基于语义的编译器测试
原文来自微信公众号:编程语言Lab- 基于语义的编译器测试
搜索关注编程语言Lab 公众号:HW-PLLab获取编程语言更多技术内容
如果读者想了解更多有关 类型系统相关的技术内容,欢迎加入 编程语言社区 SIG-程序分析。
加入方式:文末有小助手微信,添加并备注加入 SIG-程序分析。
视频回顾:
SIG-程序分析技术沙龙回顾|Semantic-based Compiler Testing https://www.bilibili.com/video/BV1zY411b7uG?
https://www.bilibili.com/video/BV1zY411b7uG?
# 研究背景及意义 #
今天的题目是编译器的测试,我先解释一下为什么这个题目本身有意义。
第一点,这个问题很重要。之前的讲座讲到了很多程序上面的漏洞,但这些只是单个程序的问题。如果编译器本身是有漏洞的话,那么理论上所有的程序都有可能有漏洞。因为所有的程序最终是在编译器上运行,如果编译器本身运行会出错,那么你没法保证这个程序的正确性。也就是说,所有程序正确性的分析是先基于这个编译器本身的正确性来做的。
第二点,现在很多新的语言层出不穷,比如智慧合约、Rust、Kotlin 等等。而且就算是传统的程序,比如像 C 或者 C++,一般认为 C 和 C++ 这种程序用了这么多年,几百万的程序员都写了各种各样的 C 程序,那么 GCC 或者 LLVM 这些编译器本身应该是比较正确了。但实际并不是,这几年大家发现这些编译器里面还是有存在很多漏洞。像刚才说的,这些漏洞理论上有可能会造成很大的麻烦。
最后一点,Tony Hoare,一个很知名的计算机科学家(大家学习过的 Quick Sort 就是他发明的),在 2003 年的时候给大家提了一系列的 Grand Challenges。他当时认为计算机科学,主要是指软件工程,形式化方法这些,缺少一些大的目标。就是说我们发了很多文章做了很多工具,但确实解决了很多很大的问题吗?好像并没有我们想象的那样。他就提了几个特别远大的目标,意思是说你们做计算机科学的最好像做物理的一样,如果有一些远大的目标,那么我们就可以保证这个领域不断的向前迈进。他其中提出的一个目标,就是我们要验证我们的编译器。如果我们连自己写的编译器,这是作为我们所有程序的基础,都做不到可以验证它的正确性,那么你要说我们可以验证别的大的系统的正确性,这个事情他觉得有可能需要打一个问号。
总的来说,我想说的是编译器的正确性这个问题本身很有意义。同时,为了解决这个问题,我们发展了一系列方法。这些方法本身也可能对解决别的问题有帮助。
# 问题定义 #
现在我们就来定义这个问题:一个编译器,你可以想象它就是一个函数,这个函数的输入就是你的源代码。比如说它可以是一个 Java 程序,或者你对智慧合约有些了解的话,它就可以是一个 Solidity 的程序。它的输出就是对应的机器码,对于 Java 来说是 JVM 上的 bytecode,对于 Solidity 来说,就是 EVM 上的 opcode。
那么我们的问题就是,给定任意一个程序,比如说 Java 程序,我们要保证原程序和通过编译器编译出来的程序,他们俩的行为是一致的。这个就是我们想要解决的问题。这个问题本身很难,因为给定一个语言以后,比如说 Java 或者 Solidity,你能写的程序有无穷多个,而我们要求任意一个程序进来,我们都能保证最后编译出来的程序是对的。
具体到怎么解决这个问题,我们需要解决三个比较小的问题。
-
我要怎么定义原程序的语义是什么?程序员用某一种语言来写某一个程序的时候,肯定是想达到某种目标的,肯定是基于对这个程序语言的某种理解来写的这个程序。这个理论上你可以理解为这就是我的这个程序想要的语义。
-
同时编译出来的那个程序,比如说 Java 的 bytecode、EVM 的 opcode,它本身也是有语义的,它的语义实际就代表了机器去执行这个东西,它应该执行出来什么效果。问题是我们要怎么定义这些编译完了的程序的语义?
