【论文阅读/翻译笔记】Deep Snake for Real-Time Instance Segmentation
原论文标题:Deep Snake for Real-Time Instance Segmentation
原论文链接:https://arxiv.org/abs/2001.01629
翻译:张欢荣
用于实时实例分割的deep snake算法
摘要
本文提出了一种基于轮廓的实时实例分割方法——deep snake。与最近一些直接从图像回归目标边界点坐标的方法不同,deep snake使用神经网络迭代变形最初的轮廓以匹配目标边界,以学习的方式实现了snake算法的经典思想。在对轮廓进行结构化特征学习时,我们提出了在deep snake中使用循环卷积,与一般的图卷积相比,它更好地利用了轮廓的循环图结构。基于deep snake算法,本文提出了一种可以处理目标定位误差的二阶段实例分割算法:先轮廓初始化,后轮廓变形。实验表明,该方法在Cityscapes、KINS、SBD和COCO数据集上取得了良好的性能,并能在单张1080Ti GPU上以32.fps的速度处理分辨率为512×512的图像。论文代码开源于https://github.com/zju3dv/snake/。

图1. deep snake的基本思想。(a) 给定一个初始轮廓,对每个顶点提取图像特征;(b) 由于轮廓是一个循环图,因此对轮廓进行循环卷积进行特征学习,其中蓝色、黄色和绿色的节点分别表示输入特征、循环卷积核和输出特征;© 最后,在每个顶点上回归偏移量,使轮廓变形以匹配目标边界。
1. 引言
实例分割是许多计算机视觉任务的基础,如视频分析、自动驾驶和机器人抓取,这些任务均对准确性和效率有着要求。大多数前沿的实例分割方法[18,27,5,19]是在目标检测器[36]给出的边界框内进行的逐像素分割,于是分割效果可能会对边界框的检测准确性较为敏感。此外,用稠密的二值像素表示目标形状通常伴随着代价高昂的后处理。
另一种形状表示方式是目标轮廓,它是沿着目标轮廓的一组顶点。与基于像素的表示法相比,目标轮廓线不受边界框的限制,需要的参数也更少。自Kass等人[21]的开创性工作以来,这种基于轮廓的表示一直被用于图像分割,即众所周知的snake或主动轮廓。在给定初始轮廓的情况下,snake算法通过迭代优化一个以低特征(如图像亮度或梯度)定义的能量函数来不断变形轮廓以匹配目标边界。虽然许多文献[6,7,15]都提出了其各自的变体,但他们的目标函数通常是手工设计的并且是非凸的,容易出现局部最优。
最近一些基于学习的分割方法[20,42,41]也将目标表示为轮廓,并尝试从RGB图像中直接回归轮廓顶点的坐标。尽管这些方法速度很快,但大多数都不如基于像素的方法表现得好。Ling等人[25]采用传统snake算法的变形流程,训练神经网络优化初始轮廓来匹配目标边界。给定具有图像特征的轮廓,该方法将输入轮廓视为一个图,使用图卷积网络(graph convolutional network, GCN)预测轮廓顶点与目标边界顶点的坐标偏移量。与基于像素的方法相比,该方法在速度上有很大的优势。然而,文献[25]提出的方法只是为了协助标注,缺乏一个完整的自动实例分割流程。此外,将轮廓视为一般的图并不能充分利用轮廓的特殊拓扑。
在本文中,我们提出了一种基于学习的snake算法——deep snake,用于实时实例分割。受之前方法的启发[21,25],deep snake以一个初始轮廓作为输入,通过回归各顶点的偏移量对其进行变形。我们的创新之处在于引入了循环卷积,以便在轮廓上高效地学习特征,如图1所示。我们观察到轮廓是一个循环图,它由一个闭合循环中连接的顶点序列组成。因为每个顶点都有相同的度2,我们可以对顶点特征应用标准的一维卷积。由于轮廓是周期性的,deep snake引入了循环卷积,即一个非周期函数(1D核)与一个周期函数(轮廓上定义的特征)以标准的方式进行卷积。循环卷积核不仅编码每个顶点的特征,而且编码相邻顶点之间的关系。相比之下,通用GCN采用的是池化来聚合来自邻近顶点的信息。在我们的循环卷积中,核函数相当于一个可学习的聚合函数,它比使用通用的GCN更有表现力,性能也更好,正如我们在5.2节中的实验结果所证明的那样。
基于deep snake,我们开发了一个实例分割的流程。在给定初始轮廓后,deep snake可以对初始轮廓进行迭代变形以匹配目标边界,得到目标形状。剩下的问题是如何初始化轮廓,它的重要性已经在经典snake算法中得到了证明。受文献[32,29,45]的启发,我们提出生成一个由目标极点构成的八边形作为初始轮廓,该八边形通常可以将目标紧紧包围。具体来说,我们将deep snake和一个目标检测器结合在一起。目标检测器首先检测边界框,接着通过连接边界框上的各边中心点初始化一个菱形轮廓。然后deep snake将菱形作为输入,输出从菱形顶点到目标极点的偏移量,并通过偏移量根据文献[45]构造八边形。最后,deep snake迭代变形八边形轮廓以匹配目标边界。
