百度NLP:强化学习之原理与应用
强化学习之原理与应用

强化学习特别是深度强化学习近年来取得了令人瞩目的成就,除了应用于模拟器和游戏领域,在工业领域也正取得长足的进步。
百度是较早布局强化学习的公司之一。这篇文章系统地介绍强化学习算法基础知识,强化学习在百度的应用,以及百度近期发布的强化学习工具PARL。
强化学习算法
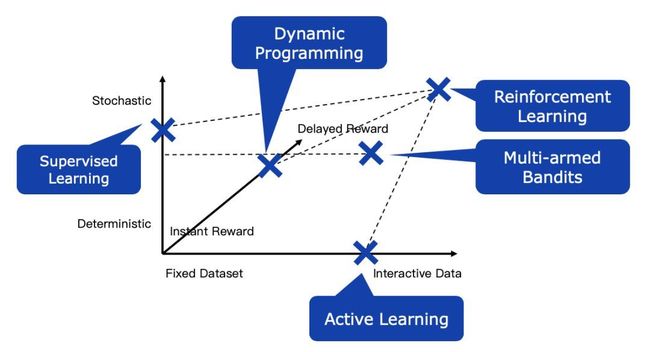
强化学习(RL)和其他学习方法的异同
首先,从宏观层面看,可以通过“三轴”图来看强化学习与其他学习方法的联系和区别:第一条轴deterministic -stochastic可以描述转移概率,决策过程和奖励值分布的随机性;第二条轴fixed dataset -interactive data,表示学习数据的来源方式;第三轴instant reward -delayed reward表示奖励值是立即返回还是有延迟的。我们熟知的有监督学习,针对的是静态的学习数据,以及近似可以看作无延迟的奖励;动态规划针对的则是确定性的环境,以及静态的数据;主动学习针对无延迟的奖励以及交互型的数据;多臂老虎机(multi-armed bandits)则同时处理带有奖励随机性和交互型的数据,但依旧是无延迟的奖励问题;只有强化学习处理三个方向(随机,有延时,交互)的问题。因此,强化学习能够解决很多有监督学习方法无法解决的问题。
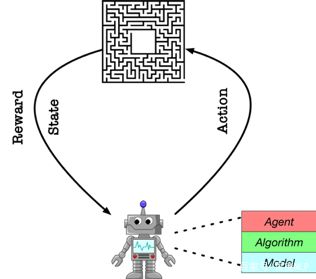
强化学习(RL)的基本定义
强化学习的主要思想是基于机器人(agent)和环境(environment)的交互学习,其中agent通过action影响environment,environment返回reward和state,整个交互过程是一个马尔可夫决策过程。
举个例子如雅利达游戏:state指看到当前电游屏幕上的图像信息;agent或者人类专家面对state可以有相应的action,比如对应游戏手柄的操作;environment在下一帧会反馈新的state和reward,整个过程可以用马尔可夫决策过程来描述。在这个过程中的environment则主要包括两个机制:一个是transition代表环境转移的概率,另外一个是reward。
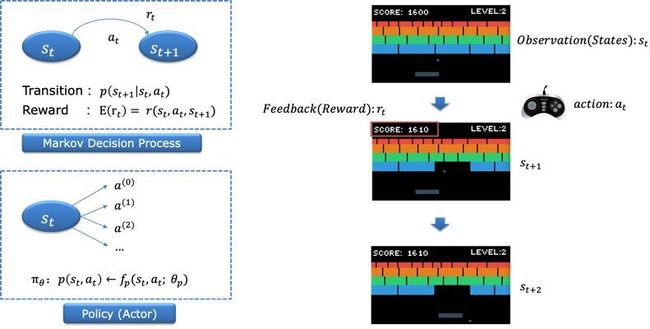
Markov Decision Process和Policy的定
可以通过更具体的类比来理解有监督和强化学习的REINFORCE算法的关联。假设在t时刻action以来表示. 在有监督的学习过程中需要人来示范动作, 通常我们希望机器去学习人的示范动作,在这里就代表示范的label。我们一般可以通过最小Negative Log-Likelihood (NLL)来使得我们的policy函数逼近人的示范。

