【深度学习模型】ChatGPT原理简述
文章目录
- 前言
- 1. GPT的前世今生
-
- 1.1 OpenAI及GPT系列
- 1.2 ChatGPT及同期对比模型
- 2. 技术原理
-
- 2.1 预训练语言模型
- 2.2 训练奖励模型
- 2.3 用强化学习微调
- 3. 目前缺陷
- 参考文献
前言
2022年11月30日,OpenAI推出人工智能聊天模型ChatGPT(ChatGPT: Optimizing Language Models for Dialogue),很快引起百万用户注册使用,公众号和热搜不断,迅速火出圈,甚至引起各大公司在聊天对话机器人上的军备竞赛。
1. GPT的前世今生
1.1 OpenAI及GPT系列
OpenAI(开放人工智能)是美国一个人工智能研究实验室,成立于2015年底,由营利组织 OpenAI LP 与母公司非营利组织 OpenAI Inc 所组成,目的是促进和发展友好的人工智能,使人类整体受益。
OpenAI 的代表作为 GPT系列自然语言处理模型。从2018年开始,OpenAI就开始发布生成式预训练语言模型GPT(Generative Pre-trained Transformer),此后还有2019年2月的GPT-2,2020年5月的GPT-3。GPT模型参数爆炸式增加,而其效果也越来越好。GPT-3的效果不输于当时统治地位的BERT,只是因为没有开源开放,所以知名度没那么高。到了2022年11月30日,OpenAI发布了ChatGPT,在研究预览期间,用户注册并登陆后可免费使用,这才一下子火出圈(但该项目对一些包括中国大陆、香港在内的地区暂不可用)。

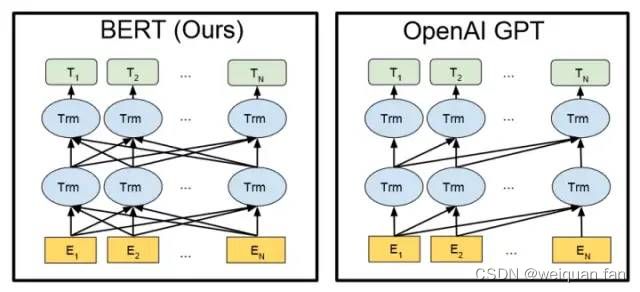
其中,BERT和GPT的示意图如下。它们都基于Transformer模型,前者是双向的,后者的单向的。
1.2 ChatGPT及同期对比模型
据悉,ChatGPT 基于GPT-3.5架构开发,是InstructGPT的兄弟模型。基于开源期间收集到的大量对话数据,之后还可能进一步推出 GPT-4。
目前,ChatGPT 具有以下特征:
1)可以主动承认自身错误。若用户指出其错误,模型会听取意见并优化答案。
