嵌入式ARM体系结构总结
可编程器件
电子器件的发展方向:
模拟器件→数字器件;
专用集成电路(ASIC)→可编程器件。
可编程器件的特点:
CPU在固定频率的时钟控制下节奏运行。 CPU可以通过总线读取外部存储设备中的二进制指令集,然后解码执行。 这些可以被CPU解码执行的二进制指令集是CPU设计的时候确定的,是CPU的设计者(ARM公司)定义的,本质上是一串由1和0组成的数字。这就是CPU的汇编指令集。
整个编程及运行过程:
程序员用汇编指令编程 --经汇编器汇编成二进制可执行程序文件-->二进制文件被CPU读取进去-->CPU内部电路对二进制文件解码-->解码通过则CPU执行指令、完成指令动作。 如果程序员用C语言等高级语言编程,则编译器先将C语言程序编译为汇编程序,再进行上面的后续部分。

汇编语言
汇编语言与C等高级语言的差异:
汇编难写,C好写 汇编无可移植性,C语言有一定可移植性,Java等更高级语言移植性更强。 汇编语言效率最高,C语言次之,Java等更高级语言效率更低。 汇编不适合完成大型复杂的项目,更高级语言更适合完成更大、更复杂的项目。
编程语言发展历程:
纯机器码编程
汇编语言编程
C语言编程
C++语言编程
Java C#等语言编程
脚本语言编程
汇编语言的本质:
汇编的实质是机器指令(机器码)的助记符,是一种低级符号语言。 机器指令集是一款CPU的编程特征,是这款CPU的设计者制定的。CPU的内部电路设计就是为了实现这些指令集的功能。
RISC和CISC
精简指令集CPU(RISC:Reduced Instruction Set Computer)是一种执行较少类型计算机指令的微处理器,类似于提供原材料,更多具体功能由程序员来实现。
RISC的设计理念是让软件来完成具体的任务,CPU本身仅提供基本功能指令集。因此RISC CPU的指令集中只有很少的指令,这种设计相对于CISC,CPU的设计和工艺简单了,但是编译器的设计变难了。代表性处理器如ARM。
复杂指令集CPU(CISC:Complex Instruction Set Computer)是一种自带有较多指令的微处理器。基本上能想到的功能都有一条单独的指令即可完成。
CISC体系的设计理念是用最少的指令来完成任务(譬如计算乘法只需要一条MUL指令即可),因此CISC的CPU本身设计复杂、工艺复杂,但好处是编译器好设计。CISC出现较早,至今Intel还一直采用CISC设计。51单片机也是这种方式的。
CPU设计方式发展:
早期简单CPU,指令和功能都很有限
CISC年代 —— CPU功能扩展依赖于指令集的扩展,实质是CPU内部组合逻辑电路的扩展。
RISC年代 —— CPU仅提供基础功能指令(譬如内存与寄存器通信指令,基本运算与判断指令等),功能扩展由使用CPU的人利用基础架构来灵活实现。
不过当今时代没有纯粹的RISC或CISC,发展方向是RISC与CISC结合,形成一种介于2者之间的CPU类型。
一般典型CISC CPU指令在300条左右 ARM CPU常用指令30条左右
统一编址和独立编址
IO和内存:
内存是程序的运行场所,内存和CPU之间通过总线连接,CPU通过一定的地址来访问具体内存单元。
IO(input and output)是输入输出接口,是CPU和其他外部设备(如串口、LCD、触摸屏、LED等)之间通信的道路。一般的,IO就是指CPU的各种内部或外部外设。
在不同的系统中,I/O端口的地址编排有两种形式:存储器统一编址和I/O独立编址。
存储器统一编址(存储器映像编址):
在这种编址方式中,I/O端口和内存单元统一编址,
即把I/O端口当作内存单元对待,
从整个内存空间中划出一个子空间给I/O端口,
每一个I/O端口分配一个地址码,
用访问存储器的指令对I/O端口进行操作。存储器统一编址的优点是:
I/O端口的数目几乎不受限制;
访问内存指令均适用于I/O端口,对I/O端口的数据处理能力强;
cpu无需产生区别访问内存操作和I/O操作的控制信号,从而可减少引脚。存储器统一编址缺点是:
程序中I/O操作不清晰,难以区分程序中的I/O操作和存储器操作;
I/O端口占用了一部分内存空间;
I/O端口地址译码电路较复杂(因为内存的地址位数较多)。I/O独立编址:
I/O端口编址和存储器的编址相互独立,
即I/O端口地址空间和存储器地址空间分开设置,互不影响。
采用这种编址方式,对I/O端口的操作使用输入/输出指令(I/O指令)。I/O独立编址的优点是:
不占用内存空间;
使用I/O指令,程序清晰,很容易看出是I/O操作还是存储器操作;
译码电路比较简单(因为I/0端口的地址空间一般较小,所用地址线也就较少)。
I/O独立编址缺点是:只能用专门的I/O指令,访问端口的方法不如访问存储器的方法多。编址总概:
上面两种编址方式各有优点和缺点,
究竟采用哪一种取决于系统的总体设计。
在一个系统中也可以同时使用两种方式,
前提是首先要支持I/O独立编址。
如:Intel的x86微处理器支持I/O独立编址,
因为它们的指令系统中都有I/O指令,
并设置了可以区分I/O访问和存储器访问的控制信号引脚。
而一些微处理器或单片机,为了减少引脚,从而减少芯片占用面积,
不支持I/O独立编址,只能采用存储器统一编址。ARM采用的就是统一编址。
进一步理解统一编址
最近看到SDRAM的课程,发现内存SDRAM只有0—13的14根数据总线,就算是两个并联在一起,也只有28根,即256M的内存空间。我很疑惑,怎么不是32根呢?不是说arm210是32位数据总线和32位地址总线吗?
对呀,到底是为啥?
首先,32位CPU通常指的都是数据总线的根数,一次性读取32位数据(4个字节),说明了这个CPU处理数据的效率,而并不是根据地址总线来决定的,这个能理解。
数据总线的根数和地址总线的根数没有必然联系,数据总线决定数据读取效率,地址总线决定能够编址的范围。
我猜想,32位指的是该CPU所能编址的最大范围是4G,但是,并不是说这些地址都要给内存,因为采用的是统一编址,所以这32位地址其实是分配给了不同的功能,比如说寄存器占用了一部分地址编码。这样能理解。
在arm210中,内存实际是占用了0x20000000-7FFFFFFF这么多的地址空间,即1.5G。
不过,还是不懂为什么只有14根数据总线。。。

哈佛结构和冯诺依曼结构
程序运行时两大核心元素:程序 + 数据
程序是我们写好的源代码经过编译、汇编之后得到的机器码,这些机器码可以拿给CPU去解码执行,CPU不会也不应该去修改程序,所以程序是只读的。
数据是程序运行过程中定义和产生的变量的值,是可以读写的,程序运行实际就是为了改变数据的值。
什么是冯诺依曼结构、哈佛结构、改进型哈佛结构?_夜风~的博客-CSDN博客_哈佛结构
程序和数据都放在内存中,且不彼此分离的结构称为冯诺依曼结构。譬如Intel的CPU均采用冯诺依曼结构。 程序和数据分开独立放在不同的内存块中,彼此完全分离的结构称为哈佛结构。譬如大部分的单片机(MCS51、ARM9等)均采用哈佛结构。
冯诺依曼结构中程序和数据不区分的放在一起,因此安全和稳定性是个问题,好处是处理起来简单。 哈佛结构中程序(一般放在ROM、flash中)和数据(一般放在RAM中)独立分开存放,因此好处是安全和稳定性高,缺点是软件处理复杂一些(需要统一规划链接地址等)
寄存器
不要把寄存器想象成内存或者硬盘一样,是一个独立的整块的盘;
寄存器是这样的模块,它是一种设计电路,这种电路可以用来存储指令、地址、数据等等,在CPU的控制器以及运算器的设计中,就有很多寄存器,当控制器或者运算器需要存储一些东西时,就会使用到这种设计电路。比如,要进行两个数的加法,CPU把内存中的两个数读取过来后,就要用到寄存器,来暂存和处理数据。参考这个视频:寄存器是什么?_哔哩哔哩_bilibili
CPU 寄存器 和内存三者之间的关系_Firm陈的博客-CSDN博客_寄存器在cpu里面吗
内部寄存器:指的是CPU内核里的寄存器,如r0,r1等;
外设寄存器:一般是指一些某一特殊功能的物理地址,嵌入式通过编程来控制外设寄存器从而控制芯片外部的外设。
寄存器属于CPU的组成部分,就算有的名字叫做外设寄存器???