我们的方法在Cityscapes[8],KINS[35],SBD[16]和COCO[24]数据集上展示了具有竞争力的性能,同时显现了高效的实时性,在单张GTX 1080ti GPU上处理分辨率为512×512的图像可达到32.3fps。以下两个事实使基于学习的snake能够达到快速而准确。首先,我们的方法可以处理在目标定位阶段的错误,从而允许使用轻量级探测器。其次,轮廓表示比基于像素的表示具有更少的参数,并且不需要昂贵的后处理,例如分割掩模上采样。
综上所述,本工作可总结为以下贡献:
1. 我们提出了一种用于实时实例分割的基于学习的snake算法,并引入了循环卷积对轮廓进行特征学习。
2. 我们提出了一种二阶段的实例分割流程:轮廓初始化和轮廓变形。这两个阶段都可以处理最初目标定位中产生的误差。
3. 我们在Cityscapes、KINS、SBD和COCO数据集上展示了最前沿的性能。对于分辨率为512×512的图像,我们的算法运行速度为32.3fps,对于实时应用非常有效。
2. 相关工作
2.1 基于像素的方法
大多数方法[9,23,18,27]都是在建议区域内进行像素级的实例分割,这在标准CNN中表现得特别好。一个典型的例子是Mask R-CNN[18],它首先检测目标,然后使用掩膜预测器来分割建议框中的实例。为了更好地利用边界框内的空间信息,PANet[27]融合了来自全连接层和卷积层的掩膜预测。这种基于建议框的方法实现了最前沿的性能。然而,这些方法的一个限制是它们不能解决定位错误,如太小或偏移了的边界框。相反,我们的方法使检测到的边界框变形到目标边界,因此目标形状的空间扩展将不受限制。
有一些基于像素的方法[2,31,28,12,43]是没有区域建议的。在这些方法中,每个像素产生辅助信息,然后由聚类算法根据像素的信息将其分组为目标实例。辅助信息和分组算法可以多种多样。文献[2]预测每个像素的边界感知能量,使用分水岭变换算法进行分组。文献[31]通过学习实例级嵌入来区分实例。文献[28,12]将输入图像视为一个图,回归像素关联性,然后通过图归并算法进行处理。由于掩膜是由稠密的像素组成,后聚类算法往往是耗时的。
2.2 基于轮廓的方法
在这些方法中,目标形状包含着沿目标边界的一系列顶点。传统的snake算法[21,6,7,15]首先引入了基于轮廓的表示来进行图像分割。他们通过优化以轮廓坐标手工制作的能量函数来变形目标边界的初始轮廓。为了提高这些方法的鲁棒性,文献[30]提出以数据驱动的方式学习能量函数。最近的一些基于学习的方法[20,42]没有迭代优化轮廓,而是尝试从RGB图像中回归轮廓点的坐标,速度快得多。然而,他们所得到的精确度并不能与最先进的基于像素的方法相提并论。
在半自动标注领域,文献[4,1,25]尝试使用其他网络代替标准CNN进行轮廓标注。文献[4,1]利用循环神经网络依次预测轮廓点。为了避免顺序推理,文献[25]遵循snake算法的思路,使用图卷积网络来预测轮廓变形的顶点偏移量。该策略显著提高了标注速度,同时与基于像素的方法一样精确。但是,文献[25]缺少用于实例分割的完整流程,也没有充分利用轮廓的特殊拓扑。deep snake没有将轮廓视为一般的图,而是利用了循环图的拓扑结构,引入了循环卷积来对轮廓进行有效的特征学习。
2. 方法
受文献[21,25]的启发,我们通过变形初始轮廓来匹配目标边界来进行物体分割。具体来说,deep snake以一个轮廓作为输入,并预测轮廓顶点指向目标边界的偏移量。利用骨干CNN从输入图像中提取轮廓顶点的特征。为了充分利用轮廓的拓扑结构,我们提出了循环卷积的方法来对轮廓进行有效的特征学习,便于deep snake学习变形。基于deep snake,我们开发了一个实例分割的流程。
3.1 基于学习的snake方法
给定初始轮廓,传统的snake算法将顶点的坐标视为一组变量,并针对这些变量优化一个能量函数。通过在轮廓坐标处设计合适的力,算法可以将轮廓驱动到目标边界。然而,由于能量函数通常是非凸的,并且是基于低阶图像特征手工制作的,因此优化倾向于寻找局部最优解。
相反,deep snake直接以端到端的方式学习轮廓的演化。给定一个有 N N N个顶点的轮廓 { x i ∣ i = 1 , ⋯ , N } \{x_i | i = 1, \cdots, N\} {xi∣i=1,⋯,N},我们首先为每个顶点构造特征向量。一个顶点 x i x_i xi的特征 f i f_i fi是由学习来的特征和顶点坐标合并而得: [ F ( x i ) ; x i ] [F(x_i); x_i] [F(xi);xi],其中 F F F表示特征图。特征图 F F F是由骨干CNN在输入图像上提取到的。在我们的实例分割流程中,骨干CNN与目标检测器中的CNN共享参数,这将在后面讨论。利用顶点坐标 x i x_i xi处的双线性插值计算图像特征 F ( x i ) F(x_i) F(xi)。后接的顶点坐标用于编码轮廓顶点之间的空间关系。由于变形不应受到图像中轮廓平移的影响,我们将 x i x_i xi的每个维度减去所有顶点的最小值。