-
如果我可以很好地定义原程序的语义和编译完的程序的语义。接下来问题就是我们要怎么证明给定任何一个程序,原程序的语义和对应的编译完的程序的语义是一样的?这里就要定义一个等价关系。这个等价关系要怎么定义,也是一个很大的问题。这个问题有很长很长的历史,很多人提出过很多不同的等价关系。
因为编译器是个很重要的东西。这么多年大家还是花了不少的精力想解决这个问题的。特别是 Tony Hoare 2003 年提出这个 Grand Challenge 以后的几年里,还是有不少的科学家做了很多尝试的。当然最后的效果不是特别好,过了几年以后大家慢慢就转战别的问题了。
# 编译器测试 #
# 方法
编译器的正确性的研究可以粗略的分成两类,形式化的证明,和测试。
## 形式化的方法
其中一个比较乌托邦的做法是,用一个很形式化的方法来很严谨的解决这个问题。比如说用形式化的方法来定义一个形式化的程序的语义,同时用一个同样的形式化的方法来定义对应的机器语言的语义,然后用一个理论证明的方法来证明这两个东西永远是一致的。当然这种做法代价很大。因为你需要:
第一步,把语言的语义完整地定义出来;
第二步,把机器语言的语义完整地定义出来;
第三步,通过人工的方法去证明对于任何程序,这俩都是等价的。
比较成功的一个例子是 CompCert verified compiler,它可以定义一个小小的 C 的子集叫 Clight。然后你给我任意一个 Clight 里面写的程序,或者说你只用某一部分 C 里面的语言特性的话,同时如果对应的出来的机器码是运行在 PowerPC assembly code 上面的,那么我可以保证这个结果是对的。
这已经是做的最好的一个结果了。比较苛刻一点地说,这个东西实际上很难有用。因为就算你可以做到这种程度,但程序语言是一个不断发展的东西。比如说 Java,这几年它发展很快,各种新的版本层出不穷。如果你通过这种方法来证明 JVM 的正确性的话,那么基本没法做。因为每次 Java 语言有些改动,你都要把这个东西重新做一遍。这是基本没法做到的。
## 测试
另一种做法是放弃这个理想,转而用一些简单的方法来找一些编译器里面的漏洞。最简单的做法就是手动测试。像 C 语言的编译器就有很多手写的测试用例,比如 SuperTest,包含了好几万个测试用例。如果你要用 GCC 或者 LLVM,或者写了一个新的 C 的编译器,你就应该跑一遍所有的这些测试用例。当然这些测试集不是免费的。这种做法的缺点在于维护这个测试集本身很难,同时很难说这个测试集本身有多全。
还有一种做法是自动生成测试用例。当然因为我们是在测试一个编译器,一个测试用例本身就是一个程序。比如说 C 的程序、Java 的程序,然后把这些程序扔到 GCC、JVM 里面跑,看它的结果对不对。这个也有 CSmith、EMI 等等一系列的工作。
# 如何自动测试
我们主要关注的是在自动测试,因为手动测试本身可做的不多,完全是一个人力的问题。具体到怎么做自动测试编译器,和自动测试任何系统一样,主要有 4 个问题我们要解决。
-
怎么运行这个测试用例?这个一般比较容易理解,比如说你要测试 Java
程序,那么 jUnit 就是帮你解决这个问题的。具体到测试编译器,就是说我们要怎么去运行一个测试用例。比如说测试 C 的话,就用 GCC、LLVM 去编译这个程序,让它跑一下看结果对不对就完了。 -
要怎么生成这些测试用例?理论上可以有无穷多个不同的程序,那么我们根据什么标准挑选我们认为更有意义的测试用例。
-
给定任意一个,比如说 C 的程序或者 Java 的程序,扔给 GCC 或者 JVM 去跑,我们怎么知道它出来的结果是对还是不对?这个叫 oracle 的问题。
-
test adequacy 问题。就是说怎么知道测试够了,比如我们现在要写一个新的编译器,我们怎么确定我们测试的够了,意思是我们能不能有办法说测试到这个程度这个编译器就不会有太大问题了。这个问题很难。
这些问题在现有的工作里是怎么解决的,我给大家举一个例子 EMI (Compiler Validation via Equivalence Modulo Inputs) [1]。他们做法是这样的,比如他们测试的是 GCC。
-
要怎么跑这些测试用例?很简单,就是用 GCC 来编译这个 C 程序,然后让它去跑。
-
怎么生成测试用例?他们做法也比较简单,就是假设已经存在一系列的现有的 C 程序。把这些现有的 C 程序拿过来,在里面随机地加一些死代码。死代码,简单来说就是不会运行到的代码,比如说原程序里有一个
if-then-else语句, 这时候我们加个else if(false) { …}。这部分新的代码肯定是不会被执行的,那么就是说加了这段代码以后,这个代码还是等价的。 -
怎么知道跑完以后,它的结果对不对?这很好理解,因为我们加的这个代码本身就是不会去影响原来的程序的运行的。那么我知道原来程序运行什么结果,现在这个程序运行还应该是什么结果。如果它的结果忽然变了,那么肯定就是编译器有问题。比如说一个可能的原因就是编译器做了一堆乱七八糟的优化,可能某个优化实现的地方是有问题的。加了这个代码以后,实际它不应该改变,结果它改变了,那么就是有问题。
-
怎么知道测试够了?这个问题他们是没有答案的。就我看到的所有文章来说,都没有提供一个答案。
这个 EMI 的工作本身做的还是很好的,也发现了很多 GCC 和 LLVM 里面的 bug。但我想说的是这个东西虽然很有用,但离我们想要的测试编译器正确性这个目标还是差的比较远。为什么这么说呢?我举个简单的例子,就 EMI 的例子来说,如果它做的只是加死代码然后看结果有没有变的话,那么就算那个程序算出 3+4=8,这个编译器的错你也是找不到的。它只能测试加了死代码不会影响你的结果,只是这样一个属性而已。
我们这边的想法是,如果你想要去测试编译器的正确性的话,那么理论上你一定要基于正确性来做。那么正确性是什么?编译器的正确性应该是它正确地实现了这个语言的语义。如果我们做编译器的测试的时候根本就没有用到这个语言的语义,那么这件事情我感觉肯定是没法做到很好的。这就是为什么我们提出了基于语义的编译器测试。
# 基于语义的编译器测试 #
#测试方法
我们这边提出的基于语义的编译器测试,具体怎么做呢?
