感知型监听器:在定义好之后就可以直接使用,不需要再通过注解或xml文件进行配置
HttpSessionBindingListener:用于感知对象和会话域绑定的监听器
核心方法
返回值
方法名
作用
void
valueBound(HttpSessionBindingEvent event)
数据添加到会话域中(绑定)时执行该方法
void
valueUnbound(HttpSessionBindingEvent event)
数据从会话域中移除(解绑)时执行该方法
参数:HttpSessionBindingEvent 代表事件对象
事件对象中封装了事件源,也就是 HttpSession
真正的事件指的是添加、移除会话域中数据的操作
HttpSessionActivationListener:用于感知会话域对象钝化和活化的监听器
核心方法
返回值
方法名
作用
void
sessionWillPassivate(HttpSessionEvent se)
会话域中数据钝化时执行该方法
void
sessionDidActivate(HttpSessionEvent se)
会话域中数据活化时执行该方法
参数:HttpSessionEvent 代表事件对象
事件对象中封装了事件源,也就是 HttpSession
真正的事件指的是会话域中数据钝化、活化的操作
监听器的使用
-
监听对象的
ServletContextListener
HttpSessionListener
ServletRequestListenerpackage study.servlet.listener;
import javax.servlet.ServletContext;
import javax.servlet.ServletContextEvent;
import javax.servlet.ServletContextListener;
import javax.servlet.annotation.WebListener;
import javax.servlet.annotation.WebServlet;@WebServlet(“/listener01”)
@WebListener
public class listener01 implements ServletContextListener {
@Override
public void contextInitialized(ServletContextEvent servletContextEvent) {
System.out.println(“监听到了对象的创建”);
ServletContext servletContext = servletContextEvent.getServletContext();
// 添加属性
servletContext.setAttribute(“username”,“张三”);
// 替换属性
servletContext.setAttribute(“username”,“李四”);
// 移除属性
servletContext.removeAttribute(“username”);} @Override public void contextDestroyed(ServletContextEvent servletContextEvent) { System.out.println("监听到了对象的销毁"); }}
-
监听属性变化的
ServletContextAttributeListener
HttpSessionAttributeListener
ServletRequestAttributeListenerpackage study.servlet.listener;
import javax.servlet.*;
import javax.servlet.annotation.WebServlet;@WebServlet(“/listener02”)
public class listener02 implements ServletContextAttributeListener {
@Override
public void attributeAdded(ServletContextAttributeEvent servletContextAttributeEvent) {
System.out.println(“监听到了属性的添加”);
ServletContext servletContext = servletContextAttributeEvent.getServletContext();
Object username = servletContext.getAttribute(“username”);
System.out.println(username);
}@Override public void attributeRemoved(ServletContextAttributeEvent servletContextAttributeEvent) { System.out.println("监听到了属性的移除"); ServletContext servletContext = servletContextAttributeEvent.getServletContext(); Object username = servletContext.getAttribute("username"); System.out.println(username); } @Override public void attributeReplaced(ServletContextAttributeEvent servletContextAttributeEvent) { System.out.println("监听到了属性的替换"); ServletContext servletContext = servletContextAttributeEvent.getServletContext(); Object username = servletContext.getAttribute("username"); System.out.println(username); }}
-
会话相关的感知型
HttpSessionBindingListener
HttpSessionActivationListener
配置监听器
-
注解方式:
@WebListener -
xml文档方式
监听器对象实现类的全路径
学生管理系统优化
解决乱码
使用过滤器实现所有资源的编码统一
-
将请求和响应对象转换为和HTTP相关的HttpServletRequest和HttpServletResponse
-
设置编码格式
-
放行
package studentSystem.filter;
import javax.servlet.;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
@WebFilter("/")
public class EncodingFilter implements Filter {
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
// 将请求和响应对象转换为和HTTP相关的HttpServletRequest和HttpServletResponse
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
// 设置编码格式
request.setCharacterEncoding(“UTF-8”);
response.setContentType(“text/html;charset=UTF-8”);
// 放行
filterChain.doFilter(request, response);
}
}
检查登录
使用过滤器解决登录检查
- 将请求和响应对象转换为和HTTP相关的HttpServletRequest和HttpServletResponse
- 获取会话域对象中的数据
- 判断用户名
- 重定向(或定时刷新)到登录页面或放行
注解配置过滤器时指定多个拦截路径
@WebFilter(value = {"/拦截路径一", "/拦截路径二", ...})
package studentSystem.filter;
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
import java.io.IOException;
@WebFilter(value = {"/add.jsp", "/list.jsp"})
public class LoginFilter implements Filter {
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
// 将请求和响应对象转换为和HTTP相关的HttpServletRequest和HttpServletResponse
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
// 获取会话域对象中的数据
HttpSession session = request.getSession();
Object username = session.getAttribute("username");
Object password = session.getAttribute("password");
// 判断用户名
if("admin".equals(username) && "abc123".equals(password)){
filterChain.doFilter(request, response);
}else{
// 输出提示信息并设置定时刷新到登录页面
response.getWriter().write("您还未登录,请登录后再试。(2s后为您跳转到登录页面)");
response.setHeader("Refresh","2:URL=/login.jsp");
}
}
}
优化JSP页面
通过EL表达式和JSTL替换之前的Java代码块和JSP表达式
完整代码:https://github.com/HelloCode66/StudentSystem
MYSQL
基本概念
数据库
- 用于存储和管理数据的仓库
- 英文单词为 DataBase。简称 DB
- 它的存储空间很大,可以存放百万条、千万条、上亿条数据
- 使用统一的方式操作数据库—SQL
Mysql
- MySQL是一个最流行的关系型数据库管理系统之一。由瑞典 MySQL AB公司开发,后被 Oracle 公司收购
- 关系型数据库是将数据保存在不同的数据表中,而不是将所有数据放在一个大仓库内,而且表与表之间还可以有关联关系。这样就提高了访问速度以及提高了灵活性
- MySQL 所使用的SQL语句是用于访问数据库最常用的标准化语言
- 免费(6版本之前)
安装
- 为了能够更好的体现真实开发环境,将MySQL 安装在 Linux 系统上,以此来模拟公司的数据库服务器
- 具体的安装步骤就不做说明了,网上很多
- 在Windows下使用SQLyog连接数据库,下载安装方法网上也很多
DDL
数据库、数据表、数据的关系

- MySQL服务器中可以创建多个数据库
- 每个数据库可以包含多张数据表
- 每个数据表中可以存储多条数据记录
- 客户端通过数据库管理系统来操作MySQL数据库
SQL的介绍
- SQL(Structured Query Language):结构化查询语言。其实就是定义了操作所有关系型数据库的一种规则
- 通用语法规则
SQL语句可以单行或者多行书写,以分号结尾
可使用空格和缩进来增强语句的可读性
MySQL 数据库的 SQL 语句不区分大小写,关键字建议使用大写
单行注释:--注释内容#注释内容(MySQL特有)
多行注释:/*注释内容*/ - SQL分类
DDL(Data Definition Language):数据定义语言。用来操作数据库、表、列等
DML(Data Manipulation Language):数据操作语言。用来对数据库中表的数据进行增删改
DQL(Data Query Language):数据查询语言。用来查询数据库中表的记录(数据)
DCL(Data Control Language):数据控制语言。用来定义数据库的访问权限和安全级别,以及创建用户
查询和创建数据库
-
查询所有数据库
SHOW DATABASES; -
查询数据库的创建语句
SHOW CREATE DATABASE 数据库名称; -
创建数据库
CREATE DATABASE 数据库名称; -
创建数据库(判断,如果不存在则创建)
CREATE DATABASE IF NOT EXISTS 数据库名称; -
创建数据库(指定字符集)
CREATE DATABASE 数据库名称 CHARACTER SET 字符集名称;– 查询所有数据库
SHOW DATABASES;– 查询数据库的创建语句
SHOW CREATE DATABASE mysql;– 创建数据库
CREATE DATABASE db1;– 创建数据库并判断,如果不存在则创建
CREATE DATABASE IF NOT EXISTS db2;– 创建数据库并指定字符集
CREATE DATABASE db3 CHARACTER SET utf8;– 查看数据库的字符集
SHOW CREATE DATABASE db3;– 练习:创建db4数据库、如果不存在则创建,并指定字符集为gbk
CREATE DATABASE IF NOT EXISTS db4 CHARACTER SET gbk;
– 查看编码验证
SHOW CREATE DATABASE db4;
修改、删除、使用数据库
-
修改数据库(修改字符集)
ALTER DATABASE 数据库名称 CHARACTER SET 字符集名称; -
删除数据库
DROP DATABASE 数据库名称; -
删除数据库(判断,如果存在则删除)
DROP DATABASE IF EXISTS 数据库名称; -
使用数据库
USE 数据库名称; -
查看当前使用的数据库
SELECT DATABASE();– 修改数据库(字符集)
ALTER DATABASE db4 CHARACTER SET utf8;
– 查看db4字符集
SHOW CREATE DATABASE db4;– 删除数据库
DROP DATABASE db1;– 删除数据库(判断,存在则删除)
DROP DATABASE IF EXISTS db2;– 使用数据库
USE db3;– 查看当前使用的数据库
SELECT DATABASE();
查询数据表
-
查询所有的数据表
SHOW TABLES; -
查询表结构
DESC 表名; -
查询表字符集
SHOW TABLE STATUS FROM 库名 LIKE '表名';– 使用mysql数据库
USE mysql;– 查询所有数据表
SHOW TABLES;– 查询表结构
DESC USER;– 查询表字符集
SHOW TABLE STATUS FROM mysql LIKE ‘user’;
创建数据表
-
创建数据表
CREATE TABLE 表名( 列名(字段) 数据类型 约束, 列名(字段) 数据类型 约束, ...... 列名(字段) 数据类型 约束 ); -
数据类型
int:整数类型
double:小数类型
date:日期类型。包含年月日,格式:yyyy-MM-dddatetime:日期类型。包含年月日时分秒,格式:yyyy-MM-dd HH:mm:ss
timestamp:时间戳类型。包含年月日时分秒,格式yyyy-MM-dd HH:mm:ss
如果不给该字段赋值、或赋值为null,则默认使用当前系统时间自动赋值
varchar(长度):字符串类型
…– 创建数据表
– 创建一个product 商品类(商品编号、商品名称、商品价格、商品库存、上架时间)
CREATE TABLE product (
id INT,
NAME VARCHAR(20),
price DOUBLE,
stock INT,
insert_time DATE
);
– 查看product 表详细结构
DESC product;
数据表的修改
-
修改表名
ALTER TABLE 表名 RENAME TO 新表名; -
修改表的字符集
ALTER TABLE 表名 CHARACTER SET 字符集名称; -
单独添加一列
ALTER TABLE 表名 ADD 列名 数据类型; -
修改某列的数据类型
ALTER TABLE 表名 MODIFY 列名 新数据类型; -
修改列名和数据类型
ALTER TABLE 表名 CHANGE 列名 新列名 新数据类型; -
删除某一列
ALTER TABLE 表名 DROP 列名– 修改表名
ALTER TABLE product RENAME TO product2;– 查看原字符集
SHOW TABLE STATUS FROM db3 LIKE ‘product2’;
– 修改表的字符集
ALTER TABLE product2 CHARACTER SET gbk;– 给product2添加一列color
ALTER TABLE product2 ADD color VARCHAR(10);– 将color数据类型修改为int
ALTER TABLE product2 MODIFY color INT;
– 查看表的详细结构
DESC product2;– 将color修改为address
ALTER TABLE product2 CHANGE color address VARCHAR(200);– 删除address列
ALTER TABLE product2 DROP address;
数据表的删除
-
删除数据表
DROP TABLE 表名; -
删除数据表(判断,如果存在则删除)
DROP TABLE IF EXISTS 表名;– 删除product2表
DROP TABLE product2;– 删除表并判断
DROP TABLE IF EXISTS product2;
DML
新增表数据
- 给指定列添加数据
INSERT INTO 表名(列名1,列名2,...)VALUES(值1,值2,...); - 给全部列添加数据
INSERT INTO 表名 VALUES(值1,值2,...); - 批量添加数据
INSERT INTO 表名(列名1,列名2,...)VALUES(值1,值2,...),(值1,值2,...),...;
INSERT INTO 表名 VALUES(值1,值2,...),(值1,值2,...),...;
列名和值的数量以及数据类型要对应,除了数字类型,其他数据类型的数据都需要加引号(单引双引都行,推荐单引)。
-- 向product表添加一条数据(给全部列添加数据)
INSERT INTO product (id, NAME, price, stock, insert_time) VALUES (1, '手机', 2999, 20, '2022-02-26');
INSERT INTO product VALUES (2, '电脑', 3999, 36, '2022-02-27');
-- 向product表中添加指定数据
INSERT INTO product (id, NAME, price) VALUES (3, '电视', 1999.99);
-- 批量添加数据
INSERT INTO product VALUES (4, '冰箱', 999.99, 42, '2022-02-26'), (5, '空调', 1999, 23, '2030-01-01');
修改和删除表数据
-
修改表中的数据
UPDATE 表名 SET 列名1=值1,列名2=值2,...[WHERE条件];
修改语句中必须加条件,如果不加条件,则会将所有数据都修改 -
删除表中的数据
DELETE FROM 表名 [WHERE 条件];
删除语句中必须加条件,如果不加条件,则会将所有数据都删除– 修改手机价格为3500
UPDATE product SET price=3500 WHERE NAME=‘手机’;– 修改电脑的价格为4800、库存为46
UPDATE product SET price=4800, stock=46 WHERE NAME=‘电脑’;– 删除product 表中的空调信息
DELETE FROM product WHERE NAME=‘空调’;
– 删除product 表中库存为10的商品信息
DELETE FROM product WHERE stock=10;
DQL
查询语法
SELECT
字段列表
FROM
表名列表
WHERE
条件列表
GROUP BY
分组字段
HAVING
分组后的过滤条件
ORDER BY
排序
LIMIT
分页
这些语句不一定全部出现,但要按照上面的顺序
查询全部
-
查询全部的表数据
SELECT * FROM 表名; -
查询指定字段的表数据
SELECT 列名1,列名2,... FROM 表名; -
去除重复查询
SELECT DISTINCT 列名1,列名2,... FROM 表名; -
计算列的值(四则运算)
SELECT 列名1 运算符(+ - * /) 列名2 FROM 表名;如果某一列为null,可以进行替换:
IFNULL (表达式1,表达式2)
表达式1:想替换的列
表达式2:想替换的值 -
起别名查询
SELECT 列名 AS 别名 FROM 表名;– 准备数据(创建数据库以及表)
CREATE DATABASE db1;
USE db1;
CREATE TABLE product(
id INT, – 商品编号
NAME VARCHAR(20), – 商品名称
price DOUBLE, – 商品价格
brand VARCHAR(10), – 商品品牌
stock INT, – 商品库存
insert_time DATE – 添加时间
);– 添加测试数据
INSERT INTO product VALUES
(1, ‘华为手机’, 5999, ‘华为’, 23, ‘2018-03-10’),
(2, ‘小米手机’, 1999, ‘小米’, 30, ‘2019-02-10’),
(3, ‘苹果手机’, 3999, ‘苹果’, 19, ‘2018-07-23’),
(4, ‘华为电脑’, 4999, ‘华为’, 14, ‘2020-10-27’),
(5, ‘小米电脑’, 5996, ‘小米’, 26, ‘2021-03-29’),
(6, ‘苹果电脑’, 10000, ‘苹果’, 15, ‘2022-02-26’),
(7, ‘联想电脑’, 6999, ‘联想’, NULL, ‘2023-03-14’);– 查询全部的表数据
SELECT * FROM product;– 查询指定字段的表数据(name、price、brand)
SELECT NAME, price, brand FROM product;– 查询品牌
SELECT brand FROM product;
– 查询品牌,去除重复
SELECT DISTINCT brand FROM product;– 查询商品名称和库存,库存数量在原有的基础上加10
SELECT NAME,stock+10 FROM product;
– 查询商品名称和库存,库存数量在原有的基础上加10,进行null值判断
SELECT NAME,IFNULL(stock,0)+10 FROM product;
– 查询商品名称和库存,库存数量在原有的基础上加10,进行null值判断,起别名为getSum
SELECT NAME,IFNULL(stock,0)+10 AS getSum FROM product;
SELECT NAME,IFNULL(stock,0)+10 getSum FROM product; – 起别名时AS可以省略(空格隔开)
条件查询
- 查询条件分类
符号
功能
>
大于
<
小于
>=
大于等于
<=
小于等于
=
等于
<> 或 !=
不等于
BETWEEN…AND…
在某个范围之内(都包含)
IN(…)
多选…
LIKE 占位符
模糊查询;占位符_表示单个任意字符,%表示多个
IS NULL
是NULL
IS NOT NULL
不是 NULL
AND 或 &&
并且
OR 或 ||
或者
NOT 或 !
