ChatGPT is not all you need,一文看尽SOTA生成式AI模型:6大公司9大类别21个模型全回顾(三)
文章目录
- ChatGPT is not all you need,一文看尽SOTA生成式AI模型:6大公司9大类别21个模型全回顾(三)
-
- Text-to-Text 模型
-
- ChatGPT
- LaMDA
- PEER
- Meta AI Speech from Brain
- Text-to-Code 模型
-
- Codex
- Alphacode
- Text-to-Science 模型
-
- Galactica
- Minerva
- 其他模型
-
- AlphaTensor
- GATO
- PhysDiff
- ChatBCG
ChatGPT is not all you need,一文看尽SOTA生成式AI模型:6大公司9大类别21个模型全回顾(三)
AI生成模型可不止ChatGPT一个,光是基于文本输入的就有7种——图像、视频、代码、3D模型、音频、文本、科学知识…尤其2022年,效果好的AI生成模型层出不穷,又以OpenAI、Meta、DeepMind和谷歌等为核心,发了不少达到SOTA的模型。
随着技术的进步,我们已经在文本到图像或文本到音频等任务中看到了大量的创造力和个性化。它们在文本到科学或文本到代码的任务中也很准确。这在很大程度上可以提升我们的自动化水平,帮助优化创造性和非创造性任务。
今天我们继续学习由西班牙科米利亚斯主教大学(Comillas Pontifical University)的研究人员提交的综述论文《ChatGPT is not all you need. A State of the Art Review of large Generative AI models》。
论文:ChatGPT is not all you need. A State of the Art Review of large Generative AI models
机构:Quantitative Methods Department, Universidad Pontificia Comillas, Madrid, Spain
作者:Roberto Gozalo-Brizuela, Eduardo C. Garrido-Merch´an
地址:https://arxiv.org/pdf/2301.04655.pdf
大家可以回顾第一部分,第二部分的内容:
传送门1:ChatGPT is not all you need,一文看尽SOTA生成式AI模型:6大公司9大类别21个模型全回顾(一)
传送门2:ChatGPT is not all you need,一文看尽SOTA生成式AI模型:6大公司9大类别21个模型全回顾(二)
这第三部分,我们接着来看Text-to-Text,Text-to-Code,Text-to-Science和其他模型的一些细节。
- ChatGPT is not all you need,一文看尽SOTA生成式AI模型:6大公司9大类别21个模型全回顾(三)
- Text-to-Text 模型
- ChatGPT
- LaMDA
- PEER
- Meta AI Speech from Brain
- Text-to-Code 模型
- Codex
- Alphacode
- Text-to-Science 模型
- Galactica
- Minerva
- 其他模型
- AlphaTensor
- GATO
- PhysDiff
- ChatBCG
- Text-to-Text 模型
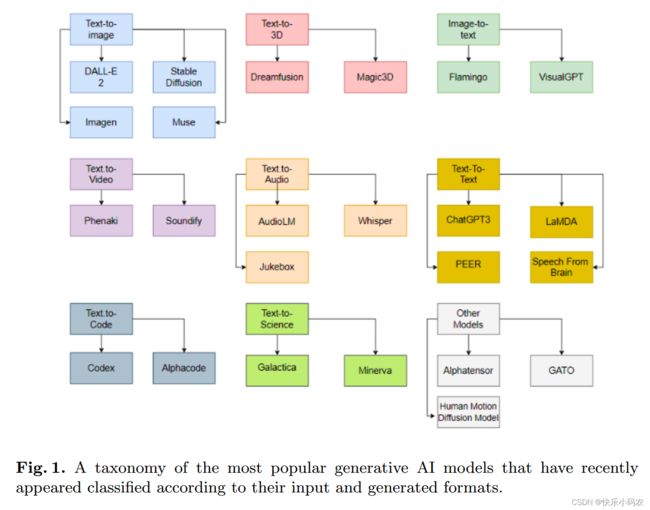
