一文读懂深度学习经典论文AlexNet(ImageNet Classification with Deep Convolutional Neural Networks)
论文链接: http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
Reference:Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[C]//Advances in neural information processing systems. 2012: 1097-1105.
0.前言
作为深度学习的奠基作之一,论文提出了AlexNet卷积神经网络并应用到图片分类中。当时在著名的计算机视觉领域竞赛(ILSVRC)中取得最好的成绩,这个比赛的任务是将120万张图片分为1000个不同的类别。在读完这篇文章后,就想用来写我第一篇正式的博客,必然有许多错漏之处,还请大家批评指正。
1.文章简介
在这篇文章出现之前,目标识别主要使用的是机器学习方法,当时提高目标识别性能的方法主要是使用更大的数据集,并通过正则化(Regularization)来避免过拟合。AlexNet是首个应用于图像分类的深层卷积神经网络,相较于传统机器学习方法更加出色。AlexNet由五个卷积层、三个最大池化层和三个全连接层组成。
2.模型架构
2.1 创新点
作者在文章3.1-3.4节主要介绍了网络架构中的几个创新点:
使用ReLU激活函数。相较于Sigmoid和tanh等饱和非线性(saturating nonlinearities)函数(意思是这些函数增长到一定阶段就增长缓慢即饱和了),ReLU函数作为不饱和非线性函数(可以一直增长而不减缓速度即不饱和)训练速度更快。
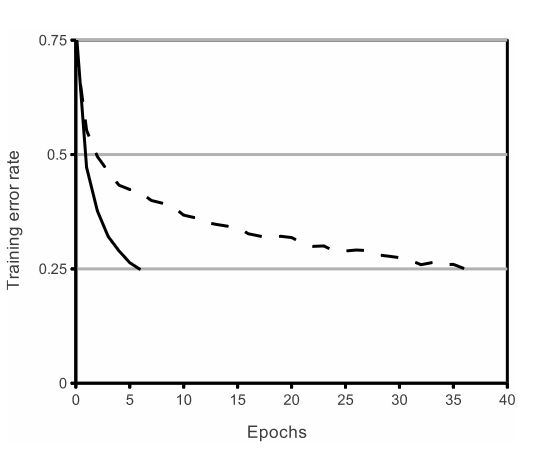
这是文中给出的使用ReLU(实线)和使用tanh(虚线)达到25%训练错误率的对比图,横坐标(Epochs)指的是训练轮数。可以看出,使用ReLU作为激活函数达到25%的错误率仅用了6轮的训练,而使用tanh作为激活函数达到相同的错误率却用了36轮,是前者的6倍。
利用GPU来训练神经网络。作者使用两个GTX 580 GPU进行训练,原因是单个GPU只有3GB内存,不足以训练这么大的网络。因此作者将网络分布在两个GPU上,在每个GPU的显存中储存一半的神经元的参数。当然,随着GPU算力的提升,这种做法现在已经几乎没有了。
使用LRN(Local Response Normalization)归一化方法。这种方法实现了侧抑制(lateral inhibition)。侧抑制是生命科学的概念,指的是兴奋神经元减少其邻近神经元活动的能力。引用到这里的目的是让局部对比度增强,以便将局部最大像素值用作下一层的激励。下面是本文中应用的Inter-Channel LRN公式:
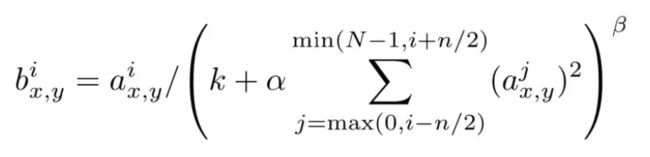
观察式子可以发现,主要参数有:
i 表示第 i 个通道,对于图片来说,不同的颜色代表不同的通道
x,y表示需要归一化的坐标位置
k是常数,为了防止分母为0无法相除
α 和 β是常数
n为邻域的长度。边界情况用0补齐。例如n=2时,在计算(i,x,y)这个点归一化后的值时,只需要考虑(i-1,x,y),(i,x,y)和(i+1,x,y)这三个点的值,从左到右长度为2。如果要计算的点超过了边界,那就不用+1或者-1,用0补全就可以。
其中常数 k、n、α 和 β 为超参数,它们的值由验证集来确定。
上面这个式子看起来比较复杂,可以参考这篇文章来理解:https://zhuanlan.zhihu.com/p/434773836