第一步,我们要回答怎么运行测试用例?这个和原来的稍微有点区别。我们除了要用编译器编译运行一个测试程序,我们还要有一个办法来执行我们的语言的语义(这样我们才知道编译运行的结果对不对)。你可以想象我如果是一个很好的程序员的话,我对这个语言理解很透彻,那么给我一个简单的程序,我可以在我的脑子里根据它的语义运行一遍,预测它的结果是什么样。那么我就可以判断编译运行的结果对不对了。
第二步,生成哪些程序作为测试用例?虽然这个理论上有更好的办法,现在我们做到的程度还是基于变异。给我一堆现有的 C 程序也好、Java 程序也好、Solidity 程序也好,我们在上面定义了很多种不同的变异。比如说变异可以是我在这边加一个 if-then-else,或者在那边加一个函数调用等等。当然我们变异的时候要保证这个变异的结果还是一个合法的程序。
第三步,我要怎么知道最后执行的结果是对还是错?这个在有语义的情况下就比较容易了。就是说,我已经知道这个语言的语义了,那么根据这个语义我是确切的知道它应该的结果是什么。具体来说,我用一个可以执行的语义出来的结果去比对通过编译器编译完了运行出来的结果。如果两个结果是一样的话,那么说明这个编译器经过编译以后出来的程序,至少在这个程序的情况下是正确的执行了我要的语义的。
最后一个问题我们也有很好的答案。最后一个问题是说我怎么知道我测试够了?这个很容易理解,如果我已经把所有语言的语义给写出来了,既然一个编译器最终的目标是把该语言的所有语义正确的实现出来,那么只要做到每一条语义都正确的测试过了,至少我们可以有某种程度的保证说这个编译器是正确的。
# 具体的难点
第一个难点,也是这一系列工作最难的部分是怎么定义一个程序语言的语义?如果你问我的话,理论上作为一个计算机科学家,我认为如果你要定义一个新的语言,那么你一定要考虑它的语义是什么。最好就是你应该有一个办法可以用形式化的方法,把这个语言的语义到底是什么写出来。如果你写不出来,你当然也可以通过,比如说一些例子、一些文档来说明这个语义,但更好的还是把语义很明确的写出来。具体到怎么写,里面有很多的细节。比如说有各种各样的定义语义方法,最常见的是叫 operational semantics。就是大家学语言的时候最常用的一种语义。比如说你是怎么学 if-then-else 的,老师告诉你如果这个条件成立,执行这个 then branch;如果这个条件不成立,就执行 else。这就是 operational semantics。当然这不是唯一的定义语言语义的方法,还有一些另外的定义方法,比如说 axiomatic semantics。什么是 axiomatic semantics,举个例子。我们怎么定义自然数?我们可以用两个 axiom 来定义。第一条,1 是个自然数。第二条,任何一个自然数加 1 它还是个自然数。这样你就定义了所有的自然数。具体到程序语义,你也可以用这种 axiomatic semantics 来定义它的语义。还有一种是 denotational semantics,同样可以用来定义程序语言的语义。这边我就不展开讲了。这里有个问题是,如果我们的目标是想要测试编译器,那么用哪一种语义比较好?