图2. 循环卷积。蓝色节点为轮廓上定义的输入特征,黄色节点为核函数,绿色节点为输出特征。突出显示的绿色节点是内核函数和突出显示的蓝色节点之间的内积,这与标准的卷积相同。循环卷积的输出特征与输入特征具有相同的长度。
给定定义在轮廓上的输入特征,deep snake引入了循环卷积进行特征学习,如图2所示。一般来说,轮廓顶点的特征可以看作是一个1D离散信号 f : Z → R D f: \mathbb{Z}→\mathbb{R}^D f:Z→RD,通过标准卷积进行处理。但这打破了轮廓线的拓扑结构。因此,我们将 f f f扩展为一个周期信号,定义为:
( f N ) i ≜ ∑ j = − ∞ ∞ f i − j N (f_N)_i \triangleq \sum_{j=-\infin}^\infin f_{i-jN} (fN)i≜j=−∞∑∞fi−jN
并提出对周期特征进行循环卷积编码,定义为:
( f N ∗ k ) i = ∑ j = − r r ( f N ) i + j k j (f_N * k)_i = \sum_{j=-r}^r (f_N)_{i+j}k_j (fN∗k)i=j=−r∑r(fN)i+jkj
其中 k : [ − r , r ] → R D k: [−r, r]→\mathbb{R}^D k:[−r,r]→RD是一个可学习的核函数,算子 ∗ ∗ ∗是标准的卷积。
与标准卷积相似,我们可以在循环卷积的基础上构建网络层进行特征学习,这很容易融入到现代网络架构中。在特征学习之后,deep snake对每个顶点的输出特征应用三个1×1卷积层,预测轮廓点与目标点的顶点偏移量,用于使轮廓变形。在所有的实验中,循环卷积的核大小都固定为9。
正如引言中所讨论的,所提出的循环卷积比一般的图卷积更好地利用了轮廓的循环结构。我们将在5.2节中展示实验对比。另一种方法是使用标准CNN从输入图像中回归一个像素级别的向量场来指导初始轮廓的演化[37,33,40]。我们认为deep snake相对于标准CNN的一个重要优势是目标级别的结构化预测,即一个顶点的偏移量预测依赖于同一轮廓线的其他顶点。因此,deep snake将为远离目标的顶点预测一个更合理的偏移量。在这种情况下,标准CNN可能会有困难,因为回归到的向量场可能会驱动这个顶点到另一个更接近的目标。

图3. 提出的基于轮廓的实例分割模型。(a) deep snake由三部分组成:骨干、融合块和预测头。它以一个轮廓作为输入,并输出各顶点的偏移量来变形轮廓。(b) 基于deep snake,我们提出了实例分割的二阶段流程:轮廓初始化和轮廓变形。目标检测器得到的边界框先给出一个菱形轮廓,然后由deep snake将菱形轮廓的四个顶点移动到目标极点。基于极点构造了一个八边形。deep snake以该八边形为初始轮廓,迭代变形以匹配目标边界。
网络体系结构。图3(a)给出了详细的原理图。按照文献[34,39,22]的思路,deep snake由三部分组成:骨干、融合块和预测头。骨干由8个“CirConv-Bn-Relu”层组成,并对所有层使用残差跳跃连接,其中“CirConv”表示循环卷积。融合块的目的是在多个尺度上融合所有轮廓点的信息。它将骨干中所有层的特征合并起来,并通过1×1卷积层和最大池化。接着,将融合的特征与每个顶点的特征连接起来。预测头对顶点特征应用三个1×1卷积层,输出各顶点的偏移量。
3.2 用于实例分割的deep snake算法
图3(b)概述了本文提出的实例分割流程。我们把deep snake和目标检测器结合在一起。目标检测器首先产生用于构造菱形轮廓的目标边界框。然后,deep snake将菱形顶点移动到目标的极点上,利用极点构造八边形轮廓线。最后,deep snake以八边形作为初始轮廓,迭代轮廓变形得到目标形状。
建议的初始轮廓。大多数主动轮廓模型都需要精确的初始轮廓。由于文献[45]中提出的八边形紧密包围了目标,我们选择它作为初始轮廓,如图3(b)所示。这个八边形由四个极点组成,分别是一个目标的上、左、下、右的像素点,表示为 x i e x ∣ i = 1 , 2 , 3 , 4 {x^{ex}_i | i = 1,2,3,4} xiex∣i=1,2,3,4。对于一个被检测到的目标边界框,我们提取上、左、下、右框边缘的4个中心点,表示为 x i b b ∣ i = 1 , 2 , 3 , 4 {x^{bb}_i | i = 1,2,3,4} xibb∣i=1,2,3,4,然后将它们连接起来得到菱形轮廓。deep snake以该轮廓线为输入,输出从每个顶点 x i b b x^{bb}_i xibb到极点 x i e x x^{ex}_i xiex的四个偏移量,即 x i e x − x i b b x^{ex}_i - x^{bb}_i xiex−xibb。
在实际应用中,为了考虑更多的上下文信息,将菱形轮廓均匀上采样到40个点,deep snake相应输出40个偏移量。损失函数只监督 x i b b x^{bb}_i xibb的偏移量。