2)ChatGPT 可以质疑不正确的问题。例如被询问 “哥伦布 2015 年来到美国的情景” 的问题时,机器人会说明哥伦布不属于这一时代并调整输出结果。
3)ChatGPT 可以承认自身的无知,承认对专业技术的不了解。
4)支持连续多轮对话。
根据广大网友们的反复测试,目前ChatGPT可以进行很大程度的开放式对话,可以问旅游攻略、可以问哲学问题、可以问数学题怎么做、甚至能让它打代码。但是它终究是一个生成式模型,而不是检索式模型,它只能基于到目前为止的数据集来回答,而无法问它明天天气如何。在开放期间,大量的测试数据也在不断地收集着,但是也通过算法屏蔽,过滤掉了有害的输入样本。
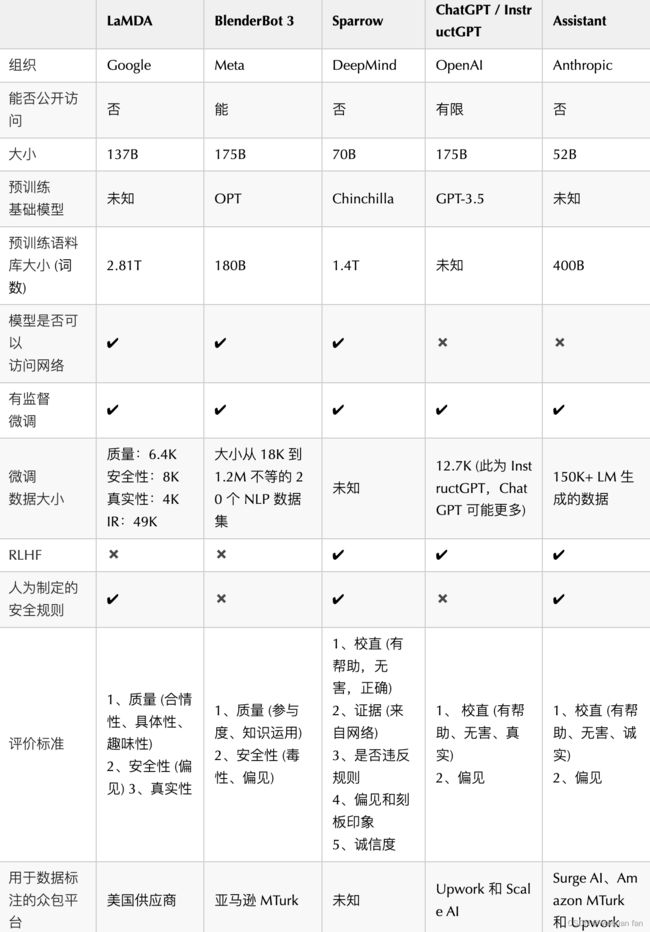
与ChatGPT同期,各大互联网公司都有自己相应的聊天机器人,以下是其对比表。
2. 技术原理
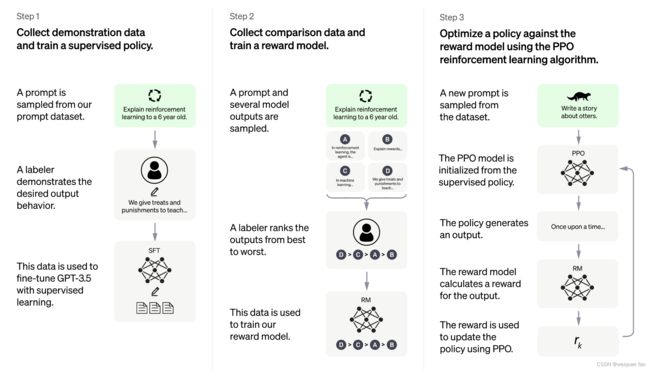
由于ChatGPT的细节尚未公布,按照InstructGPT来看,它与GPT-3的主要区别在于使用了RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习),即以强化学习方式依据人类反馈优化语言模型,通过对人类知识的引入,训练出更合理的对话模型。
其中,RLHF 是一项涉及多个模型和不同训练阶段的复杂概念,可以分解为三个步骤:
- 预训练一个语言模型 (LM) ;
- 聚合问答数据并训练一个奖励模型 (Reward Model,RM) ;
- 用强化学习 (RL) 方式微调 LM。
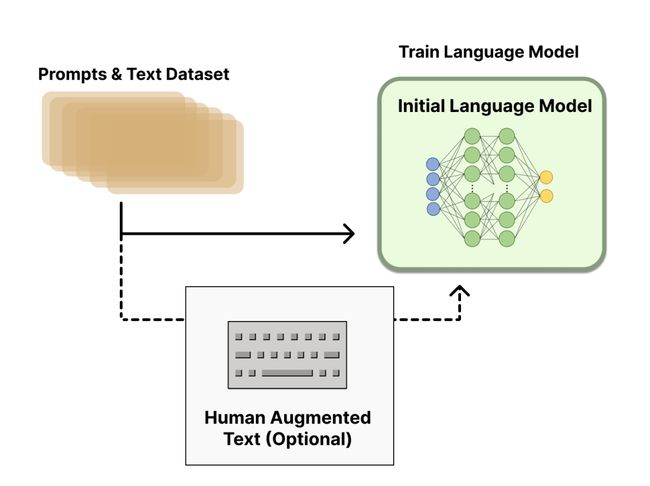
2.1 预训练语言模型
该步骤可以获得SFT(Supervised Fine-Tuning)模型。ChatGPT基于 GPT-3.5的LM,并通过额外的文本或条件进行微调(这是可选的)。OpenAI 对 “更可取” (preferable) 的人工生成文本进行了微调,其中“更可取”的评价标准包括有:
- 真实性:是虚假信息还是误导性信息?
- 无害性:它是否对人或环境造成身体或精神上的伤害?
- 有用性:它是否解决了用户的任务?
