存储性能软件加速库(SPDK)
存储性能软件加速库SPDK
- 存储加速
- 存储性能软件加速库(SPDK)
-
- SPDK NVMe驱动
-
- 1.用户态驱动
-
- 1)UIO
- 2)VFIO
-
- IOMMU(I/O Memory Management Unit)
- 3)用户态DMA
- 4)大页(Hugepage)
- 2.SPDK用户态驱动
-
- 1)异步轮询方式
- 2)无锁化
- 3)专门为Flash来优化
- 3.SPDK NVMe驱动性能
- 4.SPDK NVMe驱动新特性
- 5.SPDK用户态驱动多进程的支持
-
- 1)共享内存
- 2)共享NVMe SSD
- 3)管理软件完成队列
- 4)NVMe SSD共享管理流程
存储加速
一般从应用的角度来讲,一个存储任务或需求的完成,可以理解为用户从软件(客户端)发出一个存储需求(包括读和写),然后从存储设备返回用户的软件的过程。
存储服务到存储设备的整个I/O栈包括软件自身的I/O逻辑、网络的I/O逻辑、存储驱动的I/O逻辑,在其中可以找到很多可以优化的点。例如,在内存中,可以利用CPU的特殊指令对一些存储保护算法进行优化;在所经过的网络上,可以把数据传输的任务从CPU中卸载,交由具备RDMA功能的网卡或智能网卡来**进行远程DMA**;在操作系统到实际存储设备落盘的过程中,可以通过用户态的I/O栈来旁路(Bypass)操作系统内部的大部分I/O栈进行加速。
从目前来讲,无论在存储I/O处理的哪个阶段采用加速技术,都不能缺少软件的参与(可以是主机的软件,也可以是firmware中的软件),所以简单依照软件和硬件来划分存储技术的加速方案并没有多少价值。这里我们把存储的加速方案分为以下两类。
- 基于CPU处理器的加速和优化方案。
- 基于协处理器或其他硬件的加速方案。
基于英特尔IA平台的两个对CPU加速的软件库:智能存储加速库(Intelligent StorageAcceleration Library,ISA-L)和存储性能软件的加速库(SPDK)。本章会着重介绍存储性能软件的加速库(SPDK)。
存储性能软件加速库(SPDK)
SPDK每年发布4个版本,用于加速NVMe SSD作为后端存储使用的应用软件加速库,这个软件库的核心是用户态、异步、轮询方式的NVMe驱动,把**内核驱动放到用户态**,导致需要在用户态实施一套基于用户态软件驱动的完整I/O栈。文件系统毫无疑问是其中一个重要的话题,显而易见内核的文件系统,如ext4、Btrfs等都不能直接使用了。虽然目前SPDK提供了非常简单的文件系统blobfs/blostore,但是并不支持可移植操作系统接口,为此使用文件系统的应用需要将其直接迁移到SPDK的用户态“文件系统”上,同时需要做一些代码移植的工作,如不使用可移植操作系统接口,而采用类似AIO的异步读/写方式.
目前SPDK使用比较好的场景有以下几种
- 提供块设备接口的后端存储应用,如iSCSI Target、NVMe-oF Target。
- 对虚拟机中I/O的加速
- SPDK加速数据库存储引擎
SPDK NVMe驱动
在NVMe之前,相对来说一个存在时间更长的接口标准是串行ATA高级 主 机 控 制 器 接 口 ( Serial ATA Advanced Host Controller Interface ,AHCI)。AHCI是在英特尔领导下由多家公司联合研发的接口标准,它允许存储驱动程序启用高级串行ATA功能。相对于传统的IDE技术,AHCI对传统硬盘性能提高带来了改善。但是随着新介质、新技术的发展,AHCI对Flash SSD来说逐渐成为性能瓶颈,这个时候NVMe应运而生。
性能的影响主要在于固态硬盘(包括firmware)和软件的开销。从持续满足上层应用的高性能的角度看,有两种途径:一是开发更高性能的固态硬盘硬件设备;二是减少软件的开销。
基于最新3D XPoint技术的Intel Optane NVMe SSD设备可以在延迟和吞吐量方面使得性能更上一层楼。**软件的开销是NVMe SSD的性能瓶颈**
SPDK的核心组件之一就是用户态NVMe驱动
1.用户态驱动
应用程序是怎么和内核驱动进行交互的?
