Unsupervised semantic and instance segmentation of forest point clouds
ABSTRACT
地面激光扫描 (TLS) 越来越多地用于林业应用,包括森林清查和植物生态学。可以从 TLS 点云中准确估计树木的生物物理特性,例如叶面积分布和木材体积。在这些应用中,先决条件是正确理解大规模点云的信息内容(即点云的语义标记),以便检索树尺度属性。目前,这一要求正在经历费力费时的手工工作。在这项工作中,我们共同解决了森林点云的语义和实例分割问题。具体来说,我们提出了一种基于称为超点图的结构的无监督管道,以同时执行两项任务:单树隔离和叶木分类。所提出的方法不受森林类型的限制性假设。使用模拟数据进行的验证导致单棵树隔离的平均交集比 (mIoU) 为 0.81,叶木分类的总体准确率为 87.7%。单棵树隔离导致树高和树冠直径估计的相对均方根误差 (RMSE%) 分别为 2.9% 和 19.8%。与其他基准数据集上的现有方法的比较显示了我们的方法在单树隔离和叶木分类任务上的最新结果。我们将整个框架作为具有最终用户界面的开源工具提供。这项研究缩小了使用 TLS 点云量化大面积树木尺度特性的差距,其中自动解释 TLS 点云的信息内容仍然是一个关键的挑战。
1. Introduction
光探测和测距 (LiDAR) 技术的进步在过去几年彻底改变了树木结构量化(Dassot 等人,2011 年)。 LiDAR 技术的独特优势在于它可以获得物体的详细三维 (3D) 表示(即点云)。地面 LiDAR 或地面激光扫描 (TLS) 是迄今为止在单棵树规模上提供最准确测量的技术(Liang 等人,2016 年)。与传统的森林清查和破坏性测量相比,TLS 能够快速自动记录具有毫米级细节的树木结构。除了高度精确的 3D 坐标外,TLS 还能够提供物体的辐射特性,因此在植被研究方面具有巨大潜力(Kaasalainen 等人,2009 年)。
TLS 在林业中的应用大致可分为两个领域,森林清查和植物生态学。在森林清查中,关注的是树干。可以使用 TLS 点云准确估计茎位置、胸径 (DBH) 和茎曲线等属性 (Liang et al, 2018)。另一方面,植物生态学侧重于使用 TLS 来估计树木生理特性,例如叶角分布(Liu 等人,2019 年)、间隙分数(Danson 等人,2007 年)、冠层辐射(Van Leeuwen 等人,2013 年)、和地上生物量 (AGB)(Calders 等人,2015 年)。
然而,这些应用中的大多数都需要提前正确解释 TLS 点云(例如,过滤、分割、分类)(Morsdorf 等人,2018 年)。这一要求对于植物生态学研究尤为重要,因为重点通常放在单个树木规模的不同材料成分上。例如,树木 AGB 的估计主要是使用所谓的定量结构模型 (QSM) 完成的,该模型重建单个树木的 3D 木质结构(Gonzalez de Tanago 等人,2018 年;Takoudjou 等人,2018 年)。准确的 QSM 重建依赖于经过良好过滤的单树木质成分点云(Calders 等人,2015 年)。此外,必须去除木质材料才能了解冠层辐射机制和光合作用过程。此外,如果能够对 TLS 点云进行适当的过滤和处理,将会出现质量和能量交换等新的应用机会。因此,提前解读 TLS 点云的信息内容对于森林应用非常重要(Morsdorf 等人,2018 年;Burt 等人,2019 年)。
