R(2+1)D理解与MindSpore框架下的实现
一、R(2+1)D算法原理介绍
论文地址:[1711.11248] A Closer Look at Spatiotemporal Convolutions for Action Recognition (arxiv.org)
Tran等人在2018年发表在CVPR 的文章《A Closer Look at Spatiotemporal Convolutions for Action Recognition》提出了R(2+1)D,表明将三位卷积核分解为独立的空间和时间分量可以显著提高精度,R(2+1)D中的卷积模块将 N × t × d × d N \times t \times d \times d N×t×d×d 的3D卷积拆分为 N × 1 × d × d N \times 1 \times d \times d N×1×d×d 的2D空间卷积和 M × t × 1 × 1 M \times t \times 1 \times 1 M×t×1×1 的1D时间卷积,其中N和M为卷积核的个数,超参数M决定了信号在空间卷积和时间卷积之间投影的中间子空间的维数,论文中将M的值设置为:
M i = ⌊ t d 2 N i − 1 N i d 2 N i − 1 + t N i ⌋ M_{i}= \left \lfloor \frac{td^{2}N_{i-1}N_{i}}{d^{2}N_{i-1}+tN_{i}} \right \rfloor Mi=⌊d2Ni−1+tNitd2Ni−1Ni⌋
i表示残差网络中第i个卷积块,通过这种方式以保证(2+1)D模块中的参数量近似于3D卷积的参数量。

与全三维卷积相比,(2+1)D分解有两个优点,首先,尽管没有改变参数的数量,但由于每个块中2D和1D卷积之间的额外激活函数,网络中的非线性数量增加了一倍,非线性数量的增加了可以表示的函数的复杂性。第二个好处在于,将3D卷积强制转换为单独的空间和时间分量,使优化变得更容易,这表现在与相同参数量的3D卷积网络相比,(2+1)D网络的训练误差更低。
下表展示了18层和34层的R3D网络的架构,在R3D中,使用(2+1)D卷积代替3D卷积就能得到对应层数的R(2+1)D网络。

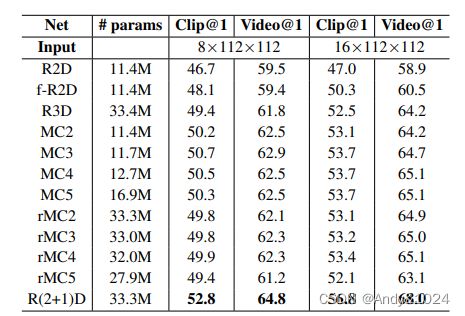
实验部分在Kinetics 上比较了不同形式的卷积的动作识别准确性,如下表所示。所有模型都基于 ResNet18,并在 8 帧或 16 帧剪辑输入上从头开始训练,结果表明R(2+1)D 的精度优于所有其他模型。
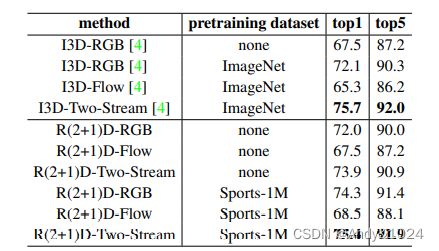
在Kinetics上与sota方法比较的结果如下表所示。当在 RGB 输入上从头开始训练时,R(2+1)D 比 I3D 高出 4.5%,在 Sports-1M 上预训练的 R(2+1)D 也比在 ImageNet 上预训练的 I3D 高 2.2%。
二、R(2+1)D的mindspore代码实现
代码仓库地址:ZJUT-ERCISS/r2plus1d_mindspore (github.com)
功能函数说明
数据预处理
-
使用GeneratorDataset读取了视频数据集文件,输出batch_size=16的指定帧数的三通道图片。
-
数据前处理包括混洗、归一化。
-
数据增强包括video_random_crop类实现的随机裁剪、video_resize类实现的调整大小、video_random_horizontal_flip实现的随机水平翻转。
模型主干
-
R2Plus1d18中,输入首先经过一个 (2+1)D卷积模块,经过一个最大池化层,之后通过4个由(2+1)D卷积模块组成的residual block,再经过平均池化层、展平层最后到全连接层。
-
最先的(2+1)D卷积模块具体为卷积核大小为(1,7,7)的Conv3d再接一个卷积核大小为(3,1,1)的Conv3d,卷积层之间是Batch Normalization和Relu层。
-
R2Plus1d18中包含4个residual block,每个block在模型中都堆叠两次,同时每个block都由两个(2+1)D卷积模块组成,每个(2+1)D卷积都由一个卷积核大小为(1,3,3)的Conv3d再接一个卷积核大小为(3,1,1)的Conv3d组成,卷积层之间仍然是Batch Normalization和Relu层,block的输入和输出之间是残差连接的结构。
具体模型搭建中各个类的作用为:
- Unit3D类实现了输入经过Conv3d、BN、Relu、Pooling层的结构,其中BN层、Relu层和Pooling层是可选的。
class Unit3D(nn.Cell):
"""
Conv3d fused with normalization and activation blocks definition.