非,不是
-
条件查询语法
SELECT 列名列表 FROM 表名 WHERE 条件;– 查询库存大于20的商品信息
SELECT * FROM product WHERE stock > 20;– 查询品牌为华为的商品信息
SELECT * FROM product WHERE brand = ‘华为’;– 查询金额在4000-6000之间的商品信息
SELECT * FROM product WHERE price > 4000 AND price < 6000;
SELECT * FROM product WHERE price BETWEEN 4000 AND 6000;– 查询库存为14、30、23的商品信息
SELECT * FROM product WHERE stock = 14 OR stock = 30 OR stock = 23;
SELECT * FROM product WHERE stock IN (14, 30, 23);– 查询库存为null的商品信息
SELECT * FROM product WHERE stock IS NULL;– 查询库存不为null的商品信息
SELECT * FROM product WHERE stock IS NOT NULL;– 查询名称以小米为开头的商品信息
SELECT * FROM product WHERE NAME LIKE ‘小米%’;– 查询名称第二个字是为的商品信息
SELECT * FROM product WHERE NAME LIKE ‘_为%’;– 查询名称为四个字符的商品信息
SELECT * FROM product WHERE NAME LIKE ‘____’;– 查询名称中包含电脑的商品信息
SELECT * FROM product WHERE NAME LIKE ‘%电脑%’;
聚合函数查询
-
聚合函数的介绍
将一列数据作为一个整体,进行纵向的计算 -
聚合函数分类
函数名
功能
COUNT(列名)
统计数量(一般选用不为null的列)
MAX(列名)
最大值
MIN(列名)
最小值
SUM(列名)
求和
AVG(列名)
平均值
-
聚合函数查询语法
SELECT 函数名(列名) FROM 表名 [WHERE 条件];– 计算product表中总记录条数
SELECT COUNT(*) FROM product;– 获取最高价格
SELECT MAX(price) FROM product;– 获取最低库存
SELECT MIN(stock) FROM product;– 获取总库存数量
SELECT SUM(stock) FROM product;– 获取品牌为苹果的总库存数量
SELECT SUM(stock) FROM product WHERE brand = ‘苹果’;– 获取品牌为小米的平均商品价格
SELECT AVG(price) FROM product WHERE brand = ‘小米’;
排序查询
-
排序查询语法
SELECT 列名列表 FROM 表名 [WHERE 条件] ORDER BY 列名 排序方式, 列名 排序方式, ...; -
排序方式
ASC升序【默认】
DESC降序
如果有多个排序条件,只有当前面的条件值一样时,才会判断第二条件– 按照库存升序排序
SELECT * FROM product ORDER BY stock ASC;– 查询名称中包含手机的商品信息,按照金额降序排序
SELECT * FROM product WHERE NAME LIKE ‘%手机%’ ORDER BY price DESC;– 按照金额升序排序,如果金额相同,按照库存降序排列
SELECT * FROM product ORDER BY price ASC, stock DESC;
分组查询
-
分组查询语法
SELECT 列名列表 FROM 表名 [WHERE 条件] GROUP BY 分组列名 [HAVING 分组后的条件过滤] [ORDER BY 排序列名 排序方式]– 按照品牌分组,获取每组商品的总金额
SELECT brand, SUM(price) FROM product GROUP BY brand;– 对金额大于4000元的商品,按照品牌分组,获取每组商品的总金额
SELECT brand,SUM(price) FROM product WHERE price > 4000 GROUP BY brand;– 对金额大于4000元的商品,按照品牌分组,获取每组商品的总金额,只显示总金额大于7000元的
SELECT brand,SUM(price) AS getsum FROM product WHERE price > 4000 GROUP BY brand HAVING getsum > 7000;– 对金额大于4000元的商品,按照品牌分组,获取每组商品的总金额,只显示总金额大于7000元的,并按照总金额的降序进行排序
SELECT brand,SUM(price) AS getsum FROM product
WHERE price > 4000
GROUP BY brand
HAVING getsum > 7000
ORDER BY getsum DESC;
分页查询
-
分页查询语法
SELECT 列名列表 FROM 表名 [WHERE 条件] [GROUP BY 分组列名] [HAVING 分组后的条件过滤] [ORDER BY 排序列名 排序方式] LIMIT 当前页数,每页显示的条数;当前页数 = (当前页数 - 1) * 每页显示的条数
每页显示3条数据
– 第一页 当前页数 = (1 - 1) * 3
SELECT * FROM product LIMIT 0, 3;– 第二页 当前页数 = (2 - 1) * 3
SELECT * FROM product LIMIT 3, 3;– 第三页 当前页数 = (3 - 1) * 3
SELECT * FROM product LIMIT 6, 3;
LIMIT后的两个参数可以理解为:从几号索引开始,一页显示几个
故第一页:从0索引开始,显示3个(0,1,2)
第二页:从3索引开始,显示3个(3,4,5)
第三页:从6索引开始,显示3个(6,7,8)
…
约束
-
什么是约束
对表中的数据进行限定,保证数据的正确性、有效性、完整性 -
约束的分类
约束
作用
PRIMARY KEY
主键约束
PRIMARY KEY AUTO_INCREMENT
主键自增
UNIQUE
唯一约束
NOT NULL
非空约束
FOREIGN KEY
外键约束
FOREIGN KEY ON UPDATE CASCADE
外键级联更新
FOREIGN KEY ON DELETE CASCADE
外键级联删除
主键约束
-
特点
主键约束默认包含非空和唯一两个功能
一张表只能有一个主键
主键一般用于表中数据的唯一标识 -
建表时添加主键约束
CREATE TABLE 表名( 列名 数据类型 PRIMARY KEY, ... 列名 数据类型 约束 ); -
删除主键约束
ALTER TABLE 表名 DROP PRIMARY KEY; -
建表以后单独添加主键
ALTER TABLE 表名 MODIFY 列名 数据类型 PRIMARY KEY;– 创建学生表(编号、姓名、年龄) 编号为主键
CREATE TABLE students(
id INT PRIMARY KEY,
NAME VARCHAR(20),
age INT
);– 查询学生表的详细信息
DESC students;– 添加数据
INSERT INTO students VALUES(NULL, ‘张三’, 23); – 添加失败,主键不能为空
INSERT INTO students VALUES(1, ‘张三’, 23);
INSERT INTO students VALUES(1, ‘李四’, 24); – 添加失败,主键唯一
INSERT INTO students VALUES(2, ‘李四’, 24);– 删除主键
ALTER TABLE students DROP PRIMARY KEY;– 建表后单独添加主键约束
ALTER TABLE students MODIFY id INT PRIMARY KEY;
主键自增约束
-
建表时添加主键自增约束
CREATE TABLE 表名( 列名 数据类型 PRIMARY KEY AUTO_INCREMENT, ... 列名 数据类型 约束 );添加自增约束之后,主键内容就可以写null,会自动进行加一操作
-
删除主键自增约束
ALTER TABLE 表名 MODIFY 列名 数据类型; -
建表后单独添加主键自增约束
ALTER TABLE 表名 MODIFY 列名 数据类型 AUTO_INCREMENT;
MySQL中的自增约束,必须配合主键的约束一起来使用!
-- 创建学生表(编号、姓名、年龄) 编号设为主键自增
CREATE TABLE students(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20),
age INT
);
-- 查询学生表的详细信息
DESC students;
-- 添加数据
INSERT INTO students VALUES(NULL, '张三',23);
INSERT INTO students VALUES(NULL, '李四',24);
-- 删除自增约束
ALTER TABLE students MODIFY id INT; -- 只删除自增约束,不会删除主键约束
-- 建表后单独添加自增约束
ALTER TABLE students MODIFY id INT AUTO_INCREMENT;
唯一约束
-
建表时添加唯一约束
CREATE TABLE 表名( 列名 数据类型 UNIQUE, ... 列名 数据类型 约束 ); -
删除唯一约束
ALTER TABLE 表名 DROP INDEX 列名; -
建表后单独添加唯一约束
ALTER TABLE 表名 MODIFY 列名 数据类型 UNIQUE;– 创建学生表(编号、姓名、年龄) 编号设为主键自增,年龄设为唯一
CREATE TABLE student(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20),
age INT UNIQUE
);
– 查询学生表的详细信息
DESC student;– 添加数据
INSERT INTO student VALUES (NULL, ‘张三’, 23);
INSERT INTO student VALUES (NULL, ‘李四’, 23);– 删除唯一约束
ALTER TABLE student DROP INDEX age;– 建表后单独添加唯一约束
ALTER TABLE student MODIFY age INT UNIQUE;
非空约束
-
建表时添加非空约束
CREATE TABLE 表名( 列名 数据类型 NOT NULL, ... 列名 数据类型 约束 ); -
删除非空约束
ALTER TABLE 表名 MODIFY 列名 数据类型; -
建表后单独添加非空约束
ALTER TABLE 表名 MODIFY 列名 数据类型 NOT NULL;– 创建学生表(编号、姓名、年龄) 编号设为主键自增,姓名设为非空,年龄设为唯一
CREATE TABLE student(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20) NOT NULL,
age INT UNIQUE
);– 查询学生表的详细信息
DESC student;– 添加数据
INSERT INTO student VALUES (NULL, ‘张三’, 23);– 删除非空约束
ALTER TABLE student MODIFY NAME VARCHAR(20);– 添加非空约束
ALTER TABLE student MODIFY NAME VARCHAR(20) NOT NULL;
外键约束
-
为什么要有外键约束?
当表与表之间的数据有相关联性的时候,如果没有相关的数据约束,则无法保证数据的准确性!
比如用户和订单,表与表之间也有关联 -
外键约束的作用
让表与表之间产生关联关系,从而保证数据的准确性! -
建表时添加外键约束
CREATE TABLE 表名{ 列名 数据类型 约束, ... CONSTRAINT 外键名 FOREIGN KEY (本表外键列名) REFERENCES 主表名(主表主键列名) }; -
删除外键约束
ALTER TABLE 表名 DROP FOREIGN KEY 外键名; -
建表后单独添加外键约束
ALTER TABLE 表名 ADD CONSTRAINT 外键名 FOREIGN KEY (本表外键列名) REFERENCES 主表名(主键列名);外键名一般取两个表的首字母_fk编号
例如:ou_fk1– 建表时添加外键约束
– 创建user表
CREATE TABLE USER(
id INT PRIMARY KEY AUTO_INCREMENT, – id
NAME VARCHAR(20) NOT NULL – 姓名
);
– 添加用户数据
INSERT INTO USER VALUES (NULL,‘张三’),(NULL, ‘李四’);– 创建orderlist订单表
CREATE TABLE orderlist(
id INT PRIMARY KEY AUTO_INCREMENT, – id
number VARCHAR(20) NOT NULL, – 订单编号
uid INT, – 外键列
CONSTRAINT ou_fk1 FOREIGN KEY (uid) REFERENCES USER(id)
);– 添加订单数据
INSERT INTO orderlist VALUES (NULL, ‘001’, 1),(NULL, ‘002’, 1),
(NULL, ‘003’, 2),(NULL, ‘004’, 2);– 添加一个订单,但是没有真实用户,添加失败
INSERT INTO orderlist VALUES (NULL, ‘005’, 3);– 删除李四用户,删除失败
DELETE FROM USER WHERE NAME=‘李四’;– 删除外键约束
ALTER TABLE orderlist DROP FOREIGN KEY ou_fk1;– 添加外键约束
ALTER TABLE orderlist ADD CONSTRAINT ou_fk1 FOREIGN KEY (uid) REFERENCES USER(id);
外键级联操作(了解)
- 什么是级联更新
当对主表中的数据进行修改时,从表中有关联的数据也会随之修改 - 什么是级联删除
当主表中的数据删除时,从表中的数据也会随之删除
级联操作在真实开发中很少使用,因为它耦合性太强,牵一发动全身
-
添加级联更新
ALTER TABLE 表名 ADD CONSTRAINT 外键名 FOREIGN KEY (本表外键列名) REFERENCES 主表名(主键列名) ON UPDATE CASCADE; -
添加级联删除
ALTER TABLE 表名 ADD CONSTRAINT 外键名 FOREIGN KEY (本表外键列名) REFERENCES 主表名(主键列名) ON DELETE CASCADE; -
同时添加级联更新和级联删除
ALTER TABLE 表名 ADD CONSTRAINT 外键名 FOREIGN KEY (本表外键列名) REFERENCES 主表名(主键列名) ON UPDATE CASCADE ON DELETE CASCADE;– 添加外键约束,同时添加级联更新和级联删除
ALTER TABLE orderlist ADD
CONSTRAINT ou_fk1 FOREIGN KEY (uid) REFERENCES USER(id)
ON UPDATE CASCADE ON DELETE CASCADE;– 将李四这个用户id修改为3,订单表中的uid也自动修改
UPDATE USER SET id=3 WHERE NAME=‘李四’;– 将李四这个用户删除,订单表中的该用户所属的订单也自动修改
DELETE FROM USER WHERE id=3;
多表操作
- 多表概念
通俗的讲就是多张数据表,而表与表之间是可以有一定的关联关系,这种关联关系通过外键约束实现。 - 多表的分类
一对一
一对多
多对多
一对一
-
适用场景
例如人和身份证。一个人只有一个身份证,一个身份证只能对应一个人 -
建表原则
在任意一个表建立外键,去关联另外一个表的主键– 创建db5数据库
CREATE DATABASE db5;– 使用db5数据库
USE db5;– 创建person表
CREATE TABLE person(
id INT PRIMARY KEY AUTO_INCREMENT, – 主键id
NAME VARCHAR(20) – 姓名
);– 添加数据
INSERT INTO person VALUES (NULL, ‘张三’), (NULL, ‘李四’);– 创建card表
CREATE TABLE card(
id INT PRIMARY KEY AUTO_INCREMENT, – 主键id
number VARCHAR(20) UNIQUE NOT NULL, – 身份证号
pid INT UNIQUE, – 外键列
CONSTRAINT cp_fk1 FOREIGN KEY (pid) REFERENCES person(id)
);– 添加数据
INSERT INTO card VALUES (NULL, ‘12345’, 1), (NULL, ‘56789’, 2);
一对多
-
适用场景
用户和订单。一个用户可以有多个订单
商品分类和商品。一个分类下可以有多个商品 -
建表原则
在多的一方,建立外键约束,来关联一的一方主键– 创建user表
CREATE TABLE USER(
id INT PRIMARY KEY AUTO_INCREMENT, – 主键id
NAME VARCHAR(20) – 姓名
);– 添加数据
INSERT INTO USER VALUES (NULL, ‘张三’), (NULL, ‘李四’);– 创建orderlist表
CREATE TABLE orderlist(
id INT PRIMARY KEY AUTO_INCREMENT, – 主键id
number VARCHAR(20), – 订单编号
uid INT, – 外键链
CONSTRAINT ou_fk1 FOREIGN KEY (uid) REFERENCES USER(id)
);– 添加数据
INSERT INTO orderlist VALUES (NULL, ‘001’, 1), (NULL, ‘002’, 1), (NULL, ‘003’, 2), (NULL, ‘004’, 2);
多对多
-
适用场景
学生和课程。一个学生可以选择多个课程,一个课程也可以被多个学生选择 -
建表原则
需要借助第三张中间表,中间表至少包含两个列。这两个列作为中间表的外键,分别关联两张表的主键– 创建student表
CREATE TABLE student(
id INT PRIMARY KEY AUTO_INCREMENT, – 主键id
NAME VARCHAR(20) – 姓名
);– 添加数据
INSERT INTO student VALUES (NULL, ‘张三’), (NULL, ‘李四’);– 创建course表
CREATE TABLE course(
id INT PRIMARY KEY AUTO_INCREMENT, – 主键id
NAME VARCHAR(10) – 课程名称
);– 添加数据
INSERT INTO course VALUES (NULL, ‘高数’), (NULL, ‘线代’);– 创建中间表
CREATE TABLE stu_course(
id INT PRIMARY KEY AUTO_INCREMENT, – 主键id
sid INT, – 用于和student表中的id进行外键关联
cid INT, – 用于和course表中的id进行外键关联
CONSTRAINT sc_fk1 FOREIGN KEY (sid) REFERENCES student(id), – 添加外键约束
CONSTRAINT sc_fk2 FOREIGN KEY (cid) REFERENCES course(id) – 添加外键约束
);– 添加数据
INSERT INTO stu_course VALUES (NULL, 1, 1), (NULL, 1, 2), (NULL, 2, 1), (NULL, 2, 2);
多表查询
多表查询分类
-
内连接查询
-
外连接查询
-
子查询
-
自关联查询
数据准备
-- 创建db4数据库
CREATE DATABASE db4;
-- 使用db4数据库
USE db4;
-- 创建user表
CREATE TABLE USER(
id INT PRIMARY KEY AUTO_INCREMENT, -- 用户id
NAME VARCHAR(20), -- 用户姓名
age INT -- 用户年龄
);
-- 添加数据
INSERT INTO USER VALUES (1, '张三', 23), (2, '李四', 24), (3, '王五', 25), (4, '赵六', 26);
-- 订单表
CREATE TABLE orderlist(
id INT PRIMARY KEY AUTO_INCREMENT, -- 订单id
number VARCHAR(30), -- 订单编号
uid INT, -- 外键字段
CONSTRAINT ou_fk1 FOREIGN KEY (uid) REFERENCES USER(id)
);
-- 添加数据
INSERT INTO orderlist VALUES (1, '001', 1);
INSERT INTO orderlist VALUES (2, '002', 1);
INSERT INTO orderlist VALUES (3, '003', 2);
INSERT INTO orderlist VALUES (4, '004', 2);
INSERT INTO orderlist VALUES (5, '005', 3);
INSERT INTO orderlist VALUES (6, '006', 3);
INSERT INTO orderlist VALUES (7, '007', NULL);
-- 商品分类表
CREATE TABLE category(
id INT PRIMARY KEY AUTO_INCREMENT, -- 商品分类id
NAME VARCHAR(10) -- 商品分类名称
);
-- 添加数据
INSERT INTO category VALUES (1, '手机数码'), (2, '电脑办公'), (3, '烟酒茶糖'), (4, '鞋靴箱包');
-- 商品表
CREATE TABLE product(
id INT PRIMARY KEY AUTO_INCREMENT, -- 商品id
NAME VARCHAR(30), -- 商品名称
cid INT, -- 外键字段
CONSTRAINT cp_fk1 FOREIGN KEY (cid) REFERENCES category(id)
);
-- 添加数据
INSERT INTO product VALUES
(1, '华为手机', 1), (2, '小米手机', 1), (3, '联想电脑', 2),
(4, '苹果电脑', 2), (5, '中华香烟', 3), (6, '玉溪香烟', 3), (7, '计生用品', NULL);
-- 中间表
CREATE TABLE us_pro(
upid INT PRIMARY KEY AUTO_INCREMENT, -- 中间表id
uid INT, -- 外键字段,需要和用户表的主键产生关联
pid INT, -- 外键字段,需要和商品表的主键产生关联
CONSTRAINT up_fk1 FOREIGN KEY (uid) REFERENCES USER(id),
CONSTRAINT up_fk2 FOREIGN KEY (pid) REFERENCES product(id)
);
-- 添加数据
INSERT INTO us_pro VALUES
(NULL, 1, 1), (NULL, 1, 2), (NULL, 1, 3), (NULL, 1, 4),
(NULL, 1, 5), (NULL, 1, 6), (NULL, 1, 7), (NULL, 2, 1),
(NULL, 2, 2), (NULL, 2, 3), (NULL, 2, 4), (NULL, 2, 5),
(NULL, 2, 6), (NULL, 2, 7), (NULL, 3, 1), (NULL, 3, 2),
(NULL, 3, 3), (NULL, 3, 4), (NULL, 3, 5), (NULL, 3, 6),
(NULL, 3, 7), (NULL, 4, 1), (NULL, 4, 2), (NULL, 4, 3),
(NULL, 4, 4), (NULL, 4, 5), (NULL, 4, 6), (NULL, 4, 7);
内连接查询
-
查询原理