其次,我怎么把这个语义变得可执行?这个本身也很难。如果你了解 C 语言的话,历史上有很多次尝试去定义它的语义。因为 C 刚开始没有一个很好的语义,有很多 C 程序的行为是未定义的,就是说它的语义没有定义好。虽然历史上尝试了好几次去定义 C 的语义,但是很多次定义出来的都不是一个可执行的语义。如果这个语义不可执行,实际上这个语义就很难用。因为它只是一些规则,人要去理解这个东西本身就很难。一个可执行的语义对于做程序的测试也好验证也好是很有意义的。
当然还有一个很实际的问题是说,定义一个语言的语义大概要花多少的功夫?大家一般都认为定义语义很难,因为一个复杂的语言像 Java,你要整个定义它的语义本身是很困难。比如说 C,大家花了几十年才慢慢把它的语义给总结出来。而最后就算你定义了这个语义,如果这个语言本身一直是在改进的(比如加了一个新的语言特性),那么我要去改这个语义多难。如果太难的话,那么你这个语义就算写出来也没用,因为很可能过了几天就没有用。
第二个难点,我们要做测试生成的时候,怎么去变异这个程序?就像我刚才说的,变异的时候,我们可以随机的加 if-then-else,或者随机的加个函数调用。但我们怎么保证这样得来的程序是有意义的。比如说加 if-then-else,那么里面你要填什么布尔表达式?同时你要保证这个表达式里面所有的变量都预先被声明并且可见。保证这些不容易。理论上这部分信息在编译器里面都是有的。就是说编译器里面肯定是做了各种各样的检查的,告诉你哪些是合法的程序,哪些是不合法的,但是要怎么系统的知道并利用这些信息是个难点。
第三个难点,我怎么知道我运行的这个程序和它的语义是相符的?假设我们的语义是可执行的,那么理论上我是知道它的结果的,然后我去比对 GCC 编译运行出来的结果是不是一样的。这个理论很简单,但实际操作的时候也会有一定的难点。比如说这个程序里面本身可能有一些不确定性。举个简单的例子,TensorFlow 里面有个函数 dropout。dropout 这个东西它本身是一个概率的行为,就是说它会随机的去掉 10% 的神经元,那么理论上就是说每次运行你有可能出来结果都会不一样。也就是说,只要它确实是去掉了 10% 的神经元,不同的结果都是正确的。那么问题就是,在有这些不确定性的情况下,我要怎么比对这个结果?还有更简单的例子,浮点数运算经常会有精度损失,那么很可能有时候结果稍微不一样,在这种情况下你要去决策,这个结果是对还是不对?
# 三个实验
## 实验 1: 测试 JVM
上面都是一些比较高层的讨论,具体到怎么做,我下面给大家讲三个例子。第一个是测试的 Java 的 JVM。第二个是测试 Solidity 的 EVM。如果大家知道智慧合约,就会知道 EVM 是现在很流行的一个编译器。第三个是测试 TensorFlow。对神经网络来说,我们认为 TensorFlow 相当于是一个编译器的角色。
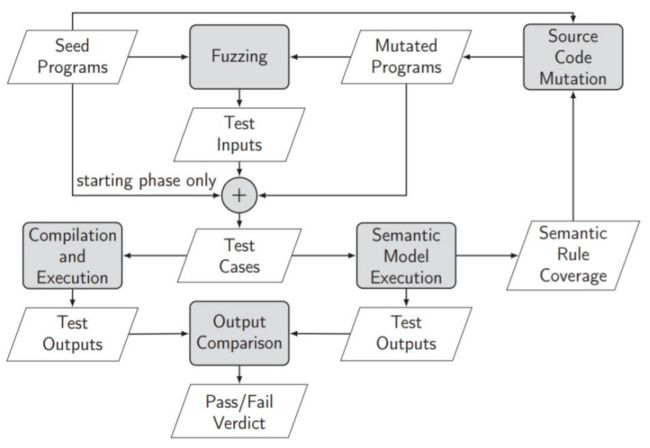
我们先来讨论怎么测试 JVM,具体的流程如图所示。
第一步,我们先收集一堆 Java 程序,这个在 OpenJDK 或者 GitHub 上面很容易就找到了。同时我们会去做一些程序变异,生成一些新的程序。
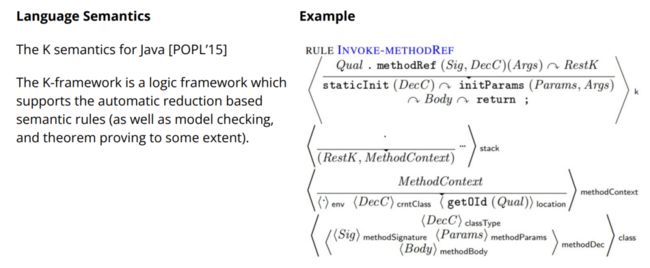
第二步,我们利用现有的 Java 的测试工具,就可以对这些 Java 程序生成一堆的测试用例。然后我们同时跑 JVM 和 Java 的一个现有的可执行语义。之后去比对结果,如果结果是一样的,那么我们认为测试通过,如果结果不一样,我们认为测试不通过。同时,因为这个现有的 Java 的语义是由一堆规则来定义的,我们监测哪些规则被覆盖了,哪些规则没有被覆盖。如果一条规则没有被覆盖,那么我们试图通过变异生成一些新的程序来增加覆盖这些规则的几率。比如说我们发现很多特殊的赋值语句,比如说 *=、/= 这些,测试的不太够,我们做的就是去变异我们的测试程序,加了很多 *=、/= 语句。这个工作相对比较容易是因为 Java 语言的可执行语义已经有人写过了。15 年 POPL 上有一篇文章,UIUC 有个组花了很大力气写了一个基于 K 逻辑的 Java 语义 [7]。K 逻辑的好处在于,在 K 逻辑里面写了以后,你是可以执行的。可以理解为,在 K 逻辑里写完一个语言的语义以后,K 提供了一个解释器。就是说,K 可以一步步根据写的规则往下跑,那么就相当于去执行你这个语言的语义。具体到在 K logic 里面程序语义是怎么定义的,大家可以看下面这个例子。这个有点复杂,我就不具体讲了。定义这个东西本身还是不容易的。这也很好理解,因为 Java 这种比较复杂的语言,它本身语义已经很复杂了。我要确切的知道一个 Java 程序怎么运行,我要考虑很多很多的东西,比如说各种各样的环境变量、各种各样的包结构等等。
