Transformer(需修改)
Transformer是编码器-解码器架构的一个实践,尽管在实际情况中编码器或解码器可以单独使用。
在Transformer中,多头自注意力用于表示输入序列和输出序列,不过解码器必须通过掩蔽机制来保留自回归属性。
Transformer中的残差连接和层规范化是训练非常深度模型的重要工具。
Transformer模型中基于位置的前馈网络使用同一个多层感知机,作用是对所有序列位置的表示进行转换。
自注意力和位置编码(比较卷积神经网络、循环神经网络和自注意力)_流萤数点的博客-CSDN博客中比较了卷积神经网络(CNN)、循环神经网络(RNN)和自注意力(self-attention)。值得注意的是,自注意力同时具有并行计算和最短的最大路径长度这两个优势。因此,使用自注意力来设计深度架构是很有吸引力的。对比之前仍然依赖循环神经网络实现输入表示的自注意力模型 (Cheng et al., 2016, Lin et al., 2017, Paulus et al., 2017),Transformer模型完全基于注意力机制,没有任何卷积层或循环神经网络层 (Vaswani et al., 2017)。尽管Transformer最初是应用于在文本数据上的序列到序列学习,但现在已经推广到各种现代的深度学习中,例如语言、视觉、语音和强化学习领域。
1.模型
Transformer作为编码器-解码器架构的一个实例,其整体架构图在 图10.7.1中展示。正如所见到的,Transformer是由编码器和解码器组成的。与 图10.4.1中基于Bahdanau注意力实现的序列到序列的学习相比,Transformer的编码器和解码器是基于自注意力的模块叠加而成的,源(输入)序列和目标(输出)序列的嵌入(embedding)表示将加上位置编码(positional encoding),再分别输入到编码器和解码器中。
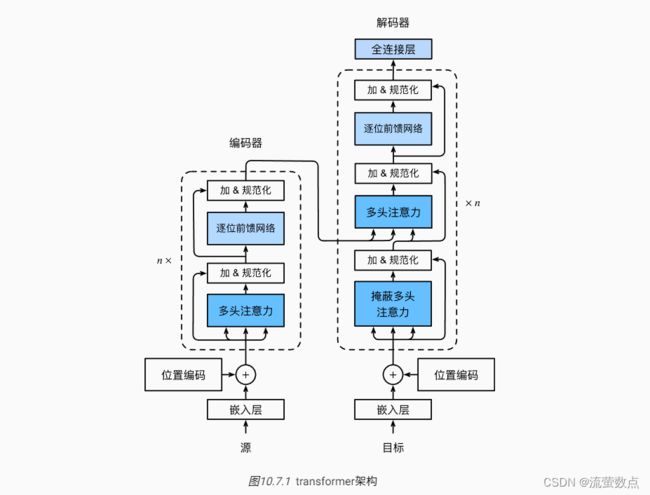
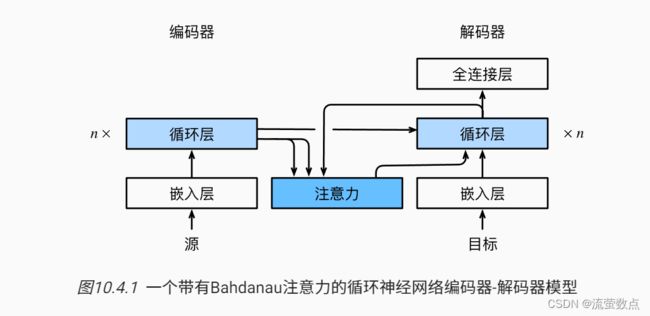 图 图10.7.1中概述了Transformer的架构。从宏观角度来看,Transformer的编码器是由多个相同的层叠加而成的,每个层都有两个子层(子层表示为sublayer)。第一个子层是多头自注意力(multi-head self-attention)汇聚;第二个子层是基于位置的前馈网络(positionwise feed-forward network)。具体来说,在计算编码器的自注意力时,查询、键和值都来自前一个编码器层的输出。受 7.6节中残差网络的启发,每个子层都采用了残差连接(residual connection)。
图 图10.7.1中概述了Transformer的架构。从宏观角度来看,Transformer的编码器是由多个相同的层叠加而成的,每个层都有两个子层(子层表示为sublayer)。第一个子层是多头自注意力(multi-head self-attention)汇聚;第二个子层是基于位置的前馈网络(positionwise feed-forward network)。具体来说,在计算编码器的自注意力时,查询、键和值都来自前一个编码器层的输出。受 7.6节中残差网络的启发,每个子层都采用了残差连接(residual connection)。
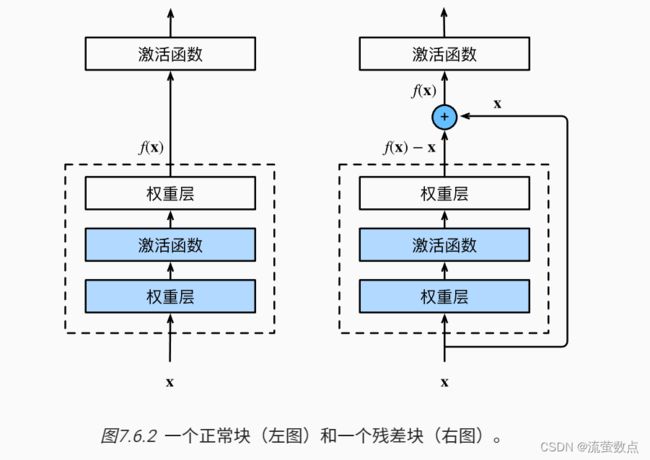
在Transformer中,对于序列中任何位置的任何输入x∈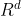 ,都要求满足sublayer(x)∈,以便残差连接满足x+sublayer(x)∈。在残差连接的加法计算之后,紧接着应用层规范化(layer normalization) (Ba et al., 2016)。因此,输入序列对应的每个位置,Transformer编码器都将输出一个d维表示向量。
,都要求满足sublayer(x)∈,以便残差连接满足x+sublayer(x)∈。在残差连接的加法计算之后,紧接着应用层规范化(layer normalization) (Ba et al., 2016)。因此,输入序列对应的每个位置,Transformer编码器都将输出一个d维表示向量。
Transformer解码器也是由多个相同的层叠加而成的,并且层中使用了残差连接和层规范化。除了编码器中描述的两个子层之外,解码器还在这两个子层之间插入了第三个子层,称为编码器-解码器注意力(encoder-decoder attention)层。在编码器-解码器注意力中,查询来自前一个解码器层的输出,而键和值来自整个编码器的输出。在解码器自注意力中,查询、键和值都来自上一个解码器层的输出。但是,解码器中的每个位置只能考虑该位置之前的所有位置。这种掩蔽(masked)注意力保留了自回归(auto-regressive)属性,确保预测仅依赖于已生成的输出词元。
在此之前已经描述并实现了基于缩放点积多头注意力 多头注意力_流萤数点的博客-CSDN博客和位置编码 自注意力和位置编码(比较卷积神经网络、循环神经网络和自注意力)_流萤数点的博客-CSDN博客。
pip install mxnet==1.7.0.post1pip install d2l==0.15.0import math
import pandas as pd
from mxnet import autograd, np, npx
from mxnet.gluon import nn
from d2l import mxnet as d2l
npx.set_np()#@save
