嵌入式arm(二)涉及的汇编指令及相关知识
arm开发中需要掌握一些汇编语言的知识,如:指令的格式,作用和用法;但不是要求用汇编去编程,而是通过学习汇编来掌握:机器指令的格式,指令在内存中是如何存储的,指令的执行过程,寄存器的变化。
文章目录
-
- 一 汇编语言是什么
- 二 汇编语言的基本语法
-
- 1 汇编语言的注释
- 2 立即数
- 3 先了解程序状态寄存器
-
- 3.1 条件码标志位
- 3.2 控制位
- 4 基本指令
-
- 4.1 指令基本格式
- 4.1.1 汇编指令格式
- 4.1.2 条件码
- 4.1.3 mov指令的机器指令格式:
- 4.2 数据传输指令mov
-
- 4.2.2 怎么解决mov中立即数的范围问题;
- 4.2.3 mov的扩展用法
- 4.3 算术指令
- 4.4 逻辑指令
- 4.5 比较指令
- 4.6 跳转指令
-
- 4.6.1 什么是语句标号
- 4.6.2 b与bl
- 4.7 内存操作指令
-
- 4.7.1 单个内存空间ldr与str
- 4.7.2 连续内存空间
- 4.7.3 堆栈操作
-
- 4.7.3.1 万恶的《堆栈》
- 4.7.3.2 堆栈相关的概念
- 4.7.3.3 堆栈操作程序请看第五章第3节
- 4.8 软中断指令
-
- 4.8.1 swi指令
- 4.8.2 中断是随机产生的,如何找到中断处理程序?
- 4.8.3 mrs指令和msr指令
- 4.8.4 当中断产生时,处理器会做哪些事情?我们需要做哪些事情?
- 4.8.5 当中断处理程序执行完之后,我们需要做哪些事情?
- 5 常用伪操作
-
- 5.1 符号定义伪操作
- 5.2 数据定义伪操作
- 5.3 控制伪操作
- 5.4 ARM汇编器支持的伪指令
- 6 汇编中的寻址方式
- 三 编程示例
-
- 1 ldrb和strb指令程序实例
-
- 1.1 ldrb+单个内存空间
- 1.2 ldrb+连续内存空间
- 2 ldm和stm指令示例
- 3 swi指令示例
-
- 3.1 基本示例
- 3.2 swi 参数用法完整示例程序
- 四 与C语言混用的内联汇编和内嵌汇编
- 五 过程调用标准AAPCS/ATPCS
-
- 1 子函数的参数
- 2 局部变量
- 3 堆栈相关
一 汇编语言是什么
汇编语言由汇编指令组成,汇编指令是机器指令的便于记忆的文本书写格式,即机器指令的助记符,由编译器把汇编指令翻译为机器指令,由于不同架构的机器指令集并不相同,对应的汇编语言也各有区别,因此汇编语言可移植性差,只有相同架构的机器之间才能做汇编代码的移植;
一般提到指令集就是在说汇编指令集,由于不同CPU架构的指令集不同,所用到的编译器也不一样,为了能够在一个架构的系统上编译出不同架构的可执行文件,需要用特殊的编译器:交叉编译工具链;
二 汇编语言的基本语法
首先,我们不看啥啥啥寻址方式,放到最后再来看,正经人谁一上来就扯半天云里雾里的概念啊。
1 汇编语言的注释
用@注释符;
2 立即数
类似于C语言中的常量;在数字前加上#号,如#0x01,#88;
3 先了解程序状态寄存器
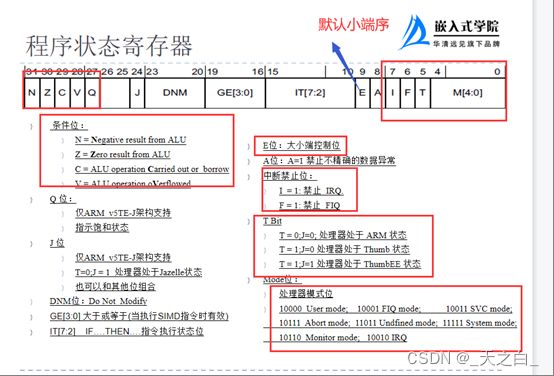
如图,在程序状态寄存器中,高5位为条件码标志,低8位为控制位;4-27位为保留位,程序不应该访问到保留位;
见名知意,在程序运行时,CPSR寄存器即随着变化。
3.1 条件码标志位
3.1.1 N位
当两个补码表示的带符号数进行运算,结果是负数则N=1;否则N=0;
3.1.2 Z位
当运算结果为0,Z=1;否则Z=0;
3.1.3 C位
加法运算(包括比较指令 CNM):C=1:运算结果产生了进位时(无符号数溢出)。C=0:运算结果没有进位
减法运算(包括比较指令 CMP):C=0:运算时产生了借位(无符号数溢出)。C=1:没有借位
对于包含移位操作的非加 / 减法运算指令,C 为移出值的最后一位
对于其他的非加 / 减法 运算指令,C 的值通常不变
3.1.4 V位
对于加 / 减法运算指令,当操作数和运算结果为二进制的补码表示的有符号数时,V=1 表示符号位溢出
对于其他的非加 / 减法 运算指令,V 的值通常不改变
3.1.5 Q位
在 ARM v5 及以上版本的 E 系列处理器中,用 Q 标志位指示增强的 DSP 运算指令是否发生了溢出。在其它版本的处理器中,Q 标志位无定义
3.2 控制位
低8位是控制位,当发生异常时,这些位将被改变,只有特权模式下程序可以修改这些位;
3.2.1 中断禁止位I、F
置1时,分别禁止IRQ中断和FIQ中断;
置0时,使能中断;
3.2.2 T标志位
反映处理器的运行状态;
T=1时,程序运行于THUMB状态;
T=0时,运行于ARM状态。
3.2.3 运行模式位M[4:0]:
这几位是模式位,这些位决定了处理器的运行模式。具体含义请查图片;
4 基本指令
4.1 指令基本格式
下图是keil4汇编代码调试的截图,汇编指令在汇编阶段翻译成机器指令,根据这条机器指令的内存地址能判断出其在内存的哪个段哪个位置;
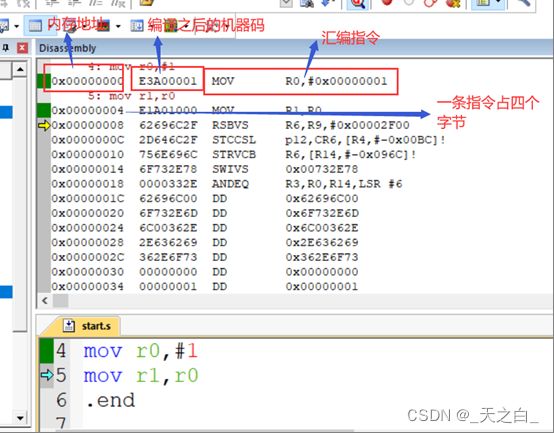