Args:
in_channels (int): The number of channels of input frame images.
out_channels (int): The number of channels of output frame images.
kernel_size (tuple): The size of the conv3d kernel.
stride (Union[int, Tuple[int]]): Stride size for the first convolutional layer. Default: 1.
pad_mode (str): Specifies padding mode. The optional values are "same", "valid", "pad".
Default: "pad".
padding (Union[int, Tuple[int]]): Implicit paddings on both sides of the input x.
If `pad_mode` is "pad" and `padding` is not specified by user, then the padding
size will be `(kernel_size - 1) // 2` for C, H, W channel.
dilation (Union[int, Tuple[int]]): Specifies the dilation rate to use for dilated
convolution. Default: 1
group (int): Splits filter into groups, in_channels and out_channels must be divisible
by the number of groups. Default: 1.
activation (Optional[nn.Cell]): Activation function which will be stacked on top of the
normalization layer (if not None), otherwise on top of the conv layer. Default: nn.ReLU.
norm (Optional[nn.Cell]): Norm layer that will be stacked on top of the convolution
layer. Default: nn.BatchNorm3d.
pooling (Optional[nn.Cell]): Pooling layer (if not None) will be stacked on top of all the
former layers. Default: None.
has_bias (bool): Whether to use Bias.
Returns:
Tensor, output tensor.
Examples:
Unit3D(in_channels=in_channels, out_channels=out_channels[0], kernel_size=(1, 1, 1))
"""
def __init__(self,
in_channels: int,
out_channels: int,
kernel_size: Union[int, Tuple[int]] = 3,
stride: Union[int, Tuple[int]] = 1,
pad_mode: str = 'pad',
padding: Union[int, Tuple[int]] = 0,
dilation: Union[int, Tuple[int]] = 1,
group: int = 1,
activation: Optional[nn.Cell] = nn.ReLU,
norm: Optional[nn.Cell] = nn.BatchNorm3d,
pooling: Optional[nn.Cell] = None,
has_bias: bool = False
) -> None:
super().__init__()
if pad_mode == 'pad' and padding == 0:
padding = tuple((k - 1) // 2 for k in six_padding(kernel_size))
else:
padding = 0
layers = [nn.Conv3d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
pad_mode=pad_mode,
padding=padding,
dilation=dilation,
group=group,
has_bias=has_bias)
]
if norm:
layers.append(norm(out_channels))
if activation:
layers.append(activation())
self.pooling = None
if pooling:
self.pooling = pooling
self.features = nn.SequentialCell(layers)
def construct(self, x):
""" construct unit3d"""
output = self.features(x)
if self.pooling:
output = self.pooling(output)
return output
- Inflate3D类使用Unit3D实现了(2+1)D卷积模块。
class Inflate3D(nn.Cell):
"""
Inflate3D block definition.
Args:
in_channel (int): The number of channels of input frame images.
out_channel (int): The number of channels of output frame images.
mid_channel (int): The number of channels of inner frame images.
kernel_size (tuple): The size of the spatial-temporal convolutional layer kernels.
stride (Union[int, Tuple[int]]): Stride size for the second convolutional layer. Default: 1.
conv2_group (int): Splits filter into groups for the second conv layer,
in_channels and out_channels
must be divisible by the number of groups. Default: 1.
norm (Optional[nn.Cell]): Norm layer that will be stacked on top of the convolution
layer. Default: nn.BatchNorm3d.
activation (List[Optional[Union[nn.Cell, str]]]): Activation function which will be stacked
on top of the normalization layer (if not None), otherwise on top of the conv layer.
Default: nn.ReLU, None.
inflate (int): Whether to inflate two conv3d layers and with different kernel size.
Returns:
Tensor, output tensor.