我一开始想的是寄存器在外设接口那里,比如在USB接口那里,后来想想,寄存器不是在CPU内部嘛。
查了很多资料还是没弄明白寄存器到底是个啥?
既然说寄存器在CPU内部,那么为什么又说外设寄存器,难道外设寄存器在CPU外部?
还有一个问题,既然是统一编址,分的是地址,为什么要占用实际的内存空间?还是说,只占用内存的空间地址?
参考了这两篇文章:
外设寄存器在STM32中的什么位置?它们是在皮层-m核心还是在外围单元本身? - 问答 - 云+社区 - 腾讯云单片机外设(ram、寄存器)地址详解_wx60bf0f6c32435的技术博客_51CTO博客
大概意思是,外设寄存器并非存在于CPU内部,而是存在于外设上。我们通过统一编址的方式来控制这些外设寄存器。外设寄存器在STM32中的什么位置?它们是在皮层-m核心还是在外围单元本身? - 问答 - 云+社区 - 腾讯云 也可以直接理解成就是外设的地址。
外设寄存器属于CPU外设的硬件组成部分,CPU可以像访问内存一样访问外设寄存器,外设寄存器是CPU的硬件设计者制定的,目的是留作外设被编程控制的“活动开关” 。正如汇编指令集是CPU的编程接口API一样,外设寄存器是外设硬件的软件编程接口API。使用软件编程控制某一硬件,其实就是编程读写该硬件的寄存器。
编程操作寄存器类似于访问内存 寄存器中每个bit位都有特定含义,因此编程操作时需要位操作。 单个寄存器的位宽一般和CPU的位宽一样,以实现最佳访问效率。
SoC中有2类寄存器:通用寄存器和SFR(special function register,特殊功能寄存器)
通用寄存器(ARM中有37个)是CPU的组成部分,CPU的很多活动都需要通用寄存器的支持和参与。
SFR(special function register,特殊功能寄存器)不在CPU中,而存在于CPU的外设中,我们通过访问外设的SFR来编程操控这个外设,这就是硬件编程控制的方法。
注意:
C语言无法操作内部寄存器,但是可以操作外部寄存器;
汇编语言可以操作内部寄存器。
以SD卡模块为例,我一开始还以为会不会卡槽那边有寄存器设计。现在看来,在SOC里针对每个外设都有个外设模块,这些模块里面就有寄存器的设计,这些电路的总和加上CPU就构成了SOC,各外设模块对外的具体控制就体现在各个引脚上。
ARM的特性
ARM是RISC架构:
常用ARM汇编指令只有二三十条
ARM是低功耗CPU
ARM的架构非常适合单片机、嵌入式,尤其是物联网领域;而服务器等高性能领域目前主导还是Intel
ARM是统一编址的:
大部分ARM(M3 M4 M7 M0 ARM9 ARM11 A8 A9等)都是32位架构
32位ARM CPU支持的内存少于4G,通过CPU地址总线来访问
SoC中的各种内部外设通过各自的SFR编程访问,这些SFR的访问方式类似于访问普通内存,这叫IO与内存统一编址。
ARM是哈佛结构:
常见ARM(除ARM7外)都是哈佛结构的 哈佛结构保证了ARM CPU运行的稳定性和安全性,因此ARM适用于嵌入式领域
哈佛结构也决定了ARM裸机程序(使用实地址即物理地址)的链接比较麻烦,必须使用复杂的链接脚本告知链接器如何组织程序;对于OS之上的应用(工作在虚拟地址之中)则不需考虑这么多
ARM的基本设定
ARM采用的是32位架构
ARM 约定:
Byte :8 bits
Halfword :16 bits (2 byte)
Word : 32 bits (4 byte)
通常一款CPU只有一种指令集,但是大部分ARM core 提供:
ARM 指令集(32-bit)(之后出现的32位指令集,稳定,当前使用的指令集)