从Supervised Learning到REINFORCE

除此之外,DQN、temporal difference等方法,则是基于一个值(critic)评价体系进行迭代,而非直接求解policy。这类方法存在显著问题是无法针对连续动作空间。本文不再展开介绍。

REINFORCE 和 CreditAssignment


从REINFORCE到Advantage Function的计
强化学习涉及的算法非常多,种类也非常广,包括:model-free算法,这类算法最为大家所熟知,而它又可以分为critic only,actor only和actor-critic;model based算法,通过对环境建模来进行规划,这类算法在训练过程中具有很高效率,但因为inference的时候需要做planning效率则较低,这类方法最近获得越来越多的关注;还有一些和不同算法结合在一起的组合RL方法,如Auxiliary Tasks, Hiearchical RL,DeepExploration,逆强化学习等。
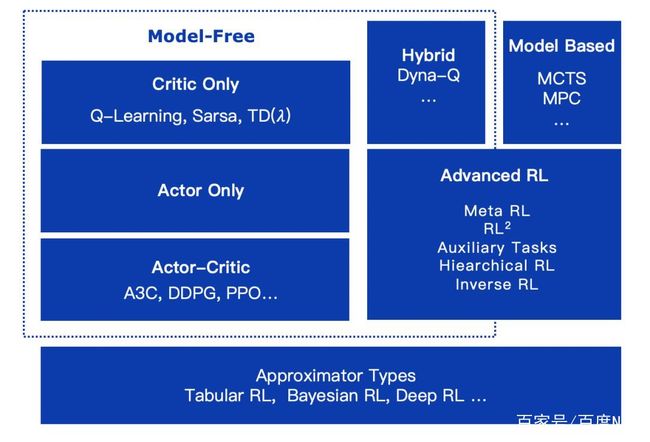
强化学习的算法罗列
强化学习应用-推荐系统
2011年之前,强化学习主要用于Intelligent Robotics等控制问题。2012-2013年,强化学习伴随深度学习的高涨逐渐火热起来。2012年,百度已开始将multi-armed bandits用于搜索排序。2014-2017年,百度将强化学习用于对话系统,广告定价,新闻推荐等场景;在学术上,也发布了首个AGI评测环境XWorld。2018-19年,百度在强化学习工具,研究,应用方面开始全面铺开。
对于推荐类问题来说,工业界的推荐系统早期比较成熟的方法包括协同过滤,CTR预估等。而现有推荐系统有两个尚未解决得很好的问题,也是业界研究热点:
1)intra-list correlations:考虑列表里的内容关联。现有推荐系统通常针对用户推荐一个列表,而不是一个一个内容推荐,因此内容之间的组合关联就会有影响。传统的多样性推荐等技术,其实都在解决这个问题。
2)inter-list correlations:考虑的是列表页间的时序关联,即内容本身对用户的价值,随着时间和交互次数的增加而动态变化。
百度基于新闻资讯推荐场景,对这两个层级的问题都开展了相应研究工作,并且均涉及强化学习技术:
在intra-list correlation角度,以往经典做法认为列表内的item之间是相互独立的,以此来预估CTR,又被称为item-independent prediction。