森林点云的信息内容(即语义标签)的解释主要涉及三个过程:地形去除、单树隔离和成分(即叶木)分类。森林地区的地形过滤是 LiDAR 技术的早期应用之一,并已得到广泛研究(Puttonen 等人,2014 年)。然而,在单树分离和叶木分类方面取得的进展较少。这两个过程可以进一步分为两个一般的点云处理问题:语义分割和实例分割。具体来说,树叶-木材分类属于语义分割问题,其目标是将每个点与类标签(即树叶或木材)相关联(Tchapmi 等人,2017 年)。单树隔离的主题是实例分割,这是一个将场景聚类为对象实例(即单个树)的过程。到目前为止,这两个过程都是费力费时的手工操作。最近,分别开发了几种方法来解决这些问题(例如,Burt 等人,2019 年;Heinzel 和 Huber,2018 年;Wang 等人,2018 年;Vicari 等人,2019 年;Wang 等人,2020 年)。然而,仍然存在一些障碍。首先,仍然经常需要在点云中进行手动描绘和校正。其次,由于缺乏对单个树冠的参考,单树隔离方法尚未得到适当评估。第三,以前的方法将单树隔离和叶材分类视为两个独立的任务。对于森林场景,结合语义和实例分割的潜力和优势仍未得到探索。最后,对于结构复杂的森林图,以前的方法的稳健性,尤其是结合使用时的稳健性是未知的。
在这项研究中,我们提出了一种完全无监督的方法,可以同时解决森林点云的语义和实例分割任务。具体来说,这种新方法基于超点图,使我们能够设计一系列图运算符,以在联合优化例程中将单树隔离和叶木分类联系起来。特别是,直觉是这两个步骤可以相互补充。主要贡献如下:
-
原始森林点云的一种新颖的超点图表示,嵌入了丰富的节点和边缘特征,在对象级别编码上下文信息。
-
在同时执行两项任务的超点图上运行的无监督双任务网络架构:单树隔离和叶木分类。
-
一个合成的 TLS 数据集模拟了一个高度逼真的森林场景,由超过 2000 万个三角形网格制作而成。该场景包含树冠结构复杂的大树。这个独特的数据集首次允许对树冠上的单棵树隔离进行明确评估。
-
在模拟和其他基准数据集上进行实验,以验证所提出方法的有效性。结果表明,协调一致的语义和实例分割在每个单独的任务上都实现了最先进的性能。
本文组织如下。第 2 节概述了相关工作。在第 3 节中,我们介绍了合成数据集和其他基准数据集。所提出方法的详细描述在第 4 节中给出。实验结果在第 5 节中给出。之后,第 6 节讨论了所提出方法的优点以及在森林点云的语义和实例分割方面的挑战。本文最终在第 7 节中得出结论。
2. Related work
2.1. Single tree isolation
TLS 点云中的单树隔离通常涉及两个子任务:单树定位和树冠分割。第一部分是树干检测,是森林资源清查的核心要求。已经提出了各种方法,例如欧氏聚类(Hackenberg 等人,2015 年)、圆/圆柱体检测(Burt 等人,2019 年)和二维点云投影(Wang 等人,2016 年)。最近针对林业应用的 TLS 方法的国际基准测试广泛评估和比较了 18 个参与者的各种算法(Liang 等人,2018 年)。总体而言,词干检测是一个深入研究的课题。
然而,另一方面,使用 TLS 数据的冠分割受到的关注要少得多(Heinzel 和 Huber,2018)。 Barbeito 等人 (2017) 在田间树木上标记胶带的帮助下使用了 k 最近邻算法。 Wang 等人 (2019) 部署了基于投影图像的 Faster RCNN 深度学习网络来定位树干。然后使用区域生长方法对树冠进行分割。 Raumonen 等人 (2015) 提出了一种基于形态学规则的方法。首先定位树干,然后基于固定距离连通性假设逐步扩展。 Trochta 等人 (2017) 使用了类似的想法。这种方法的缺点是它只适用于树木稀疏且树冠之间相互作用最小的开阔森林 (Burt et al, 2019)。一组不同的方法使用图论。这些方法本质上将点云转换为连通图。例如,Zhong 等人 (2016) 采用归一化图切割作为能量最小化技术,将冠点聚集到候选茎。同样,Yang 等人 (2016) 使用最小图割对牙冠进行了分层分割。 Heinzel 和 Huber (2018) 开发了一种约束谱聚类方法,可最大限度地减少马尔可夫随机场的能量。 Tao 等人(2015)通过基于图最短路径算法的代谢尺度理论(West 等人,1997)进一步引入了生态学理论。他们的方法能够分割相交的树冠。尽管使用了不同的聚类方法,但上述所有方法实际上都达成了共识,即树冠在空间上应该靠近各自的茎/根,这一假设显然受到生态和植物学规则的启发。