4.1.1 汇编指令格式
放一条基本指令:mov r0,#1
再放一条:moveq r0,#1
再放一条:moveqS r0,#1
指令的格式为:
< opcode > {< cond >} {s} < rd >, {rn}, {< operand2 >} 其中:<>是必须要有的;{}可选的,
(1) Opcode:汇编指令,比如:mov
(2) Cond:条件码 ,如:moveq,详见4.1.2节;
(3) S:是否影响cpsr寄存器的nzcv位,如果写出S则影响,不写不影响;指令中使用"S"后缀时,指令执行后程序状态寄存器的条件标志位将被刷新;不使用"S"后缀时,指令执行后程序状态寄存器的条件标志将不会发生变化,指3.1中的条件标志位;
(4) Rd:目标寄存器
(5) Rn:第一操作数寄存器 mov没有
(6) Operand2:第二操作数,可以是寄存器,也可以是立即数
在有些连续地址访问的指令中,还有!后缀:
如果指令地址表达式中不含"!“后缀,则基址寄存器的地址值不会发生变化。指令中的地址表达式中含有”!"后缀时,指令执行后,基址寄存器中的地址值将发生变化,变化的结果如下:基址寄存器中的值(指令执行后) = 指令执行前的值 + 地址偏移量;更多请看4.7.2节。
4.1.2 条件码
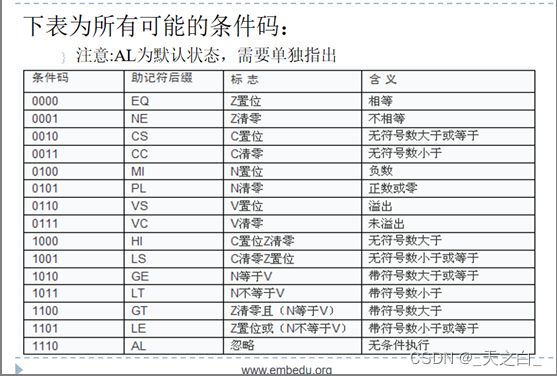
还有1111,助记符后缀为NV,标志是任何,含义是不执行;
4.1.3 mov指令的机器指令格式:
汇编指令只是助记符,文本书写格式的机器指令,一句汇编指令最终还是会翻译为一条机器指令,机器指令可以简单理解为就是一个32位的数据;每个指令都有自己的指令格式,我们以mov指令为例来了解一下:
Mov指令的机器指令格式:
31-28 27 26 25 24-21 20 19-16 15-12 11-0
31-28:条件码
27、26:预留的为00
25:I 表示第二操作数是寄存器还是立即数 1 立即数 0 寄存器
24-21:具体的指令 mov 1101
20:1 影响cpsr的nzcv位 0不影响cpsr的nzcv位
19-16:第一操作数寄存器的编号
15-12:目标寄存器的编号
11-0:如果第二操作数是寄存器,0-3就是第二操作数寄存器的编号;
关键是0-11位
如果第二操作数是立即数,则:用0-7位的低字节表示一个32位数的低8位,用8-11位来表示位移量的一半,最后表示的数是将 低8位生成的的32位的数 循环右移 8-11位的数的两倍 的数量,右移后的数即是mov操作的立即数;
于是:
位移数只能是偶数,且最大为30;
基本数是0-255(但是生成32位的);
这11位能表示的最大数是0xff000000;
循环右移:就是按位右移,最右边移出的位往最左边补入;
可知,用mov指令最大能传输的立即数是0xff000000;超出这个范围则报错;而且,在这个范围内,如果不能通过0-255的值循环右移偶数位得到,也报错,怎么解决?请看4.2.2节;
4.2 数据传输指令mov
mov r0,#1 @r0=1,把立即数1放入寄存器r0中;
mov r0,r1 @r0=r1,把寄存器r1上的数据拿出来放到r0中;
mov r0,r0 @相当于空指令;
4.2.2 怎么解决mov中立即数的范围问题;
用ldr伪指令;可以将任意32位数传输给目标寄存器;详细见4.7节
ldr r0,=0xffffffff @立即数前是=,表示是ldr伪指令;
偷懒法:
如果立即数在0-255范围内,用mov,只要超出255,就用ldr伪指令
4.2.3 mov的扩展用法
mvn指令—数据取反指令,用于生成位掩码或者求反码和补码;
mvn r4,0x0 @将第二操作数取反之后赋值给目标寄存器
mov r6, r1, lsl#1 @将r1的值左移1位赋值给r6,lsl表示左移,后跟移位位数;
Mov r6, r1, lsr#1 @将r1的值右移1位赋值给r6,lsr表示右移,后跟移位位数;
4.3 算术指令
4.3.1 add指令
add r0,r1,r2 @r0 = r1+r2
add r0,r0,r1 @r0 = r0+r1-->add r0,r1
add r0,r1,r2,lsl #1 @r0 = r1 + (r2 << 1)
add r0,#1 @r0+=1
add r0,r1,#1 @r0=r1+1
类似的有:sub 减法;mul乘法;
4.3.2 adc指令
带进位的加法,指加的时候加上上一次运算的进位,与add指令联合使用。
@以下代码实现了两个128位的数相加,
@第一个数用r4,r5,r6,r7;
@第二个数用r8,r9,r10,r11;
@结果用r0,r1,r2,r3;
addS r0,r4,r8
adcS r1,r5,r9 @会加上进位
adcS r2,r6,r10 @会加上进位
adcS r3,r7,r11 @会加上进位
4.3.3 用于减法sub的是sbc指令
即带借位的减法
@两个64位数减法
@(r1,r0)-(r3,r2)=(r1,r0);
subS r0,r0,r2