Text-to-Text 模型
前面的模型都将非结构化数据类型转换为另一种类型。但是,关于文本,将文本转换为另一个文本是非常有用的,以满足一般问题和回答的任务。以下四个模型处理文本并输出文本以满足不同的需求。
ChatGPT
最近广受欢迎的 ChatGPT 由 OpenAI 开发,是一个AI对话生成工具,懂得回答问题、拒绝不正当的问题请求并质疑不正确的问题前提。具体地,ChatGPT 背后的算法是Transformer,训练过程主要是通过人类反馈的强化学习(RLHF)算法,即在强化学习阶段,通过拟合大量的人工标注的偏好数据,来对齐大规模语言模型和人类偏好,从而给出令人满意的有用(Helpful)、可靠(Honest)和无害(Harmless)的回答。除了以对话的方式与用户进行互动,也可以生成代码和进行简单数学运算。
如下图14所示 ChatGPT 的训练过程,有监督学习和强化学习两阶段,需要训练监督模型、偏好模型和强化模型,已经抛弃了传统的 LM 方式。
| 训练监督模型 | 训练偏好模型 | 训练强化模型 |
|---|---|---|
| 1.大量标注:采样随机请求,人类训练师撰写预期回答。2.监督训练:微调预训练模型(GPT-3.5),请求(Prompt)–> 回答(人工)。3.主要目标:具备一定的对话能力。 | 1.大量标注:采样随机请求,人类训练师给生成的多个候选回答进行质量排序。2.偏序训练:微调预训练模型(GPT-3.5),请求(Prompt)+回答 --> 评分(浮点数)。3.蒸馏偏好:人类反馈。 | 采用强化学习PPO算法,以监督模型初始化,最大化偏好模型的反馈奖励。 |
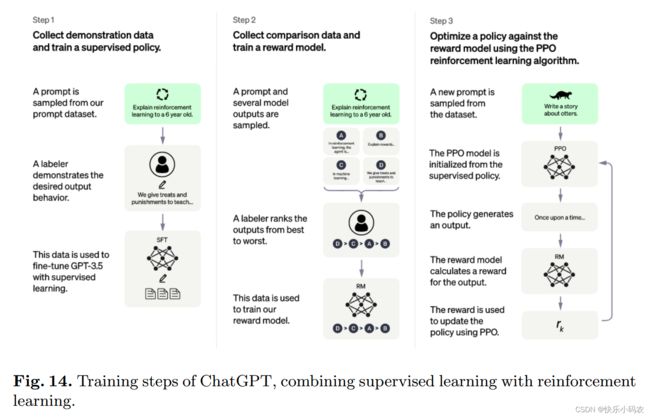
ChatGPT 成功背后的最重要技术是 RLHF(Reinforcement Learning from Human Feedback)算法。RLHF 的训练过程可以分解为三个核心步骤:
- 预训练语言模型(LM)
- 收集数据并训练奖励模型
- 通过强化学习微调 LM
所以,ChatGPT 模型上基本上和之前 GPT-3 都没有太大变化,主要变化的是训练策略变了,用上了强化学习。强化学习非常像生物进化,模型在给定的环境中,不断地根据环境的惩罚和奖励(reward),拟合到一个最适应环境的状态。图14展示的训练步骤,重点是第二步,如何建一个 reward 函数。而在 ChatGPT 里,具体就是找了40个外包公司不断地从模型的输出结果中筛选,判断哪些句子是好的,哪些是低质量的,这样就可以训练得到一个 reward 模型。通过 reward 模型来评价模型的输出结果好坏。
虽然 ChatGPT 为代表的 RLHF 技术非常有影响力,引发了巨大的关注,但仍然存在若干局限性:
- RLHF 范式训练出来的这些模型虽然效果更好,但仍然可能输出有害或事实上不准确的文本。
- 在基于 RLHF 范式训练模型时,人工标注的成本是非常高昂的,而 RLHF 性能最终仅能达到标注人员的知识水平。
- RLHF的流程还有很多值得改进的地方,其中,改进 RL 优化器显得尤为重要。
LaMDA
LaMDA 是超过 50 多位谷歌研究者参与撰写的论文《 LaMDA: Language Models for Dialog Applications 》中介绍的一个语言模型,与大多数其他语言模型不同,LaMDA接受了对话训练。
LaMDA 模型基于 Transformer 开发,专门用于对话,具有 1370 亿个参数,在1.56T的公共对话数据集和其他公开网页文本上进行预训练,只有0.001%的训练数据被用于微调,这也是它效果好的原因之一。特别地,LaMDA 的对话框模式利用了 Transformer 在文本中呈现长期依赖关系的能力。