除了方法的发展,单棵树隔离的评估仍然是一个未解决的问题。挑战在于树冠的参考极难获得,即使在点云中也是如此。除了 Heinzel 和 Huber (2018) 之外,几乎所有以前的方法都只在树的位置上评估了他们的方法。 Heinzel 和 Huber (2018) 还手动描绘了冠轮廓,并将分段冠的 3D 体积与手动描绘进行了比较。然而,逐点冠分割的评估尚未具体化。
2.2. Leaf-wood classification
已经提出了许多方法来对 TLS 点云中的树叶和木材成分进行分类。根据使用的特征,这些方法可以分为三类:基于几何、基于强度以及两者的结合(例如,Wang 等人,2018 年;Vicari 等人,2019 年;Krishna Moorthy 等人,2019 年)。
基于几何的方法只需要点的 3D 坐标。一个常见的策略是部署受监督的机器学习分类器。每个点都学习了通常从相邻点的空间排列推断出的几何特征。邻域的选择是基于固定大小或自适应大小(Wang 等人,2018 年;Krishna Moorthy 等人,2019 年)。特征的确定是至关重要的。应该设计信息丰富的和有区别的特征。研究表明,仅使用几何特征的基于机器学习的方法能够有效地区分叶点和木点(例如,Belton 等人,2013 年;Ma 等人,2015 年;Yun 等人,2016 年;Krishna Moorthy 等人,2019 年)。实现的分类准确率一般在 80% 到 95% 之间。这些方法的优点是不受限制的森林类型和数据源的影响(Disney 等人,2018 年)。然而,缺点是显而易见的。监督机器学习方法需要费力且耗时的手动选择训练数据。目前,没有可用于森林场景的大型注释数据集。设计用于叶木分类的通用深度学习网络的潜力仍有待探索。因此,很可能需要为每个特定数据集手动选择训练数据,这阻碍了这些方法对大型空间数据集的适用性。基于几何的方法的一个不同且更可取的策略是开发完全无监督的方法。最近提出了几种自动算法(例如,Tao 等人,2015 年;Hétroy-Wheeler 等人,2016 年;Li 等人,2017 年;Wang 等人,2018 年;Vicari 等人,2019 年;Wang 等人,2020 年)。这些无监督方法使用基于组件特定几何特性的聚类策略,例如扁平的叶子、线性结构和茎和树枝的圆形形状。值得注意的是,其中一些方法仅针对单棵树进行了优化(例如,Tao 等人,2015 年;Vicari 等人,2019 年)。提前需要额外的步骤来分割单个树。实验表明,与有监督的机器学习方法相比,这些无监督方法达到了相似的精度,因此具有大面积应用的巨大潜力。
另一方面,基于强度的方法假设树木成分在激光扫描仪的工作波长下具有不同的光学特性(Béland 等人,2014 年;Tao 等人,2015 年)。以前的研究表明,基于强度的方法的有效性是类似于基于几何的方法(Wang 等人,2018 年)。但是,基于强度的方法的主要局限性之一是激光返回强度可能会受到距离、部分激光命中和入射角的任意影响(Kaasalainen 等人, 2009),并且必须针对每台仪器进行专门校准(Calders 等人,2017)。如果经过校准,强度信息可以与那些基于几何的方法中的几何特征相结合,这可能比仅使用一种类型提供更多优势(Zhu 等人,2018 年)。此外,以研究为主导的多波长 LiDAR 系统的开发可能有助于以在未来区分树叶和木材组件(迪士尼,2019 年)。
3. Study data
单树隔离和叶木分类任务的评估需要详尽的参考数据,这些数据通常由人工生成。然而,在点云中隔离单个树冠在视觉上什至是不切实际的。为了缓解这个问题,我们设计了一个独特的合成数据集,它具有 100% 确定的逐点树 ID 和叶木标签。此外,还使用了另外两个基准数据集来进一步将我们的方法与文献进行比较。需要注意的是,我们对按地形(即高于地面的高度)归一化的点云进行操作。地形过滤不是本研究的重点。有关森林地区地形过滤的具体描述和讨论,请参见例如 Puttonen 等人 (2014) 和 Moudrỳ 等人 (2020)。