sbcS r1,r1,r3 @高位相减时还要减去低位的借位;
4.3.4 rsb和带借位的rsc指令
rsb是逆向的减法,即用后面的寄存器来减前面的寄存器;
rsb r2,r0,#0xff @r2=0xff-r0;
rsbS r2,r0,#0
rsc r3,r1,#0 @相减时带上借位;
4.3.5 单数据交换指令swp
用于交换
swp r1,r1,[r0] @将r1和r0存地址上的数据进行交换
swp r1,r2,[r0] @将r0地址上的数保存到r1中,再将r2中的数保存到r0存地址的空间上;
4.4 逻辑指令
and r0,r1,r2 @r0 = r1 & r2
orr r0,r1,r2 @r0 = r1 | r2
eor r0,r0,#0xf @将r0的低4位取反
bic r0,#0x2 @将r0的第1位清0,后跟的立即数即是按位清0的控制数;即哪个位写1就清0哪个位;
4.5 比较指令
cmp r0,r1 @比较r0和r1的大小--》影响cpsr的nzcv位--》条件码
tst r0,#0x2 @测试r0的第1位是否为0
cmn r0,#0 @r0减去#0的相反数的结果
teq r0,r1 @两个异或的结果
注意:比较指令会自动更新cpsr的值,不需要加S
相当于:
cmp对应减法
cmn对应加法
tst对应与运算
teq对应异或运算
这四个指令都是用相应运算之后的结果来改变标志位;
4.6 跳转指令
4.6.1 什么是语句标号
标号(LABEL)是为一组机器指令所起名字,表示程序中的指令或者数据地址的符号。标号可有可无,只有当需要用符号地址来访问该语句时,才给此语句赋予标号。通过在目标地址的前面放上一个标号,可以在指令中使用标号来代替直接使用地址。标号是程序目标标志,总是和某地址相联系,供转移或循环指令控制转移使用。标号是编译程序使用的,也就是说程序中最后生成的代码中标号都换成了相应的数值。如果想不通,想想C语言中的goto语句;
4.6.2 b与bl
b 语句标号 @无条件跳转指令
b aa @跳转到aa这个语句标号处
bl aa @跳转到aa这个语句标号处,并且将bl aa这条指令的下一条指令的地址保存在lr寄存器中,bl指令实现了跳转,执行完函数代码后,把lr中的地址值mov给pc,就又跳回了之前的位置继续执行下一条指令,从而实现函数调用;
4.7 内存操作指令
4.7.1 单个内存空间ldr与str
ldr:将一个地址所指内存空间的内容拷贝到一个寄存器中;
str:将一个寄存器中的内容拷贝到一个地址指定的内存空间中;
简单来讲,ldr是拿回来,str是送出去;
(1) ldr指令:ldr r1,[r0]这条指令,r0上的数据被认为是地址,[ ]表示:不是取寄存器上的值,而是访问这个寄存器上存的地址所指的内存空间,那么这条指令就表示去拿r0存的地址上的值,放到r1中;相当于通过指针间接访问,然后直接赋值给目标寄存器;
(2) str指令:str r1,[r2]这条指令,是把r1上的数据取出来,放到r2存的地址所指的内存空间上面;
(3) 另外还有ldrb和strb,表示在操作数据时仅访问一个字节;ldrh和strh,表示访问2字节,halfword;
ldr r1,[r0] @r1 = *r0
str r1,[r2] @*r2 = r1
@以下两句都表示先访问内存的数据,然后对内存地址进行+1的操作,即会改变r0和r1上的地址;
ldrb r2,[r0],#1 @r2 = *r0,r0 = r0+1
strb r2,[r1],#1 @*r1 = r2, r1 = r1 + 1
@以下两句都表示直接访问(寄存器上内存地址+1的地址)所指向空间的数据的操作,不改变r0和r1上的地址;
ldrb r2,[r0, #1] @r2 = *(r0+1)
strb r2,[r1, #1] @*(r1+1)= r2
ldr伪指令:
(1) ldr r0,=1234这条指令有=,所以是ldr伪指令,后跟一个不加#的立即数,表示将这个数放入r0寄存器,立即数可以是32位的任意数;
(2) ldr r0,=biaoshifu这条指令的=后跟一个我们自己定义的标识符,或者说语句标号,表示将标号的地址放入r0,
@定义一个数据类型是word的值是0x00的数据,然后用a来做这个数据的标号,那么a表示a所处位置的地址,也就是这个数据的地址;所以用a就能访问到这个数据,也就是说,定义了一个word类型的变量a;
a:
.word 0x00
@上面是在定义数据
ldr r0,=a @将a变量的地址赋值给了r0 ldr是伪指令
@注意:涉及到常量的,应该考虑到内存分区,代码放在代码段,常量放在常量区;具体怎么放可以查看第5节和程序示例;
4.7.2 连续内存空间
ldm:将一块连续内存空间的内容拷贝到一组寄存器中
stm:将一组寄存器中的内容拷贝到一块连续的内存空间中
简单来讲,ldm是送出去,stm是拿回来;
既然是连续的内存空间,那就要考虑到大小端,数据访问和内存地址变化先后的问题:
(1) 内存的变化方向:i:increase;d:decrease;
(2) 地址变化的先后:a:after;b:before;
