集成算法之Adaboost

公众号后台回复“图书“,了解更多号主新书内容
作者:小一
来源:小一的学习笔记
写在前面的话
大家好,我是小一
这是大话系列的第5节算法,也是本系列的第13篇原创文章。
上节提到两种集成方法,是集成算法的相关背景知识点,如果你搞定了上节的概念,那么这节的集成算法应该对你来说不是问题,最起码在概念上是没有什么晦涩难懂的内容需要理解的。
上节回顾:两种集成方法的简单介绍
ok,这节就来说说集成算法的Adaboost算法,真真正正的通过三个臭皮匠造一个诸葛亮出来。
AdaBoost算法
AdaBoost:adaptive boosting,是一种自适应的boosting算法
相信你应该还记得Boosting方法,毕竟上节刚提到,注意注意,Adaboost是对Boosting 算法的一种实现
AdaBoost的工作原理
先来看一下我们的目标:使用多个弱分类器构造一个自适应的boosting 的分类器。
目前构造强分类器面临两个问题:选择最优的弱分类器和每个弱分类器的权重
选择最优的弱分类器
在boosting算法的过程中,需要根据上一轮的参数对本轮的权重进行更新,这样的目的是使得在上一轮被分类错误的样本在本轮能尽可能的被正确分类
于是在每轮样本的分类结果中,我们只需要计算分类的正确率,并且选择正确率最高的弱分类器为该轮的最优弱分类器
计算每个弱分类器的权重
我们知道最终的强分类器是由若干个弱分类器组成,同时每个弱分类器都有自己的权重,那这些弱分类器的权重如何计算呢?
前面我们已经计算了每个弱分类器分类的正确率,那我们就可以基于这个错误率去决定该弱分类器的权重。
错误率越低的弱分类器权重越高,也即表示正确率越高的分类器越重要。
Adaboost 分类步骤
前面搞清楚了如何确定权重并选择最优分类器,接下来康康Adaboost 的分类流程:
1. 确定样本权重
设定每个样本的初始权重都是相等的
2. 计算错误率
利用第一个弱分类器进行学习,计算分类错误率。
其中分类错误率ε:
未正确分类的样本数 所有样本数
3. 计算弱分类器权重
利用错误率计算每个弱分类器的权重,对于正确分类的样本,降低它的权重,对于错误分类的样本,增大它的权重
其中当前弱分类器的权重α:
4. 更新样本权重
通过当前样本权重,重新调整下一轮样本的权重,使得当前被错分的样本权重提高
其中下一轮的样本权重
此时的 是一个归一化因子:
上面的式子可以化简为下面这样:
通过这个公式,我们就可以计算在下一轮的样本权重,其中 表示第t+1轮的第i个样本的权重
5. 重复学习
经过t轮的学习后,会得到t个弱分类的算法,,也就是最终的强弱分类器
此时的强分类器是由t个弱分类器组成,每一个弱学习器都是当前轮最优的弱分类器
用公式表示:
其中,sign是符号函数,表示第i轮中选择选择最优的弱分类器
到此,Adaboost 的流程就结束了,是不是感觉似懂非懂?