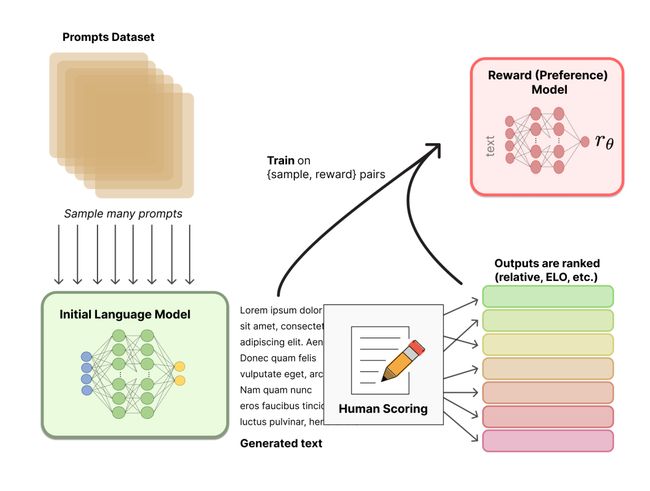
2.2 训练奖励模型
该步骤可以获得RM(Reward Model)模型。
关于模型选择方面,RM 可以是另一个经过微调的 LM,也可以是根据偏好数据从头开始训练的 LM。
关于训练文本方面,RM 的提示 - 生成对文本是从预定义数据集中采样生成的,并用初始的 LM 给这些提示生成文本。
关于训练奖励数值方面,需要人工对 LM 生成的回答进行排名。起初作者认为应该直接对文本标注分数来训练 RM,但是由于标注者的价值观不同导致这些分数未经过校准并且充满噪音,而通过排名可以比较多个模型的输出并构建更好的规范数据集。
对具体的排名方式,一种成功的方式是对不同 LM 在相同提示下的输出进行比较,然后使用 Elo 系统建立一个完整的排名。这些不同的排名结果将被归一化为用于训练的标量奖励值。
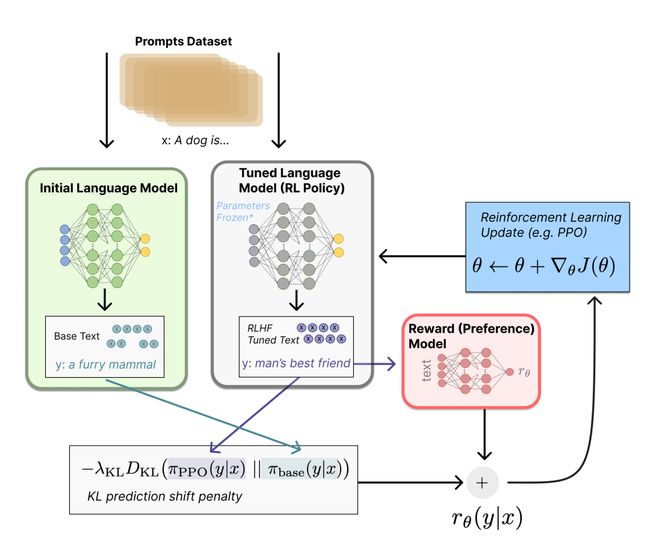
2.3 用强化学习微调
首先将微调任务表述为强化学习问题。首先,策略 (policy) 是一个接受提示并返回一系列文本 (或文本的概率分布) 的 LM。这个策略的行动空间 (action space) 是 LM 的词表对应的所有词元 (一般在 50k 数量级) ,观察空间 (observation space) 是可能的输入词元序列,也比较大 (词汇量 ^ 输入标记的数量) 。奖励函数是偏好模型和策略转变约束 的结合。
通过近端策略优化 (Proximal Policy Optimization,PPO) 微调初始 LM 的部分或全部参数。对一个输入文本,根据第一步骤的初始 LM 和当前微调的 LM,可以分别得到输出文本 y1,y2,这两个输出通过Kullback–Leibler (KL) 散度进行约束。并结合对当前微调LM的输出通过第二步骤的RM得到的奖励值,通过PPO进行优化。
3. 目前缺陷
尽管ChatGPT表现出出色的上下文对话能力甚至编程能力,完成了大众对人机对话机器人(ChatBot)从“人工智障”到“有趣”的印象改观,我们也要看到,ChatGPT技术仍然有一些局限性,还在不断的进步。
1)ChatGPT在其未经大量语料训练的领域缺乏“人类常识”和引申能力,甚至会一本正经的“胡说八道”。ChatGPT在很多领域可以“创造答案”,但当用户寻求正确答案时,ChatGPT也有可能给出有误导的回答。例如让ChatGPT做一道小学应用题,尽管它可以写出一长串计算过程,但最后答案却是错误的。
2)ChatGPT无法处理复杂冗长或者特别专业的语言结构。对于来自金融、自然科学或医学等非常专业领域的问题,如果没有进行足够的语料“喂食”,ChatGPT可能无法生成适当的回答。
3)ChatGPT需要非常大量的算力(芯片)来支持其训练和部署。抛开需要大量语料数据训练模型不说,在目前,ChatGPT在应用时仍然需要大算力的服务器支持,而这些服务器的成本是普通用户无法承受的,即便数十亿个参数的模型也需要惊人数量的计算资源才能运行和训练。,如果面向真实搜索引擎的数以亿记的用户请求,如采取目前通行的免费策略,任何企业都难以承受这一成本。因此对于普通大众来说,还需等待更轻量型的模型或更高性价比的算力平台。
4)ChatGPT还没法在线的把新知识纳入其中,而出现一些新知识就去重新预训练GPT模型也是不现实的,无论是训练时间或训练成本,都是普通训练者难以接受的。如果对于新知识采取在线训练的模式,看上去可行且语料成本相对较低,但是很容易由于新数据的引入而导致对原有知识的灾难性遗忘的问题。
5)ChatGPT仍然是黑盒模型。目前还未能对ChatGPT的内在算法逻辑进行分解,因此并不能保证ChatGPT不会产生攻击甚至伤害用户的表述。
参考文献
- ChatGPT发展历程、原理、技术架构详解和产业未来
- ChatGPT 背后的“功臣”——RLHF 技术详解
- 解读 ChatGPT 背后的技术重点:RLHF、IFT、CoT、红蓝对抗