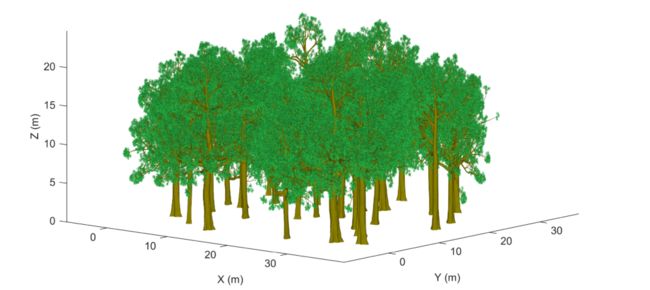
图 1. 一个 40 × 40 m 的虚拟森林图。
3.1. Synthetic dataset
在这项研究中,首先使用 SpeedTree 软件(Interactive Data Visualization, Inc. Lexington, SC, USA)对欧洲山毛榉 (Fagus sylvatica) 的 10 个基本模型进行了建模。对于所有树木,每片叶子都由菱形(即两个三角形)塑造,以与其他模拟研究保持一致(Gastellu-Etchegorry 等人,2015 年;Liu 等人,2019 年)。每棵树被复制两次。在这项研究中,总共生成了 30 棵树来组装虚拟地块。具体来说,所有 30 棵树都被随机放置、缩放和旋转在 ~40 × 40 m 的地块中(图 1)。这个虚拟场景由超过 2000 万个三角形网格模型组成。树高、胸径和树冠直径的统计数据总结在图 2 中。我们有意创建了大而明显相交的树冠,以充分验证我们方法的有效性。
TLS 点云是使用 HELIOS 模拟器(Bechtold 和 Höfle,2016 年)模拟的。 HELIOS 是一个开源工具,允许用户在由网格模型组装的虚拟场景上模拟各种激光扫描平台。在这项研究中,我们模拟了 Riegl VZ-400(0.3 mrad 光束发散角,0.05° 角分辨率)的设置和规格,这是林业研究中使用的一种流行扫描仪。模拟了来自九个位置的扫描,其中四个在外面,四个在角落,一个在中心(图 3)。此设置是为了确保高点云质量(Wilkes 等人,2017 年),因为此场景的特点是具有大型且结构复杂的树冠,这将导致严重的遮挡。在 TLS 模拟中记录了树木 ID 和叶木标签的先验信息。来自九个位置的模拟点云被合并。最终的点云通过 1 cm 体素进行下采样以减小数据大小。每个结果点都包含一个用于树标记的 ID 和一个指示树叶和木材类别的标签。
3.2. Benchmark datasets
本研究中包括两个额外的基准数据集,以分别将我们的方法与文献中关于单树隔离和叶木分类的其他方法进行比较。
3.2.1. Single tree isolation
六个森林地块的公开可用 TLS 数据集是从芬兰地理空间研究所组织的国际 TLS 基准测试项目中获得的(Liang 等人,2018 年)。这些数据集是从芬兰 Evo 的南部北方森林中获取的,涵盖了各种树种、树干密度、发育阶段和丰富的林下植被。根据这些特征,六个地块被分为三种复杂类型(即简单、中等和困难)。优势树种是苏格兰松 (Pinus sylvestris L.)、挪威云杉 (Picea abies L. Karst.)、白桦 (Betula pendula Roth) 和绒毛桦 (Betula pubescens Ehrh.)。每个地块的固定尺寸为 32 × 32 m,并由 Leica HDS1600 扫描仪(Leica Geosystems AG,Heerbrugg,Switzerland)扫描。提供了单次和多次扫描数据。本研究仅使用多扫描数据,因为我们专注于详细的牙冠分割。提供了树木位置和胸径的参考数据。使用开源布料模拟方法过滤地形点(Zhang et al,2016)。有关本研究中使用的基准图的完整描述,请参阅 Liang 等人 (2018)。

图 2. 树属性分布。箱形图显示最小值、第一四分位数、中位数、第三四分位数和最大值。 (为了解释这个图例中对颜色的引用,读者可以参考本文的网络版本。)
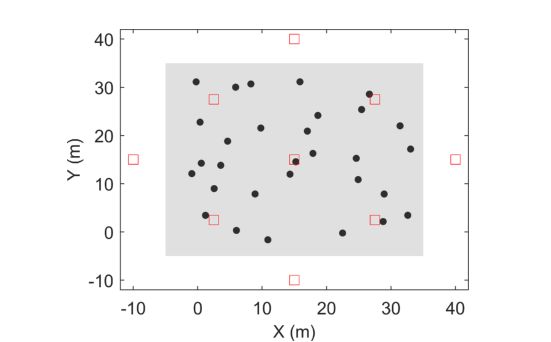