然后具体到做程序变异怎么做?这个就是我刚才说到的,比如说加一些新的语句,或者是说挑一个程序里原有的表达式,可以通过一定的变异的方法去把它改成一个新的表达式。只要保证这个新的表达式的类型是对的,基本上就没有问题。
举个简单的例子,假设我们发现 ++ 这个操作,在原来的 openjdk 里面的测试用例里测试的不够多。再假设原来的程序是 int a=2; a*=1。那么我们把右边的 1 做个简单的变异。比如把 1 变成 1+a++。因为变异完了以后这个表达式的类型是一样的,那么这还是个合法的程序。然后我们就可以通过比对这个程序在语义上执行的结果和在通过编译器执行的结果来测试编译器是不是有问题。
最后我们怎么确定我们的测试是不是足够了?就像我刚才说的,我们就是简单地去看是不是每条 K 逻辑里面的规则都被覆盖到了。也包括覆盖到了多少次,然后我们用这个次数来排序,那些最多被覆盖到的规则,我们认为最有可能是最正确的。这个也很好理解,如果大家经常用这种程序,那么一般来说不会有问题的。如果有问题的话早就被人修复了。如果有些规则没有被很好的测试到,那么我们根据这个规则看它描述的是什么语句相关的语义,再想办法把这个语句再加到我们要测试的那些程序里面。比如说我们发现 *= 在原来的 openjdk 的测试集里面就测试的很少,那我们就加了一堆 *= 在原来的这些程序里面。
## 实验 2: 测试 EVM
第二个实验我们测试的是 Solidity 的编译器 EVM。如果大家对智慧合约有一定了解的话,就知道智慧合约的正确性本身很重要。因为智慧合约里面都是钱,如果一个智慧合约里面出现一个错误的话,那么很可能造成很大的经济损失。

这边有个简单的 Solidity 程序的例子,这里面有个很小的溢出的错误。这个小错误让发这个币的人大概损失了 20 亿美元。但这只是这个智慧合约本身的一个错误。如果 Solidity 的编译器 EVM 有问题的话,那可能就不是一个两个合约有问题了。实际情况是,EVM 里面是有很多错误的。比如说我们组就发现了一些 bug。这也很好理解,相对于 C 和 Java 来说,Solidity 是一个很新的语言,它一共就没几年,大家也一直在更新,里面有 bug 那是很好理解了。
我们测试 EVM 的实验和测试 JVM 的方法基本是一样的。
第一步我们要有一个可执行的语义。Solidity 是一个相对比 Java 简单的多的语言。那么理论上定义它的语义比较容易。基于我们之前的经验,我们天真的认为用 K 逻辑来定义 Solidity 语义应该不难。具体就是照着 K 逻辑里的 Java 的语义写一堆类似的规则。这里面的细节我就不展开了。如果你确实感兴趣,欢迎联系我。我们刚开始很乐观地估计,大概三个月,两个博士生应该可以把这个事情搞定。我们这么有信心是因为 Solidity 确实不是一个很复杂的语言,同时我们和 UIUC 搞 K 逻辑那个组有合作。我们认为他们有经验,我们有时间,有基础,三个月应该够了。实际最后花了大概一年,中间有一度甚至觉得有点做不下去。同时我们发现定义出来的语言语义也会有问题。这个也很好理解,就是说所有的东西到最后都是人写的,人写的肯定是会有问题的。扯远一句的话,正确性这个东西本身是一个虚的概念,实际只存在一致性,不存在正确性。回到定义 Solidity 语义这部分,我们花了一年,把这个语义大概写完了(Solidity 里面主要的那些语言的 feature 我们都支持的)。因为这个工作量比较大,我们中途决定写几篇文章发表,结果还是不错的(见 [2]、[3])。
这部分语义做完以后,接下来这几步都和 Java 那边差不多。比如说程序变异,和 Java 那边就完全一样。那我们怎么去看结果对不对?这个和实验 1 那边也基本是一样。唯一的区别在于 Solidity 里面用一堆很大的 Hashmap,它所有的变量实际都是存在一个巨大的 Hashmap 上。那么问题就是要怎么比对两个 Hashmap,这个稍微麻烦一点。最后怎么知道我们测试完全够了?这个和之前也是一样的,我们就是去看是不是所有的定义的 K 的那些规则都被覆盖到了。