内连接查询的是两张表有交集的部分数据(有主外键关联的数据) -
查询语法
显示内连接:SELECT 列名 FROM 表名1 [INNER] JOIN 表名2 ON 条件;
隐式内连接:SELECT 列名 FROM 表名1,表名2 WHERE 条件;/*
显示内连接
*/– 查询用户信息和他对应的订单信息
SELECT * FROM USER INNER JOIN orderlist ON orderlist.uid = user.id;– 查询用户信息和对应的订单信息,起别名
SELECT * FROM USER u INNER JOIN orderlist o ON o.uid = u.id;– 查询用户姓名、年龄和订单号
SELECT
u.name, – 用户姓名
u.age, – 用户年龄
o.number – 订单编号
FROM
USER u – 用户表
INNER JOIN
orderlist o – 订单表
ON
o.uid = u.id;/*
隐式内连接
*/– 查询用户姓名,年龄,订单编号
SELECT
u.name, – 用户姓名
u.age, – 用户年龄
o.number – 订单编号
FROM
USER u,
orderlist o
WHERE
o.uid=u.id;
外连接查询
-
左外连接
- 查询原理
查询左表的全部数据,和左右两张表有交集部分的数据 - 查询语法
SELECT 列名 FROM 表名1 LEFT [OUTER] JOIN 表名2 ON 条件;
- 查询原理
-
右外连接
-
查询原理
查询右表的全部数据,和左右两张表有交集部分的数据 -
查询语法
SELECT 列名 FROM 表名1 RIGHT [OUTER] JOIN 表名2 ON 条件;– 查询所有用户信息,以及用户对应的订单信息
SELECT
u.*,
o.number
FROM
USER u
LEFT OUTER JOIN
orderlist o
ON
u.id=o.uid;– 所有订单信息,以及订单所属的用户信息
SELECT
o.*,
u.name
FROM
USER u
RIGHT OUTER JOIN
orderlist o
ON
u.id=o.uid;
-
子查询
-
概念
查询语句中嵌套了查询语句,我们就将嵌套的查询称为子查询 -
结果是单行单列的
- 查询作用
可以将查询的结果作为另一条语句的查询条件,使用运算符判断(=、>、>=、<、<=de等) - 查询语法
SELECT 列名 FROM 表名 WHERE 列名=(SELECT 列名 FROM 表名 [WHERE 条件]);
- 查询作用
-
结果是多行单列的
- 查询作用
可以作为条件,使用运算符 IN 或 NOT IN 进行判断 - 查询语法
SELECT 列名 FROM 表名 WHERE 列名 [NOT] IN (SELECT 列名 FROM 表名 [WHERE 条件]);
- 查询作用
-
结果是多行多列的
- 查询作用
查询的结果可以作为一张虚拟表参与查询 - 查询语法
SELECT 列名 FROM 表名 [别名], (SELECT 列名 FROM 表名 [WHERE 条件] [别名] [WHERE 条件]);
– 查询年龄最高的用户姓名
SELECT NAME,age FROM USER WHERE age=(SELECT MAX(age) FROM USER);– 查询张三和李四的订单信息
SELECT * FROM orderlist WHERE uid IN (SELECT id FROM USER WHERE NAME IN (‘张三’, ‘李四’));– 查询订单表中id大于4的订单信息和所属用户信息
SELECT
o.number,
u.name
FROM
USER u
INNER JOIN
(SELECT * FROM orderlist WHERE id > 4) o
ON
u.id=o.uid; - 查询作用
自关联查询
-
概念
在同一张表中数据有关联性,我们可以把这张表当成多个表来查询– 创建员工表
CREATE TABLE employee(
id INT PRIMARY KEY AUTO_INCREMENT, – 员工编号
NAME VARCHAR(20), – 员工姓名
mgr INT, – 上级编号
salary DOUBLE – 员工工资
);– 添加数据
INSERT INTO employee VALUES (1001, ‘孙悟空’, 1005, 9000.00),
(1002, ‘猪八戒’, 1005, 8000.00),
(1003, ‘沙和尚’, 1005, 8500.00),
(1004, ‘小白龙’, 1005, 7900.00),
(1005, ‘唐僧’, NULL, 15000.00),
(1006, ‘武松’, 1009, 7600.00),
(1007, ‘李逵’, 1009, 7400.00),
(1008, ‘林冲’, 1009, 8100.00),
(1009, ‘宋江’, NULL, 16000.00);– 查询所有员工的姓名及其直接上级的姓名,没有上级的员工也需要查询
SELECT
e1.id,
e1.name,
e1.mgr,
e2.id,
e2.name
FROM
employee e1
LEFT OUTER JOIN
employee e2
ON
e1.mgr=e2.id;
练习
- 查询用户的编号、姓名、年龄、订单编号
- 查询所有的用户。用户的编号、姓名、年龄、订单编号
- 查询所有的订单。用户的编号、姓名、年龄、订单编号
- 查询用户年龄大于23岁的信息。显示用户的编号、姓名、年龄、订单编号
- 查询张三和李四用户的信息。显示用户的编号、姓名、年龄、订单编号
- 查询商品分类的编号、分类名称、分类下的商品名称
- 查询所有的商品分类。商品分类的编号、分类名称、分类下的商品名称
- 查询所有的商品信息。商品分类的编号、分类名称、分类下的商品名称
- 查询所有的用户和所有的商品。显示用户的编号、姓名、年龄、商品名称
- 查询张三和李四这两个用户可以看到的商品。显示用户的编号、姓名、年龄、商品名称
-- 1.查询用户的编号、姓名、年龄、订单编号
SELECT
u.*,
o.number
FROM
USER AS u
INNER JOIN
orderlist AS o
ON
u.id=o.uid;
-- 2.查询所有的用户。用户的编号、姓名、年龄、订单编号
SELECT
u.*,
o.number
FROM
USER u
LEFT OUTER JOIN
orderlist o
ON
u.id=o.uid;
-- 3.查询所有的订单。用户的编号、姓名、年龄、订单编号
SELECT
u.*,
o.number
FROM
USER u
RIGHT OUTER JOIN
orderlist o
ON
u.id=o.uid;
-- 4.查询用户年龄大于23岁的信息。显示用户的编号、姓名、年龄、订单编号
# 方式1
SELECT
u.*,
o.number
FROM
(SELECT * FROM USER WHERE age>23) u,
orderlist o
WHERE
u.id=o.uid;
# 方式2
SELECT
u.*,
o.number
FROM
USER u,
orderlist o
WHERE
u.id=o.uid
AND
u.age > 23;
-- 5.查询张三和李四用户的信息。显示用户的编号、姓名、年龄、订单编号
# 方式1
SELECT
u.*,
o.number
FROM
(SELECT * FROM USER WHERE NAME IN ('张三', '李四')) u,
orderlist o
WHERE
u.id=o.uid;
# 方式2
SELECT
u.*,
o.number
FROM
USER u,
orderlist o
WHERE
u.id=o.uid
AND
u.name IN ('张三', '李四');
-- 6.查询商品分类的编号、分类名称、分类下的商品名称
# 方式1
SELECT
c.id,
c.name,
p.name
FROM
category c
INNER JOIN
product p
ON
c.id=p.cid;
# 方式2
SELECT
c.*,
p.name
FROM
category c,
product p
WHERE
c.id=p.cid;
-- 7.查询所有的商品分类。商品分类的编号、分类名称、分类下的商品名称
SELECT
c.*,
p.name
FROM
category c
LEFT OUTER JOIN
product p
ON
c.id=p.cid;
-- 8.查询所有的商品信息。商品分类的编号、分类名称、分类下的商品名称
SELECT
c.*,
p.name
FROM
category c
RIGHT OUTER JOIN
product p
ON
c.id=p.cid;
-- 9.查询所有的用户和所有的商品。显示用户的编号、姓名、年龄、商品名称
SELECT
u.*,
p.name
FROM
USER u,
product p,
us_pro up
WHERE
up.uid=u.id
AND
up.pid=p.id;
-- 10.查询张三和李四这两个用户可以看到的商品。显示用户的编号、姓名、年龄、商品名称
SELECT
u.id,
u.name,
u.age,
p.name
FROM
(SELECT * FROM USER WHERE NAME IN ('张三', '李四')) u,
product p,
us_pro up
WHERE
up.uid=u.id
AND
up.pid=p.id;
视图
- 视图:是一种虚拟存在的数据表,这个数据表并不在数据库中实际存在
- 作用:将一些较为复杂的查询语句的结果,封装到一个虚拟表中,后期再有相同需求时,直接查询该虚拟表即可
数据准备
-- 创建db5数据库
CREATE DATABASE db5;
-- 使用db5数据库
USE db5;
-- 创建country表
CREATE TABLE country(
id INT PRIMARY KEY AUTO_INCREMENT, -- 国家id
NAME VARCHAR(30) -- 国家名称
);
-- 添加数据
INSERT INTO country VALUES (NULL, '中国'), (NULL, '美国'), (NULL, '俄罗斯');
-- 创建city表
CREATE TABLE city(
id INT PRIMARY KEY AUTO_INCREMENT, -- 城市id
NAME VARCHAR(30), -- 城市名称
cid INT, -- 外键列
CONSTRAINT cc_fk1 FOREIGN KEY (cid) REFERENCES country(id) -- 添加外键约束
);
-- 添加数据
INSERT INTO city VALUES (NULL, '北京', 1), (NULL, '上海', 1), (NULL, '纽约', 2), (NULL, '莫斯科', 3);
创建和查询
-
创建视图语法
CREATE VIEW 视图名称 [(列表列名)] AS 查询语句; -
查询视图语法
SELECT * FROM 视图名称;– 创建city_country视图,保存城市和国家的信息(使用指定列名)
CREATE VIEW city_country (city_id, city_name, country_name) AS
SELECT
c1.id,
c1.name,
c2.name
FROM
city c1,
country c2
WHERE
c1.cid=c2.id;– 查询视图
SELECT * FROM city_country;
修改和删除
-
修改视图数据语法
UPDATE 视图名称 SET 列名=值 WHERE 条件; -
修改视图结构语法
ALTER VIEW 视图名称 (列名列表) AS 查询语句; -
删除视图语法
DROP VIEW [IF EXISTS] 视图名称;
注意:修改视图数据后,原表数据也会随之修改
SELECT * FROM city_country;
-- 修改视图数据,将北京修改为深圳
UPDATE city_country SET city_name='深圳' WHERE city_name='北京';
-- 将视图中的country_name修改为name
ALTER VIEW city_country (city_id, city_name, NAME) AS
SELECT
c1.id,
c1.name,
c2.name
FROM
city c1,
country c2
WHERE
c1.cid=c2.id;
-- 删除视图
DROP VIEW IF EXISTS city_country;
数据库备份和恢复
命令行方式
-
备份
登录到MySQL服务器,输入:mysqldump -u root -p 数据库名称 > 文件保存路径mysqldump -u root -p db5 > /root/db5.sql -
恢复
- 登录MySQL数据库:
mysql -u root -p - 删除已备份的数据库:
DROP DATABASE db5; - 重新创建名称相同的数据库:
CREATE DATABASE db5; - 使用该数据库:
USE db5; - 导入文件执行:
source 备份文件全路径;
- 登录MySQL数据库:
所谓的备份,就是将一些sql语句存储起来,恢复就是执行这些sql语句,重新创建数据库中的内容
图形化界面方式
这个方法比较简单,选中需要操作的数据库右键选择备份即可
恢复的时候删除原数据库再重新创建,然后选中新建的这个数据库,右键导入即可
存储过程和函数
- 存储过程和函数是事先经过编译并存储在数据库中的一段SQL语句的集合
- 存储过程和函数的好处
- 提高代码的复用性
- 减少数据在数据库和应用服务器之间的传输,提高效率
- 减少代码层面的业务处理
- 存储过程和函数的区别
- 存储函数必须有返回值
- 存储过程可以没有返回值
创建和调用
-
创建存储过程
-- 修改结束分隔符 DELIMITER $ -- 创建存储过程 CREATE PROCEDURE 存储过程名称(参数列表) BEGIN SQL 语句列表; END$ -- 修改结束分隔符 DELIMITER; -
调用存储过程
CALL 存储过程名称(实际参数);– 数据准备
– 创建db6数据库
CREATE DATABASE db6;– 使用db6数据库
USE db6;– 创建学生表
CREATE TABLE student(
id INT PRIMARY KEY AUTO_INCREMENT, – 学生id
NAME VARCHAR(20), – 学生姓名
age INT, – 学生年龄
gender VARCHAR(5), – 学生性别
score INT – 学生成绩
);– 添加数据
INSERT INTO student VALUES (NULL, ‘张三’, 23, ‘男’, 95), (NULL, ‘李四’, 24, ‘男’, 98),
(NULL, ‘王五’, 25, ‘女’, 100), (NULL, ‘赵六’, 26, ‘女’, 90);– 按照性别进行分组,查询每组学生的总成绩。按照总成绩的升序排序
SELECT gender,SUM(score) getsum FROM student GROUP BY gender ORDER BY getsum ASC;– 创建stu_group() 存储过程,封装 分组查询总成绩,并按照总成绩升序排序的功能
DELIMITER $CREATE PROCEDURE stu_group()
BEGIN
SELECT gender,SUM(score) getsum FROM student GROUP BY gender ORDER BY getsum ASC;
END$DELIMITER ;
– 调用存储过程
CALL stu_group;
查看和删除
-
查看数据库中所有的存储过程
SELECT * FROM mysql.proc WHERE db='数据库名称'; -
删除存储过程
DROP PROCEDURE [IF EXISTS] 存储过程名称;– 查看db6数据库中所有的存储过程
SELECT * FROM mysql.proc WHERE db=‘db6’;– 删除存储过程
DROP PROCEDURE IF EXISTS stu_group;
变量
-
定义变量
DECLARE 变量名 数据类型 [DEFAULT 默认值]; -
变量赋值方式一
SET 变量名=变量值; -
变量赋值方式二
SELECT 列名 INTO 变量名 FROM 表名 [WHERE 条件];– 定义一个int类型变量,并赋默认值为10
DELIMITER $CREATE PROCEDURE pro_test1()
BEGIN
– 定义变量
DECLARE num INT DEFAULT 10;
– 使用变量
SELECT num;
END$DELIMITER ;
– 调用pro_test1存储过程
CALL pro_test1();/*
变量赋值
*/– 定义一个varchar类型变量并赋值
DELIMITER $CREATE PROCEDURE pro_test2()
BEGIN
– 定义变量
DECLARE NAME VARCHAR(10);
– 为变量赋值
SET NAME = ‘存储过程’;
– 使用变量
SELECT NAME;
END$DELIMITER ;
– 调用pro_test2存储过程
CALL pro_test2();– 定义两个int类型的变量,用于存储男女同学的总分数
DELIMITER $CREATE PROCEDURE pro_test3()
BEGIN
– 定义两个变量
DECLARE men,women INT;
– 为变量赋值
SELECT SUM(score) INTO men FROM student WHERE gender = ‘男’;
SELECT SUM(score) INTO women FROM student WHERE gender = ‘女’;
– 使用变量
SELECT men,women;
END$DELIMITER ;
– 调用pro_test3
CALL pro_test3();
if语句
-
if语句标准语法
IF 判断条件1 THEN 执行的sql语句1; [ELSEIF 判断条件2 THEN 执行的sql语句2;] ... [ELSE 执行的sql语句n;] END IF;/*
定义一个int类型的变量,用于存储班级总成绩
定义一个varchar变量,用于存储分数描述
根据总成绩判断:
380分以上 学习优秀
320~380 学习不错
320以下 学习一般
*/DELIMITER $
CREATE PROCEDURE pro_test4()
BEGIN
– 定义变量
DECLARE total INT;
DECLARE info VARCHAR(10);
– 查询班级总成绩为total赋值
SELECT SUM(score) INTO total FROM student;
– 判断
IF total >= 380 THEN
SET info = ‘学习优秀’;
ELSEIF total BETWEEN 320 AND 380 THEN
SET info = ‘学习不错’;
ELSE
SET info = ‘学习一般’;
END IF;
– 使用变量
SELECT total,info;
END$DELIMITER ;
– 调用pro_test4
CALL pro_test4();
参数传递
-
存储过程的参数和返回值
CREATE PROCEDURE 存储过程名称([IN][OUT][INOUT] 参数名 数据类型) BEGIN SQL语句列表; END$IN:代表输入参数,需要由调用者传递实际数据(默认)
OUT:代表输出参数,该参数可以作为返回值
INOUT:代表既可以作为输入参数,也可以作为输出参数/*
输入总成绩变量,代表学生总成绩
输出分数描述变量,代表学生总成绩的描述信息
根据总成绩判断
380分及以上 学习优秀
320~380 学习不错
320分及以下 学习一般
*/DELIMITER $
CREATE PROCEDURE pro_test5(IN total INT,OUT info VARCHAR(10))
BEGIN
– 对总成绩判断
IF total >= 380 THEN
SET info = ‘学习优秀’;
ELSEIF total BETWEEN 320 AND 380 THEN
SET info = ‘学习不错’;
ELSE
SET INFO = ‘学习一般’;
END IF;
END$DELIMITER ;
– 调用存储过程
CALL pro_test5(383, @info);CALL pro_test5((SELECT SUM(score) FROM student), @info);
SELECT @info;
while循环
-
while 循环语法
初始化语句; WHILE 条件判断语句 DO 循环体语句; 条件控制语句; END WHILE;– 计算1~100之间的偶数和
DELIMITER $
CREATE PROCEDURE pro_test6()
BEGIN
– 定义求和变量
DECLARE result INT DEFAULT 0;
– 定义初始化变量
DECLARE num INT DEFAULT 1;
– while 循环
WHILE num <= 100 DO
IF num % 2 = 0 THEN
SET result = result + num;
END IF;SET num = num + 1; END WHILE; -- 查询求和结果 SELECT result;END$
DELIMITER ;
– 调用存储过程
CALL pro_test6();
存储函数
-
存储函数和存储过程是非常相似的,区别在于存储函数必须有返回值
-
创建存储函数
CREATE FUNCTION 函数名称(参数列表) RETURNS 返回值类型 BEGIN SQL语句列表; RETURN 结果; END$ -
调用存储函数
SELECT 函数名称(实际参数); -
删除函数
DROP FUNCTION 函数名称;– 定义存储函数,获取学生表中成绩大于95分的学生数量
DELIMITER $CREATE FUNCTION fun_test()
RETURNS INT
BEGIN
– 定义变量
DECLARE s_count INT;
– 查询数量并赋值
SELECT COUNT(*) INTO s_count FROM student WHERE score > 95;
– 返回
RETURN s_count;
END$DELIMITER ;
– 调用函数
SELECT fun_test();– 删除函数
DROP FUNCTION fun_test;
触发器
-
触发器是与表有关的数据库对象,可以在insert、update、delete 之前或之后触发并执行触发器中定义的SQL语句
-
这种特性可以协助应用系统在数据库端确保数据的完整性、日志记录、数据校验等操作
-
可以使用别名
NEW或者OLD来引用触发器中发生变化的内容记录 -
触发器分类
触发器类型
OLD
NEW
INSERT 型触发器
无(因为插入前无数据)
NEW表示将要或者已经新增的数据
UPDATE 型触发器
OLD表示修改之前的数据
NEW表示将要或已经修改后的数据
DELETE 型触发器
OLD表示将要或者已经删除的数据
无(因为删除后状态无数据)
触发器的操作
-
创建触发器
DELIMITER $ CREATE TRIGGER 触发器名称 BEFORE|AFTER INSERT|UPDATE|DELETE ON 表名 FOR EACH ROW BEGIN 触发器要执行的功能 END$ DELIMITER ; -
数据准备
-- 创建db7数据库 CREATE DATABASE db7; -- 使用db7数据库 USE db7; -- 创建账户表account CREATE TABLE account( id INT PRIMARY KEY AUTO_INCREMENT, -- 账户id NAME VARCHAR(20), -- 姓名 money DOUBLE -- 余额 ); -- 添加数据 INSERT INTO account VALUES (NULL, '张三', 1000), (NULL, '李四', 1000); -- 创建日志表account_log CREATE TABLE account_log( id INT PRIMARY KEY AUTO_INCREMENT, -- 日志id operation VARCHAR(20), -- 操作类型 (insert update delete) operation_time DATETIME, -- 操作时间 operation_id INT, -- 操作表的id operation_param VARCHAR(200) -- 操作参数 ); -
INSERT 型触发器