当内核驱动模块在内核加载成功后,会被标识是块设备还是字符设备,同时定义相关的访问接口,包括管理接口、数据接口等。这些接口直接或间接和文件系统子系统结合,提供给用户态的程序,通过**系统调用的方式**发起控制和读/写操作。
用户态应用程序和内核驱动的交互离不开用户态和内核态的上下文切换,以及系统调用的开销。
用户态驱动出现的目的就是减少软件本身的开销,包括这里所说的上下文切换、系统调用等。
在用户态,目前可以通过UIO(Userspace I/O)或VFIO(Virtual Function I/O)两种方式对硬件固态硬盘设备进行访问。
1)UIO
要在用户态实现设备驱动,主要需要解决以下两个问题。
- ·
如何访问设备的内存:Linux通过映射物理设备的内存到用户态来提供访问,但是这种方法会引入安全性和可靠性的问题。UIO通过限制不相关的物理设备的映射改善了这个问题。由此基于UIO开发的用户态驱动不需要关心与内存映射相关的安全性和可靠性的问题。 如何处理设备产生的中断:中断本身需要在内核处理,因此针对这个限制,还需要一个小的内核模块通过最基本的中断服务程序来处理。这个中断服务程序可以只是向操作系统确认中断,或者关闭中断等最基础的操作,剩下的具体操作可以在用户态处理。
UIO架构如图所示

用户态驱动和UIO内核模块通过/dev/uioX设备来实现基本交互,同时通过sysfs来得到相关的设备、内存映射、内核驱动等信息。
2)VFIO
VFIO不仅提供了UIO所能提供的两个最基础的功能,更多的是从安全角度考虑
把设备I/O、中断、DMA暴露到用户空间,从而可以在用户空间完成设备驱动的框架。这里的一个难点是如何将DMA以安全可控的方式暴露到用户空间,防止设备通过写内存的任意页来发动DMA攻击。
IOMMU(I/O Memory Management Unit)

IOMMU(I/O Memory Management Unit)的引入对设备进行了限制,设备I/O地址需要经过IOMMU重映射为内存物理地址(见图)。那么恶意的或存在错误的设备就不能读/写没有被明确映射过的内存。操作系统以互斥的方式管理MMU和IOMMU,这样物理设备将不能绕过或污染可配置的内存管理表项。
3)用户态DMA
虚线代表设备通过DMA直接访问相应的内存页,实线代表CPU访问内存页的方式
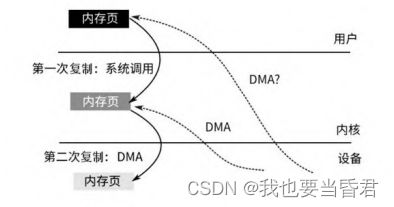
基于UIO和VFIO,我们可以实现用户态的驱动,把一个硬件设备分配给一个进程,允许该进程来操作和读/写该设备。这在一定程度上提高了进程对设备的访问效率,不需要通过内核驱动来产生额外的内存复制,而是可以直接从用户态发起对设备的DMA
是这里需要考虑以下3个问题:
- 提供设备可以认知的内存地址(可以是物理地址,也可以是虚拟地址)。
物理内存必须在位(考虑到虚拟内存可能被操作系统交换出去,产生缺页)。- CPU对内存的更新必须对设备可见。
第1个和第3个问题得益于英特尔平台的技术演进,通过设备直接支持IOMMU,同时和CPU之间实现缓存一致性(Cache-Coherent)来解决。
从用户态进程来看,怎么保证在DMA的过程中物理内存是在位的?