Examples:
>>> from mindvision.msvideo.models.blocks import Inflate3D
>>> Inflate3D(3, 64, 64)
"""
def __init__(self,
in_channel: int,
out_channel: int,
mid_channel: int = 0,
stride: tuple = (1, 1, 1),
kernel_size: tuple = (3, 3, 3),
conv2_group: int = 1,
norm: Optional[nn.Cell] = nn.BatchNorm3d,
activation: List[Optional[Union[nn.Cell, str]]] = (nn.ReLU, None),
inflate: int = 1,
):
super(Inflate3D, self).__init__()
if not norm:
norm = nn.BatchNorm3d
self.in_channel = in_channel
if mid_channel == 0:
self.mid_channel = (in_channel * out_channel * kernel_size[1] * kernel_size[2] * 3) // \
(in_channel * kernel_size[1] * kernel_size[2] + 3 * out_channel)
else:
self.mid_channel = mid_channel
self.inflate = inflate
if self.inflate == 0:
conv1_kernel_size = (1, 1, 1)
conv2_kernel_size = (1, kernel_size[1], kernel_size[2])
elif self.inflate == 1:
conv1_kernel_size = (kernel_size[0], 1, 1)
conv2_kernel_size = (1, kernel_size[1], kernel_size[2])
elif self.inflate == 2:
conv1_kernel_size = (1, 1, 1)
conv2_kernel_size = (kernel_size[0], kernel_size[1], kernel_size[2])
self.conv1 = Unit3D(
self.in_channel,
self.mid_channel,
stride=(1, 1, 1),
kernel_size=conv1_kernel_size,
norm=norm,
activation=activation[0])
self.conv2 = Unit3D(
self.mid_channel,
self.mid_channel,
stride=stride,
kernel_size=conv2_kernel_size,
group=conv2_group,
norm=norm,
activation=activation[1])
def construct(self, x):
x = self.conv1(x)
x = self.conv2(x)
return x
- Resnet3D类实现了输入经过Unit3D、Max Pooling再接4个residual block的结构,residual block的堆叠数量可以通过参数进行指定。
class ResNet3D(nn.Cell):
"""
ResNet3D architecture.
Args:
block (Optional[nn.Cell]): THe block for network.
layer_nums (Tuple[int]): The numbers of block in different layers.
stage_channels (Tuple[int]): Output channel for every res stage.
Default: [64, 128, 256, 512].
stage_strides (Tuple[Tuple[int]]): Strides for every res stage.
Default:[[1, 1, 1],
[1, 2, 2],
[1, 2, 2],
[1, 2, 2]].
group (int): The number of Group convolutions. Default: 1.
base_width (int): The width of per group. Default: 64.
norm (nn.Cell, optional): The module specifying the normalization layer to use.
Default: None.
down_sample(nn.Cell, optional): Residual block in every resblock, it can transfer the input
feature into the same channel of output. Default: Unit3D.
kwargs (dict, optional): Key arguments for "make_res_layer" and resblocks.
Inputs:
- **x** (Tensor) - Tensor of shape :math:`(N, C_{in}, T_{in}, H_{in}, W_{in})`.
Outputs:
Tensor of shape :math:`(N, 2048, 7, 7, 7)`
Supported Platforms:
``GPU``
Examples:
>>> import numpy as np
>>> import mindspore as ms
>>> from mindvision.msvideo.models.backbones import ResNet3D, ResidualBlock3D
>>> net = ResNet(ResidualBlock3D, [3, 4, 23, 3])
>>> x = ms.Tensor(np.ones([1, 3, 16, 224, 224]), ms.float32)
>>> output = net(x)
>>> print(output.shape)
(1, 2048, 7, 7)
About ResNet:
The ResNet is to ease the training of networks that are substantially deeper than
those used previously.
The model explicitly reformulate the layers as learning residual functions with
reference to the layer inputs, instead of learning unreferenced functions.