图 3. 树(黑点)和 TLS 扫描(红方块)位置。 40 × 40 m 的地块用灰色着色。 (为了解释这个图例中对颜色的引用,读者可以参考本文的网络版本。)
3.2.2. Leaf-wood classification
在本研究中,下奥地利州(奥地利)Großgöttfritz 的一个半径为 50 m 的森林地块被用作叶木分类的基准数据集。主要树种是苏格兰松 (Pinus sylvestris L.),还有一些白桦 (Betula pendula Roth)。使用 Riegl VZ-2000 扫描仪(RIEGL 激光测量系统,霍恩,奥地利)从两个位置扫描了该地块.使用已知反射率为 99% 的 Spectralon 对采集的 TLS 数据进行辐射校准。使用与第 3.2.1 节中相同的方法删除地形点。在点云中手动区分叶点和木点。可以使用各种方法的分类结果,包括基于激光强度、随机森林机器学习和先前研究中的无监督分割方法(Wang 等人,2018 年)。因此,该数据集可作为将我们的方法与其他常见和最先进的方法进行比较的独特基准。有关此数据集的完整描述以及比较基于强度、随机森林和无监督分割方法的详细信息,请参阅 Wang 等人 (2018)。
4. Methods
所提出的流水线是在结构化超级点图上操作的并发处理例程。利用这种表示,部署了具有一系列图操作的互连双任务处理链,以同时将图节点分割成簇(例如分割)并更新每个节点的上下文信息(用于语义嵌入)(图4)。
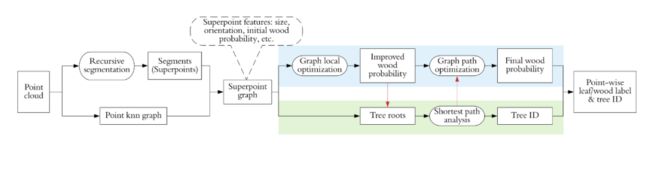
图 4. 所提出方法的工作流程。语义(即叶木分类,蓝色下划线管道)和实例(即单树隔离,绿色下划线管道)分割同时进行并共同进行。红色箭头表示两个任务的互惠互利。 (为了解释这个图例中对颜色的引用,读者可以参考本文的网络版本。)

图 5. 构建超点图步骤的可视化。 a) 输入点云被划分为 b) 几何简单的部分(即超点)。每个部分都是随机着色的。c)通过用超边连接相邻的超点来构造超点图。矩形框出的区域在右侧被放大。
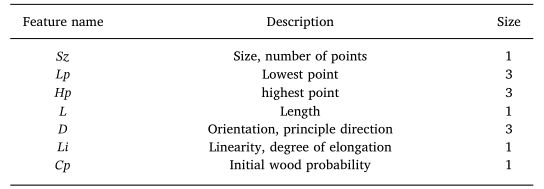
表 1 每个超点 S i \mathscr{S}_i Si的嵌入特征 f f f列表。
整个处理程序可以分为四个部分。
-
几何分区:超点是点云中一小部分几何简单但有意义的部分的聚合表示。因此,我们方法的第一步是将点云划分为聚类(即超点)。
-
超点嵌入:每个超点(即图节点)代表一个几何简单的图元,因此携带一定程度的语义信息。为每个超点推断出固定大小的特征向量。
-
超点图构造:构建结构化和无向超点图,使得空间相邻的超点通过边(即超边)连接(图 5)。
-
图划分和特征更新:通过超点图的邻接关系更新超点特征。基于超点特征和最短路径分析将超点图中的节点分割成簇。然后,每个超点簇代表一个对象实例(即单个树)。相反,路径分析用于细化和更新每个超点的语义信息。
我们在以下小节中详细描述了管道的每个步骤。
4.1. Geometric partition
此步骤的目的不是提取单个对象,例如树枝或树叶。相反,我们寻求过度分割以将对象分解为几何上简单的部分。然而,这些简单部分在语义上应该是同质的,这样每个部分就不会包含来自不同类别的对象(Landrieu 和 Simonovsky,2018)(图 5)。
我们部署了一个全自动的基于图形的分割(Felzenszwalb 和 Huttenlocher,2004)。关键步骤是构造一个无向图,从而将分割转化为图连通分量的搜索。几何特征(即垂直度)和点云密度用于约束图形。这种分割递归应用直到收敛,因此几何和语义异质部分被迭代分割。因此,这种数据驱动的方法可以适应不同的数据源和点密度。这种分割方法的细节参考了 Wang et al (2020)。
4.2. Superpoint embedding