简单理解就是,我计算归一化不仅考虑到我本身的值,还考虑我左右两边的值。作者认为这样的好处是有利于模型的泛化。现在已经不使用LRN了,而是更多的使用BN,所以看不懂也没关系。
本文参数设置为k = 2, n = 5, α = 10, β = 0.75。作者给出的结论是使用这种方法将 top-1 和 top-5 错误率分别降低了 1.4% 和 1.2%。
使用重叠的最大池化。一般来说,无论是最大池化还是平均池化,相邻池化窗口之间是不会有重叠的。即s(池化窗口移动步长)=z(池化窗口的边长)。而在重叠池化(Overlapping Pooling)里,相邻窗口会有重叠。即s(池化窗口移动步长)
在文中作者将s设置为2,z设置为3。在其他设置不变的情况下,发现比s=2,z=2时,top-1和top-5 的错误率分别减少了0.4% 和0.3%。作者认为重叠池化的做法也减少了过拟合。
至于为什么能减少过拟合,我个人认为重叠池化让信息损失减少,使得模型不那么被数值较大的特征所“主导”。
2.2 模型整体架构
在介绍完创新点后,文章的重头戏就来了。3.5节介绍了模型的整体架构。话不多说,直接看图:
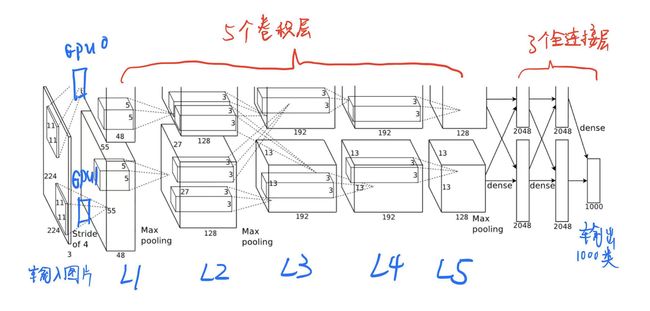
相信很多人和我一样,一开始看到原图是懵逼的,图片好像被切了一部分。为什么最上面有一部分缺失呢?还记得上面说的使用两个GPU吗?所以上面缺失的部分和下面是一样的。下面为了方便分析,我们把每层的运算都认为在一个GPU中运行。
我们从左向右看,最左边是原始图片经过处理后输入的图像,大小为224*224*3。
第一层:卷积–->ReLU–->池化
卷积层1:输入为224*224*3的图像;卷积核大小11*11*3,stride(步长) =4,padding(填充) = 2,卷积核数量为96,因为使用了两个GPU,所以图中一个GPU就是48;计算后输出FeatureMap大小为55*55*96。
ReLU:使用ReLU激活函数。在ReLU后使用LRN归一化。
池化层1:池化核大小为3*3,stride = 2,padding = 0;输出大小为27*27*96。当然一个GPU的话就是27*27*48。
第二层:卷积–->ReLU–->池化
卷积层2:输入为27*27*96;卷积核大小5*5*96,stride = 1,padding = 2,卷积核数量为256个;输出大小为27*27*256。
ReLU:依然ReLU后使用LRN归一化。
池化层:池化核大小为3*3,stride = 2,padding = 0;输出大小为13*13*256。
第三层:卷积–->ReLU
卷积层3:输入为13*13*256;卷积核大小为3*3*256,stride = 1,padding = 1,卷积核数量为384个;输出大小为13*13*384。
ReLU:这里不再使用LRN归一化。
第四层:卷积–->ReLU
卷积层4:输入为13*13*384;卷积核大小为3*3*384,stride = 1,padding = 1,卷积核数量为384个;输出大小为13*13*384。
ReLU:同上。
第五层:卷积–->ReLU–->池化
卷积层5:输入为13*13*384;卷积核大小为3*3*384,stride = 1,padding = 1,卷积核数量为256个;输出大小为13*13*256。
RELU:同上。
池化层2:输入为13*13*256;池化核大小为3*3,stride = 2,padding = 0;输出大小为6*6*256。
第六、七、八层:全连接层 --> softmax
全连接层每一层的神经元个数为4096个,最后接一个 1000 路的 softmax 层,用于分成1000类。
