chatgpt的一些思考
中文RLHF大模型开发阶段,谁愿意手上有高性能的显卡可以支持文章评论处聊(审核不允许通讯方式)
代码中,6B参数模型调试中,现在受显卡影响进度很严重
结论
国内同行对chatgpt的认识是不够的,太轻视这个模式的颠覆性认知
chatgpt是对思维过程的仿真,rlhf过程就是通过强化学习方式在利用人思维过程训练模型
chatgpt比搜索更通用化,搜索是对单个点信息的匹配,chatgpt是对思维链一个序列数据的匹配,所以通用性和能力更强
chatgpt绝对不是简单的训练数据量大打来的所谓涌现效果,数据量大是基础,但是对思维模式的仿真才是它强大的原因
更重要的是去学习决策的过程,而不仅仅是学习决策的输入和输出,即不是 Behavior Cloning 而是 Procedure Cloning 。通过把 HPO 问题建模成一个序列预测问题,让 Transformer 去学习整个 HPO 的搜索轨迹,这样做能够更多地学习到数据内部更本质的东西,而不只是简单的做输入(任务名和搜索空间)和输出(最优超参数)之间的暴力映射,学习决策过程这样的训练过程将会对下游任务有更好的泛化性。
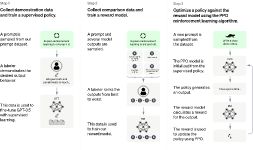
可能的应用场景
机器更理解人意图后,在人机交互肯定颠覆影响
一个好的技术是会对组织结构和社会产生重大变化,互联网的出现把人类信息数据部分的上传留在网络,人类得以更好回顾历史,参考历史;而chatgpt的出现时对全网信息的学习整理,对数据做了更近一层的理解,梳理总结出更优秀的人类思维范例,更合理的为你组织信息,引导你的创造性;把人类的知识由静态的数据和简单的堆叠在一起的数据,变成活泼可用可以增强丰富人类的智慧和知识。只要利用好一定会对人类文明产生更大帮助。
1.办公软件,其实就是人做了事到机器翻译,数据录入后人话交流可以机器理解翻译,后续工作机器执行产出报表结论,RPA会更进一步智能化
2.ps、AI、3D修改模型(简单的重复控制,没有太强创造性工作),画图也是一样人控制ps页面参数,后续可能人描述任务,机器直接翻译直接控制参数做修改
3.工控交互界面
4人机交互小助手
5.适老化电器智能设备

例子
营销文本生成:
选择主题
问题:如何生成对女性有吸引力的营销文案,帮忙生成些主题和关键词
答:
选择关键词
问题:请从{稳健,利润、增长,美丽,好心情,人生......}词列表中,选出10个最优的词来做适合女性基金营销文案生成
答:
生成模版
问题:请用【稳健、利润、增长.....】中任意三个词做组合,产出适合bart模型文案生成的模版
答:
生成句子
问题:请用‘[MASK]稳健[MASK]增长[MASK][MASK]‘模版,生成十句适合女性的差异化基金营销文案
答:
通顺度检测
问题:{'好基金稳健,年收益持续增长','好稳健好增长好好好'......}列表中通顺的句子有哪些
答:
多样性改写
问题:请把'好基金稳健,年收益持续增长'改写10句,适合不同年龄、学历、工作经验女性的基金营销文案
答:
句子挑选