def masked_softmax(X, valid_lens):
"""通过在最后一个轴上掩蔽元素来执行softmax操作"""
# X:3D张量,valid_lens:1D或2D张量
if valid_lens is None:
return npx.softmax(X)
else:
shape = X.shape
if valid_lens.ndim == 1:
valid_lens = valid_lens.repeat(shape[1])
else:
valid_lens = valid_lens.reshape(-1)
# 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0
X = npx.sequence_mask(X.reshape(-1, shape[-1]), valid_lens, True,
value=-1e6, axis=1)
return npx.softmax(X).reshape(shape)masked_softmax(np.random.uniform(size=(2, 2, 4)), np.array([2, 3]))
array([[[0.488994 , 0.511006 , 0. , 0. ], [0.4365484 , 0.56345165, 0. , 0. ]], [[0.288171 , 0.3519408 , 0.3598882 , 0. ], [0.29034296, 0.25239873, 0.45725837, 0. ]]])
#@save
class DotProductAttention(nn.Block):
"""缩放点积注意力"""
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# queries的形状:(batch_size,查询的个数,d)
# keys的形状:(batch_size,“键-值”对的个数,d)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
# valid_lens的形状:(batch_size,)或者(batch_size,查询的个数)
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[-1]
# 设置transpose_b=True为了交换keys的最后两个维度
scores = npx.batch_dot(queries, keys, transpose_b=True) / math.sqrt(d)
self.attention_weights = masked_softmax(scores, valid_lens)
return npx.batch_dot(self.dropout(self.attention_weights), values)queries, keys = np.random.normal(0, 1, (2, 1, 2)), np.ones((2, 10, 2))
# values的小批量数据集中,两个值矩阵是相同的
values = np.arange(40).reshape(1, 10, 4).repeat(2, axis=0)
valid_lens = np.array([2, 6])
attention = DotProductAttention(dropout=0.5)
attention.initialize()
attention(queries, keys, values, valid_lens)
array([[[ 2. , 3. , 4. , 5. ]], [[10. , 11. , 12.000001, 13. ]]])
#@save
class MultiHeadAttention(nn.Block):
"""多头注意力"""
def __init__(self, num_hiddens, num_heads, dropout, use_bias=False,
**kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = d2l.DotProductAttention(dropout)
self.W_q = nn.Dense(num_hiddens, use_bias=use_bias, flatten=False)
self.W_k = nn.Dense(num_hiddens, use_bias=use_bias, flatten=False)
self.W_v = nn.Dense(num_hiddens, use_bias=use_bias, flatten=False)
self.W_o = nn.Dense(num_hiddens, use_bias=use_bias, flatten=False)
def forward(self, queries, keys, values, valid_lens):
# queries,keys,values的形状:
# (batch_size,查询或者“键-值”对的个数,num_hiddens)
# valid_lens 的形状:
# (batch_size,)或(batch_size,查询的个数)
# 经过变换后,输出的queries,keys,values 的形状:
# (batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
if valid_lens is not None:
# 在轴0,将第一项(标量或者矢量)复制num_heads次,
# 然后如此复制第二项,然后诸如此类。
valid_lens = valid_lens.repeat(self.num_heads, axis=0)
# output的形状:(batch_size*num_heads,查询的个数,
# num_hiddens/num_heads)
output = self.attention(queries, keys, values, valid_lens)
# output_concat的形状:(batch_size,查询的个数,num_hiddens)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat)#@save
def transpose_qkv(X, num_heads):
"""为了多注意力头的并行计算而变换形状"""
# 输入X的形状:(batch_size,查询或者“键-值”对的个数,num_hiddens)
# 输出X的形状:(batch_size,查询或者“键-值”对的个数,num_heads,
# num_hiddens/num_heads)
X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
# 输出X的形状:(batch_size,num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
X = X.transpose(0, 2, 1, 3)
# 最终输出的形状:(batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
return X.reshape(-1, X.shape[2], X.shape[3])
#@save
def transpose_output(X, num_heads):
"""逆转transpose_qkv函数的操作"""
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
X = X.transpose(0, 2, 1, 3)
return X.reshape(X.shape[0], X.shape[1], -1)num_hiddens, num_heads = 100, 5
attention = MultiHeadAttention(num_hiddens, num_heads, 0.5)
attention.initialize()
batch_size, num_queries = 2, 4
num_kvpairs, valid_lens = 6, np.array([3, 2])
X = np.ones((batch_size, num_queries, num_hiddens))
Y = np.ones((batch_size, num_kvpairs, num_hiddens))
attention(X, Y, Y, valid_lens).shape(2, 4, 100)
#自注意力
num_hiddens, num_heads = 100, 5
attention = d2l.MultiHeadAttention(num_hiddens, num_heads, 0.5)
attention.initialize()
batch_size, num_queries, valid_lens = 2, 4, np.array([3, 2])
X = np.ones((batch_size, num_queries, num_hiddens))
attention(X, X, X, valid_lens).shape(2, 4, 100)
接下来将实现Transformer模型的剩余部分。
2.基于位置的前馈网络
基于位置的前馈网络对序列中的所有位置的表示进行变换时使用的是同一个多层感知机(MLP),这就是称前馈网络是基于位置的(positionwise)的原因。在下面的实现中,输入X的形状(批量大小,时间步数或序列长度,隐单元数或特征维度)将被一个两层的感知机转换成形状为(批量大小,时间步数,ffn_num_outputs)的输出张量。
#@save
class PositionWiseFFN(nn.Block):
"""基于位置的前馈网络"""
def __init__(self, ffn_num_hiddens, ffn_num_outputs, **kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.dense1 = nn.Dense(ffn_num_hiddens, flatten=False,
activation='relu')
self.dense2 = nn.Dense(ffn_num_outputs, flatten=False)
def forward(self, X):
return self.dense2(self.dense1(X))下面的例子显示,改变张量的最里层维度的尺寸,会改变成基于位置的前馈网络的输出尺寸。因为用同一个多层感知机对所有位置上的输入进行变换,所以当所有这些位置的输入相同时,它们的输出也是相同的。
ffn = PositionWiseFFN(4, 8)
ffn.initialize()
ffn(np.ones((2, 3, 4)))[0]
array([[ 0.00239431, 0.00927085, -0.00021069, -0.00923989, -0.0082903 ,
-0.00162741, 0.00659031, 0.00023905],