两两组合:
ia:先访问内存,后增加地址 p++
ib:先增加地址,再访问内存 ++p
da:先访问内存,后减小地址 p–
db:先减小地址,再访问内存 --p
后缀到指令:
ldmia stmia
ldmib stmib
ldmda stmda
ldmdb stmdb
ARM一般使用的是ldmia、stmia,为什么?查看cpsr寄存器第9位E位,可知arm默认小端序,低字节放在低地址;那么就是先在低地址访问低字节,然后地址增加,继续遍历;
下面来看具体指令:
@r0存放的是一块连续内存空间的首地址,将r0地址处的内容依次拷贝到@r1 r2 r3 r4 r5这组寄存器中
Ldmia r0,{r1-r5}
@将r1-r5这组寄存器中的内容拷贝到r6为首地址的内存空间中
Stmia r6,{r1-r5}
@寄存器不连续的写法:
Ldmia r0, {r1,r3,r5}
注意:
(1) 寄存器连续的写法:{r1-r5}或{r5,r4,r3,r2,r1} 不管寄存器的顺序是如何写的,总是先访问小编号的寄存器,但不能写成{r5-r2}会报错;验证程序在第五章第2节最后一张图片;
(2) 如果没有!后缀,这两个指令会完成任务,但是r0和r6寄存器上存的地址没有发生改变,如果想要使地址变为移动后的值地址,加上!后缀;
@在下面的代码中,其中!表示会更新r0,r1的值,好比*(p++),不加!就好比*(p+i)
ldmia r0!,{r2-r5}
stmia r1!,{r2-r5}
4.7.3 堆栈操作
程序示例放在第五章第3节;
4.7.3.1 万恶的《堆栈》
堆栈这个两个字,迷惑了多少学习编程的人,恶心那,恶心!
如果是内存分区,那么堆栈,分别指堆区和栈区,是两块独立的内存分区,各自有各自的功能;
如果是数据结构或者说在编程中进行堆栈操作,那指的是操作先进后出后进先出的栈,是可以操作的一种数据结构,都在栈顶操作;当然;
4.7.3.2 堆栈相关的概念
(1) 增栈:地址变化方向从小到大,也就是sp的初始值是个小地址,每进栈一个数据,sp就要增加
(2) 减栈:地址变化方向从大到小,也就是sp的初始值是个大地址,每进栈一个数据,sp就要变小
(3) 入栈:*sp = 10
(4) 出栈:r0 = *sp
(5) 满栈:栈顶有数据,所以不能直接入栈,需要先移动sp,再访问
(6) 空栈:栈顶没有数据,可以直接入栈,先访问,再移动sp
增a减d;满f空e;
ARM常用的是满减栈 stmfd ldmfd
4.7.3.3 堆栈操作程序请看第五章第3节
4.8 软中断指令
本节请结合第五章第3节;
4.8.1 swi指令
swi:软中断指令,执行了这个指令,会产生一个软件中断;
swi:software interrupt软件中断。该指令产生一个SWI异常。意思就是处理器模式改变为超级用户模式,CPSR寄存器保存到超级用户模式下的SPSR寄存器,并且跳转到SWI向量;
ARM指令格式如下:
SWI{cond} immed_24
(1) Cond域:是可选的条件码 (参见 ARM汇编指令条件执行详解).
(2) immed_24域:范围从 0 到 2^24-1 的表达式, (即0-16777215)。用户程序可以使用该常数来进入不同的处理流程。
(3)机器指令格式:
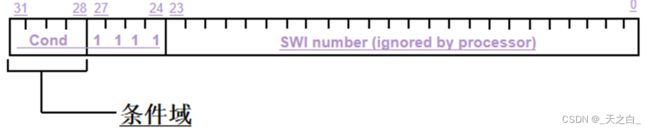
观察机器指令,immed_24的数字保存在0-23位;比如用户写下swi 2之后,0-23位变成了000…10(24位);
(4)immed数用途,可以在用户程序中在几条swi指令后跟不同的数,然后在中断程序中判断跟的哪个数来执行不同的程序语句;关于具体怎么判断请看第五章第3.2节程序示例;
4.8.2 中断是随机产生的,如何找到中断处理程序?
cpu被设计为:我们在程序中写一个异常向量表,cpu知道此时是什么异常以及这个异常在异常向量表中的位置,异常向量表中每个异常源都有四个字节的空间,刚好是一个指令需要的大小,所以这四个字节中放的就是一个跳转到对应异常处理程序的指令,所以发生异常时,cpu从异常向量表执行跳转指令到异常处理函数位置;
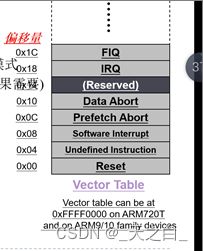
异常模式 异常源
Fiq fiq中断产生
Irq irq中断产生
Svc 复位、swi
Abort 数据存取异常、预取址异常
Undef 执行未定义指令
异常向量表:一个32个字节的数组,地址是从0x00开始,被分成了8份,每一份占4个字节,每一份对应一个异常源(7个异常源,包括预留的一份),每一种异常源的地址是固定好的,必须严格遵守,所以即使程序中没有写某个异常处理程序,也要在对应位置用一个nop来占位置;
4.8.3 mrs指令和msr指令
CPSR和SPSR寄存器比较特殊,需要专门的指令访问,这就是mrs和msr。
mrs用来读cpsr或者spsr,msr用来写cpsr或spsr;
mrs r0, cpsr @r0 = cpsr
msr cpsr, r0 @cpsr = r0
4.8.4 当中断产生时,处理器会做哪些事情?我们需要做哪些事情?

