【机器学习】多元梯度下降法
(本文略过了原课程中线性代数部分内容,如果你不理解线性代数,那你应当先去学习线性代数相关知识)
上一章——梯度下降
文章目录
- 多元假设方程
- 多元梯度下降
-
- 多元梯度下降公式
- 特征归一化
- 学习率对代价函数图像的影响
多元假设方程
在第二章中,我们给出了线性回归的一元线性假设方程
一元线性假设方程: h θ ( x ) = θ 0 + θ 1 x h_θ(x) =θ_0+θ_1x hθ(x)=θ0+θ1x
然而在实际情况中,我们不可能只有一个特征,比如房子的价格不仅由Size决定,其影响因素还有房间数量、房龄、地段等等特征,因此我们要将学习过的知识从一元推广到多元。

n 代表了特征的数量
x ( i ) x^{(i)} x(i)代表第i行的训练样本,我们可以用一个列向量表示改行
x j ( i ) x_j^{(i)} xj(i)代表第i行,第j列的元素
y y y为我们所求的预测值
那么在上列训练集中,有四个特征,因此我们可以列出如下的
四元线性假设方程:
h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + θ 3 x 3 + θ 4 x 4 h_θ(x) =θ_0+θ_1x_1+θ_2x_2+θ_3x_3+θ_4x_4 hθ(x)=θ0+θ1x1+θ2x2+θ3x3+θ4x4
n元的依此类推:
h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + . . . . . . + θ n x n h_θ(x) =θ_0+θ_1x_1+θ_2x_2+......+θ_nx_n hθ(x)=θ0+θ1x1+θ2x2+......+θnxn
让我们令 x 0 = 1 x_0=1 x0=1,得到这个式子
h θ ( x ) = θ 0 x 0 + θ 1 x 1 + θ 2 x 2 + . . . . . . + θ n x n h_θ(x) =θ_0x_0+θ_1x_1+θ_2x_2+......+θ_nx_n hθ(x)=θ0x0+θ1x1+θ2x2+......+θnxn
那么令 θ = [ θ 0 θ 1 θ 2 . . . θ n ] θ=\begin{bmatrix*}[r] θ_0 \\θ_1\\θ_2\\...\\θ_n \end{bmatrix*} θ= θ0θ1θ2...θn 令 x = [ x 0 x 1 x 2 . . . x n ] x=\begin{bmatrix*}[r] x_0 \\x_1\\x_2\\...\\x_n \end{bmatrix*} x= x0x1x2...xn
则 h θ ( x ) = θ 0 x 0 + θ 1 x 1 + θ 2 x 2 + . . . . . . + θ n x n = θ T x h_θ(x) =θ_0x_0+θ_1x_1+θ_2x_2+......+θ_nx_n=θ^Tx hθ(x)=θ0x0+θ1x1+θ2x2+......+θnxn=θTx
所以 h θ ( x ) = θ T x h_θ(x) =θ^Tx hθ(x)=θTx
多元梯度下降
多元梯度下降公式
同理我们可以将梯度下降,代价函数等也推广到多元
多元代价函数: J ( θ 0 , θ 1 , . . . , θ n ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J(θ_0,θ_1,...,θ_n)=\cfrac{1}{2m}\displaystyle\sum_{i=1}^m\bigg(h_θ(x^{(i)})-y^{(i)}\bigg)^{2} J(θ0,θ1,...,θn)=2m1i=1∑m(hθ(x(i))−y(i))2
或 J ( θ ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 J(θ)=\cfrac{1}{2m}\displaystyle\sum_{i=1}^m\bigg(h_θ(x^{(i)})-y^{(i)}\bigg)^{2} J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2[ J ( θ ) J(θ) J(θ)中θ代表向量 θ = [ θ 0 θ 1 θ 2 . . . θ n ] θ=\begin{bmatrix*}[r] θ_0 \\θ_1\\θ_2\\...\\θ_n \end{bmatrix*} θ= θ0θ1θ2...θn ]
而梯度下降公式: θ j ≔ θ j − α ∂ ∂ θ j J ( θ ) θ_j\coloneqqθ_j-α\cfrac{∂}{∂θ_j}J(θ) θj:=θj−α∂θj∂J(θ)
比如 θ 0 ≔ θ 0 − α ∂ ∂ θ 0 J ( θ 0 , θ 1 ) = θ 0 − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) θ_0\coloneqqθ_0-α\cfrac{∂}{∂θ_0}J(θ_0,θ_1)=θ_0-α\cfrac{1}{m}\displaystyle\sum_{i=1}^m\bigg(h_θ(x^{(i)})-y^{(i)}\bigg) θ0:=θ0−α∂θ0∂J(θ0,θ1)=θ0−αm1i=1∑m(hθ(x(i))−y(i))
θ j ≔ θ j − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) θ_j\coloneqqθ_j-α\cfrac{1}{m}\displaystyle\sum_{i=1}^m\bigg(h_θ(x^{(i)})-y^{(i)}\bigg)x^{(i)}_j θj:=θj−αm1i=1∑m(hθ(x(i))−y(i))xj(i)
(对 J ( θ ) J(θ) J(θ)求 θ j θ_j θj的偏导后,得到 2 ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) 2\displaystyle\sum_{i=1}^m\bigg(h_θ(x^{(i)})-y^{(i)}\bigg)x^{(i)}_j 2i=1∑m(hθ(x(i))−y(i))xj(i),最终变为上式,其中 x 0 ( i ) = 1 x^{(i)}_0=1 x0(i)=1)
特征归一化
之前在写代价公式的时候提到了,为什么我们要乘以一个 1 2 m \cfrac{1}{2m} 2m1,看起来似乎并没有必要,这是由于我们需要对数字进行归一化处理,来保证它们在可接受的大小范围内
一个简单的例子,假如我们取下列的数据, x 1 x_1 x1的范围是 [ 0 , 2000 ] [0,2000] [0,2000], x 2 x_2 x2的范围是 [ 1 , 5 ] [1,5] [1,5],那么画出来的图将如下