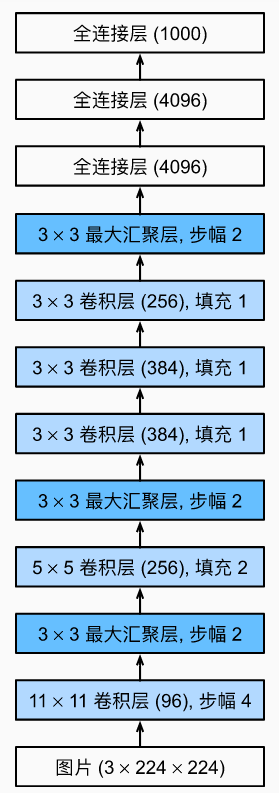
下图为网络结构示意图:
3.减少过拟合
文章在4.1-4.2节介绍了两种减少模型过拟合的方法。那什么是过拟合呢?用李沐大佬的话说,就是给你一些题,你就把他一字不差的背下来,没有理解,最终考试的时候就考不好。其实就是训练集准确率较高而测试集准确率低。
3.1 数据增强
最常用的方法是人为扩增数据集,文章用了两种方法。
第一种方法是从原始图像(256*256)及其水平镜像中,随机裁剪224*224的部分。可以理解用一个224*224的滑块在原始图像上滑动裁剪。这样的话,训练集就比原来扩增了(256-224)*(256-224)*2=2048倍。乘2的原因是还有水平镜像也是一样处理。
第二种方法是改变训练图像中RGB通道的强度。其目的是改变图像的颜色与亮度。
3.2 使用dropout正则化方法
dropout指的是通过随机丢弃神经元来缓解过拟合。其图示如下:
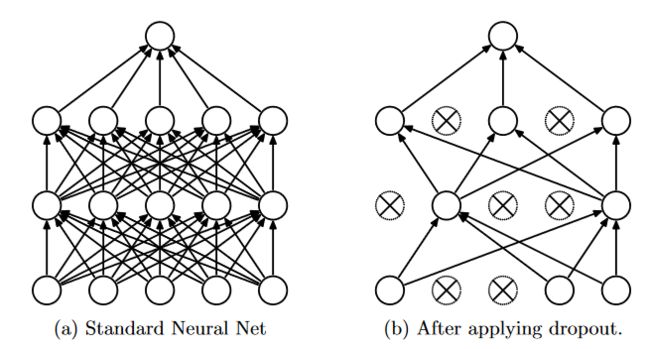
这里就不详细解释dropout了,可以查看有关dropout的参考文档:https://blog.csdn.net/stdcoutzyx/article/details/49022443
4.优化算法
这一部分主要介绍了文章使用的优化算法(Optimization algorithms)。作者实际上使用的是动量梯度下降法训练模型,批量大小(batch size) = 128,动量系数= 0.9,权重衰减系数(weight decay) = 0.0005。
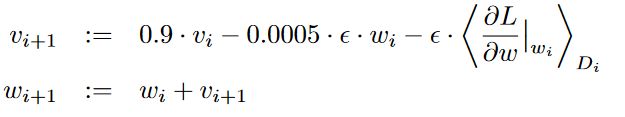
我们来看上面的式子。第一个式子是更新momentum项,其等于(0.9*上一个的momentum) - (weight decay项) - (学习率*梯度) 。第二个式子是更新权重。
5.结论
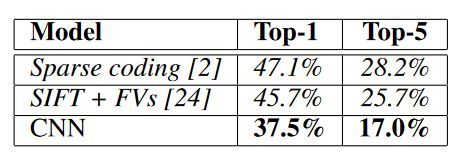
AlexNet在 ILSVRC-2010 的结果如下图所示。加粗的是AlexNet的结果,发现在top-1和top-5的错误率是最低的,分别是37.5%和17%。什么是top-1呢?就是模型的预测结果和正确结果对比,如果相符即预测正确。那什么是top-5呢?就是预测结果的前五个(top-5)与正确结果对比,其中一个相符即预测正确。所以一般top-5的错误率是比top-1低很多的。
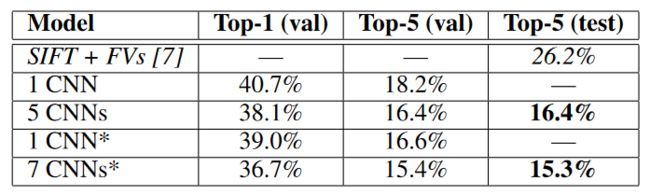
作者又将模型放到ILSVRC-2012 竞赛中。结果如下图所示。由于ILSVRC-2012测试集标签没有公布,我们主要看验证集的错误率。5CNNs的意思是5 个模型组成的集成模型。
6.讨论
作者在文章最后一部分,给出了一些想法与讨论。
网络深度对于结果十分重要。如果移除单个卷积层,网络性能会下降。移除任何中间层会导致网络top-1的性能损失约2%。
使用无监督的预训练预计会对结果有所帮助。
作者希望卷积神经网络也能应用到视频图像处理中。
参考文献:
1. AlexNet 论文详解: https://zhuanlan.zhihu.com/p/69273192
2.【深度学习】AlexNet原理解析及实现: http://t.csdn.cn/9Kf8E
3. AlexNet: https://towardsdatascience.com/alexnet-8b05c5eb88d4
4.动手学深度学习: https://zh-v2.d2l.ai/chapter_convolutional-modern/alexnet.html
5.理解dropout: http://t.csdn.cn/A4KZH