多样性是在此基础上的一个改进,即以整个组合来考虑推荐内容,而不单纯只考虑item自身。学术界对多样性理论的研究包括DPP,Submodular Ranking等方法[2][3]。Submodular实际上就是对“边际效用递减”这个说法的形式化,通俗的说,把所有商品看成一个集合,随着所拥有的商品数量的增加,那么获得同类商品的满足程度越来越小。在推荐系统中,在上文推荐的基础上进行重新估计,例如下面的图中,第i次新闻推荐内容项为,第i+1次推荐的内容需要考虑去掉已推荐过的相似内容,考虑用户感兴趣的topic空间,给用户推荐的应该是月牙形区域的内容,这便是submodular中的net gain的定义。DPP的做法也类似。
然而,目前对于多样性的研究缺乏统一的目标定义,多样性也不对最终用户反馈直接负责,导致多样性效果很难客观衡量,往往只能主观调节。
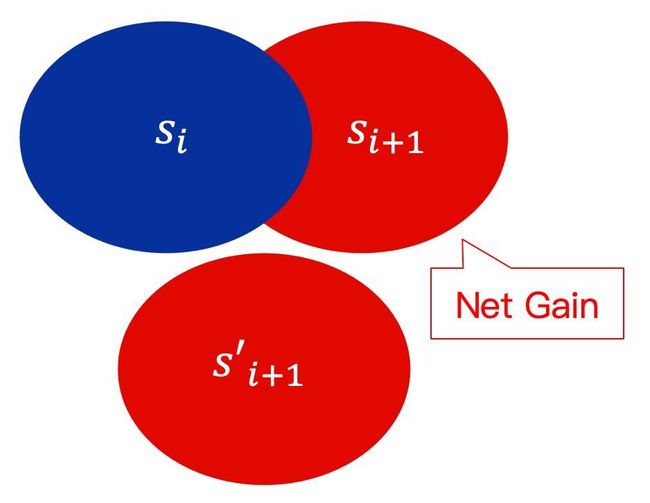
Submodular排序Net-Gain的计算
基于此背景,百度提出了列表页内组合优化框架,整合了学术界对列表页框架的认识。这个框架包括多个方面贡献:1. 提出了完全以用户反馈utility来衡量列表页内组合是否合理的方法。2. 提出了评价-生成的框架来解决组合优化的局部和全局最优的问题,以及off-policy训练的问题。3. 提出了不少新的模型结构,包括Recursive网络,Transformer网络等,用于更加通用地建模列表页内的组合,不仅包括两两关联组合,包括更高阶的组合,正向反向的组合等。百度相关产品在2017年底就上线了序列优化框架,相对于以往很多方法已经取得了不少收益,相关的成果已发表论文[4]。
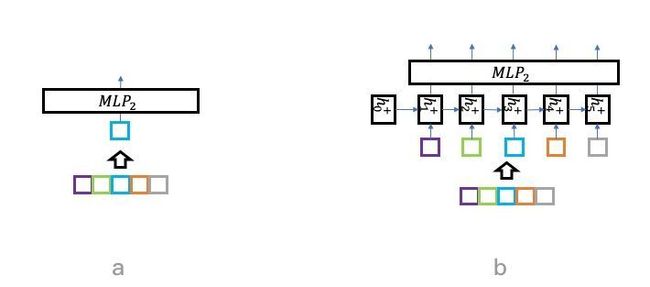
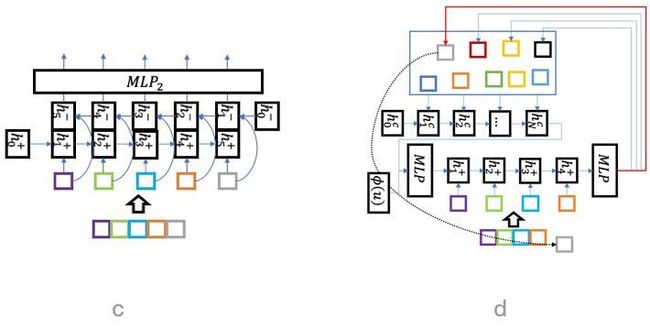
建模列表页内内容的一些模型和方法
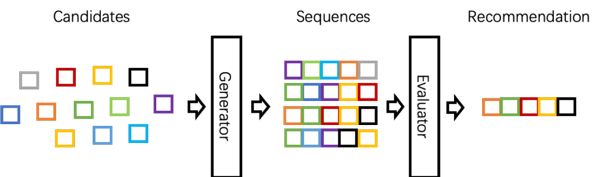
Evaluator – Generator列表组合排序框