-- 创建insert型触发器,用于对account表新增数据进行日志的记录 DELIMITER $ CREATE TRIGGER account_insert AFTER INSERT ON account FOR EACH ROW BEGIN INSERT INTO account_log VALUES (NULL, 'INSERT', NOW(), new.id, CONCAT('插入后{id=',new.id,',name=',new.name,',money=',new.money,'}')); END$ DELIMITER ; -- 向account表添加一条数据 INSERT INTO account VALUES (NULL, '王五', 2000); -- 查询account表 SELECT * FROM account; -- 查询account_log表 SELECT * FROM account_log; -
UPDATE 型触发器
-- 创建update型触发器,用于对account表修改数据进行日志记录 DELIMITER $ CREATE TRIGGER account_update AFTER UPDATE ON account FOR EACH ROW BEGIN INSERT INTO account_log VALUES (NULL, 'UPDATE', NOW(), new.id, CONCAT('更新前{id=',old.id,',name=',old.name,',money=',old.money,'}','更新后{id=',new.id,',name=',new.name,',money=',new.money,'}')); END$ DELIMITER ; -- 修改account表中李四的金额为2000 UPDATE account SET money = 2000 WHERE NAME = '李四'; -- 查询account表 SELECT * FROM account; -- 查询account_log表 SELECT * FROM account_log; -
DELETE 型触发器
-- 创建delete型触发器,用于对account表删除的数据进行日志的记录 DELIMITER $ CREATE TRIGGER account_delete AFTER DELETE ON account FOR EACH ROW BEGIN INSERT INTO account_log VALUES (NULL, 'DELETE', NOW(), old.id, CONCAT('删除前{id=',old.id,',name=',old.name,',money=',old.money,'}')); END$ DELIMITER ; -- 删除account表中王五 DELETE FROM account WHERE NAME = '王五'; -- 查询account表 SELECT * FROM account; -- 查询account_log表 SELECT * FROM account_log;
查看和删除
-
查看触发器
SHOW TRIGGERS; -
删除触发器
DROP TRIGGER 触发器名称;– 查看触发器
SHOW TRIGGERS;– 删除account_delete触发器
DROP TRIGGER account_delete;
事务
事务:一条或多条SQL语句组成一个执行单元,其特点是这个单元要么同时成功要么同时失败
单元中的每条SQL语句都相互依赖,形成一个整体
如果某条SQL语句失败或者出现错误,那么这个单元就会撤回到事务最初的状态
如果单元中所有的SQL语句都执行成功,则事务就顺利执行
基本使用
-
开启事务
START TRANSACTION; -
回滚事务
ROLLBACK; -
提交事务
COMMIT;– 创建db8数据库
CREATE DATABASE db8;– 使用db8数据库
USE db8;– 创建账户表
CREATE TABLE account(
id INT PRIMARY KEY AUTO_INCREMENT, – 账户id
NAME VARCHAR(20), – 账户名称
money DOUBLE – 账户余额
);
– 添加数据
INSERT INTO account VALUES (NULL, ‘张三’, 1000), (NULL, ‘李四’, 1000);– 张三给李四转账500元
– 开启事务
START TRANSACTION;– 1. 张三账户-500
UPDATE account SET money = money - 500 WHERE NAME = ‘张三’;出错了…
– 2.李四账户+500
UPDATE account SET money = money + 500 WHERE NAME = ‘李四’;– 回滚事务
ROLLBACK;– 提交事务
COMMIT;
提交方式
-
事务提交方式
- 自动提交(MySQL默认)
- 手动提交
-
查看事务提交方式
SELECT @@AUTOCOMMIT;0代表手动提交
1代表自动提交 -
修改事务提交方式
SET @@AUTOCOMMIT = 数字;– 查询事务提交方式
SELECT @@autocommit;– 修改事务提交方式
SET @@autocommit = 0;UPDATE account SET money = 2000 WHERE id = 1; – 临时修改,并未提交
COMMIT;
四大特征(ACID)
- 原子性(Atomicty)
原子性指事物包含的所有操作要么全部成功,要么全部失败回滚
因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响 - 一致性(Consistency)
一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态
也就是说一个事务执行之前和执行之后都必须处于一致性状态 - 隔离性(Isolcation)
隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务
不能被其他事务的操作所干扰,多个并发事务之间要相互隔离 - 持久性(Durability)
持久性是指一个事务一旦提交了,那么对数据库中的数据的改变就是永久性的
即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作
隔离级别
-
事务的隔离级别
多个客户端操作时,各个客户端的事务之间应该是隔离的,相互独立的,不受影响的
而如果多个事务操作同一批数据时,就会产生不同的问题,我们需要设置不同的隔离级别来解决这些问题 -
隔离级别分类
隔离级别
名称
会引发的问题
read uncommitted
读未提交
脏读、不可重复读、幻读
read committed
读已提交
不可重复读、幻读
repeatable read
可重复读
幻读
serializable
串行化
无
-
引发的问题
问题
现象
脏读
在一个事务处理过程中读取到了另一个未提交事务中的数据,导致两次查询结果不一致
不可重复读
在一个事务处理过程中读取到了另一个事务中修改并已提交的数据,导致两次查询不一致
幻读
查询某数据不存在,准备插入此纪录,但执行插入时发现此纪录已存在,无法插入。或者查询数据不存在执行删除操作,却发现删除成功
-
查询数据库隔离级别
SELECT @@TX_ISOLATION; -
修改数据库隔离级别
SET GLOBAL TRANSACTION ISOLATION LEVEL 级别字符串;– 查询事务隔离级别
SELECT @@tx_isolation;– 修改事务隔离级别(修改后需要重新连接)
SET GLOBAL TRANSACTION ISOLATION LEVEL READ COMMITTED; -
总结
序号
隔离级别
名称
脏读
不可重复读
幻读
数据库默认隔离级别
1
read uncommitted
读未提交
是
是
是
2
read committed
读已提交
否
是
是
Oracle
3
repeatable read
可重复读
否
否
是
MySQL
4
serializable
串行化
否
否
否
注意 :隔离级别从小到大安全性越来越高,但是效率越来越低,所以不建议修改数据库默认的隔离级别
存储引擎
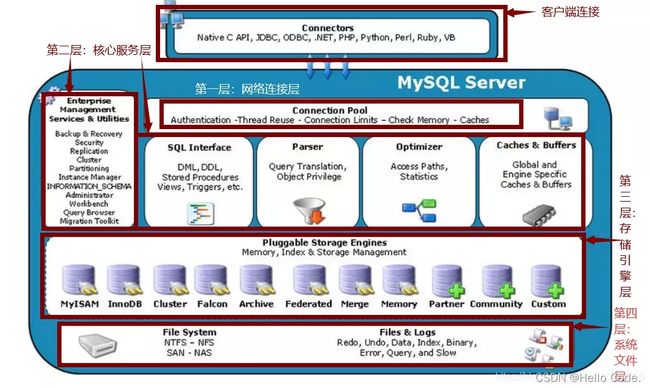
体系结构
- 客户端连接
支持接口:支持的客户端连接,例如:C、Java、PHP等语言来连接MySQL数据库 - 第一层:网络连接层
连接池:管理、缓冲用户的连接,线程处理等需要缓存的需求 - 第二层:核心服务层
- 管理服务和工具:系统的管理和控制工具,例如备份恢复、复制、集群等
- SQL接口:接受SQL命令,并且返回查询结果
- 查询解析器:验证和解析SQL命令,例如过滤条件、语法结构等
- 缓存:如果缓存当中有想查询的数据,则直接将缓存中的数据返回。没有的话重新查询
- 第三层:存储引擎层
插件式存储引擎:管理和操作数据的一种机制,包括(存储数据、如何更新、查询数据等) - 第四层:系统文件层
文件系统:配置文件、数据文件、日志文件、错误文件、二进制文件等等的保存
存储引擎
- 在生活中,引擎就是整个机器运行的核心(发动机),不同的引擎具备不同的功能,应用于不同的场景之中
- MySQL数据库使用不同的机制存取表文件,包括存储方式、索引技巧、锁定水平等不同的功能。这些不同的技术以及配套的功能称为存储索引
- Oracle、SQL server等数据库只有一种存储引擎。而MySQL针对不同的需求,配置不同的存储索引,就会让数据库采取不同处理数据的方式和扩展功能
- MySQL支持的存储引擎有很多,常用的有三种:InnoDB、MyISAM、MEMORY
- 特性对比
- MyISAM存储引擎:访问快,不支持事务和外键操作
- InnoDB存储引擎:支持事务和外键操作,支持并发控制,占用磁盘空间大(MySQL 5.5版本后默认)
- MEMORY存储引擎:内存存储,速度快,不安全。适合小量快速访问的数据
基本操作
-
查询数据库支持的存储引擎
SHOW ENGINES; -
查询某个数据库中所有数据表的存储引擎
SHOW TABLE STATUS FROM 数据库名称; -
查询某个数据库中某个数据表的存储索引
SHOW TABLE STATUS FROM 数据库名称 WHERE NAME = '数据表名称'; -
创建数据表,指定存储引擎
CREATE TABLE 表名( 列名 数据类型, ... )ENGINE = 引擎名称; -
修改数据表的存储引擎
ALTER TABLE 表名 ENGINE = 引擎名称;– 查询数据库支持的存储引擎
SHOW ENGINES;– 查询db4数据库所有表的存储引擎
SHOW TABLE STATUS FROM db4;– 查看db4数据库中category表的存储引擎
SHOW TABLE STATUS FROM db4 WHERE NAME = ‘category’;– 创建数据表并指定存储引擎
CREATE TABLE engine_test(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(10)
)ENGINE = MYISAM;SHOW TABLE STATUS FROM db4 WHERE NAME = ‘engine_test’;
– 修改数据表的存储引擎
ALTER TABLE engine_test ENGINE = INNODB;
存储引擎的选择
- MyISAM
- 特点:不支持事务和外键操作。读取速度快,节约资源
- 使用场景:以查询操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不是很高
- InnoDB
- 特点:MySQL的默认存储引擎,支持事务和外键操作
- 使用场景:对事务的完整性有比较高的要求,在并发条件下要求数据的一致性,读写频繁的操作
- MEMORY
- 特点:将所有数据保存在内存中,在需要快速定位记录和其他类似数据环境下,可以提供更快的访问
- 使用场景:通常用于更新不太频繁的小表,用来快速得到访问的结果
总结 :针对不同的需求场景,来选择最适合的存储引擎即可。如果不确定,则使用默认的存储引擎
索引
- MySQL索引:是帮助MySQL高效获取数据的一种数据结构。所以,索引的本质就是数据结构
- 在表数据之外,数据系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式指向数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引
分类
- 按照功能分类
- 普通索引:最基本的索引,没有任何限制
- 唯一索引:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值组合必须唯一
- 主键索引:一种特殊的唯一索引,不允许有空值。在建表时有主键列同时创建主键索引
- 联合索引:顾名思义,就是将单列索引进行组合
- 外键索引:只有InnoDB引擎支持外键索引,用来保证数据的一致性、完整性和实现级联操作
- 全文索引:快速匹配全部文档的方式。InnoDB引擎5.6版本后才支持全文索引。MEMORY引擎不支持
- 按照结构分类
- BTree索引:MySQL使用最频繁的一个索引数据结构,是InnoDB和MyISAM存储索引默认的索引类型,底层是基于B+Tree数据结构
- Hash索引:MySQL中Memory存储引擎默认支持的索引类型
创建和查询
-
创建索引
CREATE [UNIQUE | FULLTEXT] INDEX 索引名称 [USING 索引类型] -- 默认是BTREE ON 表名(列名...); -
查看索引
SHOW INDEX FROM 表名;– 创建db9数据库
CREATE DATABASE db9;– 使用db9数据库
USE db9;– 创建student表
CREATE TABLE student(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(10),
age INT,
score INT
);– 添加数据
INSERT INTO student VALUES (NULL, ‘张三’, 23, 98), (NULL, ‘李四’,24, 95),
(NULL, ‘王五’,25, 96), (NULL, ‘赵六’,26, 94), (NULL, ‘周七’,27, 99);– 为student表中的name列创建一个普通索引
CREATE INDEX idx_name ON student(NAME);– 为student表中的age列创建一个唯一索引
CREATE UNIQUE INDEX idx_age ON student(age);– 查询索引(主键列自带主键索引)
SHOW INDEX FROM student;– 查询db4中的product表(外键列自带外键索引)
SHOW INDEX FROM product;
添加和删除
-
添加索引
普通索引:ALTER TABLE 表名 ADD INDEX 索引名称(列名);
组合索引:ALTER TABLE 表名 ADD INDEX 索引名称(列名1,列名2,...);
主键索引:ALTER TABLE 表名 ADD PRIMARY KEY(主键列名);
外键索引:ALTER TABLE 表名 ADD CONSTRAINT 外键名 FOREIGN KEY (本表外键列名) REFERENCES 主表名(主键列名);
唯一索引:ALTER TABLE 表名 ADD UNIQUE 索引名称(列名);
全文索引:ALTER TABLE 表名 ADD FULLTEXT 索引名称(列名); -
删除索引
DROP INDEX 索引名称 ON 表名;– 为student表中score列添加唯一索引
ALTER TABLE student ADD UNIQUE idx_score(score);– 查询student表的索引
SHOW INDEX FROM student;– 删除索引
DROP INDEX idx_score ON student;
索引的原理
- 索引是在存储引擎中实现的,不同的存储引擎所支持的索引也不一样,这里主要介绍InnoDB 引擎的BTree索引
- BTree索引类型是基于B+Tree数据结构的,而B+Tree数据结构又是BTree数据结构的变种。通常使用在数据库和操作系统中的文件系统,特点是能够保持数据稳定有序
- 需要理解的
- 磁盘存储
- BTree
- B+Tree
磁盘存储
- 系统从磁盘读取数据到内存时是以磁盘块(block)为基本单位的
- 位于同一个磁盘块中的数据会被一次性读取出来,而不是需要什么取什么
- InnoDB 存储引擎中有页(page)的概念,页是其磁盘管理的最小单位。InnoDB存储引擎中默认每个页的大小为 16 KB
- InnoDB 引擎将若干个地址连接磁盘块,以此来达到页的大小 16 KB,在查询数据时如果一个页中的每条数据都能有助于定位数据记录的位置,这将会减少磁盘 I/O 次数,提高查询效率
BTree
- 在每一个结点上,除了保存键值外,还会保存真实的数据
- 左边存小的,右边存大的,类似二叉树
- 但是在查询数据时,涉及到的磁盘块数据都会被读取出来,会增加查询数据时磁盘的IO次数,效率并不高
B+Tree
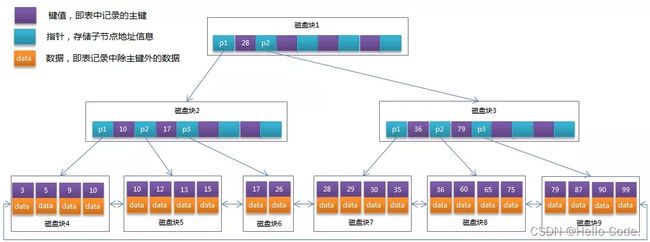
- 在每一个结点上,只保存键值,并不保存真实的数据
- 在叶子结点上保存着真实数据
- 所有的叶子结点之间都有连接指针
- 好处
- 提高查询速度
- 减少磁盘的IO次数
- 树型结构较小
设计原则
- 创建索引遵循的原则
- 对查询频次较高,且数据量比较大的表建立索引
- 使用唯一索引,区分度越高,使用索引的效率越高
- 索引字段的选择,最佳候选应当从where子句的条件中提取
- 索引虽然可以有效的提升查询数据的效率,但并不是多多益善
- 最左匹配原则(使用组合索引)
- 例如:为user表中的name、address、phone 列添加组合索引
ALTER TABLE user ADD INDEX idx_three(name,address,phone); - 此时,组合索引idx_three实际建立了(name)、(name,address)、(name,address,phone)三个索引
- 下面的三个SQL语句都可以命中索引
SELECT * FROM user WHERE address = ‘北京’ AND phone = '12345' AND name = '张三';
SELECT * FROM user WHERE name = '张三' AND address = '北京';
SELECT * FROM user WHERE name = '张三'; - 这三条SQL语句在检索时分别会使用以下索引进行数据匹配
(name,address,phone)
(name,address)
(name) - 索引字段出现的顺序可以是任意的,MySQL 优化器会帮我们自动的调整where 条件中的顺序
- 如果组合索引中最左边的列不在查询条件中,则不会命中索引
SELECT * FROM user WHERE address = '北京';
- 例如:为user表中的name、address、phone 列添加组合索引
锁
-
锁机制:数据库为了保证数据的一致性,在共享的资源被并发访问时变得安全所设计的一种规则
-
锁机制类似多线程中的同步,作用就是可以保证数据的一致性和安全性
-
按操作分类
- 共享锁:也叫读锁。针对同一份数据,多个事务读取操作可以同时加锁而不相互影响,但是不能修改数据
- 排他锁:也叫写锁。当前的操作没有完成前,会阻断其他操作的读取和写入
-
按粒度分类
- 表级锁:会锁定整张表。开销小,加锁快。锁定粒度大,发生锁冲突概率高,并发度低。不会出现死锁情况
- 行级锁:会锁定当前行。开销大,加锁慢。锁定粒度小,发生锁冲突概率低,并发度高。会出现死锁情况
-
按使用方式分类
- 悲观锁:每次查询数据时都认为别人会修改,很悲观,所以查询时加锁
- 乐观锁:每次查询时都认为别人不会修改,很乐观,但是更新时会判断一下在此期间别人有没有去更新这个数据
-
不同存储引擎支持的锁
存储引擎
表锁
行锁
InnoDB
支持
支持
MyISAM
支持
不支持
MEMORY
支持
不支持
注意: 在下面所有的锁的操作中,只提到了修改操作,但是增删都是和修改一样的
InnoDB共享锁
-
共享锁特点
数据可以被多个事务查询,但是不能修改
InnoDB引擎默认加的是行锁,如果不采用带索引的列加锁时加的就是表锁 -
创建共享锁格式
SELECT语句 LOCK IN SHARE MODE;/*
数据准备
*/– 创建db10数据库
CREATE DATABASE db10;– 使用db10数据库
USE db10;– 创建student表
CREATE TABLE student(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(10),
age INT,
score INT
);– 添加数据
INSERT INTO student VALUES (NULL, ‘张三’, 23, 99), (NULL, ‘李四’, 24, 95),
(NULL, ‘王五’, 25, 98), (NULL, ‘赵六’, 26, 97);/*
窗口1
*/– 开启事务
START TRANSACTION;– 查询id为1的数据,并加入共享锁
SELECT * FROM student WHERE id = 1 LOCK IN SHARE MODE;– 查询分数为99的数据,并加入共享锁
SELECT * FROM student WHERE score = 99 LOCK IN SHARE MODE;– 提交事务
COMMIT;/*
窗口2
*/– 开启事务
START TRANSACTION;– 查询id为1的数据(普通查询没有问题)
SELECT * FROM student WHERE id = 1;– 查询id为1的数据,也加入共享锁(共享锁和共享锁之间相互兼容)
SELECT * FROM student WHERE id = 1 LOCK IN SHARE MODE;– 修改id为1的数据,姓名改为张三三(修改失败,出现锁的情况,只有在窗口一提交事务之后才能修改成功)
UPDATE student SET NAME = ‘张三三’ WHERE id = 1;– 修改id为2的数据,将姓名修改为李四四(修改成功,InnoDB引擎默认加的是行锁)
UPDATE student SET NAME = ‘李四四’ WHERE id = 2;– 修改id为3的数据,姓名改为王五五(修改失败,锁,InnoDB如果不采用带索引的列加锁时加的就是表锁)
UPDATE student SET NAME = ‘王五五’ WHERE id = 3;– 提交事务(窗口2没提交事务时修改的内容在窗口1中不能查询到)
COMMIT;
InnoDB排他锁
-
排他锁特点
加锁的数据,不能被其他事务加锁查询或修改(普通查询可以)
锁和锁之间不能共存 -
创建排他锁的格式
SELECT语句 FOR UPDATE;/*
窗口1
*/– 开启事务
START TRANSACTION;– 查询id为1的数据,并加入排他锁
SELECT * FROM student WHERE id = 1 FOR UPDATE;
SELECT * FROM student WHERE score = 99 FOR UPDATE;
– 提交事务
COMMIT;/*
窗口2
*/– 开启事务
START TRANSACTION;– 查询id为1的数据(成功,普通查询没问题)
SELECT * FROM student WHERE id =1;– 查询id为1的数据,并加入共享锁(失败,排他锁和共享锁不兼容)
SELECT * FROM student WHERE id = 1 LOCK IN SHARE MODE;– 查询id为1的数据,并加入排他锁(失败,排他锁和排他锁也不兼容)
SELECT * FROM student WHERE id =1 FOR UPDATE;– 修改id为1的数据,姓名改为张三(失败,会出现锁的情况,只有窗口1提交事务后才能修改)
UPDATE student SET NAME = ‘张三’ WHERE id = 1;– 提交事务
COMMIT;
MyISAM 读锁
-
读锁特点
所有连接只能查询数据,不能修改
MyISAM存储引擎只能添加表锁,且不支持事务 -
读锁语法格式
- 加锁:
LOCK TABLE 表名 READ; - 解锁:
UNLOCK TABLES;
– 创建product表
CREATE TABLE product(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20),
price INT
)ENGINE = MYISAM;– 添加数据
INSERT INTO product VALUES (NULL, ‘华为手机’, 4999), (NULL, ‘小米手机’, 2999),
(NULL, ‘苹果’, 8999), (NULL, ‘中兴’, 1999);/*
窗口1
*/– 为product表添加读锁
LOCK TABLE product READ;– 查询id为1的数据
SELECT * FROM product WHERE id = 1;– 修改id为1的数据,金额改为4999(失败,读锁中所有连接只能读取数据不能修改数据)
UPDATE product SET price = 4999 WHERE id = 1;– 解锁