我们需要做哪些事情?----保存现场到栈区:
用连续地址访问指令ldrm把用到的寄存器和lr一次性保存到栈区我们自己申请的空间内;
4.8.5 当中断处理程序执行完之后,我们需要做哪些事情?
恢复现场–》恢复寄存器的值:用连续地址访问指令strm把栈区我们自己申请的空间内的数据放回到异常之前的寄存器和lr中;
恢复lr到pc—》继续执行之前的代码;那不如直接把栈中的数据返回到pc中,不要中间经过lr;
将spsr的值恢复到cpsr–》恢复工作模式,工作模式不会自动回复,需要我们手动恢复;
5 常用伪操作
5.1 符号定义伪操作
.global @该伪指令的含义是让global过的符号对链接器ld可见,变成整个工程都可以使用的全局变量;一个函数或变量,通常情况下只在本文件内有效,当需要在外部引用该文件里的某一个函数或变量时,必须首先将该函数或变量使用.global伪指令进行声明;
.local @声明一个局部变量,对外部不可见,作用域是本文件;
.align expr @后面的内容以expr字节对齐,值为1,2,4,8,16等
.text @告诉编译器以下的代码放在代码段,即定义一个指令段;
.data @告诉编译器以下内容放在初始化数据区,即定义一个数据段;
.section @定义一个段;
.include @用于包含头文件
.include"abc.h"
.arm @以下代码用arm指令集编译,等价于.code32
.thumb @以下代码用thumb指令集编译,等价于.code16
.weak 符号 @声明一个弱符号,如果后面使用了这个符号但是还没有定义,不报错;
.end @告诉编译器汇编文件结束
.set @用于给一个变量赋值;
.set start,0x40
.set start,0x50
mov r1,#start
@经过三条指令后,r1的值为0x50;
.equ @宏替换伪操作,用于给一个变量赋值;
start .equ,0x40
start .equ,0x50
mov r1,#start
@经过三条指令后,r1的值为0x50;
5.2 数据定义伪操作
数据定义伪操作用于为特定的数据分配存储单元,同时对该内存单元中的数据进行初始化;指令格式为label: 点+类型 数据
a: .byte #1 @char a=1
a: .short 0x1234 @short a=0x1234
a: .word 0x12345678 @int a=0x12345678
.long = .word
a: .quad 0x123456789abcd @申请的是8个字节空间
a: .float 1.11 @类似于float a=1.11
a: .space 8 @申请8个字节的连续空间并初始化为0;
a: .space 8,0x1 @申请8个字节的连续空间并初始化为0x1;
.skip = .space
a: .string "abc" 类似于char a="abc";
@功能相同的还有.ascii和.asciz;
5.3 控制伪操作
@.rept功能是重复执行后面的指令,以.rept加次数开始,以.endr结束;
.rept 3
mov r0,#1
.endr
@执行了三次mov指令;
.if 条件 @类似于C语言中的#if
@中间放上代码
.elseif
@中间放上代码
.else
@中间放上代码
.endif
.macro macroname macargs... @macroname是宏名,macargs是参数;
@宏代码;
.endm
@以下为代码示例:
.macro sum from=0,to=5
.long \from
.if \to-\from
sum (\from+1),\to
.endif
.endm
@其中“\”在宏指令在被展开时,用来取变量的值;
@在程序中调用宏,展开后,这个宏被替换为:
.long 0
.long 1
.long 2
.long 3
.long 4
.long 5
5.4 ARM汇编器支持的伪指令
arm伪指令在汇编阶段被编译成arm或者thumb指令或者指令序列,即伪指令是在汇编阶段编译器对其进行了替换。
5.4.1 adr伪指令
@adr rn,label @把标签所在地址加载到寄存器中
start: mov r0,#0x1
adr r1,start @相当于sub r1,pc,#0x0c,PC的值是当前指令地址加8,所以减去12后能得到上一条指令的地址;
5.4.2 adrl伪指令
与adr指令类似,但是后面的label可以是基于原label的表达式,这样就可以把更大范围的地址装载到rn中;
adrl在编译时会被转换成两条指令,只要是两条指令内可以完成的,都换成两条;如果必须用到三条或以上,则报错;
如:
start: mov r0,#1
adrl r1,start+6000
编译后变成:
add r1,pc,#59392
add r1,#596
@pc+59392+596=pc-12+6000
5.4.3 ldr伪指令
上面讲mov指令时已经谈到;
6 汇编中的寻址方式
先学习具体的语法,再来看这些寻址方式,是不是感觉就一下子能接受了;

再插入一次目录方便查找
文章目录
-
- 一 汇编语言是什么
- 二 汇编语言的基本语法
-
- 1 汇编语言的注释
- 2 立即数
- 3 先了解程序状态寄存器
-
- 3.1 条件码标志位
- 3.2 控制位
- 4 基本指令
-
- 4.1 指令基本格式
- 4.1.1 汇编指令格式
- 4.1.2 条件码
- 4.1.3 mov指令的机器指令格式:
- 4.2 数据传输指令mov
-
- 4.2.2 怎么解决mov中立即数的范围问题;
- 4.2.3 mov的扩展用法
- 4.3 算术指令
- 4.4 逻辑指令
- 4.5 比较指令
- 4.6 跳转指令
-
- 4.6.1 什么是语句标号
- 4.6.2 b与bl
- 4.7 内存操作指令
-
- 4.7.1 单个内存空间ldr与str
- 4.7.2 连续内存空间
- 4.7.3 堆栈操作
-
- 4.7.3.1 万恶的《堆栈》
- 4.7.3.2 堆栈相关的概念
- 4.7.3.3 堆栈操作程序请看第五章第3节
- 4.8 软中断指令
-
- 4.8.1 swi指令
- 4.8.2 中断是随机产生的,如何找到中断处理程序?