每个超点 S i \mathscr{S}_i Si代表整个点云的一小部分。此步骤的目标是通过将每个超点嵌入到七维特征向量 f ∈ R f \in \mathbb{R} f∈R(表 1)中来独立推断每个超点的描述符。通过这样做,每个超点都携带一定程度的语义信息,稍后将支持图分区(第 4.4 节)。
除了大小和长度等几个简单特征外,我们还学习了一个关键特征——每个超点的初始木材分类概率 Cp,因为最终目标之一是对树叶和木材成分进行分类。我们寻求一种无监督的方法,因为没有可用且不需要的组件类先验知识。 Wang 等人 (2018) 表明,可以通过在点云分割后识别线性结构来提取木材成分。首先,根据超点协方差矩阵的特征值计算线性 Li (Wang et al, 2018)。然后,通过对大小 Sz 和线性度 Li 进行阈值处理,可以将超点标记为叶子或木材(Wang 等人,2020)。但是,这些阈值的确定并不简单。相反,测试了一组似是而非的阈值(Raumonen 和塔瓦宁,2018 年)。因此,结果是称为软标签的木材类别概率。然而,这一步仍然容易受到主观选择合理阈值的影响。因此,我们将此 Cp 表示为初始木材类别概率,并将在以下步骤中进一步优化。
4.3. Superpoint graph construction
超点图 G = ( S , C , W , F ) \mathscr{G}=(\mathscr{S}, \mathscr{C}, \mathscr{W}, \mathscr{F}) G=(S,C,W,F)由一组超点 S \mathscr{S} S(即节点)、超点特征 F ∈ R S × f \mathscr{F} \in \mathbb{R}^{\mathscr{S} \times f} F∈RS×f、超边 E \mathscr{E} E和映射超点之间欧氏距离的边权重 W : E ∈ R \mathscr{W}: \mathscr{E} \in \mathbb{R} W:E∈R组成。
要将点云转换为图形(graph),通常使用两种方法。首先,一个点连接到它的以最近邻点 (KNN) 或给定半径为界的邻点。其次,点连通性可以直接通过 Delaunay 三角剖分建模。此外,如果点云投影可用,则可以生成 2D 4 连通图或 8 连通图(Ben-Shabat 等人,2018)。基于给定半径内的邻居创建的图容易受到异质点密度的影响,而基于 KNN 和 Delaunay 三角剖分的方法可能会错误地连接远点。 Ben-Shabat 等人 (2018) 比较了所有这些点云分割方法,并得出结论,如果投影图像不可用,则应使用 KNN。
但是,不能直接在超点上构造 KNN 图,因为超点会丢失拓扑和邻接关系。在这项研究中,首先在原始点云上构建 KNN 图,然后将连接信息传输到超点(即超边)(图 5)。
生成的超点图是一个对称的无向图,具有嵌入的超点特征和代表超点之间邻接关系的超边。
4.4. Graph partition and feature updating
4.4.1. Graph local optimization
在超点嵌入中,估计初始木材类别概率 Cp。该初始估计应用于单个超点,因此缺乏上下文信息。例如,在实践中,类标签的分布应该在空间上是平滑的(Landrieu 和 Simonovsky,2018)。具体来说,图中的大多数相邻节点将共享相同的类标签。由于丰富的超点特征和邻接关系,可以直接优化图中的初始木材概率。我们使用简单的局部加权平均方法,称为图 4 中的图局部优化。一个超点的初始木材概率 Cp 由图中其 N 个相邻超点的所有 Cp 的平均值更新(图 4)。 6), 并由大小 Sz 加权为:

改进后的类别概率 Cp 在图 4 中表示为改进的木材概率。因此,超点图更新为 G = ( S , E , W , F ′ ) \mathscr{G}=\left(\mathscr{S}, \mathscr{E}, \mathscr{W}, \mathscr{F}^{\prime}\right) G=(S,E,W,F′),在 F ′ \mathscr{F}^{\prime} F′中具有空间平滑的木材类别概率。