LaMDA 在技术上没什么新突破,但提供了很多有价值的落地方案参考。首先,对于训练对话模型来说,定义目标和指标至关重要。LaMDA 模型具有质量、安全和扎实性三个关键目标,每个目标有各自的衡量指标。
- Sensibleness, Specificity, Interestingness:是否合理、符合上下文、有创造力。
- Safety:是否有风险、不公正。
- Groundedness、Informativeness:在知识型问答中,是否包含真实的信息、并引用相关链接。
其次,LaMDA 用单个大模型实现整个端到端的问答。模型结构采用decoder-only Transformer,类似 GPT 的自回归模型, 做到了同时「生成+排序」。
第三,LaMDA 的一个最关键的创新点是融入知识。模型有时会生成很多看起来合理,但不合逻辑的回复。一种方案是增加模型大小,从而让它很好地记忆训练数据中的外部知识。而LaMDA提出了一种模拟人类先研究后回复的训练方案,从而让模型更好利用外部知识。如下图15是 LaMDA 的一段有意思的对话。

PEER
PEER 是由 Meta AI Research 和卡内基梅隆大学的研究人员提出的一个新的文本生成模型,基于维基百科编辑历史进行训练,直到模型掌握完整的写作流程。
PEER 基于四个步骤:计划(Plan),编辑(Edit),解释(Explain),重复(Repeat),完全模拟人类写作文的过程,从打草稿、征求建议到编辑文本,再不断迭代。重复这些步骤,直到文本处于不需要进一步更新的满意状态。该模型允许将写作任务分解成更多子任务,并允许人类随时干预,引导模型写出人类想要的作品。

PEER 解决了传统语言模型只会生成最终结果,并且生成文本无法控制的问题,通过输入自然语言命令,PEER可以对生成文本进行修改。
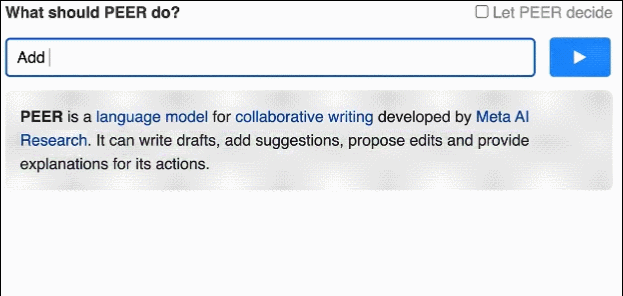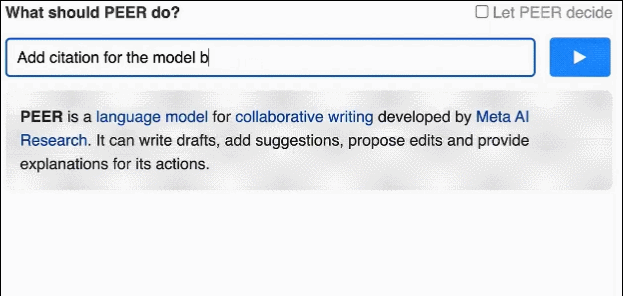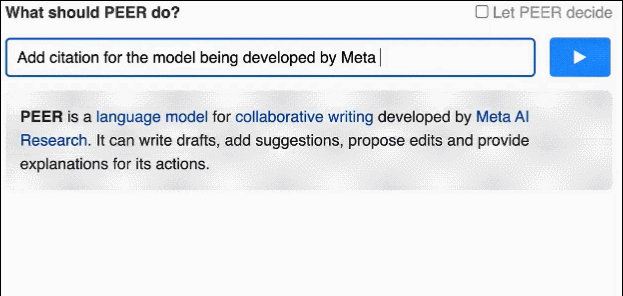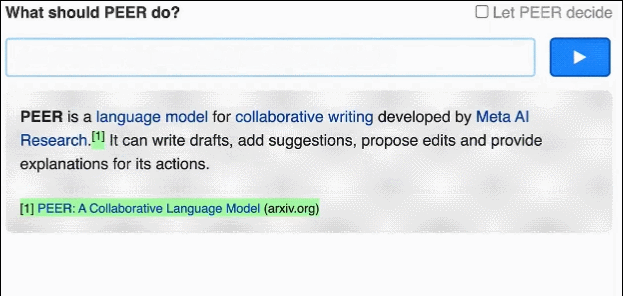
最重要的是,PEER 使用**自我训练(self-training)**方法提高训练数据的质量、数量以及多样性。具体地,训练多个PEER实例,并用这些实例学习填充写作过程中的多个环节。这些模型可以用来生成合成数据作为训练语料库中缺失部分的替代。
但是,模型依靠维基百科作为训练数据的唯一来源存在缺陷:
- 仅使用维基百科训练得到的模型在预期文本内容的样子和预测的计划和编辑方面需要和维基百科相似。
- 维基百科中的评论是有噪音的,因此在许多情况下,评论并不是计划或解释的恰当输入。
- 维基百科中的许多段落不包含任何引文,虽然这种背景信息的缺乏可以通过使用检索系统来弥补,但即使这样的系统也可能无法为许多编辑找到支持性的背景信息。
Meta AI Speech from Brain
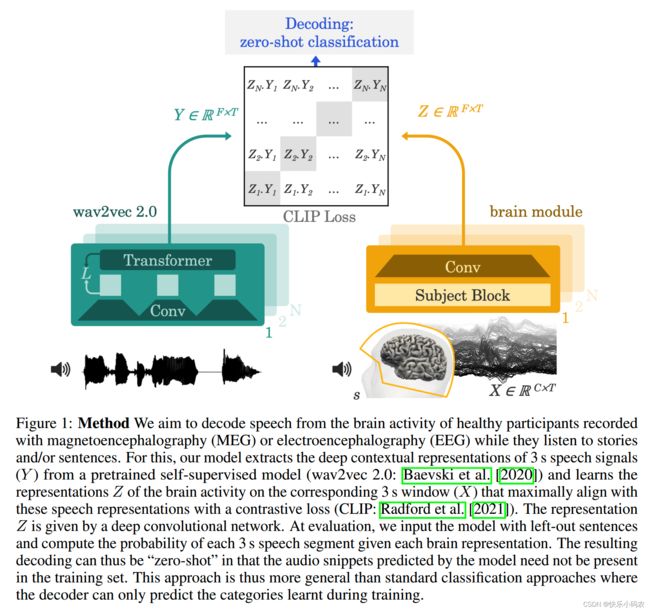
Speech from Brain 是由 Meta AI 开发的AI模型,可以根据大脑活动的无创记录解码语音,相关论文是《从非侵入性大脑记录解码语音》(Decoding speech from non-invasive brain recordings)。具体地,首先使用深度学习方法对语音输入和对应的脑电(磁)图信号进行解码,得到深层次的特征表示;然后,应用对比学习策略匹配两种模态的潜在特征表示;最终,在四个公共数据集上评估了该模型。