"""
def __init__(self,
block: Optional[nn.Cell],
layer_nums: Tuple[int],
stage_channels: Tuple[int] = (64, 128, 256, 512),
stage_strides: Tuple[Tuple[int]] = ((1, 1, 1),
(1, 2, 2),
(1, 2, 2),
(1, 2, 2)),
group: int = 1,
base_width: int = 64,
norm: Optional[nn.Cell] = None,
down_sample: Optional[nn.Cell] = Unit3D,
**kwargs
) -> None:
super().__init__()
if not norm:
norm = nn.BatchNorm3d
self.norm = norm
self.in_channels = stage_channels[0]
self.group = group
self.base_with = base_width
self.down_sample = down_sample
self.conv1 = Unit3D(3, self.in_channels, kernel_size=7, stride=2, norm=norm)
self.max_pool = ops.MaxPool3D(kernel_size=3, strides=2, pad_mode='same')
self.layer1 = self._make_layer(
block,
stage_channels[0],
layer_nums[0],
stride=stage_strides[0],
norm=self.norm,
**kwargs)
self.layer2 = self._make_layer(
block,
stage_channels[1],
layer_nums[1],
stride=stage_strides[1],
norm=self.norm,
**kwargs)
self.layer3 = self._make_layer(
block,
stage_channels[2],
layer_nums[2],
stride=stage_strides[2],
norm=self.norm,
**kwargs)
self.layer4 = self._make_layer(
block,
stage_channels[3],
layer_nums[3],
stride=stage_strides[3],
norm=self.norm,
**kwargs)
def _make_layer(self,
block: Optional[nn.Cell],
channel: int,
block_nums: int,
stride: Tuple[int] = (1, 2, 2),
norm: Optional[nn.Cell] = nn.BatchNorm3d,
**kwargs):
"""Block layers."""
down_sample = None
if stride[1] != 1 or self.in_channels != channel * block.expansion:
down_sample = self.down_sample(
self.in_channels,
channel * block.expansion,
kernel_size=1,
stride=stride,
norm=norm,
activation=None)
self.stride = stride
bkwargs = [{} for _ in range(block_nums)] # block specified key word args
temp_args = kwargs.copy()
for pname, pvalue in temp_args.items():
if isinstance(pvalue, (list, tuple)):
Validator.check_equal_int(len(pvalue), block_nums, f'len({pname})')
for idx, v in enumerate(pvalue):
bkwargs[idx][pname] = v
kwargs.pop(pname)
layers = []
layers.append(
block(
self.in_channels,
channel,
stride=self.stride,
down_sample=down_sample,
group=self.group,
base_width=self.base_with,
norm=norm,
**(bkwargs[0]),
**kwargs
)
)
self.in_channels = channel * block.expansion
for i in range(1, block_nums):
layers.append(
block(self.in_channels,
channel,
stride=(1, 1, 1),
group=self.group,
base_width=self.base_with,
norm=norm,
**(bkwargs[i]),
**kwargs
)
)
return nn.SequentialCell(layers)
def construct(self, x):
"""Resnet3D construct."""
x = self.conv1(x)
x = self.max_pool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
return x
- R2Plus1dNet类继承了Resnet3D类,主要是使用了Resnet3D中的4个residual block,实现了输入经过(2+1)D、Max Pooling,再通过4个residual block,最后经过平均池化层、展平层到全连接层的结构。
class R2Plus1dNet(ResNet3D):
"""Generic R(2+1)d generator.
Args:
block (Optional[nn.Cell]): THe block for network.
layer_nums (Tuple[int]): The numbers of block in different layers.
stage_channels (Tuple[int]): Output channel for every res stage. Default: (64, 128, 256, 512).
stage_strides (Tuple[Tuple[int]]): Strides for every res stage.
Default:((1, 1, 1),
(2, 2, 2),
(2, 2, 2),
(2, 2, 2).
conv12 (nn.Cell, optional): Conv1 and conv2 config in resblock. Default: Conv2Plus1D.
base_width (int): The width of per group. Default: 64.
norm (nn.Cell, optional): The module specifying the normalization layer to use. Default: None.
num_classes(int): Number of categories in the action recognition dataset.
keep_prob(float): Dropout probability in classification stage.
kwargs (dict, optional): Key arguments for "make_res_layer" and resblocks.
Returns:
Tensor, output tensor.