[ 0.00239431, 0.00927085, -0.00021069, -0.00923989, -0.0082903 ,
-0.00162741, 0.00659031, 0.00023905],
[ 0.00239431, 0.00927085, -0.00021069, -0.00923989, -0.0082903 ,
-0.00162741, 0.00659031, 0.00023905]])
加入多头注意力和自注意力代码后,结果发生变化
array([[-0.00287785, 0.00498407, 0.00187507, 0.00638567, -0.00288809,
-0.00211326, -0.00631514, 0.00674991],
[-0.00287785, 0.00498407, 0.00187507, 0.00638567, -0.00288809,
-0.00211326, -0.00631514, 0.00674991],
[-0.00287785, 0.00498407, 0.00187507, 0.00638567, -0.00288809,
-0.00211326, -0.00631514, 0.00674991]])
3.残差连接和层规范化
现在让我们关注 图10.7.1中的加法和规范化(add&norm)组件。正如在本节开头所述,这是由残差连接和紧随其后的层规范化组成的。两者都是构建有效的深度架构的关键。
7.5节中解释了在一个小批量的样本内基于批量规范化对数据进行重新中心化和重新缩放的调整。层规范化和批量规范化的目标相同,但层规范化是基于特征维度进行规范化。尽管批量规范化在计算机视觉中被广泛应用,但在自然语言处理任务中(输入通常是变长序列)批量规范化通常不如层规范化的效果好。
在模型训练过程中,批量规范化利用小批量的均值和标准差,不断调整神经网络的中间输出,使整个神经网络各层的中间输出值更加稳定。
批量规范化在全连接层和卷积层的使用略有不同。
批量规范化层和暂退层一样,在训练模式和预测模式下计算不同。
批量规范化有许多有益的副作用,主要是正则化。另一方面,”减少内部协变量偏移“的原始动机似乎不是一个有效的解释。
以下代码对比不同维度的层规范化和批量规范化的效果。
ln = nn.LayerNorm()
ln.initialize()
bn = nn.BatchNorm()
bn.initialize()
X = np.array([[1, 2], [2, 3]])
# 在训练模式下计算X的均值和方差
with autograd.record():
print('层规范化:', ln(X), '\n批量规范化:', bn(X))层规范化: [[-0.99998 0.99998] [-0.99998 0.99998]] 批量规范化: [[-0.99998 -0.99998] [ 0.99998 0.99998]]
现在可以使用残差连接和层规范化来实现AddNorm类。暂退法(dropout)也被作为正则化方法使用。
#@save
class AddNorm(nn.Block):
"""残差连接后进行层规范化"""
def __init__(self, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm()
def forward(self, X, Y):
return self.ln(self.dropout(Y) + X)残差连接要求两个输入的形状相同,以便加法操作后输出张量的形状相同。
add_norm = AddNorm(0.5)
add_norm.initialize()
add_norm(np.ones((2, 3, 4)), np.ones((2, 3, 4))).shape(2, 3, 4)
4.编码器
有了组成Transformer编码器的基础组件,现在可以先实现编码器中的一个层。下面的EncoderBlock类包含两个子层:多头自注意力和基于位置的前馈网络,这两个子层都使用了残差连接和紧随的层规范化。
#@save
class EncoderBlock(nn.Block):
"""Transformer编码器块"""
def __init__(self, num_hiddens, ffn_num_hiddens, num_heads, dropout,
use_bias=False, **kwargs):
super(EncoderBlock, self).__init__(**kwargs)
self.attention = d2l.MultiHeadAttention(
num_hiddens, num_heads, dropout, use_bias)
self.addnorm1 = AddNorm(dropout)
self.ffn = PositionWiseFFN(ffn_num_hiddens, num_hiddens)
self.addnorm2 = AddNorm(dropout)
def forward(self, X, valid_lens):
Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))
return self.addnorm2(Y, self.ffn(Y))正如从代码中所看到的,Transformer编码器中的任何层都不会改变其输入的形状。
X = np.ones((2, 100, 24))
valid_lens = np.array([3, 2])
encoder_blk = EncoderBlock(24, 48, 8, 0.5)