目前,从大脑活动中解码语音的大多数进展,依赖于侵入性大脑记录技术,例如立体定向脑电图和脑皮层电图。但相较于无创方法,它们需要打开头骨并将电极直接放在大脑本身上,对人有一定风险和危害性。而 Meta AI 提出的模型试图从非侵入性大脑记录中直接解码语言。这将提供一个更安全、更可扩展的解决方案,使更多人受益。这种方法的挑战来自于噪音和每个人的大脑以及传感器放置位置的差异。
为了解决这个问题,Meta AI 的研究人员转向机器学习算法来帮助“清理”噪声。他们使用的模型称为 wave2vec 2.0,这是该团队在 2020 年研发的开源自监督学习 AI 工具,可用于从嘈杂的音频中识别正确的语音。
具体来说,研究人员专注于脑电图和脑磁图两种非侵入性技术,他们在这两种方式的四个开源录音上,对 wave2vec 2.0 进行了训练。训练数据集包括来自 169 名健康志愿者,在听有声读物和孤立句子(英语和荷兰语)时,大脑活动的 150 多个小时的录音。该团队还将这些脑电图/EEG和脑磁图/MEG的记录输入到一个“大脑”模型中,该模型由一个带有残差连接的标准深度卷积网络组成。
为了从非侵入性大脑信号中解码语音,Meta AI 提出一种单一的端到端架构,用对比学习的方式在大量的个体群中进行训练,以预测自然语音的自监督表示。
值得一提的是,Meta AI 在之前工作中,使用 wav2vec 2.0 证明了该算法可生成与大脑相似的语音表示。如下图所示。wav2vec 2.0 中语音“类脑”表示的特点使其成为构建解码器的理想选择,它有助于了解应该从大脑信号中提取哪些表示。

进一步分析表明,该算法的几个组成部分,包括 wav2vec 2.0 和主题层,有利于解码性能。此外,算法随着脑电图/EEG和脑磁图/MEG记录的增加而改进。尽管数据中存在噪声和可变性,但经过自我监督训练的AI可以解码反常的语音。总的来说,这项研究的最大局限是它专注于解码语音感知,但最终目标是将此项研究扩展到语音生成。
Text-to-Code 模型
和Text-to-Text类似,但并非所有文本都遵循相同的语法。一种特殊类型的文本是代码。
Codex
Codex 是由 OpenAI 开发的将文本翻译为代码的AI系统。Codex 是一个通用编程模型,因为它基本上可以应用于任何编程任务。目前,Codex 最擅长 Python 语言,并且精通 JavaScript、Go、Perl、PHP、Ruby、Swift 、TypeScript 和 Shell 等其他十数种编程语言。Codex 的演示和API可以在OpenAI的网站上找到:https://openai.com/blog/openai-codex/。

编程可以分为两部分:1)将问题分解为更简单的问题,2)将这些问题映射到已经存在的现有代码(库、API或函数)中。其中第二部分是程序员最花时间的部分,也是 Codex 最擅长的地方。
Codex 的目的是让程序员在第一部分上花费更多时间,而不是第二部分。毕竟,大量的代码都是在重复或直接抄袭别人之前所做的事情。
Codex 建立在 OpenAI 的语言生成模型 GPT-3 之上,该模型在大规模的数据上进行训练,可以用来解析和生成文本等功能。GPT-3 的一个应用是生成代码,但是 Codex 改进了代码生成能力,它可以对从网上搜集的开源代码库进行训练。
Codex 基于GPT-3使用code数据进行了Fine-Tuning,模型参数从 12M 到 12B不等。众所周知,在训练大规模预训练模型时,通常是“模型未动,数据先行”。Codex 的训练数据收集于2020年5月 Github上托管的 54,000,000 个公开代码仓,包括 179 GB 文件大小在 1 MB 以下的独一无二的Python文件,在经过过滤后,最终的数据集大小为 159GB。