UNLOCK TABLES;/*
窗口2
*/– 查询id为1的数据
SELECT * FROM product WHERE id = 1;– 修改id为1的数据,金额改为5999(失败,读锁中所有连接只能读取数据不能修改数据)
UPDATE product SET price = 5999 WHERE id = 1; - 加锁:
MyISAM 写锁
-
写锁特点
其他连接不能查询和修改数据(当前连接下可以查询和修改) -
写锁语法格式
- 加锁:
LOCK TABLE 表名 WRITE; - 解锁:
UNLOCK TABLES;
/*
窗口1
*/– 为product表添加写锁
LOCK TABLE product WRITE;– 查询(没有问题)
SELECT * FROM product;– 修改(没有问题)
UPDATE product SET price = 1999 WHERE id = 2;– 解锁
UNLOCK TABLES;/*
窗口2
*/– 查询(失败,出现锁,只有窗口1解锁后才能成功)
SELECT * FROM product;– 修改(失败,出现锁,只有窗口1解锁后才能成功)
UPDATE product SET price = 2999 WHERE id = 2; - 加锁:
悲观锁和乐观锁
- 悲观锁
就是很悲观,它对于数据被外界修改的操作持保守态度,认为数据随时会修改
整个数据处理中需要将数据加锁。悲观锁一般都是依靠关系型数据库提供的锁机制
我们之前所学习的锁机制都是悲观锁 - 乐观锁
就是很乐观,每次自己操作数据的时候认为没有人会来修改它,所以不去加锁
但是在更新的时候会去判断在此期间数据有没有被修改
需要用户自己去实现,不会发生并发抢占资源,只有在提交操作的时候检查是否违反数据完整性
乐观锁实现方式(了解)
-
方式一
- 给数据表中添加一个version列,每次更新后都将这个列的值加1
- 读取数据时,将版本号读取出来,再执行更新的时候,比较版本号
- 如果相同则执行更新,如果不同,说明此条数据已经发生了变化
- 用户自行根据这个通知来决定怎么处理,比如重新开始一遍,或者放弃本次更新
-
方式二
- 和版本号方式基本一样,给数据表加入一个列,名称无所谓,数据类型是 timestamp
- 每次更新后都将最新时间插入到此列
- 读取数据时,将时间读取出来,在执行更新的时候,比较时间
- 如果相同则更新,如果不相同,说明此条数据已经发生了变化
– 创建city表
CREATE TABLE city(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20),
VERSION INT
);– 添加数据
INSERT INTO city VALUES (NULL, ‘北京’, 1), (NULL, ‘上海’, 1), (NULL, ‘广州’, 1), (NULL, ‘深圳’, 1);– 将北京修改为北京市
– 1. 将北京的版本号读取出来
SELECT VERSION FROM city WHERE NAME = ‘北京’; – 1
– 2. 修改北京为北京市,版本号+1,并对比版本号是否相同
UPDATE city SET NAME = ‘北京市’, VERSION = VERSION + 1 WHERE NAME = ‘北京’ AND VERSION = 1;
MyCat
本部分内容理解就行,在最终项目时可能才会用到,后期还需要单独的学习
随着互联网的发展,数据的量级也是不断地增长,从GB 到 TB 到 PB。对数据的各种操作也是越来越困难,一台数据库服务器已经无法满足海量数据的存储需求,所以多台数据库服务器构成的数据库集群成了必然的方式。不过,还要保证数据的一致性,查询效率等,同时又要解决多台服务器间的通信、负载均衡等问题
-
MyCat可以针对多台服务器做统一的管理,连接时只需要连接MyCat
-
Mycat是一款出色的数据库集群软件,不仅支持MySQL,常用关系型数据库也都支持
-
其实就是一个数据库中间件产品,支持MySQL集群。提供高可用性数据分片集群
-
我们可以像使用MySQL一样使用MyCat。对于开发人员来说几乎感觉不到MyCat 的存在
安装
- MyCat官网
http://www.mycat.io - 通过CRT工具上传到linux
put D:Mycat-server-1.6.7.1-release-20190627191042-linux.tar.gz - 解压并查看
tar -zxvf mycat.tar.gz
cd mycat
ls - 为mycat目录授权
chmod -R 777 mycat - 配置环境变量
编辑文件:vi /etc/profile
添加内容:export MYCAT_HOME=/root/mycat(最下方)
加载文件:source /etc/profile - 启动mycat
进入目录:cd /root/mycat/bin
执行启动:./mycat start - 查看端口监听
netstat -ant|grep 8066 - SQLyog连接mycat
默认用户名:root
默认密码:123456
默认端口号:8066
集群环境
- 集群模型
- MyCat MySQL 主服务器
- MySQL 从服务器
- 克隆虚拟机
- 修改第二个虚拟机的网卡,重新生成MAC地址
- 修改第二个服务器MySQL 配置文件 uuid
- 编辑配置文件:
vi /var/lib/mysql/auto.cnf - 将 server-uuid 更改一个数字即可
- 编辑配置文件:
- 启动相关服务
- 关闭两台服务器的防火墙:
systemctl stop firewalld - 启动两台服务器的MySQL:
service mysqld restart - 启动两台服务器的MyCat:
cd /root/mycat/bin./mycat restart - 查看两台服务器的监听端口:
netstat -ant|grep 3306netstat -ant|grep 8066
- 关闭两台服务器的防火墙:
主从复制
- 为了使用MyCat进行读写分离,我们先要配置MySQL 数据库的主从复制
- 从服务器自动同步主服务器的数据,从而达到数据一致
- 进而,我们可以在写操作时,只操作主服务器,而读操作,就可以操作从服务器了
配置
主服务器
-
在第一个服务器上,编辑mysql配置文件
-
编辑mysql配置文件:
vi /etc/my.cnf -
在[mysqld]下面加上
// log-bin代表开启主从复制,server-id代表主从服务器的唯一标识
log-bin=mysql-bin
server-id=1
innodb_flush_log_at_trx_commit=1
sync_binlog=1
-
-
查看主服务器的配置
- 重启mysql:
service mysqld restart - 登录mysql:
mysql -u root -p - 查看主服务的配置:
show master status;
需要记住 File 列和 Position 列的数据,将来配置从服务器需要使用
- 重启mysql:
从服务器
-
在第二个服务器上,编辑mysql配置文件
- 编辑mysql配置文件:
vi /etc/my.cnf - 在[mysqld]下面加上:
server-id=2
- 编辑mysql配置文件:
-
登录mysql:
mysql -u root -p -
执行
use mysql; drop table slave_master_info; drop table slave_relay_log_info; drop table slave_worker_info; drop table innodb_index_stats; drop table innodb_table_stats; source /usr/share/mysql/mysql_system_tables.sql; -
重启mysql,重新登录,配置从节点
- 重启mysql:
service mysqld restart - 重新登录mysql:
mysql -u root -p - 执行:
change master to master_host='192.168.59.143',master_port=3306,master_user='root',master_password='itheima',master_log_file='mysql-bin.000001',master_log_pos=154; - 开启从节点:
start slave; - 查询结果:
show slave statusG;
Slave_IO_Running和Slave_SQL_Running都为YES才表示同步成功。
- 重启mysql:
-
测试:在主服务器上创建一个db1数据库,查看从服务器上是否自动同步
读写分离
- 写操作只写入主服务器,由于有主从复制,从服务器中也会自动同步数据
- 读操作是读取从服务器中的数据
配置
-
修改主服务器 server.xml:
vi /root/mycat/conf/server.xmlMyCat密码 MyCat逻辑数据库显示的名字(虚拟数据库名) -
修改主服务器 schema.xml:
vi /root/mycat/conf/schema.xmlselect user() -
重启MyCat
进入mycat路径:cd /root/mycat/bin
重启mycat:./mycat restart
查看端口监听:netstat -ant|grep 8066
分库分表
- 分库分表:将庞大的数据量拆分为不同的数据库和数据表进行存储
- 水平拆分
根据表的数据逻辑关系,将同一表中的数据按照某种条件,拆分到多台数据库服务器上,也叫做横向拆分
例如:一张 1000万的大表,按照一模一样的结构,拆分成4个250万的小表,分别保存到4个数据库中 - 垂直拆分
根据业务的维度,将不同的表切分到不同的数据库上,也叫做纵向拆分
例如:所有的动物表都保存到动物库中,所有的水果表都保存到水果库中,同类型的表保存在同一个库中
水平拆分
-
修改主服务器中 server.xml:
vi /root/mycat/conf/server.xml0 -
修改主服务器中 sequence_conf.properties:
vi /root/mycat/conf/sequence_conf.properties#default global sequence GLOBAL.HISIDS= # 可以自定义关键字 GLOBAL.MINID=10001 # 最小值 GLOBAL.MAXID=20000 # 最大值 -
修改主服务器中 schema.xml:
vi /root/mycat/conf/schema.xmlselect user() -
修改主服务器中 rule:
vi /root/mycat/conf/rule.xml3
垂直拆分
-
修改主服务器中 schema.xml:
vi /root/mycat/conf/schema.xmlselect user()
JDBC
JDBC(Java DataBase Connectivity java数据库连接) 是一种用于执行SQL语句的Java API,可以为多种关系型数据库提供统一访问,它是由一组用Java语言编写的类和接口组成的
- 本质:其实就是Java官方提供的一套规范(接口)。用于帮助开发人员快速实现不同关系型数据库的连接
快速入门
-
导入jar包
-
注册驱动
-
获取数据库连接
-
获取执行者对象
-
执行sql语句并返回结果
-
处理结果
-
释放资源
package study.jdbc;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;public class Demo01 {
public static void main(String[] args) throws Exception {
// 导入jar包
// 注册驱动
Class.forName(“com.mysql.jdbc.Driver”);// 获取连接 Connection con = DriverManager.getConnection("jdbc:mysql://192.168.23.129:3306/db2","root","lh18391794828"); // 获取执行者对象 Statement stat = con.createStatement(); // 执行sql语句,并接收结果 String sql = "SELECT * FROM user"; ResultSet rs = stat.executeQuery(sql); // 处理结果 while(rs.next()){ System.out.println(rs.getInt("id") + " " + rs.getString("name")); } // 释放资源 con.close(); stat.close(); rs.close(); }}
功能类详解
DriverManager 驱动管理对象
-
注册驱动
注册给定的驱动程序:static void registerDriver(Driver driver);
写代码使用:Class.forName("com.mysql.jdbc.Driver");
在com.mysql.jdbc.Driver类中存在静态代码块static{ try{ DriverManager.registerDriver(new Driver()); }catch(SQL Exception E){ throw new RuntimeException("Can't register driver!"); } }我们不需要通过DriverManager调用静态方法registerDriver(),因为只要Driver类被使用,就会执行其静态代码块完成注册驱动
mysql 5之后可以省略注册驱动的步骤。在jar包中,存在一个java.sql.Driver配置文件,文件中指定了 com.mysql.jdbc.Driver -
获取数据库连接
获取数据库连接对象:static Connection getConnection(String url,String user,String password);
返回值:Connection 数据库连接对象连接成功返回Connection对象,连接失败则会报错
url:指定连接的路径。语法:jdbc:mysql://ip地址(域名):端口号/数据库名称
user:用户名
password:密码
Connection 数据库连接对象
- 获取执行者对象
获取普通执行者对象:Statement createStatement();
获取预编译执行者对象:PreparedStatement prepareStatement(String sql); - 管理事务
开启事务:setAutoCommit(boolean autoCommit);参数为false,则开启事务
提交事务:commit();
回滚事务:rollback(); - 释放资源
立即将数据库连接对象释放:void close();
Statement 执行者对象
- 执行DML语句:
int executeUpdate(String sql);
返回值int:返回影响的行数
参数sql:可以执行insert、update、delete语句 - 执行DQL语句:
ResultSet executeQuery(String sql);
返回值ResultSet:封装查询的结果
参数sql:可以执行select语句 - 释放资源
立即将执行者对象释放:void close();
ResultSet 结果集对象
- 判断结果集中是否还有数据:
boolean next();
有数据返回true,并将索引向下移动一行
没有数据返回false - 获取结果集中的数据:
XXX getXXX("列名");
XXX代表数据类型(要获取某列数据,就指这一列的数据类型)
例如:String getString("name");int getInt("age"); - 释放资源
立即将结果集对象释放:void close();
案例
使用 JDBC 技术完成对student 表的 CRUD 操作
数据准备
创建数据库和数据表
-- 创建db11数据库
CREATE DATABASE db11;
-- 使用db11数据库
USE db11;
-- 创建student表
CREATE TABLE student(
sid INT PRIMARY KEY AUTO_INCREMENT, -- 学生id
NAME VARCHAR(20), -- 学生姓名
age INT, -- 学生年龄
birthday DATE -- 学生生日
);
-- 添加数据
INSERT INTO student VALUES (NULL, '张三', 23, '1999-09-23'), (NULL, '李四', 24, '1998-08-10'),
(NULL, '王五', 25, '1996-06-06'), (NULL, '赵六', 26, '1994-10-20');
创建Student类
package study.jdbc.Demo.domain;
import java.util.Date;
public class Student {
private Integer sid;
private String name;
private Integer age;
private Date birthday;
public Student() {
}
public Student(Integer sid, String name, Integer age, Date birthday) {
this.sid = sid;
this.name = name;
this.age = age;
this.birthday = birthday;
}
public Integer getSid() {
return sid;
}
public void setSid(Integer sid) {
this.sid = sid;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public Date getBirthday() {
return birthday;
}
public void setBirthday(Date birthday) {
this.birthday = birthday;
}
@Override
public String toString() {
return "Student{" +
"sid=" + sid +
", name='" + name + ''' +
", age=" + age +
", birthday=" + birthday +
'}';
}
}
注意:
自定义类的功能是为了封装表中每列数据,成员变量和列要保持一致
所有基本数据类型需要使用对应的包装类,以免表中null值无法赋值
需求实现
- 查询所有学生信息
- 根据id查询学生信息
- 新增学生信息
- 修改学生信息
- 删除学生信息
代码展示
查询所有学生信息
/*
查询所有学生信息
*/
@Override
public ArrayList findAll() {
Connection con = null;
Statement stat = null;
ResultSet res = null;
ArrayList list = new ArrayList<>();
try{
// 1.注册驱动
Class.forName("com.mysql.jdbc.Driver");
// 2.获取数据库连接
con = DriverManager.getConnection("jdbc:mysql://192.168.23.129:3306/db11", "root", "密码");
// 3.获取执行者对象
stat = con.createStatement();
// 4.执行sql语句,并接收返回的结果集
String sql = "SELECT * FROM student";
res = stat.executeQuery(sql);
// 5.处理结果集
while(res.next()){
Integer sid = res.getInt("sid");
String name = res.getString("name");
Integer age = res.getInt("age");
Date birthday = res.getDate("birthday");
list.add(new Student(sid,name,age,birthday));
}
}catch(Exception e){
e.printStackTrace();
}finally {
// 6.释放资源
if(con != null) {
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(stat != null) {
try {
stat.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(res != null) {
try {
res.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
// 将集合对象返回
return list;
}
根据id查询学生信息
/*
根据id查询学生信息
*/
@Override
public Student findById(Integer id) {
Connection con = null;
Statement stat = null;
ResultSet res = null;
Student stu = new Student();
try{
// 1.注册驱动
Class.forName("com.mysql.jdbc.Driver");
// 2.获取数据库连接
con = DriverManager.getConnection("jdbc:mysql://192.168.23.129:3306/db11", "root", "密码");
// 3.获取执行者对象
stat = con.createStatement();
// 4.执行sql语句,并接收返回的结果集
String sql = "SELECT * FROM student WHERE sid = " + id;
res = stat.executeQuery(sql);
// 5.处理结果集
while(res.next()){
Integer sid = res.getInt("sid");
String name = res.getString("name");
Integer age = res.getInt("age");
Date birthday = res.getDate("birthday");
// 封装学生对象
stu.setSid(sid);
stu.setName(name);
stu.setAge(age);
stu.setBirthday(birthday);
}
}catch(Exception e){
e.printStackTrace();
}finally {
// 6.释放资源
if(con != null) {
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(stat != null) {
try {
stat.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(res != null) {
try {
res.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
// 将对象返回
return stu;
}
新增学生信息
/*
添加学生信息
*/
@Override
public int insert(Student stu) {
Connection con = null;
Statement stat = null;
int result = 0;
try{
// 1.注册驱动
Class.forName("com.mysql.jdbc.Driver");
// 2.获取数据库连接
con = DriverManager.getConnection("jdbc:mysql://192.168.23.129:3306/db11", "root", "密码");
// 3.获取执行者对象
stat = con.createStatement();
// 4.执行sql语句,并接收返回的结果集
Date d = stu.getBirthday();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
String birthday = sdf.format(d);
String sql = "INSERT INTO student VALUES ('"+stu.getSid()+"','"+stu.getName()+"','"+stu.getAge()+"','"+birthday+"')";
result = stat.executeUpdate(sql);