encoder_blk.initialize()
encoder_blk(X, valid_lens).shape(2, 100, 24)
下面实现的Transformer编码器的代码中,堆叠了num_layers个EncoderBlock类的实例。由于这里使用的是值范围在−1和1之间的固定位置编码,因此通过学习得到的输入的嵌入表示的值需要先乘以嵌入维度的平方根进行重新缩放,然后再与位置编码相加。
#@save
class TransformerEncoder(d2l.Encoder):
"""Transformer编码器"""
def __init__(self, vocab_size, num_hiddens, ffn_num_hiddens,
num_heads, num_layers, dropout, use_bias=False, **kwargs):
super(TransformerEncoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for _ in range(num_layers):
self.blks.add(
EncoderBlock(num_hiddens, ffn_num_hiddens, num_heads, dropout,
use_bias))
def forward(self, X, valid_lens, *args):
# 因为位置编码值在-1和1之间,
# 因此嵌入值乘以嵌入维度的平方根进行缩放,
# 然后再与位置编码相加。
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self.attention_weights = [None] * len(self.blks)
for i, blk in enumerate(self.blks):
X = blk(X, valid_lens)
self.attention_weights[
i] = blk.attention.attention.attention_weights
return X下面我们指定了超参数来创建一个两层的Transformer编码器。 Transformer编码器输出的形状是(批量大小,时间步数目,num_hiddens)。
encoder = TransformerEncoder(200, 24, 48, 8, 2, 0.5)
encoder.initialize()
encoder(np.ones((2, 100)), valid_lens).shape 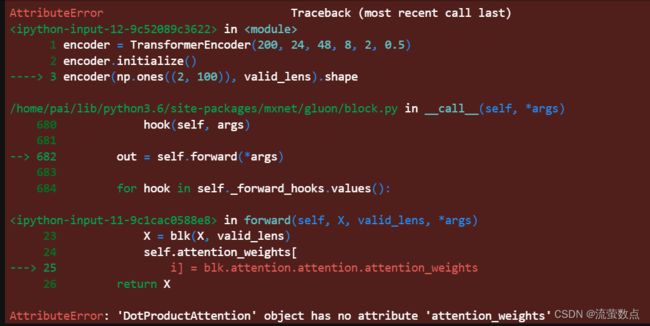
报错, 发现没有DotProductAttention代码,检查后在最开始加入了缩放点积、多头注意力和自注意力代码块,然后还是报这个错,。。。
5.解码器
如 图10.7.1所示,Transformer解码器也是由多个相同的层组成。在DecoderBlock类中实现的每个层包含了三个子层:解码器自注意力、“编码器-解码器”注意力和基于位置的前馈网络。这些子层也都被残差连接和紧随的层规范化围绕。
正如在本节前面所述,在掩蔽多头解码器自注意力层(第一个子层)中,查询、键和值都来自上一个解码器层的输出。关于序列到序列模型(sequence-to-sequence model),在训练阶段,其输出序列的所有位置(时间步)的词元都是已知的;然而,在预测阶段,其输出序列的词元是逐个生成的。因此,在任何解码器时间步中,只有生成的词元才能用于解码器的自注意力计算中。为了在解码器中保留自回归的属性,其掩蔽自注意力设定了参数dec_valid_lens,以便任何查询都只会与解码器中所有已经生成词元的位置(即直到该查询位置为止)进行注意力计算。
class DecoderBlock(nn.Block):
"""解码器中第i个块"""
def __init__(self, num_hiddens, ffn_num_hiddens, num_heads,
dropout, i, **kwargs):
super(DecoderBlock, self).__init__(**kwargs)
self.i = i
self.attention1 = d2l.MultiHeadAttention(num_hiddens, num_heads,
dropout)
self.addnorm1 = AddNorm(dropout)
self.attention2 = d2l.MultiHeadAttention(num_hiddens, num_heads,
dropout)
self.addnorm2 = AddNorm(dropout)
self.ffn = PositionWiseFFN(ffn_num_hiddens, num_hiddens)
self.addnorm3 = AddNorm(dropout)
def forward(self, X, state):
enc_outputs, enc_valid_lens = state[0], state[1]
# 训练阶段,输出序列的所有词元都在同一时间处理,
# 因此state[2][self.i]初始化为None。
# 预测阶段,输出序列是通过词元一个接着一个解码的,
# 因此state[2][self.i]包含着直到当前时间步第i个块解码的输出表示
if state[2][self.i] is None:
key_values = X
else:
key_values = np.concatenate((state[2][self.i], X), axis=1)