构造八边形的方法是根据顶点生成四条线段,并将它们的端点连接起来。具体来说,这四个极点定义了一个新的边界框。从每一个极点开始,一条线沿着相应的框边在两个方向上延伸1/4的边长,如果它遇到框角,则被截断。然后,将四条线段的端点连起来,形成一个八边形。
轮廓变形。首先,我们从顶点 x 1 e x x^{ex}_1 x1ex开始,沿八边形轮廓均匀采样 N N N个点。类似地,真值(ground truth, GT)轮廓是沿目标边界均匀采样 N N N个顶点生成的,并将第一个顶点定义为最接近 x 1 e x x^{ex}_1 x1ex的顶点。deep snake以初始轮廓为输入,输出从各个顶点到对应目标边界点的 N N N个偏移量。在所有实验中我们都将 N N N设为128,这样可以均匀覆盖大部分目标形状。
然而,从仅一次推理回归偏移量是非常有挑战性的,特别是对于远离目标的顶点。受文献[21,25,38]的启发,我们采用迭代优化的方式来处理这个问题。具体来说,我们的方法首先基于当前轮廓预测 N N N个偏移量,然后通过向顶点坐标添加偏移量来对轮廓进行变形。该变形轮廓可用于下次迭代。在实验中,除非另有说明,推理迭代次数设置为3次。
请注意,轮廓线是对目标的空间扩展的替代表示。通过变形初始轮廓来匹配目标边界,deep snake可以解决检测器的定位误差。

图4. 多组件的检测。给定一个目标边界框,我们执行RoIAlign来获得特征图,并使用检测器来检测组件框。
多组件的检测。一些目标由于遮挡被分成几个组件,如图4所示。但是,一个轮廓只能勾画出一个组件。为了克服这个问题,我们建议使用另一个检测器来查找目标框中的目标组件。图4显示了基本思想。具体来说,使用检测到的框,我们的方法执行RoIAlign[18]来提取一个特征图,并在特征图上添加一个检测器分支来生成组件框。对于检测到的组件,我们使用deep snake对每个组件进行分割,然后将分割结果进行合并。
4. 实现细节
训练策略。对于deep snake的训练,我们使用文献[14]中提出的平滑 l 1 \mathbb{l}_1 l1 损失来学习这两个变形过程。极点预测的损失函数定义如下:
L e x = 1 4 ∑ i = 1 4 l 1 ( x ~ i e x − x i e x ) \mathcal{L}_{ex} = \frac{1}{4}\sum_{i=1}^4\mathbb{l}_1(\widetilde{x}_i^{ex} - x_i^{ex}) Lex=41i=1∑4l1(x iex−xiex)
其中, x ~ i e x \widetilde{x}_i^{ex} x iex为预测的极点。轮廓迭代变形的损失函数定义如下:
L i t e r = 1 N ∑ i = 1 N l 1 ( x ~ i − x i g t ) \mathcal{L}_{iter} = \frac{1}{N}\sum_{i=1}^N\mathbb{l}_1(\widetilde{x}_i - x_i^{gt}) Liter=N1i=1∑Nl1(x i−xigt)
其中, x ~ i \widetilde{x}_i x i为变形的轮廓顶点, x i g t x_i^{gt} xigt为GT边界顶点。在检测部分,我们采用与原始检测模型相同的损失函数。训练细节随着数据集的变化而变化,这将在5.3节中描述。
检测器。所有实验均采用CenterNet[44]作为检测器。CenterNet将检测任务重新定义为关键点检测问题,在速度和准确性之间实现了令人印象深刻的平衡。对于目标框检测器,我们采用与CenterNet[44]相同的设置,它输出类特定的框。对于组件框检测器,采用了类不可知的CenterNet。具体地说,给定一个 H × W × C H\times W\times C H×W×C的特征图,类别不可知的CenterNet输出一个表示组件中心的 H × W × 1 H\times W\times 1 H×W×1的张量和一个表示框大小的 H × W × 2 H\times W\times 2 H×W×2的张量。
5. 实验
5.1 数据集和度量指标
Cityscapes[8]包含2,975个训练图像,500个验证图像和1,525个测试图像,具有高质量的标注。此外,它含有20k张带有粗糙标注的图片。我们使用数据集中八个语义类的平均精度(AP)来度量方法性能。
KINS[35]是为Kitti[13]数据集添加实例级语义标注后而得的数据集。该数据集用于amodal实例分割,目标是恢复完整的实例形状,即使在遮挡下。KINS由7,474张训练图像和7,517张测试图像组成。根据它的设置,我们使用数据集中七个类别的平均精度(AP)来度量方法性能。
SBD[16]重新标注了来自PASCAL VOC[10]数据集11,355幅图像的实例级边界。我们没有在PASCAL VOC上评估的原因在于它的标注包含洞,这不适合基于轮廓的方法。将SBD分为5,623张训练图像和5,732张测试图像。我们根据2010 VOC AP v o l _{vol} vol[17],AP 50 _{50} 50,AP 70 _{70} 70指标评估方法的结果,其中 A P v o l AP_{vol} APvol指阈值从0.1到0.9的AP平均值。