具体这两个实验的结果是这样的。实验 1 我们测试的是 openjdk 13 的 JVM。我们大概有 700 多个种子测试程序。这些是 openjdk 里面自带的一些测试用例。我们写的用来变异 Java 程序的工具大概有 6000 多行。Java 的语义一共有 1385 条规则。Java 的语义还是比较复杂的。然后我们跑了 3 万多个测试用例,大概跑了一个星期。实验 2 我们测试的是 Solidity version 0.5.13。一共就 37 个种子测试程序。种子少的原因在于我们虽然花了很多精力去写它的语义,还是有不少 Solidity 的语言特征很难支持。我们写的 Solidity 的变异器有 5300 行。Solidity 的语义比较简单,一共有 304 条规则。我们跑了 5 万多个测试用例,大概跑了两个星期。
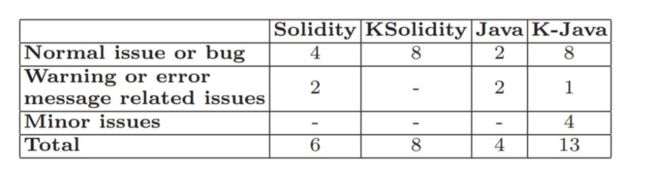
如上表所示,我们还是找到了一些问题的。比如说,我们找到了 4 个 Solidity 编译器里的 bug,和两个 JVM 的 bug。Java 本身测试的比较完备,然后就跑了一星期,找到 2 个 bug,我们还是相对比较开心的。有意思的是我们发现语义本身很容易出错,比如 K Java(Java 在 K 逻辑里的语义)是在 15 年的 POPL 上发表的,中间也经过了很多迭代,但我们发现在里面还是有很多的 bug。也就是说,定义语义本身也是个很难的问题。
至于我们找到的 bug 是什么样的,我给大家举几个例子。下面是一个 Java 的程序。
long a = 1L+0.1*3L //error: incompatible type
long b = 1L; b += 0.1*3L; //no error这两行代码,理论上它们的效果应该是完全一样的。但实际上你用 JDK 来跑的话,你会发现第一行它是会报错的(incompatible type)。因为 0.1*3L 的类型是 float,这个和 1L 的类型(long)是不兼容的。但是如果你把它拆成两句,就没有出错了。这肯定是不合理的。
int a =2; a *= 1+a++; //the result is 9 but should be 6上面的一个我们发现的 Solidity 里面的 bug。这个结果应该是 6,但是 Solidity 当时的版本运行出来的结果是 9。有鉴于 Solidity 里的算术大多是跟钱相关的,这种错误还是让人有点担心的。当然这些 bug 我们都报上去了。新的版本里面应该都已经被改过来了。具体的实验细节大家可以在 [5] 里找到。
通过这两个实验,我们得到结论是。第一,你要完整地写出一个可执行的程序语义还是挺困难的。第二,我们这两个工作都是基于 K 框架来做。首先 K 框架本身能支持多大的程序是个问题,因为 K 的运行速度比较慢。其次还有一个问题是,我们在 K 里面定义 Solidity 的语义的时候就发现,感觉我们又把 Solidity 的编译器又实现了一遍。因为我们实现的 Solidity 的语义是 operational。这个不是太好。因为编译器实现的也是 operational semantics。如果实现原来编译器的那个人对这个语言的语义这部分理解有误差的话,而我们这边又有相同的误差,那么很可能我们在实现这个语义的时候,也会有同样的 bug。结果就是这个 bug 不会被发现。最后一个结论就是变异程序本身很难。变异程序需要考虑各种各样的东西,比如这个程序变异完了以后是不是有合法,是不是意义等等。
## 实验 3:测试 AI 框架
最后一个实验是这样的,AI 特别是神经网络现在比较火。我们认为神经网络相当于是一种新的形式的程序。然后神经网络都是在比如说 TensorFlow、PyTorch 之类的框架上运行的。那么 TensorFlow、PyTorch 这些就相当于扮演了原来的传统程序的编译器的角色。那么上面提到的关于传统编译器的观点对这些 AI 框架也适用,就是说如果 TensorFlow 或者 PyTorch 这些框架里面是有 bug 的话,那么所有在上面跑的那些神经网络很可能都有问题。而且神经网络相对于传统的程序来说,就算里面有问题你都不容易发现,因为里面就是训练出来的一堆数字。