state[2][self.i] = key_values
if autograd.is_training():
batch_size, num_steps, _ = X.shape
# dec_valid_lens的开头:(batch_size,num_steps),
# 其中每一行是[1,2,...,num_steps]
dec_valid_lens = np.tile(np.arange(1, num_steps + 1, ctx=X.ctx),
(batch_size, 1))
else:
dec_valid_lens = None
# 自注意力
X2 = self.attention1(X, key_values, key_values, dec_valid_lens)
Y = self.addnorm1(X, X2)
# “编码器-解码器”注意力。
# 'enc_outputs'的开头:('batch_size','num_steps','num_hiddens')
Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)
Z = self.addnorm2(Y, Y2)
return self.addnorm3(Z, self.ffn(Z)), state为了便于在“编码器-解码器”注意力中进行缩放点积计算和残差连接中进行加法计算,编码器和解码器的特征维度都是num_hiddens。
decoder_blk = DecoderBlock(24, 48, 8, 0.5, 0)
decoder_blk.initialize()
X = np.ones((2, 100, 24))
state = [encoder_blk(X, valid_lens), valid_lens, [None]]
decoder_blk(X, state)[0].shape(2, 100, 24)
现在我们构建了由num_layers个DecoderBlock实例组成的完整的Transformer解码器。最后,通过一个全连接层计算所有vocab_size个可能的输出词元的预测值。解码器的自注意力权重和编码器解码器注意力权重都被存储下来,方便日后可视化的需要。
class TransformerDecoder(d2l.AttentionDecoder):
def __init__(self, vocab_size, num_hiddens, ffn_num_hiddens,
num_heads, num_layers, dropout, **kwargs):
super(TransformerDecoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.num_layers = num_layers
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add(
DecoderBlock(num_hiddens, ffn_num_hiddens, num_heads,
dropout, i))
self.dense = nn.Dense(vocab_size, flatten=False)
def init_state(self, enc_outputs, enc_valid_lens, *args):
return [enc_outputs, enc_valid_lens, [None] * self.num_layers]
def forward(self, X, state):
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self._attention_weights = [[None] * len(self.blks) for _ in range (2)]
for i, blk in enumerate(self.blks):
X, state = blk(X, state)
# 解码器自注意力权重
self._attention_weights[0][
i] = blk.attention1.attention.attention_weights
# 编码器-解码器自注意力权重
self._attention_weights[1][
i] = blk.attention2.attention.attention_weights
return self.dense(X), state
@property
def attention_weights(self):
return self._attention_weights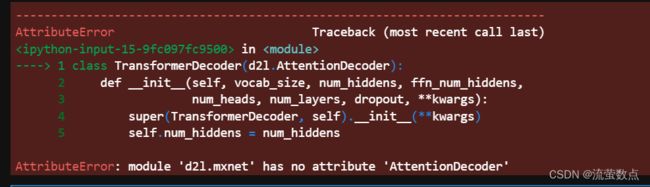
6.训练
依照Transformer架构来实例化编码器-解码器模型。在这里,指定Transformer的编码器和解码器都是2层,都使用4头注意力。与序列到序列学习(seq2seq,BLEU)_流萤数点的博客-CSDN博客_序列到序列类似,为了进行序列到序列的学习,下面在“英语-法语”机器翻译数据集上训练Transformer模型。
num_hiddens, num_layers, dropout, batch_size, num_steps = 32, 2, 0.1, 64, 10
lr, num_epochs, device = 0.005, 200, d2l.try_gpu()
ffn_num_hiddens, num_heads = 64, 4
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = TransformerEncoder(