Examples:
>>> from mindvision.msvideo.models.backbones.r2plus1d import *
>>> from mindvision.msvideo.models.backbones.resnet3d import ResidualBlockBase3D
>>> data = Tensor(np.random.randn(2, 3, 16, 112, 112), dtype=mindspore.float32)
>>>
>>> net = R2Plus1dNet(block=ResidualBlockBase3D, layer_nums=[2, 2, 2, 2])
>>>
>>> predict = net(data)
>>> print(predict.shape)
"""
def __init__(self,
block: Optional[nn.Cell],
layer_nums: Tuple[int],
stage_channels: Tuple[int] = (64, 128, 256, 512),
stage_strides: Tuple[Tuple[int]] = ((1, 1, 1),
(2, 2, 2),
(2, 2, 2),
(2, 2, 2)),
num_classes: int = 400,
**kwargs) -> None:
super().__init__(block=block,
layer_nums=layer_nums,
stage_channels=stage_channels,
stage_strides=stage_strides,
conv12=Conv2Plus1d,
**kwargs)
self.conv1 = nn.SequentialCell([nn.Conv3d(3, 45,
kernel_size=(1, 7, 7),
stride=(1, 2, 2),
pad_mode='pad',
padding=(0, 0, 3, 3, 3, 3),
has_bias=False),
nn.BatchNorm3d(45),
nn.ReLU(),
nn.Conv3d(45, 64,
kernel_size=(3, 1, 1),
stride=(1, 1, 1),
pad_mode='pad',
padding=(1, 1, 0, 0, 0, 0),
has_bias=False),
nn.BatchNorm3d(64),
nn.ReLU()])
self.avgpool = AdaptiveAvgPool3D((1, 1, 1))
self.flatten = nn.Flatten()
self.classifier = nn.Dense(stage_channels[-1] * block.expansion,
num_classes)
# init weights
self._initialize_weights()
def construct(self, x):
"""R2Plus1dNet construct."""
x = self.conv1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = self.flatten(x)
x = self.classifier(x)
return x
def _initialize_weights(self):
"""
Init the weight of Conv3d and Dense in the net.
"""
for _, cell in self.cells_and_names():
if isinstance(cell, nn.Conv3d):
cell.weight.set_data(init.initializer(
init.HeNormal(math.sqrt(5), mode='fan_out', nonlinearity='relu'),
cell.weight.shape, cell.weight.dtype))
if cell.bias:
cell.bias.set_data(init.initializer(
init.Zero(), cell.bias.shape, cell.bias.dtype))
elif isinstance(cell, nn.BatchNorm2d):
cell.gamma.set_data(init.initializer(
init.One(), cell.gamma.shape, cell.gamma.dtype))
cell.beta.set_data(init.initializer(
init.Zero(), cell.beta.shape, cell.beta.dtype))
- R2Plus1d18类继承了R2Plu1dNet类,主要的作用是指定residual block的堆叠次数,在此类中指定的数量即为每个block都堆叠两次。
class R2Plus1d18(R2Plus1dNet):
"""
The class of R2Plus1d-18 uses the registration mechanism to register,
need to use the yaml configuration file to call.
"""
def __init__(self, **kwargs):
super(R2Plus1d18, self).__init__(block=ResidualBlockBase3D,
layer_nums=(2, 2, 2, 2),
**kwargs)
三、代码仓库使用
克隆代码
使用如下命令克隆代码:
git clone https://github.com/ZJUT-ERCISS/r2plus1d_mindspore.git
环境准备
要运行存储库中的 python 脚本,需要按如下方式准备环境:
-
Python版本及以依赖
- python==3.7.5
- decord==0.6.0
- mindspore-gpu==1.6.1
- ml-collections==0.1.1
- numpy==1.21.5
- Pillow==9.0.1
- PyYAML==6.0
-
MindSpore框架相关信息
- MindSpore tutorials
- MindSpore Python API
可使用使用以下命令安装依赖项:
pip install -r requirements.txt
数据集准备
代码仓库使用 Kinetics400 数据集进行训练和验证。
预训练模型
预训练模型是在 kinetics400 数据集上训练,下载地址:r2plus1d18_kinetic400.ckpt
代码运行
1P训练启动:
在终端“r2plus1d_mindspore”文件夹的目录下输入命令,
bash scripts/train_standalone.sh [PROJECT_PATH] [DATA_PATH]
其中PROJECT_PATH表示项目的路径,DATA_PATH表示数据的路径。
命令示例:
bash scripts/train_standalone.sh /home/zhengs/r2plus1d_mindspore /home/publicfile/kinetics-400
使用命令tail -f train_standalone.log 查看训练日志。
1P推理启动:
在终端“r2plus1d_mindspore”文件夹的目录下输入命令,
bash scripts/eval_standalone.sh [PROJECT_PATH] [DATA_PATH] [MODEL_PATH]
其中PROJECT_PATH表示项目的路径,DATA_PATH表示数据的路径,MODEL PATH表示ckpt文件路径。
命令示例:
bash scripts/eval_standalone.sh /home/zhengs/r2plus1d_mindspore /home/publicfile/kinetics-400 scripts/r2plus1d18_kinetic400.ckpt
使用命令tail -f eval_result.log 查看训练日志。