当然 Codex 还存在一些局限性,Codex 更倾向于“背代码”和做“代码组合”,而没有真正掌握多少编程知识。如果我们把编程能力分为:1. 编程语言知识(语法知识、API功能等);2. 逻辑推理能力(算法能力);3. 利用已有代码的能力(掌握一些常用实现);那么 Codex 在前两点上的能力都比较弱,只在第三点上展现出了强大的能力,从这个角度来看,真正的专业的代码智能依旧任重而道远。
Alphacode
AlphaCode 是由 DeepMind 开发的基于 Transformer 的语言模型,实现了大规模代码生成,并且针对那些需要深度推理的编程问题,能够创建新颖的解决方案。在 10 场有 5000 多名人类参与者的竞赛级别的编程比赛中,AlphaCode 排名位于前 54.3%。也就是说,其已达到了平均人类水平。AlphaCode 相关论文以《可实现完成竞赛级别的代码生成任务的 AlphaCode》(Competition-level code generation with AlphaCode)为题发表在 Science,并成为当期封面论文。
DeepMind 为 AlphaCode 设置了以下三个关键组件,使其得以在代码生成任务中实现可以与人类竞争的水平:一是选用广泛且简洁的竞争性编程数据集,以便进行训练和评估;二是采用大型、且具备高效采样能力的架构;三是通过大规模模型抽样来缩小探索空间,并根据程序行为对一小组提交内容进行过滤。

如上图所示,是 AlphaCode 的方法概述,其系统工作主要分为4个步骤:
- Pre-training:基于一个标准的语言建模目标函数,使用 Transformer 模型架构在GitHub数据集上做预训练。这是一个比Codex预训练数据集更广泛的数据集,总计715.1GB。这样模型可以合理地表征人类编码空间,可以极大地减少搜索量级。
- Fine-tuning:使用带tempering的GOLD目标函数,在编程竞赛数据集CodeContests上做微调。这可以进一步将搜索空间缩小,并可以通过预训练来补偿少量的竞争性编程数据。
- Large scale sampling:为每个问题生成大量样本。用训练完的模型 sample 大量的 solution 出来,并且做过滤和聚类。过滤是为了去掉无法通过样例的代码(会干掉绝大部分),聚类是为了让实现不同但输出相同的代码只提交一次(节约提交的budget)。聚类中,还需要一个独立训练的生成测试数据的模型。这个步骤是针对竞赛题设计的,从这个步骤看,直接用生成的代码直接run错误的概率很高。
- Execute & evaluate:对这些样本进行过滤,并获得数量不超过 10 个的一小组候选样本提交。然后通过使用示例测试和聚类等,对所选样本进行隐藏的测试评估,然后根据程序的反馈来选择样本。
AlphaCode 并不包含关于计算机代码结构的明确的内置知识,相反,它依靠一种纯粹的「数据驱动」方法来编写代码,也就是通过简单地观察大量现有代码来学习计算机程序的结构。从根本上说,使 AlphaCode 在竞争性编程任务上胜过其他系统的原因归结为两个主要属性:1. 训练数据;2. 候选解决方案的后处理。
Text-to-Science 模型
科研文字也是AI文本生成的目标之一,但要任重而道远。
Galactica
Galatica 是由 Meta AI 和 Papers with Code 联合开发的一个学术论文处理领域预训练大模型。Galatica 作为1200亿参数论文写作辅助模型,又被称之为“写论文的Copilot模型”,目的是帮助人们快速总结并从新增论文中得到新结论,在包括生成文本、数学公式、代码、化学式和蛋白质序列等任务上取得了不错的效果,然而一度因为内容生成不可靠被迫下架。 Galactica 试用地址:https://galactica.org/.