而在inter-list correlation角度,对于新闻推荐这类产品的列表间优化,强化学习面临一个难题是variance过大,可能导致准确率下降。过去Google,京东发表的一些论文,针对这个问题,较为机械地用传统强化学习方法来解决。但是这些方法往往因为定义过大的action空间,以及过长的MDP,导致准确性下降。而且这些成果,大部分都是在理想的实验环境,而非真正的线上环境使用。百度多年前针对机械使用强化学习技术的尝试也发现,对于线上极大规模的排序或者推荐的列表页间的交互优化并没有实际优势。目前百度正在采用Credit Assignment这类新的算法,以更好地解决这些问题,不久之后会发布这些成果。
强化学习 应用-对话系统
对话系统可以分为任务型对话系统(Task Oriented Dialogue System)和开放对话系统(Open Domain Dialogue System),经典的任务对话系统结构如下。在对话管理中,强化学习可以起到非常重要的作用。
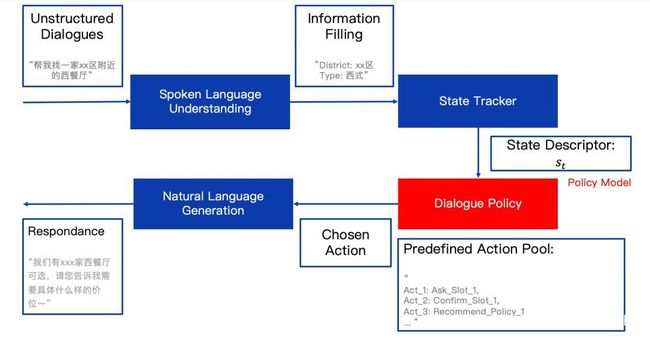
任务型对话系统流程
百度早在2012年就开始任务型对话系统的探索,其中一个早期的强化学习实验是2012-2013年做的点餐系统。这是一个百度内部员工使用的外卖订餐Demo。这个Demo基于一些NLU的特征,以及一些对话NLG的模板,利用LSTD模型来迭代对话管理逻辑。这个Demo设计的反馈也很粗糙,就是内部员工自己来标注。这个项目拿到一些结论,但整体不是很理想。
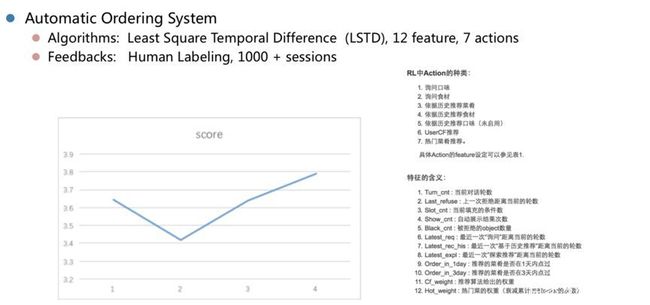
百度早期探索的对话式点餐系统
之后百度在各种垂类对话系统上进行了进一步的的实验。其中比如聊天气的垂类对话。它的特征相对点餐系统多一些,投入的人工评估和标注的资源也更多。最终效果上,有些指标能够超越人精心设计的规则策略。
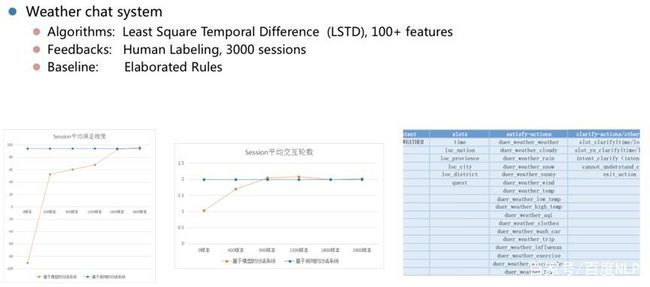
百度早期探索的聊天气对话系统
这之后,随着深度学习的兴盛,学术界也产生了一些成果。如2016年WenTsung-Hsien提出端到端面向任务对话系统[5],使用神经网络把四个模块综合起来,所有模块中的状态都可训练,相对以前工作有较大进步。利用深度强化学习结合端到端的对话模型,在足够的数据下,任务型对话系统可以达到比较理想的效果。
与任务型对话系统不同,开放式对话系统的潜力更大,难度也更高。百度早期做过一些尝试,比如聊天系统中的对话引导功能,引导用户提出下一句可能的问题。这功能的传统做法是通过语义匹配(semantic matching)网络来学习选择用户点击概率高的引导项,而通过强化学习来提升语义匹配网络的效果,使得语义匹配可以不单单考虑当前的点击概率,而是可以考虑后续的可能引导给出最佳的选择。