// 5.处理结果集
}catch(Exception e){
e.printStackTrace();
}finally {
// 6.释放资源
if(con != null) {
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(stat != null) {
try {
stat.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
// 将结果返回
return result;
}
修改学生信息
/*
修改学生信息
*/
@Override
public int update(Student stu) {
Connection con = null;
Statement stat = null;
int result = 0;
try{
// 1.注册驱动
Class.forName("com.mysql.jdbc.Driver");
// 2.获取数据库连接
con = DriverManager.getConnection("jdbc:mysql://192.168.23.129:3306/db11", "root", "密码");
// 3.获取执行者对象
stat = con.createStatement();
// 4.执行sql语句,并接收返回的结果集
Date d = stu.getBirthday();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
String birthday = sdf.format(d);
String sql = "UPDATE student SET sid='"+stu.getSid()+"',name='"+stu.getName()+"',age='"+stu.getAge()+"',birthday='"+birthday+"' WHERE sid='"+stu.getSid()+"'";
result = stat.executeUpdate(sql);
// 5.处理结果集
}catch(Exception e){
e.printStackTrace();
}finally {
// 6.释放资源
if(con != null) {
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(stat != null) {
try {
stat.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
// 将结果返回
return result;
}
删除学生信息
/*
删除学生信息
*/
@Override
public int delete(Integer id) {
Connection con = null;
Statement stat = null;
int result = 0;
try{
// 1.注册驱动
Class.forName("com.mysql.jdbc.Driver");
// 2.获取数据库连接
con = DriverManager.getConnection("jdbc:mysql://192.168.23.129:3306/db11", "root", "密码");
// 3.获取执行者对象
stat = con.createStatement();
// 4.执行sql语句,并接收返回的结果集
String sql = "DELETE FROM student WHERE sid='"+id+"'";
result = stat.executeUpdate(sql);
// 5.处理结果集
}catch(Exception e){
e.printStackTrace();
}finally {
// 6.释放资源
if(con != null) {
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(stat != null) {
try {
stat.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
// 将结果返回
return result;
}
工具类
抽取工具类
-
编写配置文件
在src目录下创建config.properties 配置文件driverClass=com.mysql.jdbc.Driver url=jdbc:mysql://localhost:3006/db4 username=root password=密码 -
编写JDBC 工具类
package study.jdbc.Demo.utils; import com.mysql.jdbc.Driver; import java.io.IOException; import java.io.InputStream; import java.sql.*; import java.util.Properties; public class JDBCUtils { // 1. 私有构造方法 private JDBCUtils(){} // 2. 声明所需要的配置变量 private static String driverClass; private static String url; private static String username; private static String password; private static Connection con; // 3. 提供静态代码块。读取配置文件的信息为变量赋值,注册驱动 static { try { // 读取配置文件的信息为变量赋值 InputStream is = JDBCUtils.class.getClassLoader().getResourceAsStream("config.properties"); Properties prop = new Properties(); prop.load(is); driverClass = prop.getProperty("driverClass"); url = prop.getProperty("url"); username = prop.getProperty("username"); password = prop.getProperty("password"); // 注册驱动 Class.forName(driverClass); } catch (Exception e) { e.printStackTrace(); } } // 4. 提供获取数据库连接方法 public static Connection getConnection(){ try { con = DriverManager.getConnection(url, username, password); } catch (SQLException e) { e.printStackTrace(); } return con; } // 5. 提供释放资源的方法 public static void close(Connection con, Statement stat, ResultSet rs){ if(con != null){ try { con.close(); } catch (SQLException e) { e.printStackTrace(); } } if(stat != null){ try { stat.close(); } catch (SQLException e) { e.printStackTrace(); } } if(rs != null){ try { rs.close(); } catch (SQLException e) { e.printStackTrace(); } } } public static void close(Connection con, Statement stat){ if(con != null){ try { con.close(); } catch (SQLException e) { e.printStackTrace(); } } if(stat != null){ try { stat.close(); } catch (SQLException e) { e.printStackTrace(); } } } }
优化学生案例
package study.jdbc.Demo.dao;
import study.jdbc.Demo.domain.Student;
import study.jdbc.Demo.utils.JDBCUtils;
import java.sql.*;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
public class StudentDaoImpl implements StudentDao{
/*
查询所有学生信息
*/
@Override
public ArrayList findAll() {
Connection con = null;
Statement stat = null;
ResultSet res = null;
ArrayList list = new ArrayList<>();
try{
con = JDBCUtils.getConnection();
// 获取执行者对象
stat = con.createStatement();
// 执行sql语句,并接收返回的结果集
String sql = "SELECT * FROM student";
res = stat.executeQuery(sql);
// 处理结果集
while(res.next()){
Integer sid = res.getInt("sid");
String name = res.getString("name");
Integer age = res.getInt("age");
Date birthday = res.getDate("birthday");
list.add(new Student(sid,name,age,birthday));
}
}catch(Exception e){
e.printStackTrace();
}finally {
// 释放资源
JDBCUtils.close(con, stat, res);
}
// 将集合对象返回
return list;
}
/*
条件查询,根据id获取学生信息
*/
@Override
public Student findById(Integer id) {
Connection con = null;
Statement stat = null;
ResultSet res = null;
Student stu = new Student();
try{
con = JDBCUtils.getConnection();
// 获取执行者对象
stat = con.createStatement();
// 执行sql语句,并接收返回的结果集
String sql = "SELECT * FROM student WHERE sid = " + id;
res = stat.executeQuery(sql);
// 处理结果集
while(res.next()){
Integer sid = res.getInt("sid");
String name = res.getString("name");
Integer age = res.getInt("age");
Date birthday = res.getDate("birthday");
// 封装学生对象
stu.setSid(sid);
stu.setName(name);
stu.setAge(age);
stu.setBirthday(birthday);
}
}catch(Exception e){
e.printStackTrace();
}finally {
// 释放资源
JDBCUtils.close(con,stat,res);
}
// 将对象返回
return stu;
}
/*
新增学生信息
*/
@Override
public int insert(Student stu) {
Connection con = null;
Statement stat = null;
int result = 0;
try{
con = JDBCUtils.getConnection();
// 获取执行者对象
stat = con.createStatement();
// 执行sql语句,并接收返回的结果集
Date d = stu.getBirthday();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
String birthday = sdf.format(d);
String sql = "INSERT INTO student VALUES ('"+stu.getSid()+"','"+stu.getName()+"','"+stu.getAge()+"','"+birthday+"')";
result = stat.executeUpdate(sql);
// 处理结果集
}catch(Exception e){
e.printStackTrace();
}finally {
// 释放资源
JDBCUtils.close(con,stat);
}
// 将结果返回
return result;
}
/*
修改学生信息
*/
@Override
public int update(Student stu) {
Connection con = null;
Statement stat = null;
int result = 0;
try{
con = JDBCUtils.getConnection();
// 获取执行者对象
stat = con.createStatement();
// 执行sql语句,并接收返回的结果集
Date d = stu.getBirthday();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
String birthday = sdf.format(d);
String sql = "UPDATE student SET sid='"+stu.getSid()+"',name='"+stu.getName()+"',age='"+stu.getAge()+"',birthday='"+birthday+"' WHERE sid='"+stu.getSid()+"'";
result = stat.executeUpdate(sql);
// 处理结果集
}catch(Exception e){
e.printStackTrace();
}finally {
// 释放资源
JDBCUtils.close(con,stat);
}
// 将结果返回
return result;
}
/*
删除学生信息
*/
@Override
public int delete(Integer id) {
Connection con = null;
Statement stat = null;
int result = 0;
try{
con = JDBCUtils.getConnection();
// 获取执行者对象
stat = con.createStatement();
// 执行sql语句,并接收返回的结果集
String sql = "DELETE FROM student WHERE sid='"+id+"'";
result = stat.executeUpdate(sql);
// 处理结果集
}catch(Exception e){
e.printStackTrace();
}finally {
// 释放资源
JDBCUtils.close(con,stat);
}
// 将结果返回
return result;
}
}
注入攻击
-
什么是SQL注入攻击
就是利用SQL语句的漏洞来对系统进行攻击/*
使用Statement的登录方法,有注入攻击
*/
@Override
public User findByLoginNameAndPassword(String loginName, String password) {
//定义必要信息
Connection conn = null;
Statement st = null;
ResultSet rs = null;
User user = null;
try {
//1.获取连接
conn = JDBCUtils.getConnection();
//2.定义SQL语句
String sql = “SELECT * FROM user WHERE loginname='”+loginName+“’ AND password='”+password+“'”;
System.out.println(sql);
//3.获取操作对象,执行sql语句,获取结果集
st = conn.createStatement();
rs = st.executeQuery(sql);
//4.获取结果集
if (rs.next()) {
//5.封装
user = new User();
user.setUid(rs.getString(“uid”));
user.setUcode(rs.getString(“ucode”));
user.setUsername(rs.getString(“username”));
user.setPassword(rs.getString(“password”));
user.setGender(rs.getString(“gender”));
user.setDutydate(rs.getDate(“dutydate”));
user.setBirthday(rs.getDate(“birthday”));
user.setLoginname(rs.getString(“loginname”));
}
//6.返回
return user;
}catch (Exception e){
throw new RuntimeException(e);
}finally {
JDBCUtils.close(conn,st,rs);
}
}
在上面代码中,登录时账户随便输入,密码输入bbb’ or ‘1’ = '1 就会直接登录成功
执行者对象会执行SELECT * FROM user WHERE loginname='aaa' AND password='bbb' or '1' = '1'语句
-
SQL注入攻击的原理
- 按照正常道理来说,我们在密码处输入的内容,都应该认为是密码的组成
- 但是现在Statement对象在执行sql语句时,将密码的一部分内容当作查询条件来执行了
-
SQL注入攻击的解决
-
PreparedStatement 预编译执行者对象
- 在执行sql语句之前,将sql语句进行提前编译。明确sql语句的格式后,就不会改变了。剩余的内容都会认为是参数
- SQL语句中的参数使用
?作为占位符
-
为
?占位符赋值的方法:setXxx(参数1,参数2);-
Xxx代表:数据类型
-
参数1: 的位置编号(编号从1开始)
-
参数2: 的实际参数
String sql = "SELECT * FROM user WHERE loginname=? AND password=?"; PreparedStatement st = conn.prepareStatement(sql); st.setString(1,loginName); st.setString(2,password); rs = st.executeQuery();
-
-
执行SQL 语句
- 执行 insert、update、delete 语句:
int executeUpdate(); - 执行select 语句:
ResultSet executeQuery();
- 执行 insert、update、delete 语句:
-
事务管理
-
JDBC 如何管理事务
- 管理事务的功能类:Connection
- 开启事务:
setAutoCommit(boolean autoCommit);参数为false,则开启事务 - 提交事务:
commit(); - 回滚事务:
rollback();
- 开启事务:
- 管理事务的功能类:Connection
-
演示批量添加数据并在业务层管理事务
@Override public void batchAdd(Listusers) { //获取数据库连接对象 Connection con = JDBCUtils.getConnection(); try { //开启事务 con.setAutoCommit(false); for (User user : users) { //1.创建ID,并把UUID中的-替换 String uid = UUID.randomUUID().toString().replace("-", "").toUpperCase(); //2.给user的uid赋值 user.setUid(uid); //3.生成员工编号 user.setUcode(uid); //出现异常 //int n = 1 / 0; //4.保存 userDao.save(con,user); } //提交事务 con.commit(); }catch (Exception e){ //回滚事务 try { con.rollback(); } catch (SQLException e1) { e1.printStackTrace(); } e.printStackTrace(); } finally { //释放资源 JDBCUtils.close(con,null); } }
连接池
数据库连接是一种关键的、有限的、昂贵的资源,这一点在多用户的网页应用体现的尤为突出
对数据库连接的管理能显著影响到整个应用程序的性能指标,数据库连接池正是针对这个问题提出来的
- 数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个。这项技术能明显提高对数据库操作的性能
自定义数据库连接池
DataSource
- javax.sql.DataSource 接口:数据源(数据库连接池)。Java官方提供的数据库连接池规范(接口)
- 如果想完成数据库连接池技术,就必须实现DataSource 接口
- 核心功能:获取数据库连接对象:
Connection getConnection();
自定义数据库连接池
-
定义一个类,实现DataSource 接口
-
定义一个容器,用于保存多个 Connection 连接对象
-
定义静态代码块,通过 JDBC 工具类获取10个连接保存到容器中
-
重写 getConnection方法,从容器中获取一个连接并返回
-
定义 getSize方法,用于获取容器的大小并返回
package jdbc.demo01;
/*
- 自定义数据库连接池
- */
import jdbc.utils.JDBCUtils;
import javax.sql.DataSource;
import java.io.PrintWriter;
import java.sql.Connection;
import java.sql.SQLException;
import java.sql.SQLFeatureNotSupportedException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.logging.Logger;public class MyDataSource implements DataSource {
// 1.准备容器。保存多个连接对象(通过Collections的方法获取一个线程安全的集合对象)
private static List pool = Collections.synchronizedList(new ArrayList<>());// 2. 定义静态代码块,通过工具类获取10个连接对象 static { for(int i = 1; i <= 10; i++){ Connection con = JDBCUtils.getConnection(); pool.add(con); } } // 3. 重写getConnection方法,获取连接对象 @Override public Connection getConnection() throws SQLException { if(pool.size() > 0){ Connection con = pool.remove(0); return con; }else{ throw new RuntimeException("连接数量已用尽"); } } // 4. 定义getSize方法,获取连接池容器的大小 public int getSize(){ return pool.size(); } @Override public Connection getConnection(String username, String password) throws SQLException { return null; } @Override publicT unwrap(Class iface) throws SQLException { return null; } @Override public boolean isWrapperFor(Class iface) throws SQLException { return false; } @Override public PrintWriter getLogWriter() throws SQLException { return null; } @Override public void setLogWriter(PrintWriter out) throws SQLException { } @Override public void setLoginTimeout(int seconds) throws SQLException { } @Override public int getLoginTimeout() throws SQLException { return 0; } @Override public Logger getParentLogger() throws SQLFeatureNotSupportedException { return null; } }