- 4.8.3 mrs指令和msr指令
- 4.8.4 当中断产生时,处理器会做哪些事情?我们需要做哪些事情?
- 4.8.5 当中断处理程序执行完之后,我们需要做哪些事情?
- 5 常用伪操作
-
- 5.1 符号定义伪操作
- 5.2 数据定义伪操作
- 5.3 控制伪操作
- 5.4 ARM汇编器支持的伪指令
- 6 汇编中的寻址方式
- 三 编程示例
-
- 1 ldrb和strb指令程序实例
-
- 1.1 ldrb+单个内存空间
- 1.2 ldrb+连续内存空间
- 2 ldm和stm指令示例
- 3 swi指令示例
-
- 3.1 基本示例
- 3.2 swi 参数用法完整示例程序
- 四 与C语言混用的内联汇编和内嵌汇编
- 五 过程调用标准AAPCS/ATPCS
-
- 1 子函数的参数
- 2 局部变量
- 3 堆栈相关
上面为第二次目录方便查找
三 编程示例
1 ldrb和strb指令程序实例
1.1 ldrb+单个内存空间
.text @告诉编译器以下的代码放在代码段
@分别将aa和bb的地址存放在r0和r1中,aa和bb定义在.data区,见后面的代码
ldr r0,=aa
ldr r1,=bb
ldrb r2,[r0] @将r0存的地址指向空间的值取出来一个字节放到r2中;
strb r2,[r1] @将r2上的值放到r1存的地址指向的空间;
nop @空指令
.data @表示以下内容放在.data区
aa: @定义aa变量
.word 0x12345678
bb: @定义变量bb
.word 0x00
.end @汇编文件结束
运行结果:

1.2 ldrb+连续内存空间
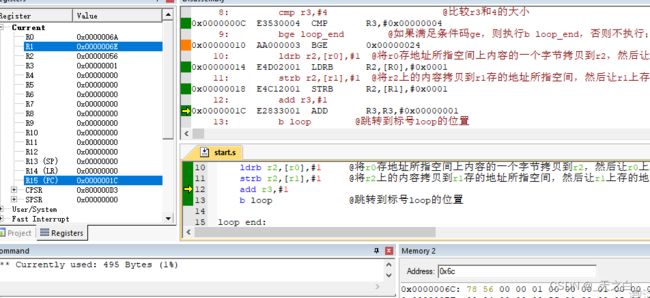
下面这段代码中的loop代码块:实现了一次循环;从 loop开始,先比较r3与4的大小,如果r3的值等于4,就跳转到 loop_end结束循环,如果r3的值还没有等于4,就不跳转,而是执行ldrb和strb,并使r3+1;然后再跳到 loop的位置继续下一次循环;
.text @告诉编译器以下的代码放在代码段
@分别将aa和bb的地址存放在r0和r1中,aa和bb定义在.data区,见后面的代码
ldr r0,=aa
ldr r1,=bb
mov r3,#0 @使r3存立即数0
loop: @定义一个语句标号
cmp r3,#4 @比较r3和4的大小
bge loop_end @如果满足条件码ge,则执行b loop_end,否则不执行;
ldrb r2,[r0],#1 @将r0存地址所指空间上内容的一个字节拷贝到r2,然后让r0上存的地址+1;
strb r2,[r1],#1 @将r2上的内容拷贝到r1存的地址所指空间,然后让r1上存的地址+1;
add r3,#1
b loop @跳转到标号loop的位置
loop_end:
nop @空语句
.data @表示以下内容放在.data区
aa: @定义aa变量,aa是地址,aa地址指向的空间上放的是0x12345678;
.word 0x12345678
bb: @定义变量bb,bb是地址,bb地址指向的空间上放的是0x00;
.word 0x00
.end @.data区结束
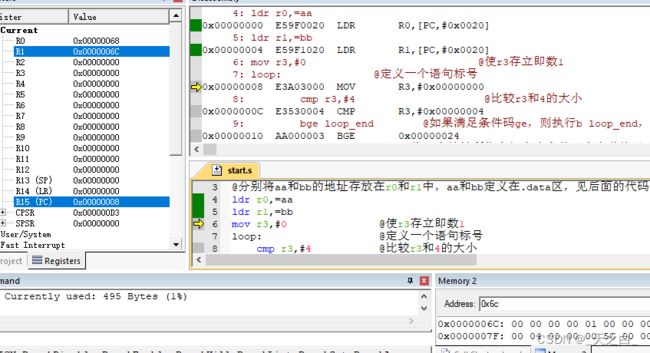
以下是运行过程中循环时的部分截图,观察寄存器r0,r1,r2和bb的地址上的值,可以看出代码控制的循环过程;
下面这张图中,执行了第4,5行的代码,r0和r1分别获得了aa和bb的地址;我们在右下角观察bb地址上的数据;
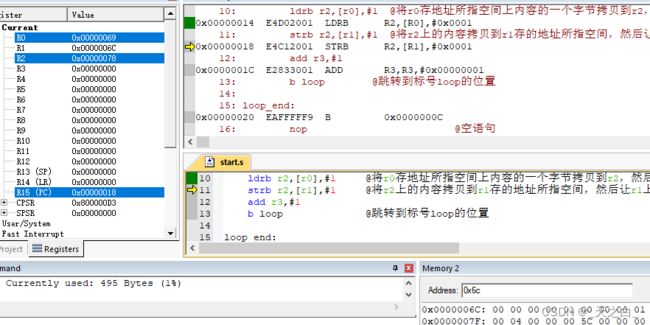
下面这张图中,执行了第10行的代码,r2获得了aa地址上的一个字节,因为arm默认是小端序,因此获取的是低字节;之后,r0上的地址进行了+1;
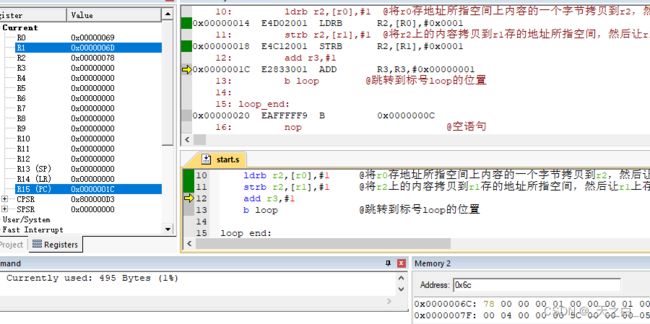
下面这张图中,执行了11行的代码,将r2上的数据传输给r1地址所指空间,然后将r1的地址加1,注意,只是r1上存的地址加1,bb的地址还是0x6c,在右下角可以看到,这个地址上已经获得了数据0x78;