图 6. 超点(绿色)通过超边与其相邻的超点(红色)相连。 (为了解释这个图例中对颜色的引用,读者可以参考本文的网络版本。)
4.4.2. Graph shortest path analysis
两个超级点之间的路径类似于用于传输水和其他营养物质的导管(Tao 等人,2015 年)。对于那些代表树根(或基)的超点,路径将它们连接到其他超点,从而充当所有可能的传输立方体。根据生态规则,传导路径应该是效率最大化的路径(即,最小化行进距离)。因此,如果图中存在多个实例(即树),则可以通过比较超点到各个根超点的路径距离来划分图。这种隔离单棵树的策略在 Tao 等人 (2015) 中被命名为比较最短路径 (CSP)。
CSP 方法要求首先识别表示单个树基的图节点。以前的方法使用欧几里德聚类或圆/圆柱检测方法检测原始点云中的树干(例如,Hackenberg 等人,2015 年;Burt 等人,2019 年)。而在我们的方法中,可以通过检查嵌入在超点特征集 F ′ \mathscr{F}^{\prime} F′中的语义信息来直接识别树基。首先,我们删除 Cp 小于 0.5 的叶超点。这一步已经大大消除了低植被和树叶的影响。接下来,可以通过对表 1 中的大小、方向和最低点等几何特征进行阈值化来识别树干超点。这些茎超点表示为根超点 S r t \mathscr{S}_{r t} Srt。
在某些情况下,检测到的根超点需要进一步合并,因为多个 Srt 可以来自同一树干。如果超点 Srti 正好位于另一个超点 Srtj 的上方并且它们具有相似的方向,则它们很可能来自同一棵树干 (Xia et al, 2015)(图 7)。我们从最低的超点开始,搜索其上方的其他超点,其最低点Lp在当前超点的最高点Hp的水平距离范围dr内。如果存在这样的超级点,则合并最低合格的超级点。这个过程一直持续到没有超级点可以被合并(图 7)。需要注意的是,这种合并只影响根超点 Srt 的识别,因为只有每个合并组的最低超点被标记为最终根超点。因此,超点图本身没有被修改。

图 7. 根超点的迭代合并。 S2首先合并到S1。然后将 S3 合并到由 S1 和 S2 组成的新组中。在这个例子中,最终的根超点是 S1 和 S4。

图 8. 木材检测的图形路径优化。左图:木材超点(棕色)在其通往根(蓝色背景)的路径上回溯到最后一个叶超点(绿色)。右图:目标叶超点被修正为木材。 (为了解释这个图例中对颜色的引用,读者可以参考本文的网络版本。)
接下来,通过 Dijkstra 的最短路径优先算法(Dijkstra,1959)计算超点 Si 到所有根超点 Srt 之间的路径距离。如果一个或多个 Srt 没有路径可用,则距离设置为无限大。每个超点都聚集到具有最短路径距离的 Srt。因此,每个超点都聚集到一个不同的对象实例,由各自的根 Srt 确定。因此,超点图被划分为实例,因此每个实例都包含来自单个树的超点(即,树 ID 被添加到特征集 F 中)。
4.4.3. Graph path optimization
木材超级点与其根部之间的最短路径类似于水和其他养分的传输立方体。因此,路径本身可用于改进木材检测,因为只有木材超点才能充当转移立方体(Vicari 等人,2019)。具体来说,从木超点到其根的最短路径上的任何超点也应该是木头。基于这一假设,Vicari 等人 (2019) 应用了一种回溯和间隙填充方法。我们在这里使用类似的方法,通过沿着最短路径重新分配木材超级点到根部(图 8)。木材超点被追溯至其路径上的最后一个叶超点(如果存在)。然后将此叶超点的 Cp 更新为 0.51(即木材概率 > 0.5)。为每个木超级点遍历此步骤。这种不那么激进的策略不是一次性填补所有空白(Vicari 等人,2019 年),而是避免了四肢上的叶超点也被错误检索的风险。此步骤称为图形路径优化(图 4)。因此,G S E W F= ( , , , ) 进一步更新为 G S E W F= ( , , , ),最终木材概率 Cp 在 F 中。