COCO[24]是一个最具挑战性的实例分割数据集。它由115k张训练图像、5k张验证图像和20k张测试图像组成。我们通过AP来评估方法的结果。
5.2 消融研究
我们在SBD数据集上进行了消融研究,因为它有20个语义类别,拥有全面评估处理各种目标形状的能力。我们评估了提出的三个组件,包括我们的网络架构、初始轮廓方案和循环卷积。在实验中,我们对检测器和deep snake进行了端到端的160个epoch的多尺度数据增广。学习速率从 1 e − 4 1e^{−4} 1e−4开始,在80和120个epoch时衰减一半。
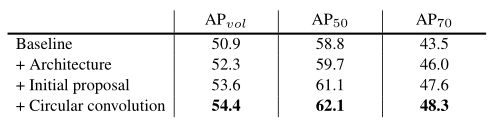
表1. 在SBD验证集上的消融研究。基线是Curve-gcn[25]和CenterNet[44]的直接组合。第二个模型保留了图卷积,用我们提出的网络结构代替了网络结构,得到1.4 AP v o l _{vol} vol的改进。然后在轮廓变形前加入初始轮廓方案,改进了1.3 AP v o l _{vol} vol。从第四行可以看出,用循环卷积代替图卷积进一步提高了0.8 AP v o l _{vol} vol。
表1总结了消融研究的结果。Baseline行列出了Curve-gcn[25]与CenterNet[44]直接组合的结果。具体地说,检测器会产生对象框,它在目标周围设置椭圆。然后,通过Graph-ResNet,椭圆向目标边界方向变形。需要注意的是,该基线方法将轮廓表示为图,采用图卷积网络进行轮廓变形。
为了验证我们网络的优势,第二行的模型保留了图卷积的卷积操作但将使用的Graph-ResNet修改为我们提出的结构,最终提升了1.4 AP v o l _{vol} vol。这两个网络结构的主要区别在于我们的结构在检测头前添加了一个全局融合块。
在研究轮廓初始化对轮廓的影响时,我们在轮廓变形前加入了初始轮廓方案。该方法不直接使用椭圆,而是通过预测物体的四个极点来生成一个八边形作为初始轮廓,这样不仅可以弥补检测误差,而且可以更紧密地包围目标。第二行和第三行之间的比较显示AP v o l _{vol} vol改进了1.3。

表2. 在SBD数据集上用不同的卷积算子和在不同迭代次数下的AP v o l _{vol} vol指标结果。在所有推理迭代中,循环卷积均优于图卷积。两次迭代的循环卷积比三次迭代的图卷积性能好0.6 AP v o l _{vol} vol,变形能力更强。我们还发现,增加更多的迭代并不一定会提高性能,这表明用更多的迭代训练网络可能会更加困难。
最后,我们用循环卷积代替图卷积,达到了0.8的AP v o l _{vol} vol改进。为了充分验证循环卷积的重要性,我们进一步比较了不同卷积算子和不同推理迭代的模型,如表2所示。在所有推理迭代中,循环卷积均优于图卷积。两次迭代的循环卷积比三次迭代的图卷积性能好0.6 AP v o l _{vol} vol。图5给出了图卷积和循环卷积在SBD上的定性结果,其中循环卷积给出了更清晰的边界。定量和定性结果表明,采用循环卷积的模型具有较强的轮廓变形能力。

图5. 在SBD数据集上使用图卷积(上)和循环卷积(下)方案的比较。两次迭代的循环卷积在视觉上优于三次迭代的图卷积。
5.3 与最前沿方法的比较
在Cityscapes上的性能。由于城市景观中碎片化实例非常普遍,因此采用了本文提出的多组件检测策略。我们的网络在多尺度增广数据上进行训练,在分辨率为1216×2432的图像上进行测试,没有使用测试技巧。检测器第一次单独训练140个epoch,学习速率从 1 e − 4 1e^{−4} 1e−4开始,在80、120个epoch时下降一半。然后检测和snake分支被端到端训练200个epoch,学习速率从 1 e − 4 1e^{−4} 1e−4开始,在80、120、150个epoch时下降一半。我们选择在验证集上表现最好的模型。

表3. 在Cityscapes验证集(AP [val]列)和测试集(剩余列)上的结果。我们的方法实现了最先进的性能,在验证集上比PANet[27]高出0.9 AP,在测试集上高出1.3 AP 50 _{50} 50。就推理速度而言,我们的方法大约比PANet快5倍。其它方法的定时结果均来自文献[31]。
表3将我们的结果与其他最前沿方法在Cityscapes验证集和测试集上进行了比较,所有的方法都没有使用测试技巧。只使用精细的注释,我们的方法在验证和测试集上都达到了最先进的性能。我们在验证集上比PANet好0.9个AP,在测试集上比PANet好1.3个AP 50 _{50} 50。在不采用碎片实例处理策略的情况下,我们的方法在测试集上达到了28.2 AP。可视化的结果如图6所示。