问题:请从{'好基金稳健,年收益持续增长','好稳健好增长好'......}句子中选出10句,作为年底**货币基金营销的文案,要求句子间差异度性最大,句子押韵文风优美
答:
输出
问题:{'好基金稳健,年收益持续增长','好稳健好增长好'......}句子对**人群匹配度有多高,年轻高职高学历未婚用户会最喜欢哪条文案
答:
思考
把人类解决问题的过程,人类解决问题时的思维链做仿真。把人类思维链路作为训练数据,作为强化学习的建模绝对是一次更接近智能本质的探索。
你甚至可以简单理解为
通过强化学习 机器学会了 人的指令转化为gpt3可以理解的指令
或者就是一个编译器
他们找到一个很牛逼的方法来把人的语言转化为gpt3可以准确理解的语言
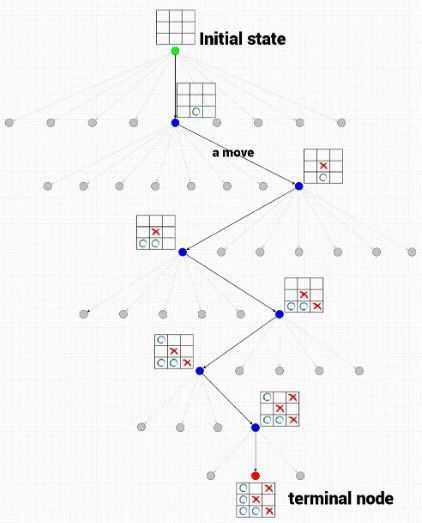
搜索是点匹配全域数据
而chatgpt是一个点选择有限思维链路
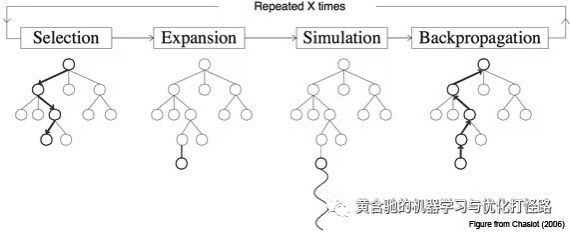
然后通过输入交互数据逐步递进下一个决策状态
思维链路是有限的 每个思维链路下可选状态也是有限的 有点类似多步马尔可夫树搜索
所以chatgpt学习的是思维链
然后通过模型检索在指定链路下的可选集合
并且会通过用户交互信息逐步修正精准答案
举个例子:
写文章,有两个思维链模式(可以是显式的也可能是隐式的),
主题——大纲——每段论据——论据支撑——论据衔接文字
主题——关键——关键词衍生段落——段落句子——句子衔接顺序
用户在输入写作命令+写的信息后,chatgpt隐或显的选择了一个思维链,然后用有限的‘写的信息’写出一些东西,然后把检索到的信息案思维链一步一步扩展出可能的门特卡洛决策树,直到得到最后答案。
所以rlhf训练学习的是思维链,人做事思考的思维链其实是有限的,所以在有限信息下经过这种链+检索方式生产的内容和答案是有逻辑的。但是对于多轮对话,这个问题chatgpt还是没能很好解决,这应该设计到长期记忆和分区记忆信息,现在模式还不具备这种更高级别能力
推测的chatgpt如何建模训练
把这个问题抽象成一个数学问题,建模如下:
把人语描述的指令转化成机器可以明白指令:人语长度*共有文字数 翻译成 指令长度*机器指令token个数
上面问题解空间太大,需要找到一种快速求解方法:RHLF
chatgpt的强化学习建模:
1.agent是gpt3.5
2.action是选择哪个prompt
3.reward是用户是否复制文本、或是否继续交流、或是否再次问相似问题
4.环境是用户
模型迭代:
action选择模型增强,利用用户反馈较好prompt、生成答案训练instruct模型
agent增强,把用户数据和机器生成答案采样迭代更新gpt3.5
训练数据
agent数据,用户提问和机器回答全量数据
action模型数据,用户prompt反馈数据、外包打标数据
代码实现(已经在调试,开源计划中)
reward模型:learn2rank算法的listwise模型
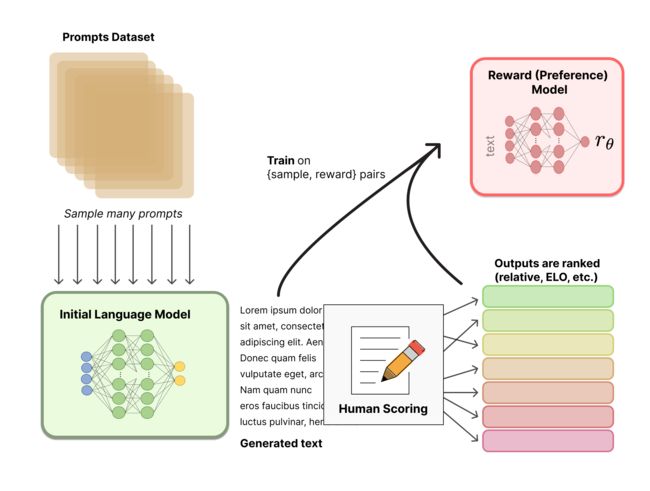
强化学习部分:
约束生成文本质量:参考模型生成文本分布和需要优化模型生成本分布KL