下面这张图中,已经进入了第二次循环,可以看到r0,r1上的地址又增加,r2上获得了另一个字节,0x6d上获得了这个字节;
可以观察PC,LR,CPSR寄存器来观察循环的过程,这里就不看了;


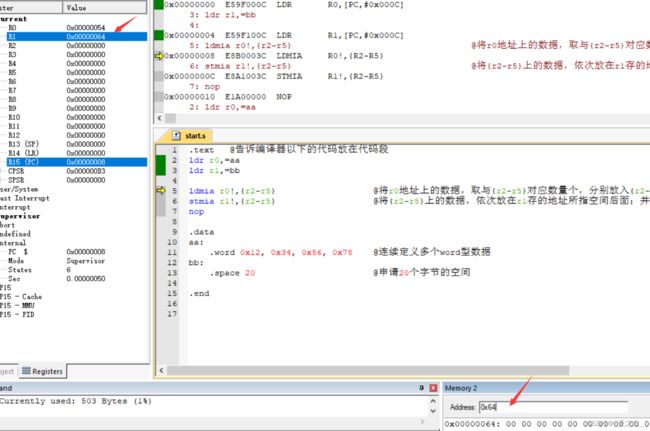
2 ldm和stm指令示例
.text @告诉编译器以下的代码放在代码段
ldr r0,=aa
ldr r1,=bb
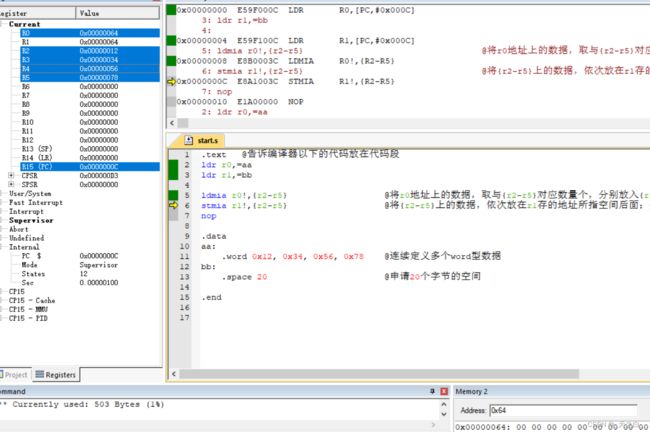
ldmia r0!,{r2-r5} @将r0地址上的数据,取与{r2-r5}对应数量个,分别放入{r2-r5},并改变r0上存放的地址;
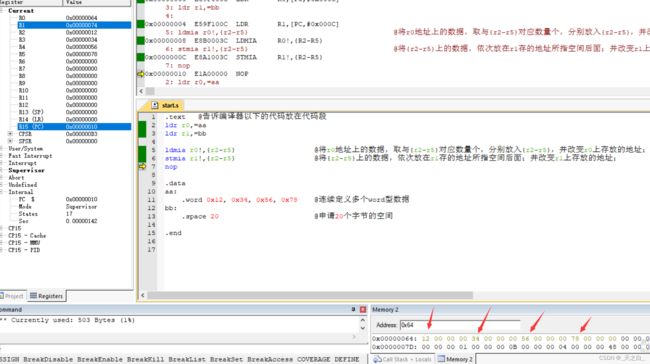
stmia r1!,{r2-r5} @将{r2-r5}上的数据,依次放在r1存的地址所指空间后面;并改变r1上存放的地址;
nop
.data
aa:
.word 0x12, 0x34, 0x56, 0x78 @连续定义多个word型数据
bb:
.space 20 @申请20个字节的空间
.end
下面的图中,执行完第2,3行代码后,r0,r1上存放aa和bb的地址,右下角准备查看bb地址处的值;
如下图,执行完第5行代码后,因为“ !”后缀,r0上的地址已经变为了0x64,与aa地址差了0x10即16个字节即4个数据的空间大小;且r2-r5上获得了值,从这里可以看出,执行ldm命令,{r2-r5}的访问顺序是从小序号到大;代码中即使写成{r5,r4,r3,r2},访问顺序也是从小序号到大;验证代码在本小节最后一张图片;
如下图中,执行完第6行代码后,r1的地址变成了0x74,和bb的地址差0x10即16字节即4个数据;观察右下角0x64上已经放上了相应的值;
下图是验证ldm指令中寄存器顺序,图中ldmia r0!,{r5,r4,r3,r2} 与ldmia r0!,{r2-r5}相反,但依然有相同的输出;
但是,这样写会报警告,若是写成{r5-r2}直接报错,因此,还是按顺序写比较好;
stm同理;

3 swi指令示例
3.1 基本示例
.text @告诉编译器以下的代码放在代码段
@异常向量表 @必须放在程序开头,表中每个向量的地址或者说位置已经固定,必须要按顺序来写,(当异常发生时,硬件电路使得cpu直接到表中相应位置执行指令)所以即使没有处理程序,也要用nop语句占位置;每个地址隔4个字节,刚好是一个字节,一个指令的大小,放上跳转指令,就实现了异常发生而执行处理函数;
b reset @0x00 reset
nop @0x04 undef
@ldr pc,=swi_handler
b swi_handler @0x08 swi @pc = pc+偏移量 正负32M的限制;当执行到swi语句时,cpu会跳到这里来执行这里的指令;
@mov pc, swi_handler
nop @0x0c prefetch abort
nop @0x10 data abort
nop @0x14 reserved
nop @0x18 irq
nop @0x1c fiq
reset: @上电或复位后到这里,此时是svc模式
ldr sp,=svc_stack_top @给sp寄存器栈顶值;
@切换到user模式:将cpsr的0-4位设置为10000-》0x10
mrs r0, cpsr @先将cpsr的值拿出来;
bic r0, #0x1f @先把模式位全清0;
orr r0, #0x10 @把模式为设置成user模式的值;
msr cpsr, r0 @把改好的值放回去;
_main: @然后就开始进入用户的主程序;
mov r1,#0x11
mov r2,#0x22
nop
swi 2 @相当于mov pc, 0x08-->cpu自动跳转;
nop @执行swi指令时,这条nop指令的地址被存入lr中;
_main_end: @程序执行完进入死循环;