图6. 在Cityscapes和KINS测试集上的定性结果。前两行展示了Cityscapes上的结果,最后一行列出了KINS上的结果。注意KINS上的结果是amodal实例分割。
在KINS上的性能。KINS数据集用于一个非模态实例分割,其中目标都标注为单组件,因此不采用多组件检测策略。我们把探测器和snake从头到尾训练了150个epoch。学习速率从 1 e − 4 1e^{−4} 1e−4开始,在80和120个epoch时分别以0.5和0.1衰减。我们在768×2496的单分辨率下对模型进行多尺度训练和测试。

表4. 在KINS测试集上的AP结果。在检测任务中,使用amodal边界框作为GT边界框。 × \times ×表示对应方法中没有这样的输出。
表4展示了和文献[9,23,11,18,27]在KINS数据集上的AP结果比较。我们在所有方法中达到了最佳性能。我们发现snake分支能够改善检测性能。当单独训练CenterNet时,它在检测上获得30.5 AP。当使用snake分支进行训练时,其性能提高了2.3 AP。对于KINS数据集上分辨率为768×2496的图像,我们的方法在1080 Ti GPU上运行速度为7.6 fps。图6显示了一些关于KINS的定性结果。
在SBD上的性能。由于SBD上目标的标注大多是单组件的,所以没有采用多组件检测策略。对于碎片实例,我们的方法是单独检测它们的组件,而不是检测整个目标。我们对检测和snake分支进行了150个epoch的端到端多尺度数据增广训练。学习速率从 1 e − 4 1e^{−4} 1e−4开始,在80和120个epoch时下降一半。该网络在512×512的单尺度下进行测试。

表5. 在SBD验证集上的结果。我们的方法大大优于其他基于轮廓的方法。AP随着IoU阈值增加而提升(AP 50 _{50} 50:21.4;AP 70 _{70} 70:36.2)。
在表5中,我们在SBD数据集上就VOC AP指标与其他基于轮廓的方法进行了比较[20,42]。文献[20,42]通过回归形状向量预测物体轮廓。STS[20]将物体轮廓定义为径向向量,ESE[42]用切比雪夫多项式近似目标轮廓。我们的性能至少比这些方法高出19.1 AP v o l _{vol} vol。注意,我们的方法得到了21.4 AP 50 _{50} 50和36.2 AP 70 _{70} 70的改进,这说明改进随着IoU阈值的减小而增加。这表明我们的方法可以更精确地勾画出目标的边界。

表6. 在COCO上与其他实时方法的比较。
在COCO上的性能。与SBD上的实验相似,没有采用多组件检测策略。使用多尺度数据增广训练网络,并在原始图像分辨率下进行测试,不使用任何技巧(如翻转增广)。检测和snake分支端到端训练160个epoch,其中检测器用文献[44]发布的预训练模型初始化。学习速率从 1 e − 4 1e^{−4} 1e−4开始,在80和120个epoch时下降一半。我们最后选择一个在验证集上表现最好的模型。表6将我们的方法与其他实时方法进行了比较。我们的方法在COCO test-dev集上以27.2 fps实现了30.3 segm AP和33.2 bbox AP。
5.4 运行时间

表7. 在PASCAL VOC数据集上的运行时间。“MS”代表Mask R-CNN[18],“OURS”代表我们的方法。最后三个方法为基于轮廓的方法。
表7比较了我们的方法和其他方法[9,23,18,20,42]在PASCAL VOC数据集上的运行时间。由于SBD与PASCAL VOC数据集共享图像,因此SBD数据集上的运行时间在技术上与PASCAL VOC上的运行时间相同。我们从文献[42]中获得其他方法的运行时间。
对于SBD数据集上分辨率为512×512的图像,我们的算法在Intel i7 3.7GHz和GTX 1080 Ti GPU上以32.3 fps的速度运行,对于实时实例分割非常有效。其中,CenterNet花费了18.4 ms,轮廓初始化花费了3.1 ms,每次迭代轮廓变形花费3.3 ms。因为我们的方法输出的是目标边界,所以不需要诸如上采样这样的后处理。如果采用多组件检测策略,检测器额外需要3.6 ms。
6. 结论
我们提出了一种基于学习的snake算法用于实时实例分割,该算法引入了循环卷积来有效地学习轮廓上的特征,并对轮廓变形的顶点偏移量进行了回归。在deep snake算法的基础上,我们开发了一个二阶段实例分割流程:轮廓初始化和轮廓变形。文章表明,该流程获得了优于直接回归目标边界点坐标的性能。为了克服轮廓表示只能勾画出一个连通组件的局限性,我们提出了多组件检测策略,并通过Cityscapes数据集验证了该策略的有效性。该模型在Cityscapes、Kins、Sbd和COCO数据集上均取得了较好的实时性结果。
参考文献
[1] David Acuna, Huan Ling, Amlan Kar, and Sanja Fidler. Efficient interactive annotation of segmentation datasets with polygon-rnn++. In CVPR, 2018.