Thumb 指令集(16-bit )(最先出现,16位指令集,省空间,但是不健全)
Thumb2指令集(16 & 32bit)(综合)
Jazelle cores 支持 Java bytecode,即支持JAVA加速
ARM处理器工作模式
ARM 有7个基本工作模式:
User : 非特权模式,大部分任务执行在这种模式
FIQ:当一个高优先级(fast) 中断产生时将会进入这种模式
IRQ :当一个低优先级(normal) 中断产生时将会进入这种模式
Supervisor(SVC):当复位或软中断指令执行时将会进入这种模式
Abort :当存取异常时将会进入这种模式
Undef :当执行未定义指令时会进入这种模式
System : 使用和User模式相同寄存器集的特权模式
以上,有1个用户模式+6个特权模式
其中,6个特权模式中,又有5个异常模式+1个系统模式
其中,5个异常模式中,有2个正常异常模式+3个非正常异常模式
各种模式的切换,可以是程序员通过代码主动切换(通过写CPSR寄存器);也可以是CPU在某些情况下自动切换。 各种模式下权限和可以访问的寄存器不同。
CPU为什么设计这些模式?
CPU是硬件,OS是软件,软件的设计要依赖硬件的特性,硬件的设计要考虑软件需要,便于实现软件特性。
操作系统有安全级别要求,因此CPU设计多种模式是为了方便操作系统的多种角色安全等级需要。
补充:
用户模式,运行应用程序的普通模式。限制你的内存访问并且你不能直接读取硬件设备。
超级用户模式(SVC 模式),主要用于 SWI(软件中断)和 OS(操作系统)。这个模式有额外的特权,允许你进一步控制计算机。例如,你必须进入超级用户模式来读取一个插件(podule)。这不能在用户模式下完成。
中断模式(IRQ 模式),用来处理发起中断的外设。这个模式也是有特权的。导致 IRQ 的设备有键盘、 VSync (在发生屏幕刷新的时候)、IOC 定时器、串行口、硬盘、软盘、等等...
快速中断模式(FIQ 模式),用来处理发起快速中断的外设。这个模式是有特权的。导致 FIQ 的设备有处理数据的软盘,串行端口(比如在 82C71x 机器上的 A5000) 和 Econet。
IRQ 和 FIQ 之间的区别是对于 FIQ 你必须尽快处理你事情并离开这个模式。IRQ 可以被 FIQ 所中断但 IRQ 不能中断 FIQ。为了使 FIQ 更快,所以有更多的影子寄存器。FIQ 不能调用 SWI。FIQ 还必须禁用中断。如果一个 FIQ 例程必须重新启用中断,则它太慢了并应该是 IRQ 而不是 FIQ。
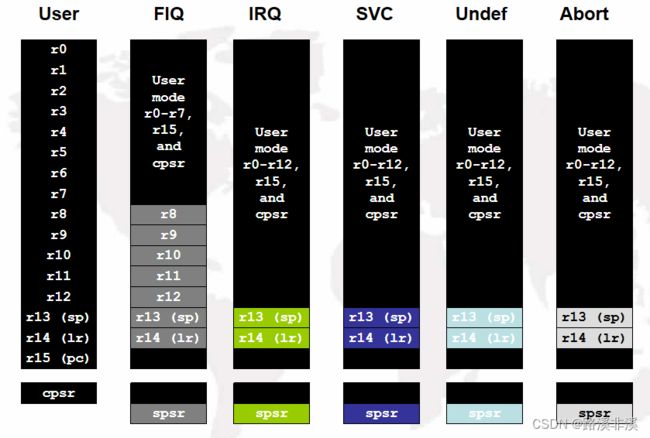
ARM的37个寄存器
1、ARM总共有37个寄存器,但是每种模式下最多只能看到18个寄存器,其他寄存器虽然名字相同但是在当前模式不可见。
2、对r13这个名字来说,在ARM中共有6个名叫r13(又叫sp)的寄存器,但是在每种特定处理器模式下,只有一个r13是当前可见的,其他的r13必须切换到他的对应模式下才能看到。这种设计叫影子寄存器(banked register)
注意:
每种模式下都有cpsr
用户模式下没有spsr,只有17种
r13、r14、spsr在每种模式下都是专用的(除了用户模式没有)
System模式使用user模式寄存器集。
ARM共有37个寄存器,都是32位长度。
37个寄存器中30个为“通用”型,1个固定用作PC,一个固定用作CPSR,5个固定用作5种异常模式下的SPSR。
PC是程序寄存器(program count),PC指向哪里,CPU就会执行哪条指令(所以程序跳转时就是把目标地址代码放到PC中),整个CPU中只有一个PC。(这样不就会被覆盖吗?)