通用引导对话逻辑
在开放式对话方向的研究基本可以分为基于检索、自动生成两种方式。检索方式受限于有限的语料库,对于最终解决开放式对话问题而言,生成方式更具有潜力。而业界对于开放域的对话的生成,尚没有标准的解决方案。从2015年开始,端到端神经网络开始逐渐展现潜力。而当前端到端的对话系统存在的问题通常包括: 1)生成式回答中没有内容,如经常回复“哈哈”,“呵呵”;2)缺乏逻辑性,如“我有一个女儿,我12岁”;3)答非所问,如问“你从哪里来”,回答“我喜欢踢足球”;4)对话缺乏明确的目标和评价方式,导致效果评估效率低甚至无法实现。
强化学习作为解决上述部分问题的潜在方法,备受瞩目。但强化学习对话系统也存在显著问题:1)强化学习需要明确的学习目标,或者用户明确反馈,而评价目标很难制定,用户反馈则很难获取;2)强化学习通常需要大量的数据,甚至比有监督学习需要更多的数据。这些是阻碍强化学习应用的关键因素。
百度目前在开展一个比较有野心的工作,就是建立一套完整的对话评估体系。基于一套完整的评估体系,有可能在包括人-机对话,机-机对话(self-play),机-模拟器对话系统中,引入强化学习,提升对话质量。对于这套评估系统,有几个层面的要求:1)Word-level adversarial safe,使得这套评估系统能够被任何强化学习生成方法作为稳定的学习目标;2)和人的评估接近,可以被不同任务特化。
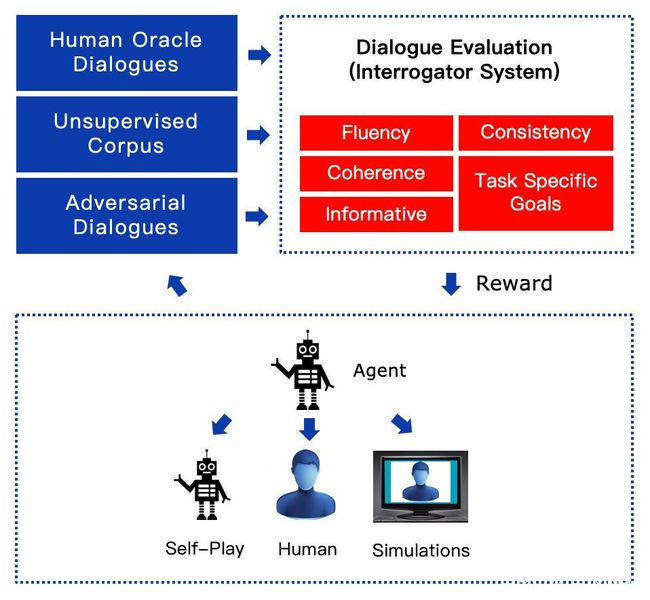
百度正在优化的自动评估的对话进化系统
在这套框架下,百度开展了一些尝试性工作。图中是Facebook发布的数据集persona[6],基于两个persona(个性数据),产生两个人之间的对话。通过两个机器人相互聊,聊完之后用evaluation-system来进行评估获得reward,从而强化这两个机器人的对话。相关进展未来将发布。
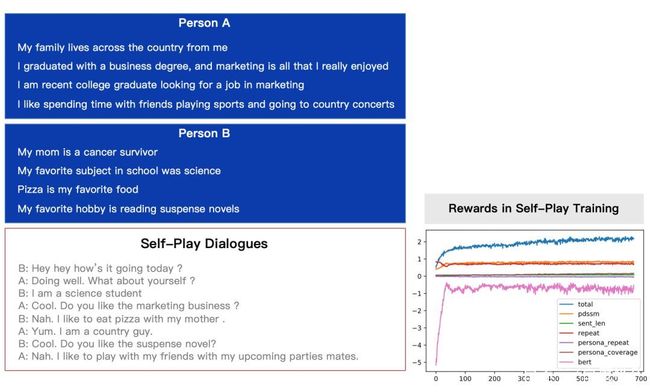
在自动评估-进化框架下,Self-Play训练
强化学习应用-移行控制