我们想要做最后这个实验,还有一个原因是这个做起来比较容易。相对于传统的程序,神经网络的语义相对来说很简单。不管是什么样的神经网络,CNN 也好、RNN 也好、CapsNet 也好,神经网络里面用到的数学函数实际就那么几种。那么理论上我把这些数学函数应该达到什么效果写出来是很容易的,也就是说神经网络本身的语义是很容易的。同时,如果我们可以把它的语义准确的描述出来,那么我们不只是可以做测试,还可以做另外的东西,比如说去做一些神经网络的自动修复(见 [4]),如果大家感兴趣后续也可以给大家讲。
我们具体怎么做的?第一步还是一样,我们需要写神经网络的语义。这次我们没有用 K 逻辑,而是用了 Prolog。大家如果没有学过 Prolog 的话,它是一种传统的 logic programming 的语言。Logic programming 和主流的 Java,C# 这些不太一样。比如要把一个 list 加和的话,那么在 Prolog 里就写两条规则就够了。
sumlist([], 0).
sumlist([H|T], N) :- sumlist(T, N1), N is N1+H
第一条,如果这个 list 是空,那就返回 0。第二条,如果是非空的话,那把第一个数字拿出来,和后面剩下的那些 list 里面的和加起来就是它的结果。大家可以看到这个程序和 Java,C# 之类的程序不太一样。换句话说,用这种程序来描述的语义更接近于我刚才说的 axiomatic semantics,就是通过一些规则来描述语义。
我们系统的在 Prolog 里定义了所有的神经网络里面经常用到的那些函数的语义到底是什么。比如说 dense layer 的语义,大概就是一些加权操作。用 Prolog 来写这个语义,我们发现很容易。比如我们刚才提到了程序里会有不确定性的问题,用传统的 operational semantics 是很难解决这个问题的,但在 Prolog 里就很容易,因为它是 axiomatic 的。我给大家举个简单的例子。比如说 dropout,它是一个概率的行为,就是说它只要随机的,比如说丢掉 10% 的神经元就可以了,到底丢掉哪些实际不重要。那么在这种情况下,我用 Prolog 来写也就很容易,我只要去数一下它到底丢掉了多少,然后算一下它的比例看是不是 10% 就好了,不需要去真正的说它到底丢掉哪一个。
总的来说,写 TensorFlow 的语义很容易。TensorFlow 里面一共就只有 79 个不同的 layer,其中 72 个我们都很快写出来了。大概也就花了一两个月时间。剩下的 7 个都有些特殊的地方,相对麻烦一点,当然现在也基本支持了。麻烦主要是因为它有很多跟 TensorFlow 框架本身相关的一些东西。
我们也发现绝大多数的 layer 还是比较容易写的。比如说下面这个表展示的是我们需要多少行 Prolog 语句来描述一个 layer 的语义,你可以看到绝大多数在 40 行以内,只有很少数需要 40 行以上来描述它的语义。这个说明它的语义还是比较简单的。然后我们同时发现 TensorFlow 虽然很多人用,实际它的语义还是有很多地方是没有明确的。我们在这个过程中发现了不少问题,也反馈了,他们也确实改了一些东西。

刚才是说怎么写语义,下面来说说怎么去变异神经网络。变异神经网络就很容易了,因为在神经网络里面,实际你可以做的就是加减各种各样的 layer,或者改 layer 间的互相关系,这个还是很容易的。举个比较有意思的例子,比如说我们随机生成了下面这个神经网络,里面用到了 cropping。Cropping 简单来说就是说把某一些维度给去掉。

我们发现了一个很有意思的问题。我们在 cropping 的时候,因为我们已经有语义了,我们知道 cropping 里的这几个系数需要满足什么样的条件。比如说第二个系数和第三个系数是互相有关系的,这个关系是不能违反的,不然就会有问题。比如在这个例子里,第二个和第三个系数是一样的,它实际把所有的维度都 crop 掉了。结果就变成了空的。我们发现 TensorFlow 在这种情况下它不会报错,而根据我们的语义,我们就发现这是有问题的。