cpsr是程序状态寄存器current program status register。spsr(saved program status register)是用来保存cpsr的,因为各种模式的cpsr都是同一个寄存器,所以,切换模式之后就存在覆盖问题,所以在切换之前,就先将cpsr存入待进入模式的spsr,等到将来返回时,又原封不动地还给原来的cpsr。
通用,指的是这块寄存器的作用是可以根据需求制定的。r13、r14这两个通用寄存器作为sp和lr,是一种约定俗成的习惯。
其中,sp(stack pointer)是堆栈指针,各种模式下的堆栈互不影响,比如当前模式下的sp出了问题,切换到其他模式下就可以找回。
lr是用来存储每种模式下的返回地址,比如从User模式切换到FIQ模式,切换之前,先将User模式的地址存进去,之后在其他模式下工作完返回时,可以直接跳转。
有个问题,跳转时是放在跳转前模式寄存器下,还是跳转后模式寄存器下呢?
sp是保存当前用户的堆栈信息,不用动;
lr是保存返回地址,这个比较关键,跳转时,需要保存到待进入模式的lr,这样就能返回了;
pc是实时的,永远指向最新的程序读取处,不用管;
cpsr要保存到待进入模式的spsr中。
综上所述,只需要保存lr和cpsr到待进入模式中即可。即,根据地址返回,并返还恢复所有原状态。
CPSR程序状态寄存器:
bit0~bit4是模式位(就是上面说的7种模式),模式位不要乱写。
J位控制java加速的,Q位知识饱和状态,这两个了解即可。
条件位(重要):
N,负结果(negative)
Z,结果为0(zero)
C,有进位(carry)
V,进位有溢出(oVerflow)
这几个bit位是自动的。很重要,但是我们在编程时不会直接使用。这几个标志位常用作判断条件,是程序自动实现的。


ARM异常处理
什么是异常?
正常工作之外的流程都叫异常,异常会打断正在执行的工作,并且一般我们希望异常处理完成后继续回来执行原来的工作,中断是异常的一种。
异常向量表:
所有的CPU都有异常向量表,这是CPU设计时就设定好的,是硬件决定的。 当异常发生时,CPU会自动动作(PC跳转到异常向量处处理异常,有时伴有一些辅助动作) 异常向量表是硬件向软件提供的处理异常的支持。
异常向量表其实就是内存的一种规划,比如说软件中断的异常就会跳转到software interrupt开始执行。通常,向量表里存的是实际异常处理程序的指针。有时,会有二级向量表,比如先跳到中断,再跳到中断里的具体哪一种中断。
ARM的异常处理机制:
当异常产生时, ARM core:
拷贝 CPSR 到 SPSR_
设置适当的 CPSR 位:
改变处理器状态进入ARM态(ARM状态才能进行异常处理)
改变处理器模式进入相应的异常模式
设置中断禁止位禁止相应中断 (如果需要)
保存返回地址到 LR_
设置 PC 为相应的异常向量
返回时, 异常处理需要:
从 SPSR_
恢复CPSR 从LR_
恢复PC 上述这些操作只能在ARM态执行。
补充:
c语言中地址+1表示下一个元素地址,比如数组中首地址+1就会跳到第二个元素的地址,默认以1*sizeof(元素)为步进。
裸机中的地址加减是表示什么呢?就是实地址加减,1就代表一个字节。