Galactica 模型是在一个大型语料库上训练出来的,该语料库包括超过3.6亿条上下文引文和超过5000万条在不同来源中规范化的独特引用。这使得Galactica能够建议引文并帮助发现相关的论文。
Galatica 模型的主要优点是即便进行多个episode的训练后,模型仍然不会过拟合,并且上游和下游的性能会随着token的重复使用而提高。数据集的设计对 Galatica 至关重要,因为所有的数据都是以通用的markdown格式处理的,从而能够混合不同来源的知识。引文(citations)通过一个特定的token来处理,使得研究人员可以在任何输入上下文中预测一个引文。Galactica 模型预测引文的能力会随着规模的提升而提高。
此外,Galatica 模型在仅有解码器的设置中使用了一个Transformer架构,对所有尺寸的模型进行了GeLU激活,从而可以执行涉及SMILES化学公式和蛋白质序列的多模态任务。
研究团队说,Galactica可以存储、组合和推理科学内容。在数学MMLU等基准测试中,它远远超过了Chinchilla(41.3%比35.7%)或PaLM 540B(20.4%比8.8%)等大型语言模型。

图注:Galactica 总结出一篇综述论文
Minerva
Minerva 是由谷歌开发的深度学习语言模型,目的是通过逐步推理解决数学定量问题,可以主动生成相关公式、常数和涉及数值计算的解决方案,也能生成LaTeX、MathJax等公式,而不需要借助计算器来得到最终数学答案。
Minerva 相关论文以《用语言模型解决定量推理问题》(Solving Quantitative Reasoning Problems with Language Models)为题提交在arXiv上。下图是 Minerva 针对一个定量数学问题的输出示例。

Minerva 构建在 Pathways 语言模型(PaLM,5400 亿个参数,密集激活,基于Transformer语言模型)之上,并在一个 118GB 数据集(包括科学论文和含有数学表达式的网页)上进行训练。为了在符号数据上训练模型,训练数据集中保留了数学符号表示。这个过程如下图所示。

Minerva 的一个局限性是模型的答案不能进行自动评估。由于 Minerva 并没有使用底层数学结构来回答问题,这使其无法自动验证答案,因而检测不到“误报”情况。该模型还无法利用计算器或Python解释器等外部工具。因此,它进行需要复杂数值计算的定量推理任务的能力有限。Minerva模型的性能目前与人类的表现还有不小差距。
为了推广量化推理的 NLP 模型,谷歌 AI 分享了一个交互式示例集合:https://minerva-demo.github.io,用于帮助用户探索 Minerva 的能力。

其他模型
除了前面提及的9大类的21个模型,还有其他的生成模型,如Alphatensor、GATO、PhysDiff等。
AlphaTensor
AlphaTensor 由DeepMind开发,懂得自己改进矩阵乘法并提升计算速度,不仅改进了目前最优的4×4矩阵解法,也提升了70多种不同大小矩阵的计算速度,基于“棋类AI”AlphaZero打造,其中棋盘代表要解决的乘法问题,下棋步骤代表解决问题的步骤。

基于深度强化学习方法,智能体 AlphaTensor 的训练过程就是玩一个单人游戏,目标是在有限的因子空间内寻找张量分解。在TensorGame的每一步,玩家需要选择如何结合矩阵的不同entries来进行乘法,并根据达到正确的乘法结果所需的操作数量来获得奖励分数。AlphaTensor 使用一种特殊的神经网络架构来利用合成训练游戏(synthetic training game)的对称性。
GATO