NeurIPS 2018 AI for Prosthetics Chal

百度在NeurIPS 2018 AI for Prosthetic
百度强化学习团队近期在NeurIPS 2018 AI forProsthetics竞赛中,也以绝对优势夺冠。在这个比赛中,需要控制一个人体骨骼肌肉模型的肌肉(19维),学习的目标是按照外部不断变换的给定的速度行走。对没有按照速度行走或者跌落扣分。
这次比赛中百度用到四个关键技术包括:
1)模型结构和学习方法上,使用deep deterministic policy gradient[7],该网络结构由4层MLP组成,将速度目标,状态,动作结合在一起建模,使得速度之间具有很好的可转移性。

百度在NeurIPS 2018AI for Prosthetics
2)CurriculumLearning[8]:为了获得稳定的奔跑姿态,首先训练一个高效的高速奔跑姿势,再利用课程学习(CurriculumLearning),设计一系列从易到难的课程,让机器人逐渐地降低速度。通过这种方式,得到一种特别稳定的姿态用于热启动。
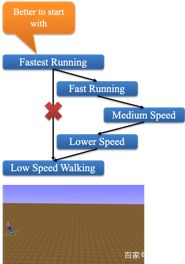
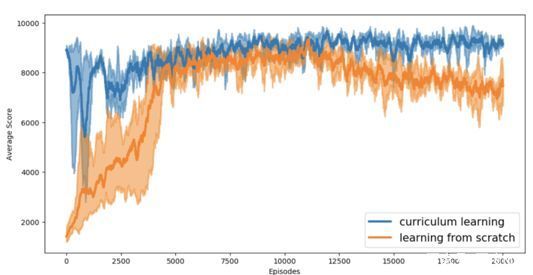
百度在NeurIPS 2018AI for Prosthetics
3)DeepExploration[9]:这项技术利用多个header的预测,得到其预测的波动,这个波动代表了当前策略和值的波动范围。这个能够帮助策略有效探索到探索不足的空间。
4)Parallelization:最后,基于PaddlePaddle的高效的计算框架,采用多个CPU的模拟器,以及一个data server、一个高性能GPU作为单机多卡的训练,将训练性能提高几百上千倍。
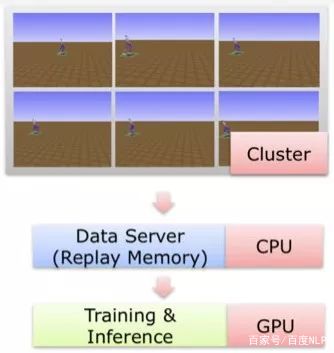
Distributed DDPG训练框架
基于上述的方法,百度团队不断刷新指标,最终以9980的绝对高分拿下比赛冠军。
另外一个进展则和自动驾驶相关。端到端的控制在机器人领域一直都具有比较高的吸引力。但控制问题是典型的delayedreward的问题,有监督学习在这个领域作用相对较少。近年来不断有用imitation learning,RL等提升端到端模型的研究。但同时,端到端模型又非常难以训练。百度首次在一个飞行器上实现了一种新的强化学习训练框架,并在避障导航问题中应用。
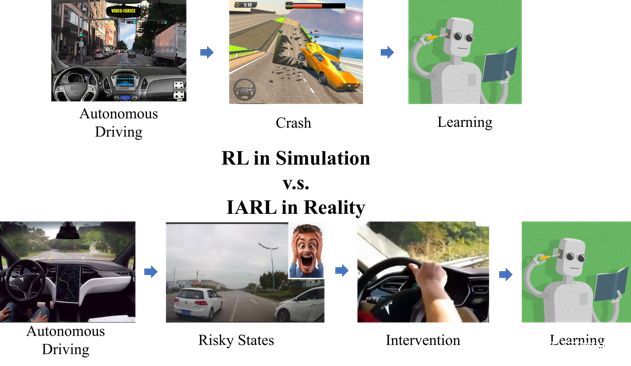
百度提出“干预强化学习(IARL)”和普
强化学习用在autonomous driving中的问题有:1)需要大量的数据;2)强化学习需要探索一些冒进的动作,并且经历一些风险和失败(比如碰撞)。然而在真实世界这个成本过大,不可能让无人车或者无人机撞毁无数次来学会如何躲避障碍。
百度提出的一种解决方案是利用安全员,当发现紧急情况时,安全员会做一些紧急动作。policy如下图所示,是一个比较复杂的端到端网络结构,融合CNN与LSTM(多帧信息)。但是通常不能把无人车或者飞行器真的完全交给这个模型,而是通过引入安全员来保障安全。