测试
package jdbc.demo01;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class MyDataSourceTest {
public static void main(String[] args) throws SQLException {
// 1. 创建连接池对象
MyDataSource dataSource = new MyDataSource();
// 2.通过连接池对象获取连接对象
Connection con = dataSource.getConnection();
// 3. 查询学生表全部信息
String sql = "SELECT * FROM student";
PreparedStatement ps = con.prepareStatement(sql);
ResultSet rs = ps.executeQuery();
while(rs.next()){
System.out.println(rs.getInt("sid") + " " + rs.getString("name") + " " + rs.getInt("age") + " " + rs.getDate("birthday"));
}
// 释放资源
rs.close();
ps.close();
// 用完还是关闭连接了,r存在问题
con.close();
}
}
归还连接
- 归还数据库连接的方式
- 继承方式
- 装饰设计模式
- 适配器设计模式
- 动态代理方式
继承方式(行不通)
-
通过打印连接对象,发现DriverManager 获取的连接实现类是JDBC4Connection
-
那我们就可以自定义一个类,继承JDBC4Connection 这个类,重写close()方法,完成连接对象的归还
-
实现步骤
- 定义一个类,继承JDBC4Connection
- 定义Connection 连接对象和连接池容器对象的成员变量
- 通过有参构造方法完成对成员变量的赋值
- 重写close方法,将连接对象添加到池中
-
继承方式归还数据库连接存在问题
通过查看JDBC 工具类获取连接的方法发现:我们虽然自定义了一个子类,完成了归还连接的操作。但是DriverManager 获取的还是 JDBC4Connection 这个对象,并不是我们的子类对象,而我们又不能整体去修改驱动包中类的功能,所以继承方式行不通
装饰设计模式
-
装饰设计模式归还数据库连接的思想
- 我们可以自定义一个类,实现Connection 接口。这样就具备了和 JDBC4Connection 相同的行为了
- 重写 close()方法,完成连接的归还。其余功能还调用mysql 驱动包实现类原有的方法即可
-
实现步骤
-
定义一个类,实现Connection接口
-
定义 Connection 连接对象和连接池容器对象的成员变量
-
通过有参构造方法完成对成员变量的赋值
-
重写 close() 方法,将连接对象添加到池中
-
剩余方法,只需要调用mysql 驱动包的连接对象完成即可
-
在自定义的连接池中,将获取的连接对象通过自定义连接对象进行包装
package jdbc.demo02;
import java.sql.*;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.Executor;public class MyConnection2 implements Connection {
private Connection con;
List pool;public MyConnection2(Connection con, Listpool){ this.con = con; this.pool = pool; } @Override public void close() throws SQLException { pool.add(con); } @Override public Statement createStatement() throws SQLException { return con.createStatement(); } @Override public PreparedStatement prepareStatement(String sql) throws SQLException { return con.prepareStatement(sql); } @Override public CallableStatement prepareCall(String sql) throws SQLException { return con.prepareCall(sql); } @Override public String nativeSQL(String sql) throws SQLException { return con.nativeSQL(sql); } @Override public void setAutoCommit(boolean autoCommit) throws SQLException { con.setAutoCommit(autoCommit); } @Override public boolean getAutoCommit() throws SQLException { return con.getAutoCommit(); } @Override public void commit() throws SQLException { con.commit(); } @Override public void rollback() throws SQLException { con.rollback(); } @Override public boolean isClosed() throws SQLException { return con.isClosed(); } @Override public DatabaseMetaData getMetaData() throws SQLException { return con.getMetaData(); } @Override public void setReadOnly(boolean readOnly) throws SQLException { con.setReadOnly(readOnly); } @Override public boolean isReadOnly() throws SQLException { return con.isReadOnly(); } @Override public void setCatalog(String catalog) throws SQLException { con.setCatalog(catalog); } @Override public String getCatalog() throws SQLException { return con.getCatalog(); } @Override public void setTransactionIsolation(int level) throws SQLException { con.setTransactionIsolation(level); } @Override public int getTransactionIsolation() throws SQLException { return con.getTransactionIsolation(); } @Override public SQLWarning getWarnings() throws SQLException { return con.getWarnings(); } @Override public void clearWarnings() throws SQLException { con.clearWarnings(); } @Override public Statement createStatement(int resultSetType, int resultSetConcurrency) throws SQLException { return con.createStatement(resultSetType,resultSetConcurrency); } @Override public PreparedStatement prepareStatement(String sql, int resultSetType, int resultSetConcurrency) throws SQLException { return con.prepareStatement(sql,resultSetType,resultSetConcurrency); } @Override public CallableStatement prepareCall(String sql, int resultSetType, int resultSetConcurrency) throws SQLException { return con.prepareCall(sql,resultSetType,resultSetConcurrency); } @Override public Map T unwrap(Class iface) throws SQLException { return con.unwrap(iface); } @Override public boolean isWrapperFor(Class iface) throws SQLException { return con.isWrapperFor(iface); } }
// 重写getConnection方法,获取连接对象
@Override
public Connection getConnection() throws SQLException {
if(pool.size() > 0){
Connection con = pool.remove(0);
// 通过自定义的连接对原有的对象进行包装
MyConnection2 myCon = new MyConnection2(con,pool);
return myCon;
}else{
throw new RuntimeException(“连接数量已用尽”);
}
}
-
- 存在的问题
实现Connection 接口后,有大量的方法需要在自定义类中进行重写
适配器设计模式
-
思想
- 可以提供一个适配器类,实现Connection 接口,将所有的方法进行实现(除了close方法)
- 自定义连接类只需要继承这个适配器类,重写需要改进的close()方法即可
-
步骤
- 定义一个适配器类,实现Connection 接口
- 定义 Connection 连接对象的成员变量
- 通过有参构造方法完成对成员变量的赋值
- 重写所有方法(除了close),调用mysql 驱动包的连接对象完成即可
- 定义一个连接类,继承适配器类
- 定义 Connection 连接对象和连接池容器对象的成员变量,并通过有参构造进行赋值
- 重写 close()方法,完成归还连接
- 在自定义连接池中,将获取的连接对象通过自定义连接对象进行包装
public class MyConnection3 extends MyAdapter{
private Connection con;
private List pool;public MyConnection3(Connection con, Listpool){ super(con); this.con = con; this.pool = pool; } @Override public void close() throws SQLException { pool.add(con); } }
- 存在的问题
自定义连接类虽然很简洁了,但适配器还是我们自己编写的,也比较麻烦
动态代理
-
动态代理:在不改变目标对象方法的情况下对方法进行增强
-
组成
- 被代理的对象:真实的对象
- 代理对象:内存中的一个对象
-
要求:代理对象必须和被代理对象实现相同的接口
-
实现:
Proxy.newProxyInstance()-
三个参数
类加载器:和被代理对象使用相同的类加载器(对象.getClass().getClassLoader())
接口类型的Class数组:和被代理对象使用相同接口(new Class[]{接口名.class})
代理规则:完成代理增强的功能(匿名内部类方式new InvocationHandler(){})代理规则这个内部类中需要重写一个抽象方法:
invoke
invoke方法三个参数,第一个参数proxy不用管
第二个method方法对象,用来表示被代理对象中的每个方法(被代理对象的每个方法在执行前都会先经过invoke方法)
第三个参数args表示被代理对象对应的形参
-
动态代理方式归还数据库连接
-
思想
- 我们可以通过 Proxy 来完成对Connection 实现类对象的代理
- 代理过程中判断如果执行的是close方法,就将连接归还池中。如果是其他方法则调用连接对象原来的功能即可
-
步骤
- 定义一个类,实现 DataSource 接口
- 定义一个容器,用于保存多个 Connection 连接对象
- 定义静态代码块,通过 JDBC 工具类获取10个连接保存到容器中
- 重写 getConnection 方法,从容器中获取一个连接
- 通过 Proxy 代理,如果是close 方法,就将连接归还池中。如果是其他方法则调用原有功能
- 定义 getSize方法,用于获取容器的大小并返回
/*
* 动态代理方式
*/@Override
public Connection getConnection() throws SQLException {
if(pool.size() > 0){
Connection con = pool.remove(0);Connection proxyCon = (Connection) Proxy.newProxyInstance(con.getClass().getClassLoader(), new Class[]{Connection.class}, new InvocationHandler() { /* * 执行Connection实现类连接对象所有方法都会经过invoke * */ @Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { if(method.getName().equals("close")){ pool.add(con); return null; }else{ return method.invoke(con,args); } } }); return proxyCon; }else{ throw new RuntimeException("连接数量已用尽"); }}
- 存在的问题
我们自己写的连接池技术不够完善,功能也不够强大
开源数据库连接池
C3P0 数据库连接池
- 使用步骤
- 导入jar包
- 导入配置文件到src目录下
- 创建 C3P0 连接池对象
- 获取数据库连接进行使用
注意: C3P0的配置文件会自动加载,但是必须叫 c3p0-config.xml 或 c3p0-config.properties
com.mysql.jdbc.Driver
jdbc:mysql://192.168.23.129:3306/db11
root
lh密码
5
10
3000
com.mysql.jdbc.Driver
jdbc:mysql://localhost:3306/db15
root
itheima
5
8
1000
public class C3P0Test1 {
public static void main(String[] args) throws SQLException {
// 创建c3p0数据库连接池对象
DataSource dataSource = new ComboPooledDataSource();
// 通过连接池对象获取数据库连接
Connection con = dataSource.getConnection();
// 执行操作
String sql = "SELECT * FROM student";
PreparedStatement ps = con.prepareStatement(sql);
ResultSet rs = ps.executeQuery();
while(rs.next()){
System.out.println(rs.getInt("sid") + " " + rs.getString("name") + " " + rs.getInt("age") + " " + rs.getDate("birthday"));
}
// 释放资源
rs.close();
ps.close();
con.close();
}
}
Druid 数据库连接池
- 步骤
- 导入jar包
- 编写配置文件,放在src 目录下
- 通过 Properties 集合加载配置文件
- 通过 Druid 连接池工厂类获取数据库连接池对象
- 获取数据库连接进行使用
注意:Druid 不会自动加载配置文件,需要手动加载,但是文件的名称可以自定义
# Druid配置文件
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://127.0.0.1:3306/db3
username=root
password=root
# 初始化连接数量
initialSize=5
# 最大连接数量
maxActive=10
# 超时时间
maxWait=3000
package jdbc.demo04;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.IOException;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.Properties;
public class DruidTest1 {
public static void main(String[] args) throws Exception {
// 获取配置文件的流对象
InputStream is = DruidTest1.class.getClassLoader().getResourceAsStream("druid.properties");
// 加载配置文件
Properties prop = new Properties();
prop.load(is);
// 获取数据库连接池对象
DataSource dataSource = DruidDataSourceFactory.createDataSource(prop);
// 获取数据库连接
Connection con = dataSource.getConnection();
// 执行操作
String sql = "SELECT * FROM student";
PreparedStatement ps = con.prepareStatement(sql);
ResultSet rs = ps.executeQuery();
while(rs.next()){
System.out.println(rs.getInt("sid") + " " + rs.getString("name") + " " + rs.getInt("age") + " " + rs.getDate("birthday"));
}
// 释放资源
rs.close();
ps.close();
con.close();
}
}
连接池的工具类
-
私有化构造方法(不让其他人创建对象)
-
声明数据源变量
-
提供静态代码块。完成配置文件的加载以及获取数据库连接池对象
-
提供获取数据库连接的方法
-
提供获取数据库连接池对象的方法
-
释放资源
package jdbc.utils;
/*
- 数据库连接池工具类
**/
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;public class DataSourceUtils {
// 1. 私有化构造方法(不让其他人创建对象)
private DataSourceUtils(){}
// 2.声明数据源变量
private static DataSource dataSource;
// 3. 提供静态代码块。完成配置文件的加载以及获取数据库连接池对象
static {
try{
// 完成配置文件的加载
InputStream is = DataSourceUtils.class.getClassLoader().getResourceAsStream(“druid.properties”);Properties prop = new Properties(); prop.load(is); // 获取数据库连接池对象 dataSource = DruidDataSourceFactory.createDataSource(prop); }catch (Exception e){ e.printStackTrace(); } } // 4.提供获取数据库连接的方法 public static Connection getConnection(){ Connection con = null; try { con = dataSource.getConnection(); } catch (SQLException e) { e.printStackTrace(); } return con; } // 5. 提供获取数据库连接池对象的方法 public static DataSource getDataSource(){ return dataSource; } // 6. 释放资源 public static void close(Connection con, Statement stat, ResultSet rs){ if(con != null){ try { con.close(); } catch (SQLException e) { e.printStackTrace(); } } if(stat != null){ try { stat.close(); } catch (SQLException e) { e.printStackTrace(); } } if(rs != null){ try { rs.close(); } catch (SQLException e) { e.printStackTrace(); } } } public static void close(Connection con, Statement stat){ if(con != null){ try { con.close(); } catch (SQLException e) { e.printStackTrace(); } } if(stat != null){ try { stat.close(); } catch (SQLException e) { e.printStackTrace(); } } }}
/*
测试类
*/
package jdbc.demo04;import jdbc.utils.DataSourceUtils;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;public class DruidTest2 {
public static void main(String[] args) throws Exception{
// 通过连接池工具类获取数据库连接
Connection con = DataSourceUtils.getConnection();
// 执行操作
String sql = “SELECT * FROM student”;