GATO 是由DeepMind开发的通用智能体,它可以作为一个多模态、多任务或多embodiment泛化策略来使用。该模型可用于执行不同模态下(文本、图像、视频、音频等)复杂的计算任务,如生成对话与字幕、玩视频游戏、控制机械臂搭积木等。

在所有任务中使用单一的神经序列模型有很多好处,减少了手工制作具有自身归纳偏见策略模型的需要,并增加了训练数据的数量和多样性。这种通用智能体在大量任务中都取得了成功,并且可以用很少的额外数据进行调整,以便在更多的任务中取得成功。
在 GATO 的训练阶段,来自不同任务和模态的数据被序列化为扁平的 token 序列,并由类似于大型语言模型的 Transformer 神经网络进行批处理。在此过程中,模型的一部分损失函数被选择性地隐藏,以使得 GATO 只对行为决策和文本目标进行学习。

GATO 只有11.8 亿个参数,可以实时控制现实世界机器人的模型规模。与 1750 亿个参数的 GPT-3、巨大的 5400 亿个参数的PaLM 模型或 700 亿个参数的 Chinchilla 相比,它的体量无疑是很小的。
PhysDiff
PhysDiff 是英伟达推出的人体运动生成扩散模型,进一步解决了AI人体生成中漂浮、脚滑或穿模等问题,教会AI模仿使用物理模拟器生成的运行模型,并在大规模人体运动数据集上达到了最先进的效果。
ChatBCG
ChatBCG 是由来自斯坦福大学的两名学生(Joseph Semrai与Silas Alberti)共同开发的一个用来生成 PPT 的模型。目前已在官网开放Demo和试用:https://www.chatbcg.com/。
ChatBCG 已经开放的功能,包括自动生成大纲、标题、要点、粗体关键字、图像和图形,还能够变换多种布局和主题。此外,完成的文件还支持以PPTX和PDF格式导出。
参考:
https://openai.com/blog/chatgpt/
https://roll.sohu.com/a/634763268_121207965
https://baijiahao.baidu.com/s?id=1742754879198749278&wfr=spider&for=pc
https://baijiahao.baidu.com/s?id=1742990592560504585&wfr=spider&for=pc
http://www.360doc.com/content/22/1025/09/76039144_1053186428.shtml
https://baijiahao.baidu.com/s?id=1751778973357411234&wfr=spider&for=pc
https://t.cj.sina.com.cn/articles/view/5901272611/15fbe4623019021f7l?finpagefr=p_104
https://minerva-demo.github.io/#category=Algebra&index=1
https://www.deepmind.com/blog/discovering-novel-algorithms-with-alphatensor
https://www.deepmind.com/publications/a-generalist-agent
https://baijiahao.baidu.com/s?id=1756520241186383004&wfr=spider&for=pc
https://www.producthunt.com/posts/chatbcg-generative-ai-for-slides
欢迎各位关注我的个人公众号:HsuDan,我将分享更多自己的学习心得、避坑总结、面试经验、AI最新技术资讯。