需要优化模型的reward打分(标量),这边是只对优化模型计算reward哦(很多大佬对论文解读,是把参考模型和优化模型生成文本做pair,然后用pairwise做打分优化,参考论文他们讲解是有问题的)

Instrcut模型如何训练
为了减少创建和验证有效指令所涉及的人工成本,作者提出将用自动提示工程师 (Automatic Prompt Engineer, APE)算法来生成有效指导 LLM 的指令,即自然语言程序合成(natural language program synthesis),如下图 (a) 所示,将其作为黑盒优化问题处理,使用 LLM 生成和搜索一些可行的候选解决方案。
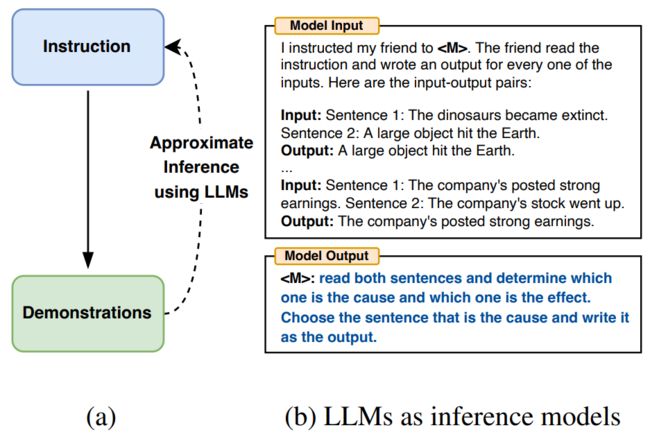
▲图1 使用LLM作为推理模型来填充空白
作者将以三种方式来利用 LLM 的通用能力:
首先,基于“输入-输出对”形式的小集合,使用 LLM 作为推理模型生成候选指令,如上图(b)所示,使用 LLM 作为推理模型来填充空白,此算法涉及到搜索推理模型所提出的候选指令。
其次,通过为想要控制的 LLM 下的每条指令计算一个分数来指导搜索过程。
最后,提出一种迭代蒙特卡洛搜索方法,LLM 通过提出语义相似的指令变体来改进最佳候选指令。
总之,该算法要求 LLM 根据示例生成一组候选指令集,然后再评估其中哪些更有效。即自动地为通过输出示例指定的任务生成指令:通过直接推理或基于语义相似性的递归过程生成几个候选指令,用目标模型执行它们,并根据计算出的评估分数选择最合适的指令。
算法介绍
对于一个包含从总体 中采样的输入-输出示例的数据集 和一个提示模型 指定的任务,自然语言程序合成的目标是找到这样的一条指令 ,使得当用指令和给定输入的拼接 提示 时, 产生相应的输出 。即将其构建为一个优化问题,为找到指令 ,使每个样本分数 的期望最大化,超过可能的 :
本文的算法 APE 在 proposal 和评分这两个关键模块中都使用 LLM。如下图和算法 1 所示,APE 首先提出几个候选提示,然后根据选定的评分函数对候选集合进行筛选和精炼,最终选择得分最高的指令。

▲图2 Automatic Prompt Engineer(APE)方法

▲算法1 Automatic Prompt Engineer(APE)
初始 proposal 分布
由于搜索空间无限大,导致很难找到正确的指令,这也是自然语言程序合成历来的难点。作者考虑用一个预训练的 LLM 找到很好的候选集 来指导整个搜索过程,虽然来自 LLM 的随机样本不太可能产生所需的 对,但可以让 LLM 在给定输入/输出示例的情况下近似推断出最有可能的高分指令,即从 中近似采样。
从 中生成高质量候选项有两种方法:
首先,采用一种基于“正向”模式生成的方法,将这个分布 翻译成单词。例如使用如下图方法提示 LLM:

这表明输出是根据指令生成的,因此其分数函数将很高。尽管“正向”模型对大多数预训练的 LLM 来说都是开箱即用的,但将 转换为单词需要跨不同任务的定制工程。这是因为“正向”模型只从左到右生成文本,而我们希望模型在演示之前预测缺失的上下文。