len(src_vocab), num_hiddens, ffn_num_hiddens, num_heads, num_layers,
dropout)
decoder = TransformerDecoder(
len(tgt_vocab), num_hiddens, ffn_num_hiddens, num_heads, num_layers,
dropout)
net = d2l.EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
训练结束后,使用Transformer模型将一些英语句子翻译成法语,并且计算它们的BLEU分数。
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, dec_attention_weight_seq = d2l.predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device, True)
print(f'{eng} => {translation}, ',
f'bleu {d2l.bleu(translation, fra, k=2):.3f}')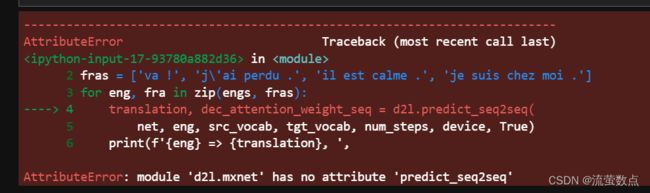
当进行最后一个英语到法语的句子翻译工作时,让我们可视化Transformer的注意力权重。编码器自注意力权重的形状为(编码器层数,注意力头数,num_steps或查询的数目,num_steps或“键-值”对的数目)。
enc_attention_weights = np.concatenate(net.encoder.attention_weights, 0).reshape((num_layers,
num_heads, -1, num_steps))
enc_attention_weights.shape在编码器的自注意力中,查询和键都来自相同的输入序列。因为填充词元是不携带信息的,因此通过指定输入序列的有效长度可以避免查询与使用填充词元的位置计算注意力。接下来,将逐行呈现两层多头注意力的权重。每个注意力头都根据查询、键和值的不同的表示子空间来表示不同的注意力。
d2l.show_heatmaps(
enc_attention_weights, xlabel='Key positions', ylabel='Query positions',
titles=['Head %d' % i for i in range(1, 5)], figsize=(7, 3.5))为了可视化解码器的自注意力权重和“编码器-解码器”的注意力权重,我们需要完成更多的数据操作工作。例如用零填充被掩蔽住的注意力权重。值得注意的是,解码器的自注意力权重和“编码器-解码器”的注意力权重都有相同的查询:即以序列开始词元(beginning-of-sequence,BOS)打头,再与后续输出的词元共同组成序列。
dec_attention_weights_2d = [np.array(head[0]).tolist()
for step in dec_attention_weight_seq
for attn in step for blk in attn for head in blk]
dec_attention_weights_filled = np.array(
pd.DataFrame(dec_attention_weights_2d).fillna(0.0).values)
dec_attention_weights = dec_attention_weights_filled.reshape((-1, 2, num_layers, num_heads, num_steps))
dec_self_attention_weights, dec_inter_attention_weights = \
dec_attention_weights.transpose(1, 2, 3, 0, 4)
dec_self_attention_weights.shape, dec_inter_attention_weights.shape由于解码器自注意力的自回归属性,查询不会对当前位置之后的“键-值”对进行注意力计算。
# Plusonetoincludethebeginning-of-sequencetoken
d2l.show_heatmaps(
dec_self_attention_weights[:, :, :, :len(translation.split()) + 1],
xlabel='Key positions', ylabel='Query positions',
titles=['Head %d' % i for i in range(1, 5)], figsize=(7, 3.5))与编码器的自注意力的情况类似,通过指定输入序列的有效长度,输出序列的查询不会与输入序列中填充位置的词元进行注意力计算。
d2l.show_heatmaps(
dec_inter_attention_weights, xlabel='Key positions',
ylabel='Query positions', titles=['Head %d' % i for i in range(1, 5)],
figsize=(7, 3.5))尽管Transformer架构是为了序列到序列的学习而提出的,但正如本书后面将提及的那样,Transformer编码器或Transformer解码器通常被单独用于不同的深度学习任务中。