飞行器上使用的端到端控制模型
当系统做出错误判断或者出现高危动作时,安全员会及时介入。安全员的每次干预,说明机器的动作不对,这是非常珍贵的反馈信息,可以被机器学习。这就是干预辅助强化学习(Intervention Aided Reinforcement Learning)的思想。百度设计的IARL算法包括两个方面:1. 惩罚任何干预; 2. 学习安全员干预时所采用的操作。

干预强化学习的流程
IARL在policy和loss function中的体现如下,一方面,需要修改behavior policy,因为现在的policy不再是机器完全自主,而是变成了机器和干预的混合策略;第二方面,在reward上,需要对干预的过程做出惩罚;第三方面,对于policy的目标函数进行修改,增加一项用于学习干预过程的imitation learningloss。
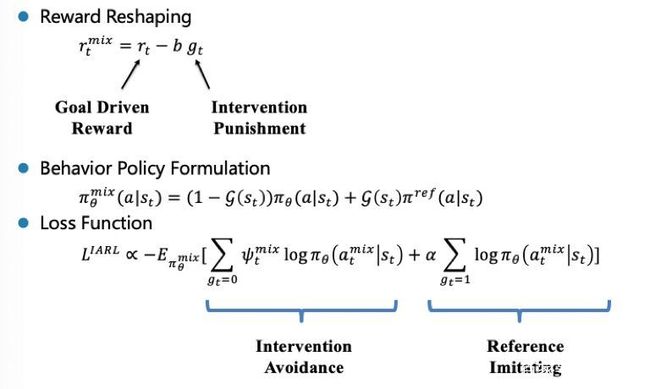
干预强化学习算法
该算法最终很好地实现了避障。而这个成果,也发表在CoRL 2018会议上:

干预强化学习的效果
工具-PARL
现在业界已有不少开源强化学习工具,百度也于近期发布了PARL框架。PARL是基于PaddlePaddle的一个强化学习框架,特点是:1)灵活性高,支持多数的强化学习算法;2)为数不多的开源其大规模分布式能力的强化学习算法库;3)通过之前介绍的工业级场景,验证了算法库的可用性。
这套强化学习框架基于3个基础类,分别是agent、algorithm、model。通过不同层级的定制,PARL能够实现方便,灵活,可服用,定制方便的强化学习算法,并具有对于大规模并行能力良好支持。用户可以很方便写出自己独特的定制算法,而不必去管具体通信接口等逻辑。以DQN为例,PARL提供了algorithm的现成DQN算法,用户只需要定制自己的模型即可。