具体来说,我们测试 TensorFlow 的流程大概是这样的。首先就是我们自动生成了一些神经网络,也在网上收集了一些神经网络。然后开始变异,就是在这边加一个 layer,在那边加一个 layer。再去跑我们的语言的语义,然后去跑 TensorFlow,最后看出来结果是不是符合语义的预期。因为我们有语义,我们确定的知道,比如说神经网络里面这些系数它应该满足什么样的条件,根据这些条件我们就很容易生成合法的神经网络。我们大概算了一下,我们生成的 99% 的神经网络都是合法的。比较而言,当时最好的做法实际也就大概只有 25%。最后我们是怎么确定我们生成的测试用例够了呢?我们用 Prolog 自带的工具统计每条规则的覆盖度。刚才提到的用 K 来运行这些语义速度比较慢。我们换成 Prolog 以后,我们做的第一件事情就是去试验一下 Prolog 是不是更快。我们发现确实是这样的,Prolog 作为一个程序语言,它的效率还是相对比较好的。比如我们跑了一个有 50 个 layer 的神经网络(已经不算太小了),也就是几秒钟到分钟就可以跑完。当然网络越复杂的,每一层 layer 越多,花的时间也越久。
这个实验的结果大概是这样的。我们发现了 TensorFlow 里面三个比较严重的问题。其中两个已经被修复,还有一个正在被审查。同时我们发现了 TensorFlow 里面的出错信息不是很好。有时候明明是同样的原因,在不同的情况下,它的出错信息不一致。我们就又额外的生成了很多有错的神经网络,去看 TensorFlow 输出的信息到底有多少情况下是有意义的。是否有意义还是根据我们的语义来判断的,因为根据语义我们是确定的知道为什么这个东西是有问题的。我们发现 TensorFlow 的出错信息经常性的和它的真正原因关系不是特别大。具体的实验细节大家可以在 [6] 里找到。
# 总结 #
我这边通过这三个实验,主要想说明的这个问题是:如果我们想很好的去解决一个问题,那么我们一定要把这个问题定义的很清楚。比如很多工作都在讨论程序正确性的问题,那么我们认为一定要先说明什么是程序正确性,那么很多程序分析的工作才是有意义的。回到编译器的正确性问题,语言的语义正好定义了编译器的正确性。如果缺少这个正确性的标准,那么我感觉这个问题你再怎么试图去解决,离真正的目标都会差的比较远。
如果我们要做一个新的语言,做一个新的编译器,那么手动测试是一定会做的,但很可能就是远远不够的。就按 GCC、LLVM 最近的测试结果来看,GCC、LLVM 那么多人用了那么几十年,还是可以被找到很多 bug。很大程度上就说明这些编译器里面实现的这个语义本身还有很多的问题,那么结论就是我们一定要用一个系统的方法来检查,是不是语言的语义都被完整的正确的实现了。
参考
[1] Compiler Validation via Equivalence Modulo Inputs https://www.vuminhle.com/pdf/pldi14-emi.pdf
[2] Jiao Jiao, Shuanglong Kan, Shangwei Lin, David Sanan, Yang Liu and Jun Sun: “Semantic Understanding of Smart Contracts: Executable Operational Semantics of Solidity”, S&P 2020.
[3] Jiao Jiao, Shang-Wei Lin, and Jun Sun: “A General Formal Semantic Framework for Smart Contracts”. FASE 2020.
[4] Bing Sun, Jun Sun, Pham Hong Long and Jie Shi: “Causality-based Neural Network Repair”, ICSE 2022.
[5] Richard Schumi and Jun Sun: “SpecTest: Specification-Based Compiler Testing”, FASE 2021. EASST “Best Paper at ETAPS 2021”.
[6] Richard Schumi, and Jun Sun: “ExAIs: Executable AI Semantics”, ICSE 2022.
[7] Denis Bogdanas, Grigore Rosu: K-Java: A Complete Semantics of Java. POPL 2015.