为了解决这个问题,还考虑了“反向”模式生成,它使用具有填充功能的 LLM(如 T5 和 InsertGPT)来推断缺失的指令。“反向”模型通过填充空白直接从 中采样,使其成为比“正向”模型更通用的方法。如下所示:

评分函数
为了将问题转化为黑盒优化,选择了一个评分函数,该函数可以精确度量数据集和模型生成的数据之间的对齐程度。在 TruthfulQA 实验中,主要关注前人提出的自动化指标,类似于执行准确率。在每个case中,使用等式 (1) 来评估生成指令的质量,并对测试集 计算期望。
执行准确率。使用Honovich等人提出的执行准确率矩阵来评估指令 的质量,将其表示为 。大多数情况下,执行准确率被简单地定义为 0-1 loss,而在某些任务中,则会考虑到不变量。
对数概率。进一步提出一个更偏向 soft 概率的评分函数,假设它可能会通过在搜索低质量候选指令时提供更细粒度的信号来改进优化,尤其考虑了目标模型 下给定指令和问题的期望答案的对数概率,在每个样本的基础上它是 。
有效的评分估计。通过计算所有指令候选的整个训练集的分数来估计分数开销很大,因此为减少计算开销,这里还采用了一种过滤方案,即分配计算资源时,有潜力的候选获得更多,而低质量则获得更少,这可以通过在算法 1 的第 2-9 行使用多阶段计算策略来实现。首先用训练集的一小部分来评估所有候选数据,对于分数大于某个阈值的候选指令,从训练集中采样并评估一个新的非重叠子集,以更新分数的移动平均值,然后,重复这个过程直到留下一小部分候选对象,并在整个训练集上对其进行评估。这种自适应过滤方案保持了高质量样本的精确计算代价的同时,也大大降低了低质量候选的计算代价,从而显著提高了计算效率。
迭代proposal分布
尽管想直接对高质量的初始候选指令进行采样,但可能出现的情况是,上述方法无法产生一个好的 proposal 集(要么是因为缺乏多样性,要么是不包含任何具有合适高分的候选对象),因此作者又研究了重采样 的迭代过程。
迭代蒙特卡洛搜索。考虑在当前最佳候选对象周围局部探索搜索空间,而不仅从初始 proposal 中采样,这便可以生成更可能成功的新指令,作者称这个变体为迭代 APE。在每个阶段,都会评估一组说明,并筛选出得分较低的候选者,然后要求 LLM 生成与高分指令相似的新指令。这里使用 LLM 重采样 ,并对模型提示如下:

而实验结果表明,虽然这种方法提高了proposal 集 的整体质量,但随着阶段的增加,得分最高的指令往往保持不变,因此与前文中描述的生成过程的相对简单和有效性相比,迭代生成提供了边际改善。所以除非另有说明,否则后面的实验中将用没有迭代搜索的 APE。
训练费用:
看阿里云发布的数据:
“最近火爆全网的人工智能产品ChatGPT也是以GPT文本生成模型为底座。虽然GPT大模型作用在这些应用领域的效果很好,但是训练成本非常高。以OpenAI推出的1750亿的GPT-3为例,在1024张A100GPU上预估需要34天,一万亿参数的GPT-3在3072张A100显卡上也至少需要84天;微软/英伟达联合推出的5300亿的NLG模型,在2048张A100显卡上耗时了3个月的训练时间才能达到比较好的收敛效果。”