[2] Min Bai and Raquel Urtasun. Deep watershed transform for instance segmentation. In CVPR, 2017.
[3] Daniel Bolya, Chong Zhou, Fanyi Xiao, and Y ong Jae Lee. Yolact: real-time instance segmentation. In ICCV, 2019.
[4] Lluis Castrejon, Kaustav Kundu, Raquel Urtasun, and Sanja Fidler. Annotating object instances with a polygon-rnn. In CVPR, 2017.
[5] Kai Chen, Jiangmiao Pang, Jiaqi Wang, Y u Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, Ziwei Liu, Jianping Shi, Wanli Ouyang, et al. Hybrid task cascade for instance segmentation. In CVPR, 2019.
[6] Laurent D Cohen. On active contour models and balloons. CVGIP: Image understanding, 53(2):211–218, 1991.
[7] Timothy F Cootes, Christopher J Taylor, David H Cooper, and Jim Graham. Active shape models-their training and application. CVIU, 61(1):38–59, 1995.
[8] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. In CVPR, 2016.
[9] Jifeng Dai, Kaiming He, and Jian Sun. Instance-aware semantic segmentation via multi-task network cascades. In CVPR, 2016.
[10] Mark Everingham, Luc V an Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge. IJCV, 88(2):303–338, 2010.
[11] Patrick Follmann, Rebecca Kö Nig, Philipp Hä Rtinger, Michael Klostermann, and Tobias Bö Ttger. Learning to see the invisible: End-to-end trainable amodal instance segmentation. In WACV, 2019.
[12] Naiyu Gao, Yanhu Shan, Y upei Wang, Xin Zhao, Yinan Y u, Ming Yang, and Kaiqi Huang. Ssap: Single-shot instance segmentation with affinity pyramid. In ICCV, 2019.
[13] Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset. IJRR, 32(11):1231–1237, 2013.
[14] Ross Girshick. Fast r-cnn. In ICCV, 2015.
[15] Steve R Gunn and Mark S Nixon. A robust snake implementation; a dual active contour. PAMI, 19(1):63–68, 1997.
[16] Bharath Hariharan, Pablo Arbeláez, Lubomir Bourdev, Subhransu Maji, and Jitendra Malik. Semantic contours from inverse detectors. In ICCV, 2011.
[17] Bharath Hariharan, Pablo Arbeláez, Ross Girshick, and Jitendra Malik. Simultaneous detection and segmentation. In ECCV, 2014.
[18] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. In ICCV, 2017.