b _main_end;
@swi的中断处理程序
@svc模式
swi_handler: @开始swi中断处理程序
@入栈保存现场
stmfd sp!,{r0-r12,lr} @把中断前程序中的所有寄存器的值都保存起来到之前申请的栈中;为了之后跳回去,把lr的值也保存;
nop @执行中断语句;
mov r1,#0x66
mov r2,#0x77
nop
swi_handler_end: @中断程序结束后,出栈恢复现场
ldmfd sp!,{r0-r12, pc}^ @加上^:将spsr的值恢复到cpsr;最后本来应该写lr,然后lr传给pc,优化为:这里写pc,直接将lr的值传给pc;
.data
.space 100 @申请100个字节的空间当作栈;
svc_stack_top: @定义栈底地址;因为是满减栈,栈底是最大地址,所以栈底(初始栈顶)标号放在申请的空间最后;这样就定义好了一个满减栈;
.end
请自己仿真验证;
程序执行流程:上电复位执行b reset;程序将svc模式改为user模式,然后执行用户代码,当执行到swi语句时,由cpu执行跳转到中断向量表的0x08地址执行b swi_handler指令并改变工作模式为svc;开始执行中断处理程序,执行完之后又回到中断前的位置的下一条语句继续执行用户程序,需要手动切换工作模式;
3.2 swi 参数用法完整示例程序
.text @告诉编译器以下的代码放在代码段;
.global _start @使_start对编译器和链接器可见;
_start:
@异常向量表
b reset @0x00 reset
nop @0x04 undef
@ldr pc,=swi_handler
b swi_handler @0x08 swi @pc = pc+偏移量 正负32M的限制
@mov pc, swi_handler
nop @0x0c prefetch abort
nop @0x10 data abort
nop @0x14 reserved
nop @0x18 irq
nop @0x1c fiq
reset:
@此时是svc模式
ldr sp,=svc_stack_top
@切换到user模式
@将cpsr的0-4位设置为10000-》0x10
mrs r0, cpsr
bic r0, #0x1f
orr r0, #0x10
msr cpsr, r0
mov r1,#0x11
mov r2,#0x22
nop
swi 2 @mov pc, 0x08-->cpu自动跳转的,因为cpu设计好的 open
nop
swi 3 @read
nop
@swi的中断处理程序
@svc模式
swi_handler:
@入栈保存现场
stmfd sp!,{r0-r12,lr}
sub r0, lr,#4 @得到软中断指令存放的内存地址
ldr r3,[r0] @得到地址处的内容,也就是swi指令的机器码
bic r3, #0xff000000 @得到软中断号
@判断
cmp r3,#2
moveq r4,#2 @bl sys_open
cmp r3,#3
moveq r4,#3
nop
mov r1,#0x66
mov r2,#0x77
nop
swi_handler_end:
@出栈恢复现场
ldmfd sp!,{r0-r12, pc}^ @^:将spsr的值恢复到cpsr
.data
.space 100
svc_stack_top: @满减栈 栈顶
.end
四 与C语言混用的内联汇编和内嵌汇编
五 过程调用标准AAPCS/ATPCS
它们是子程序调用的规则
1 子函数的参数
子函数传参最多可以使用四个寄存器,r0-r3,如果参数超过4个,多出的部分用堆栈传递;
2 局部变量
用r4-r11做子程序的局部变量;所以如果要用这些寄存器,在跳转后要先保存这些寄存器的值;返回的时候要恢复这些寄存器;在thumb程序中,通常只用r4-r7;
3 堆栈相关
r12用作子程序间scratch寄存器,用于保存sp,在函数返回时使用该寄存器出栈;
r14是栈顶指针,sp在进入子程序和退出子程序时的值必须相等;