根据公布数据算了下费用:
gpt3 1750亿参数(45.3t)
一张a100大概10w(就算批量采购打折5w)显卡费用5120w
训练一次大概a100 1024张 34天,一张显卡功率 400w
一次电费33w(电费按一度一块算)
光要把gpt3装进a100 80g的显卡就要600张
就算租用云计算,一次训练费用也在500w(不包括前置数据工程费用)
训练数据费用:
gpt3(2020年数据)570g
lambda 1.1t
InstructGPT(ChatGPT)用了近50TB数据,洗出来50TB,预需要PB级至ZB级的数据,纯算法工程Team 50人以上,数据工程100人以上,配置GPU和CPU的算力支撑保底一年烧掉10个小目标,再加流式数据到应用自如估计烧掉100个小目标软妹币。
QA:
Q:思维链是怎么来,在哪体现
A:instruct其实就是蕴含用户的思维链,训练时候数据中蕴含不一定是显示的数据输入就有思维链这么个数据选项。
Q:大家疑惑我是单问题提问,本没有有序列的提问,openai看起来也没有对数据处理列出个序列做思维链模型学习,何以可以对思维链建模学习
A:其实对深度强化学习熟悉的朋友,应该知道一个训练技巧,就是有意的打乱训练数据中游戏序列顺序、有意的会在游戏顺序数据中插入不相干的随机数据、所以对于模拟人思维链的建模强化学习,在训练数据中前一条和后一条数据并非信息连贯有上下文关系、甚至前一条数据和后一条数据毫不相干,只要数据量大对模型效果影响是不大的

LaMDA通过学习使用利用外部知识源去缓解这个问题。LaMDA构建一个包含信息检索系统,计算模块,翻译模块的工具(简称TS),这部分的finetune也包括两个子任务,第一个是将历史上文跟模型回复一起输入到模型中,生成对应的检索query。第二个子任务是将历史上文+模型回复+检索结果一同输入到模型中,让模型决定是生成新的检索query或者生成最终回复(根据生成的第一个字符串决定,如果是TS,则继续检索,如果是User则返回对应结果)
LaMDA和chatgpt是同类技术路线产品,LaMDA论文曝光的更详细技术实现细节,可以看到LaMDA是有更显示的思维链在里面。
注:
我讲的打乱顺序:
用文本生成举例吧
并没有哪个用户会按选主题、生成提纲、每个提纲在做观点生成、每个观点在做论据生成..这么十几步的顺序和agent交互,所以按理来讲数据是没办法想游戏一样 有个交互序列,那agent是如何学会写作的这套链路的
还有就是有一千多万的用户
每个用户问的问题之间是没有上下文和相关性的
那么这些数据在训练时候也是没有一个序列的
agent又是如何在看起来有点乱数据里面学到 做事的序列的呢
文本现在还比较乱,可以看作是我在实践工作之余的,一个脑暴和灵感的记录
个人觉得chatgpt在rlhf这个模式上用的非常棒(不管是技术、经营、产品)所以急急忙忙分享出来
给大家造成的阅读困扰,在此深表歉意;后面空下来有整块时间我会再重新整理(估计要很久后了)
但是此期间我会不间断的跟新自己一些使用体悟和自己一些主观想法
各位看官,贻笑大方了