基于PARL的利用现成的DQN Algorithm来
而如果用户需要定制全新的RL算法,也可以通过定制algorithm简单地实现。

PARL的DDPG Algorithm实例
最后,如果需要定义自己的全新的并行RL训练框架,用户能够通过定义一些通信逻辑,实现一些并行化的复杂操作。

PARL开发并行训练方法实例
这套强化学习库目前在业界已经引起了不少反响。主打灵活,易用和高并发的PARL能够取得什么样的成果,请拭目以待。
强化学习的存在问题及应对方法

强化学习 – 问题和潜在的研究方向
强化学习绝不是AI的终点,它实实在在解决了一类问题,然而仍然有更多待解决的问题。深度强化学习还远远不够好(Deep Reinforcement Learning Doesn’t Work Yet)。总结而言,强化学习存在的这些问题,也是未来值得去突破的方向,包括:
1)在很多应用中,往往目标不明确。例如对话最终目的一般来说是希望对话系统“表现得像人”,然而这个目标无法清楚地进行数学描述。因此reward modeling是很重要的研究方向。比如百度在推荐排序的时候,使用evaluation-generator的框架,即首先对reward的建模。
2)强化学习需要海量的样本,甚至比有监督学习还需要更多的样本。解决方法比如使用world model或planning。
3)奖励函数过于稀疏,难以探索到优质解。研究方向比如分层训练、课程学习和引入辅助任务。
4)泛化能力比较差,很多结果处在过拟合的区域。可以使用元学习,迁移学习,以及近期研究较多的攻防理论来改善。
5)实验难以复现。很多实验,甚至随机种子不一样都会得到完全不一致的效果。这也是百度将自己的工具开源的原因之一,也是要解决这个问题的第一步。
而这些方向,既是强化学习研究的前沿,也是很多工业应用面临的实际问题。百度也正在着力研究,期待有更多突破性的产出。
参考文献
[1] Schulman, John, etal. “High-dimensional continuous control using generalized advantageestimation.” arXiv preprintarXiv:1506.02438 (2015).
[2] Yue, Yisong, andCarlos Guestrin. “Linear submodular bandits and their application todiversified retrieval.” Advances in Neural Information Processing Systems.2011.
[3] Wilhelm, Mark, etal. “Practical Diversified Recommendations on YouTube with DeterminantalPoint Processes.” Proceedings of the 27th ACM International Conference on Informationand Knowledge Management. ACM, 2018.
[4] WangF , Fang X , Liu L , et al. Sequential Evaluation and Generation Framework for CombinatorialRecommender System[J]. 2019.
[5] Wen, Tsung-Hsien,et al. “A network-based end-to-end trainable task-oriented dialoguesystem.” arXiv preprintarXiv:1604.04562 (2016).
[6] Zhang, Saizheng,et al. “Personalizing Dialogue Agents: I have a dog, do you have petstoo?.” arXiv preprint arXiv:1801.07243(2018). “Self-EvolvingDialogue System with Adversarial Safe Automatic Evaluation”
[7] Lillicrap, TimothyP., et al. "Continuous control with deep reinforcement learning."arXiv preprintarXiv:1509.02971(2015).
[8] Bengio, Yoshua, etal. “Curriculum learning.” Proceedings of the 26th annualinternational conference on machine learning. ACM, 2009.
[9] Ian Osband,Charles Blundell, Alexander Pritzel, Benjamin Van Roy, Deep Exploration viaBootstrapped DQN, In NIPS 2016.
[10] Wang, F., Zhou,B., Chen, K., Fan, T., Zhang, X., Li, J., … & Pan, J. (2018, October).Intervention Aided Reinforcement Learning for Safe and Practical PolicyOptimization in Navigation. In Conference on Robot Learning.