[19] Zhaojin Huang, Lichao Huang, Y ongchao Gong, Chang Huang, and Xinggang Wang. Mask scoring r-cnn. In CVPR, 2019.
[20] Saumya Jetley, Michael Sapienza, Stuart Golodetz, and Philip HS Torr. Straight to shapes: Real-time detection of encoded shapes. In CVPR, 2017.
[21] Michael Kass, Andrew Witkin, and Demetri Terzopoulos. Snakes: Active contour models. IJCV, 1(4):321–331, 1988.
[22] Guohao Li, Matthias Müller, Ali Thabet, and Bernard Ghanem. Can gcns go as deep as cnns? In ICCV, 2019.
[23] Yi Li, Haozhi Qi, Jifeng Dai, Xiangyang Ji, and Yichen Wei. Fully convolutional instance-aware semantic segmentation. In CVPR, 2017.
[24] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014.
[25] Huan Ling, Jun Gao, Amlan Kar, Wenzheng Chen, and Sanja Fidler. Fast interactive object annotation with curve-gcn. In CVPR, 2019.
[26] Shu Liu, Jiaya Jia, Sanja Fidler, and Raquel Urtasun. Sgn: Sequential grouping networks for instance segmentation. In ICCV, 2017.
[27] Shu Liu, Lu Qi, Haifang Qin, Jianping Shi, and Jiaya Jia. Path aggregation network for instance segmentation. In CVPR, 2018.
[28] Yiding Liu, Siyu Yang, Bin Li, Wengang Zhou, Jizheng Xu, Houqiang Li, and Yan Lu. Affinity derivation and graph merge for instance segmentation. In ECCV, 2018.
[29] Kevis-Kokitsi Maninis, Sergi Caelles, Jordi Pont-Tuset, and Luc V an Gool. Deep extreme cut: From extreme points to object segmentation. In CVPR, 2018.
[30] Diego Marcos, Devis Tuia, Benjamin Kellenberger, Lisa Zhang, Min Bai, Renjie Liao, and Raquel Urtasun. Learning deep structured active contours end-to-end. In CVPR, 2018.
[31] Davy Neven, Bert De Brabandere, Marc Proesmans, and Luc V an Gool. Instance segmentation by jointly optimizing spatial embeddings and clustering bandwidth. In CVPR, 2019.
[32] Dim P Papadopoulos, Jasper RR Uijlings, Frank Keller, and Vittorio Ferrari. Extreme clicking for efficient object annotation. In ICCV, 2017.
[33] Sida Peng, Y uan Liu, Qixing Huang, Xiaowei Zhou, and Hujun Bao. Pvnet: Pixel-wise voting network for 6dof pose estimation. In CVPR, 2019.
[34] Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. In CVPR, 2017.
[35] Lu Qi, Li Jiang, Shu Liu, Xiaoyong Shen, and Jiaya Jia. Amodal instance segmentation with kins dataset. In CVPR, 2019.
[36] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In NeurIPS, 2015.
[37] Christian Rupprecht, Elizabeth Huaroc, Maximilian Baust, and Nassir Navab. Deep active contours. arXiv preprint arXiv:1607.05074, 2016.
[38] Nanyang Wang, Yinda Zhang, Zhuwen Li, Yanwei Fu, Wei Liu, and Y u-Gang Jiang. Pixel2mesh: Generating 3d mesh models from single rgb images. In ECCV, 2018.
[39] Y ue Wang, Y ongbin Sun, Ziwei Liu, Sanjay E Sarma, Michael M Bronstein, and Justin M Solomon. Dynamic graph cnn for learning on point clouds. TOG, 2018.
[40] Zian Wang, David Acuna, Huan Ling, Amlan Kar, and Sanja Fidler. Object instance annotation with deep extreme level set evolution. In CVPR, 2019.
[41] Enze Xie, Peize Sun, Xiaoge Song, Wenhai Wang, Xuebo Liu, Ding Liang, Chunhua Shen, and Ping Luo. Polarmask: Single shot instance segmentation with polar representation. In CVPR, 2020.
[42] Wenqiang Xu, Haiyang Wang, Fubo Qi, and Cewu Lu. Explicit shape encoding for real-time instance segmentation. In ICCV, 2019.
[43] Ze Yang, Yinghao Xu, Han Xue, Zheng Zhang, Raquel Urtasun, Liwei Wang, Stephen Lin, and Han Hu. Dense reppoints: Representing visual objects with dense point sets. arXiv preprint arXiv:1912.11473, 2019.
[44] Xingyi Zhou, Dequan Wang, and Philipp Krähenbühl. Objects as points. arXiv preprint arXiv:1904.07850, 2019.
[45] Xingyi Zhou, Jiacheng Zhuo, and Philipp Krahenbuhl. Bottom-up object detection by grouping extreme and center points. In CVPR, 2019.