PreparedStatement ps = con.prepareStatement(sql);
ResultSet rs = ps.executeQuery();
while(rs.next()){
System.out.println(rs.getInt(“sid”) + " " + rs.getString(“name”) + " " + rs.getInt(“age”) + " " + rs.getDate(“birthday”));
}
DataSourceUtils.close(con,ps,rs);
}
} - 数据库连接池工具类
框架
在之前的JDBC网页版案例中,定义必要的信息、获取数据库连接、释放资源都是重复的代码,我们最终的核心功能仅仅只是执行一条sql语句,所以我们可以抽取出一个 KDBC 模板类,来封装一些方法(update、query),专门帮我们执行增删改查的sql语句。将之前那些重复的操作,都抽取到模板类中的方法里,就能大大简化使用步骤
源信息
DataBaseMetaData:数据库的源信息(了解)
- java.sql.DataBaseMetaData封装了整个数据库的综合信息
例如:String getDatabaseProductName():获取数据库产品的名称int getDatabaseProductVersion():获取数据库产品的版本号
ParameterMetaData:参数的源信息
- java.sql.ParameterMetaData封装的是预编译执行者对象中每个参数的类型和属性,这个对象可以通过预编译执行者对象中的
getParameterMetaData()方法来获取 - 核心功能:
int getParameterCount()用于获取sql语句中参数的个数
ResultSetMetaData:结果集的源信息
- java.sql.ResultSetMetaData:封装的是结果集对象中列的类型和属性,这个对象可以通过结果集对象中的
getMetaData()方法来获取 - 核心功能
int getColumnCount()用于获取列的总数
String getColumnName(int i)用于获取列名
update方法
-
用于执行增删改功能的update()方法
- 定义所需成员变量(数据源、数据库连接、执行者、结果集)
- 定义有参构造,为数据源对象赋值
- 定义update()方法,参数:sql语句、sql语句所需参数
- 定义int类型变量,用于接收sql 语句执行后影响的行数
- 通过数据源获取一个数据库连接
- 通过数据库连接对象获取执行者对象并对sql语句预编译
package jdbc.demo05;
import jdbc.utils.DataSourceUtils;
import javax.sql.DataSource;
import java.sql.*;/*
-
JDBC框架类
-
*/
public class JDBCTemplate {
// 1. 定义所需成员变量(数据源、数据库连接、执行者、结果集)
private DataSource dataSource;
private Connection con;
private PreparedStatement pst;
private ResultSet rs;// 2. 定义有参构造,为数据源对象赋值
public JDBCTemplate(DataSource dataSource){
this.dataSource = dataSource;
}// 3. 定义update()方法,参数:sql语句、sql语句所需参数
public int update(String sql, Object…objs){
// 4. 定义int类型变量,用于接收sql 语句执行后影响的行数
int result = 0;
try {
// 5. 通过数据源获取一个数据库连接
con = dataSource.getConnection();
// 6. 通过数据库连接对象获取执行者对象并对sql语句预编译
pst = con.prepareStatement(sql);
// 7.通过执行者对象获取参数源信息对象
ParameterMetaData parameterMetaData = pst.getParameterMetaData();
// 8.通过源信息对象获取sql语句中的参数个数
int count = parameterMetaData.getParameterCount();// 9.判断参数数量是否一致 if(count != objs.length){ throw new RuntimeException("参数个数不匹配"); } // 10.为sql语句中问号占位符赋值 for(int i = 0; i < objs.length; i++){ pst.setObject(i+1,objs[i]); } // 11.执行sql语句并接收结果 result = pst.executeUpdate(); } catch (Exception e) { e.printStackTrace(); }finally { // 12.释放资源 DataSourceUtils.close(con,pst); } // 13.返回结果 return result;}
}
-
测试
package jdbc.demo05;
/*
-
模拟dao层 - */
import jdbc.utils.DataSourceUtils;
import org.junit.Test;public class JDBCTemplateTest1 {
private JDBCTemplate template = new JDBCTemplate(DataSourceUtils.getDataSource());@Test public void delete(){ // 删除数据测试 String sql = "DELETE FROM student WHERE name=?"; int result = template.update(sql, "周七"); if(result != 0){ System.out.println("删除成功"); }else{ System.out.println("删除失败"); } } @Test public void update(){ // 修改数据测试 String sql = "UPDATE student SET age=? WHERE name=?"; Object[] params = {37,"周七"}; int result = template.update(sql, params); if(result != 0){ System.out.println("修改成功"); }else{ System.out.println("修改失败"); } } @Test public void insert(){ // 新增数据测试 String sql = "INSERT INTO student VALUES (?,?,?,?)"; Object[] params = {null,"周七",27,"1997-07-07"}; int result = template.update(sql, params); if(result != 0){ System.out.println("添加成功"); }else{ System.out.println("添加失败"); } }}
-
查询功能
方法介绍
- 查询一条记录并封装对象的方法:
queryForObject() - 查询多条记录并封装集合的方法:
queryForList() - 查询聚合函数并返回单条数据的方法:
queryForScalar()
实体类的编写
-
定义一个类,提供一些成员变量
注意:成员变量的数据类型和名称要和表中的列保持一致private Integer sid; private String name; private Integer age; private Date birthday; // 其他就是标准类中的构造、get、set方法以及toString方法
处理结果集的接口
- 定义泛型接口
ResultSetHandler - 定义用于处理结果集的泛型方法:
T handler(ResultSet rs)
注意:此接口仅用于为不同处理结果集的方式提供规范,具体的实现类还需要自行编写
处理结果集的接口实现类BeanHandler
- 定义一个类,实现ResultSetHandler接口
- 定义Class对象类型变量
- 通过有参构造为变量赋值
- 重写handler方法。用于将一条记录封装到自定义对象中
- 声明自定义对象类型
- 创建传递参数的对象,为自定义对象赋值
- 判断结果集中是否有数据
- 通过结果集对象获取结果集源信息的对象
- 通过结果集源信息对象获取列数
- 通过循环遍历列数
- 通过结果集源信息对象获取列名
- 通过列名获取该列的数据
- 创建属性描述器对象,将获取到的值通过该对象的set方法进行赋值
- 返回封装好的对象
package jdbc.demo05.handler;
/*
实现类1:用于将查询到的一条记录,封装为Student对象并返回
*/
import java.beans.PropertyDescriptor;
import java.lang.reflect.Method;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
// 1. 定义一个类,实现ResultSetHandler接口
public class BeanHandler implements ResultSetHandler{
// 2. 定义Class对象类型变量
private Class beanClass;
// 3. 通过有参构造为变量赋值
public BeanHandler(Class beanClass){
this.beanClass = beanClass;
}
// 4. 重写handler方法。用于将一条记录封装到自定义对象中
@Override
public T handler(ResultSet rs) {
// 5. 声明自定义对象类型
T bean = null;
try {
// 6. 创建传递参数的对象,为自定义对象赋值
bean = beanClass.newInstance();
// 7. 判断结果集中是否有数据
if(rs.next()){
// 8. 通过结果集对象获取结果集源信息的对象
ResultSetMetaData metaData = rs.getMetaData();
// 9. 通过结果集源信息对象获取列数
int count = metaData.getColumnCount();
// 10. 通过循环遍历列数
for(int i = 1; i <= count; i++){
// 11. 通过结果集源信息对象获取列名
String columnName = metaData.getColumnName(i);
// 12. 通过列名获取该列的数据
Object value = rs.getObject(columnName);
// 13. 创建属性描述器对象,将获取到的值通过该对象的set方法进行赋值
PropertyDescriptor pd = new PropertyDescriptor(columnName.toLowerCase(),beanClass);
// 获取set方法
Method writeMethod = pd.getWriteMethod();
// 执行set方法,给成员变量赋值
writeMethod.invoke(bean,value);
}
}
} catch (Exception e) {
e.printStackTrace();
}
// 14. 返回封装好的对象
return bean;
}
}
用于查询一条记录并封装对象的方法 queryForObject()
/*
* 执行查询的方法:将一条记录封装成一个自定义类型对象并返回
* */
public T queryForObject(String sql, ResultSetHandler rsh, Object...objs){
T obj = null;
try {
// 通过数据源获取一个数据库连接
con = dataSource.getConnection();
// 通过数据库连接对象获取执行者对象并对sql语句预编译
pst = con.prepareStatement(sql);
// 通过执行者对象获取参数源信息对象
ParameterMetaData parameterMetaData = pst.getParameterMetaData();
// 通过源信息对象获取sql语句中的参数个数
int count = parameterMetaData.getParameterCount();
// 判断参数数量是否一致
if(count != objs.length){
throw new RuntimeException("参数个数不匹配");
}
// 为sql语句中问号占位符赋值
for(int i = 0; i < objs.length; i++){
pst.setObject(i+1,objs[i]);
}
// 执行sql语句并接收结果
rs = pst.executeQuery();
// 通过BeanHandler 方式对结果处理
obj = rsh.handler(rs);
} catch (Exception e) {
e.printStackTrace();
}finally {
// 释放资源
DataSourceUtils.close(con,pst);
}
// 返回结果
return obj;
}
@Test
public void queryForObject(){
// 查询数据测试
String sql = "SELECT * FROM student WHERE sid=?";
Student stu = template.queryForObject(sql, new BeanHandler<>(Student.class), 1);
System.out.println(stu);
}
处理结果集的接口实现类BeanListHandler
- 定义BeaanListHandler l类实现 ResultSetHandler接口
- 定义class 对象类型的变量
- 定义有参构造为变量赋值
- 重写handler方法,用于将结果集中的所有记录封装到集合中并返回
- 创建List集合对象
- 遍历结果集对象
- 创建传递参数的对象
- 通过结果集对象获取结果集的源信息对象
- 通过结果集源信息对象获取列数
- 通过循环遍历列数
- 通过结果集源信息获取列名
- 通过列名获取该列的数据
- 创建属性描述器对象,将获取到的值通过对象的set方法进行赋值
- 将封装好的对象添加到集合中
- 返回集合对象
package jdbc.demo05.handler;
/*
实现类2:用于将查询到的一条记录,封装为Student对象并添加到集合返回
*/
import java.beans.PropertyDescriptor;
import java.lang.reflect.Method;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.util.ArrayList;
import java.util.List;
// 1. 定义一个类,实现ResultSetHandler接口
public class BeanListHandler implements ResultSetHandler{
// 2. 定义Class对象类型变量
private Class beanClass;
// 3. 通过有参构造为变量赋值
public BeanListHandler(Class beanClass){
this.beanClass = beanClass;
}
// 4. 重写handler方法。用于将多条记录封装到自定义对象中并添加到集合返回
@Override
public List handler(ResultSet rs) {
// 5. 声明集合对象类型
List list = new ArrayList<>();
try {
// 6. 判断结果集中是否有数据
while(rs.next()){
// 7. 创建传递参数的对象,为自定义对象赋值
T bean = beanClass.newInstance();
// 8. 通过结果集对象获取结果集源信息的对象
ResultSetMetaData metaData = rs.getMetaData();
// 9. 通过结果集源信息对象获取列数
int count = metaData.getColumnCount();
// 10. 通过循环遍历列数
for(int i = 1; i <= count; i++){
// 11. 通过结果集源信息对象获取列名
String columnName = metaData.getColumnName(i);
// 12. 通过列名获取该列的数据
Object value = rs.getObject(columnName);
// 13. 创建属性描述器对象,将获取到的值通过该对象的set方法进行赋值
PropertyDescriptor pd = new PropertyDescriptor(columnName.toLowerCase(),beanClass);
// 获取set方法
Method writeMethod = pd.getWriteMethod();
// 执行set方法,给成员变量赋值
writeMethod.invoke(bean,value);
}
// 将对象保存到集合中
list.add(bean);
}
} catch (Exception e) {
e.printStackTrace();
}
// 14. 返回封装好的对象
return list;
}
}
queryForList实现和测试
/*
* 执行查询的方法:将多条记录封装成一个自定义类型对象并添加到集合返回
* */
public List queryForList(String sql, ResultSetHandler rsh, Object...objs){
List list = new ArrayList<>();
try {
// 通过数据源获取一个数据库连接
con = dataSource.getConnection();
// 通过数据库连接对象获取执行者对象并对sql语句预编译
pst = con.prepareStatement(sql);
// 通过执行者对象获取参数源信息对象
ParameterMetaData parameterMetaData = pst.getParameterMetaData();
// 通过源信息对象获取sql语句中的参数个数
int count = parameterMetaData.getParameterCount();
// 判断参数数量是否一致
if(count != objs.length){
throw new RuntimeException("参数个数不匹配");
}
// 为sql语句中问号占位符赋值
for(int i = 0; i < objs.length; i++){
pst.setObject(i+1,objs[i]);
}
// 执行sql语句并接收结果
rs = pst.executeQuery();
// 通过BeanListHandler 方式对结果处理
list = rsh.handler(rs);
} catch (Exception e) {
e.printStackTrace();
}finally {
// 释放资源
DataSourceUtils.close(con,pst);
}
// 返回结果
return list;
}
@Test
public void queryForList(){
// 查询数据测试
String sql = "SELECT * FROM student";
List list= template.queryForList(sql, new BeanListHandler<>(Student.class));
for(Student stu : list){
System.out.println(stu);
}
}
处理结果集的接口实现类ScalarHandler
-
定义ScalarHandler 类实现ResultSetHandler接口
-
重写handler方法,用于返回一个聚合函数的查询结果
-
定义Long类型变量
-
判断结果集对象是否有数据
-
通过结果集对象获取结果集源信息对象
-
通过结果集源信息对象获取第一列的列名
-
通过列名获取该列的数据
-
将结果返回
package jdbc.demo05.handler;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;// 1.定义ScalarHandler 类实现ResultSetHandler接口
public class ScalarHandler implements ResultSetHandler{
// 2.重写handler方法,用于返回一个聚合函数的查询结果
@Override
public Long handler(ResultSet rs) {
// 3.定义Long类型变量
Long value = null;try { // 4.判断结果集对象是否有数据 if(rs.next()){ // 5.通过结果集对象获取结果集源信息对象 ResultSetMetaData metaData = rs.getMetaData(); // 6. 获取第一列的列名 String columnName = metaData.getColumnName(1); // 7.根据列名获取该列的值 value = rs.getLong(columnName); } } catch (Exception e) { e.printStackTrace(); } // 8.返回结果 return value; }}
queryForScalar实现和测试
/*
* 执行查询的方法:将聚合函数的查询结果返回
* */
public Long queryForScalar(String sql, ResultSetHandler rsh, Object...objs){
Long value = null;
try {
// 通过数据源获取一个数据库连接
con = dataSource.getConnection();
// 通过数据库连接对象获取执行者对象并对sql语句预编译
pst = con.prepareStatement(sql);
// 通过执行者对象获取参数源信息对象
ParameterMetaData parameterMetaData = pst.getParameterMetaData();
// 通过源信息对象获取sql语句中的参数个数
int count = parameterMetaData.getParameterCount();
// 判断参数数量是否一致
if(count != objs.length){
throw new RuntimeException("参数个数不匹配");
}
// 为sql语句中问号占位符赋值
for(int i = 0; i < objs.length; i++){
pst.setObject(i+1,objs[i]);
}
// 执行sql语句并接收结果
rs = pst.executeQuery();
// 通过ScalarHandler 方式对结果处理
value = rsh.handler(rs);
} catch (Exception e) {
e.printStackTrace();
}finally {
// 释放资源
DataSourceUtils.close(con,pst);
}
// 返回结果
return value;
}
@Test
public void queryForScalar(){
// 查询聚合函数测试
String sql = "SELECT COUNT(*) FROM student";
Long value = template.queryForScalar(sql, new ScalarHandler());
System.out.println(value);
}
Mybatis
JavaScript
jQuery
AJAX
Vue + Element
Redis
Maven基础
Web项目实战-黑马页面
因为正文字数过多,后续内容请前往专栏查阅: 《Java Web从入门到实战》
先自我介绍一下,小编13年上师交大毕业,曾经在小公司待过,去过华为OPPO等大厂,18年进入阿里,直到现在。深知大多数初中级java工程师,想要升技能,往往是需要自己摸索成长或是报班学习,但对于培训机构动则近万元的学费,着实压力不小。自己不成体系的自学效率很低又漫长,而且容易碰到天花板技术停止不前。因此我收集了一份《java开发全套学习资料》送给大家,初衷也很简单,就是希望帮助到想自学又不知道该从何学起的朋友,同时减轻大家的负担。添加下方名片,即可获取全套学习资料哦