4.5. Point-wise labels
超点 S 和特征集 F 被转换回单点级别。直接为每个点记录树 ID。如果一个点的 Cp 大于 0.5,则该点被标记为木材,反之亦然。
4.6. Method comparisons
我们分别将我们的方法与单树隔离和叶木分类的最先进方法进行了比较。由于以前的单树隔离方法只在树干定位上进行评估,因此这里的比较也是在树干定位上进行的。 Zhang et al (2019) 中的词干检测方法在第 3.2.1 节中描述的基准数据集上进行了比较。对于叶木分类,比较了多种方法,包括激光强度、机器学习和无监督分割方法。 3.2.2 节中描述的基准数据用于此比较。
4.7. Assessment
我们从三个方面评估了我们方法的有效性:(a) 详细的树冠分割,(b) 单树定位,和 © 叶木分类。
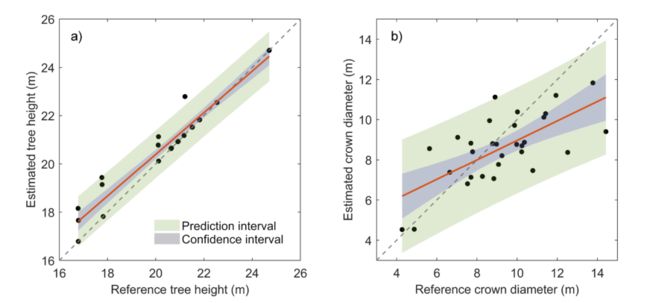
图 9. a) 树高和 b) 树冠直径估计的评估。
4.7.1. Crown segmentation
详细冠分割的评估进一步分为两部分。首先,我们使用 Intersection over Union (IoU),一种用于分割评估度量的标准度量,来评估我们的方法在详细牙冠分割方面的结果。对于 ×N N 混淆矩阵(本研究中 N = 30),每个条目 cij 指的是参考树 i 中预测为树 j 的点数。那么树i的IoU计算为:

然后通过以下方式估计所有树的平均 IoU (mIoU):

此外,我们还报告了总体准确度 (OA),由以下公式给出:

其次,我们还评估了树冠分割对树高和树冠直径估计的影响。均方根误差 (RMSE) 及其相对值报告为:
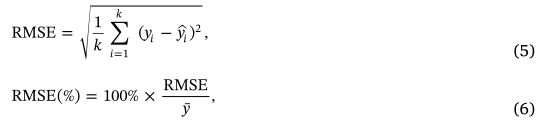
其中 k 是观测数据的数量,y 表示参考值,y¯ 是变量的平均值。
4.7.2. Single tree locating
我们使用检测的完整性、正确性和平均准确度指标评估了单树在基准数据集上定位的结果,以与 Zhang 等人 (2019) 和 TLS 基准测试项目 (Liang 等人,2018) 保持一致.完整性衡量检测到的参考树的百分比。正确性衡量检测到的树木相对于参考的百分比。平均准确度是基于完整性和正确性的联合度量,由下式给出:

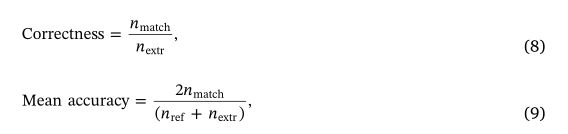
其中nmatch是检测到的参考树的数量,nref是参考树的数量,nextr是检测到的树的数量。
4.7.3. Leaf-wood classification
叶木分类报告了相同的 OA 指标(公式 4)。该指标用于衡量我们的方法区分叶子和木材成分的能力。此外,报告了叶木分类的模型敏感性和特异性。灵敏度测量真阳性(即木材)率,特异性给出真阴性(即叶)率,由下式给出:

其中 TP 代表真阳性,TN 代表真阴性。 FP 和 FN 分别代表假阳性(I 类错误)和假阴性(II 类错误)。
7. Conclusion
森林点云的语义和实例分割是树木尺度分析中的关键和基本步骤。在这项研究中,我们提出了一个无监督的管道,它同时执行单树隔离和叶木分类。所提出的方法基于嵌入了丰富的节点和边缘特征的新型超点图。一个联合双任务网络使学习类标签和使用图运算符对点进行聚类成为可能。
我们在高度逼真的森林图上模拟的合成 TLS 数据集上评估了所提出的方法。首次对单树隔离进行了详细的树冠分割评估。我们还将所提出的方法与其他基准数据集上的现有方法进行了比较。结果表明,我们在单树定位和叶木分类任务上都取得了最先进的性能。
所提出的方法在 TLS 和森林应用程序方面取得了重大进展。我们证明了可以有效且全自动地实现解释森林点云信息内容的先决条件。此外,我们将所提出的方法作为具有最终用户界面的开源工具提供,我们希望 TLS 和林业研究社区可以使用它来促进某些数据处理链。