ok,看个例子吧
例:Adaboost分类
假设有10个训练样本,需要通过Adaboost构建一个强分类器。样本数据如下:
 点击看大图
点击看大图
针对当前样本数据,我们的基础分类器有三个,分别如下:
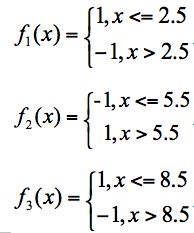
三个基础分类器
①首先赋权重
根据Adaboost 分类的性质,我们需要为每个样本赋予相等的权重,也就是每个样本的权重w = 1/10 = 0.1,即初始权重D1=(0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1)
②进行第一轮的训练
针对每个样本,我们使用三个基分类器进行分类并计算分类错误率,此时:
分类器f1的错误率是0.1*3,即x取6、7、8时分类错误
分类器f2的错误率是0.1*4,即x取0、1、2、9分类错误
分类器f3的错误率是0.1*3,即x取3、4、5时分类错误
根据误差率最小,我们选择f1为第一轮的最优分类器(或f3分类器也可),此时根据权重计算公式第一个分类器的权重为:
根据第一个分类器更新样本的权重(这一步的目的是对于上面分类错误的样本点6、7、8增大权重),权重的更新公式如下:
对应的我们计算出新的样本权重为:D2=(0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715)。
③进行第二轮的训练
同理此时三个基分类器的错误率:
分类器 f1 的错误率为 0.1666 * 3,也就是 x 取值为 6、7、8 时分类错误。
分类器 f2 的错误率为 0.0715 * 4,即 x 取值为 0、1、2、9 时分类错误。
分类器 f3 的错误率为 0.0715 * 3,即 x 取值 3、4、5时分类错误。
根据误差率最小,我们选择f3作为第二轮的最优分类器,根据此时的错误率计算第二个分类器的权重:
同理可以得到D3=(0.0455,0.0455,0.0455,0.1667, 0.1667,0.01667,0.1060, 0.1060, 0.1060, 0.0455)。
④进行第三轮的训练
同样的方法第三轮选择f2分类器为最优分类器,相应的第三个分类器的权重为:
⑤最终的强分类器
基于当前的三轮训练,我们可以得到一个强分类器:
skelarn 应用实战
在sklearn 中调用Adaboost也非常简单
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import AdaBoostRegressor
巧的是,Adaboost可分类可回归,前面介绍的算法中也有好几个是可分类可回归的
AdaBoost 分类器
Adaboost分类器可以使用如下代码进行创建:
# 创建Adaboost 分类器
AdaBoostClassifier(base_estimator=None, n_estimators=50, learning_rate=1.0,algorithm=’SAMME.R’, random_state=None)
其中,有几个主要的参数,小一一一给你介绍一下:
| 参数 | 含义 |
|---|---|
| base_estimator | 代表的是弱分类器,AdaBoost 中默认使用的是决策树 |
| n_estimators | 算法的最大迭代次数,也是分类器的个数。默认是 50 |
| learning_rate | 代表学习率,取值在 0-1 之间,默认是 1.0 |
| algorithm | boosting 算法:SAMME 和 SAMME.R。默认是 SAMME.R |
| random_state | 代表随机数种子的设置,默认是 None |
AdaBoost 回归器
# 创建Adaboost 回归
AdaBoostRegressor(base_estimator=None, n_estimators=50, learning_rate=1.0, loss=‘linear’, random_state=None)
不同的时,在Adaboost回归器中多了一个loss 参数
loss 代表损失函数的设置,提供 linear(线性)、square(平方)和exponential(指数)三种损失函数。默认是线性。这个在回归模型中我们再细说。
Adaboost思维导图
 高清思维导图加小一微信领取
高清思维导图加小一微信领取
写在后面的话
Adaboost 就这一节,没掌握的可以多读几遍,相信你理解起来问题不大。
实战的话这节没有安排,因为是集成算法,前面四篇算法的实战项目都可以拿来做练习,而且在文中也有写到sklearn的相关使用方法,直接拿去用就可以了。
◆ ◆ ◆ ◆ ◆麟哥新书已经在京东上架了,我写了本书:《拿下Offer-数据分析师求职面试指南》,目前京东正在举行100-50活动,大家可以用相当于原价5折的预购价格购买,还是非常划算的:
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
管理员二维码:
猜你喜欢
● 卧槽!原来爬取B站弹幕这么简单● 厉害了!麟哥新书登顶京东销量排行榜!● 笑死人不偿命的知乎沙雕问题排行榜
● 用Python扒出B站那些“惊为天人”的阿婆主!● 你相信逛B站也能学编程吗