由于我们在纵轴上的范围更大,横轴上的范围小,这就导致画出的等高线图像是一个瘦长的椭圆形,
如果我们想要在这个图上进行梯度下降的话,对于这种又瘦又高的图像,梯度下降时则会在图像的左右两侧来回震荡,
最终晃晃悠悠地接近最低点,这就导致需要花费更长的时间来进行计算
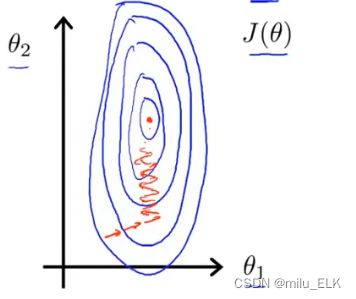
因此,我们的解决方法是将数据进行归一化,进行特征缩放
将每个特征除以区间大小,再绘制图像
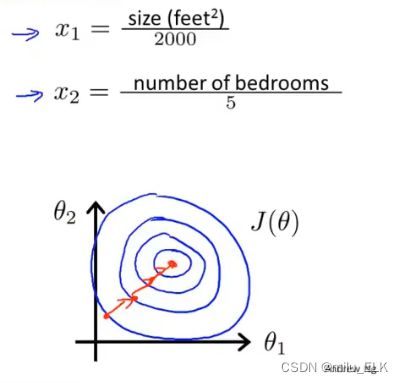
可以看到在新的图像中,梯度下降变得更加敏捷、有效。
归一化公式:
x i ≔ x i − μ i S i x_i\coloneqq \cfrac{x_i-μ_i}{S_i} xi:=Sixi−μi,其中 μ i μ_i μi代表特征值的平均值, S i S_i Si代表特征值的范围大小
总得来说,一般要求特征范围在 − 1 ≤ x i ≤ 1 -1\le x_i \le 1 −1≤xi≤1内
在实际中 − 3 ≤ x i ≤ 3 -3\le x_i \le 3 −3≤xi≤3, − 1 3 ≤ x i ≤ 1 3 -\cfrac{1}{3}\le x_i \le \cfrac{1}{3} −31≤xi≤31内都是可以接受的
学习率对代价函数图像的影响
之前在学习梯度下降的公式时我们就知道学习率对梯度下降的影响了
那么在选择学习率的过程中,如何确定适宜的学习率呢,我们可以通过对代价函数的图像观察来得出结论。

上图是一个学习率适宜时,以迭代次数为横轴,代价函数大小为纵轴的图像,我们可以清楚的看到:如果学习率选择正确,那么代价函数 J ( θ ) J(θ) J(θ)应当不断变小,并且随着迭代次数的增加,代价函数会趋近于0,当迭代次数足够多时,曲线趋于平坦,意味着函数收敛了。但是我们不知道它可能在何时收敛,也许需要迭代3千次,或者3万次,甚至30万次才能收敛,不过好在我们也有判断收敛的方法,我们可以用自动收敛算法来判断,或者给出一个定值η,当小于这个定值η时认为它收敛了。

如果图像呈现上升的趋势,说明梯度下降算法没有正常运行,这是由于学习率过大,在这种情况下我们就应该降低学习率
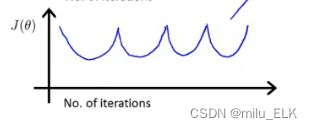
或者有可能由于学习率取得不对,导致图像呈现周期性。
在测试最佳学习率的时候,我们可以每隔十倍取一次数,比如100,10,1,0.1,0.01…或者每隔三倍,来寻找最佳学习率。
下一章——正规方程