现在Linux主流被认可的方法是人工把虚拟地址对应的物理内存Pin在位置上(意思是不会被换出)。这样,无论你用的是物理地址还是虚拟地址,只要完成了Pin的操作,这个地址就可以用于DMA。
4)大页(Hugepage)
虚拟地址映射到物理地址的工作主要是TLB(Translation Lookaside Buffers)与MMU一起来完成的。以4KB的页大小为例,虚拟地址寻址时,首先在TLB中查找,如果没有找到,则需要通过MMU加载的页表基地址进行多次寻表来找到对应的物理地址。如果找不到,则产生缺页,这时会有相应的handler进行处理,来填充页表和更新TLB。通过页表查询而导致缺页带来的CPU开销是非常大的,TLB的出现能很好地解决性能问题。但是经常性的缺页是不可避免的,为此我们可以采取大页的方式。因为页大小的增加,可以减少缺页异常。TLB同样的空间可以保存更多虚存空间到物理空间的映射。尽可能地利用TLB,少用MMU,以减少寻址和缺页处理带来的开销,从而提高应用程序的整体性能。
大页还有一个优势是这些预先分配的内存基本上不会被换出,当进行DMA的时候,所对应的虚拟地址永远有相对应的物理页。
2.SPDK用户态驱动
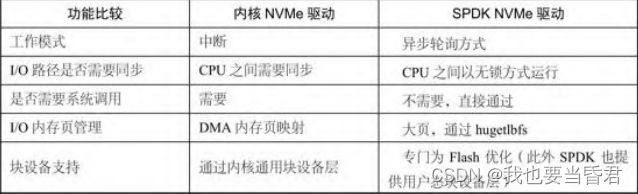
1)异步轮询方式
UIO和VFIO需要在内核实现最基本的中断功能来响应设备的中断请求。而SPDK更进一步,这些中断请求不需要通知到用户态来处理,在UIO和VFIO内核模块做最简化的处理就可以了。
这种处理方式的原因
- 把内核态的中断抛到用户态进程来处理对大部分硬件是不合适的
- 中断会引入软件处理的不确定性,同时不能避免上下文的切换
SPDK用户态驱动的操作基本上都是采用了异步轮询的方式,轮询到操作完成时会触发上层的回调函数,这样使得应用程序无须等待读或写操作的完成,就可以按需发送多个请求,再由回调函数处理。由此来提高应用的读/写性能。这样的方式从性能上来说是有很大帮助的,但是要发挥出这个特点,需要应用做出相应的修改来匹配优化的异步轮询操作。
2)无锁化
主要考虑以下问题
- 读/写处理要在一个CPU核上完成,避免核间的缓存同步。
- 单核上的处理,对资源的分配是无锁化的。
针对第一个问题,可以通过线程亲和性的方法,来将某个处理线程绑定到某个特定的核上,同时通过轮询的方式占住该核的使用,避免操作系统调度其他的线程到该核上面。当应用程序接收到这个核上的读/写请求的时候,采用运行直到完成(Run To Completion)的方式,把这个读/写请求的整个生命周期都绑定在这个核上来完成。
这其中涉及第二个问题,在处理该核上的读/写请求时,需要分配相关的资源,如Buffer。这些Buffer主要通过大页分配而来。DPDK为SPDK提供了基础的内存管理,单核上的资源依赖于DPDK的内存管理,不仅提供了核上的专门资源,还提供了高效访问全局资源的数据结构,如mempool、无锁队列、环等。
3)专门为Flash来优化
内核驱动的设计以通用性为主,考虑了不同的硬件设备实现一个通用的块设备驱动的问题。这样的设计有很好的兼容性和维护性,但是单从性能角度看,不一定能发挥出特定性能的优势。
SPDK作为用户态驱动,就是专门针对高速NVMe SSD设备的。为了能让上层应用程序充分利用硬件设备的高性能(高带宽、低延时),SPDK实现了一组C代码开发库,这些开发库的接口可以直接和应用程序结合起来。
通过UIO或VFIO把PCI设备的BAR(Base Address Register)地址映射到应用进程的空间,这样SPDK用户态驱动就可以遵循NVMe的规范来初始化NVMe SSD,创建出最基本的I/O发送和完成队列,最终实现对NVMe SSD设备的I/O读或写操作。
3.SPDK NVMe驱动性能
SPDK用户态驱动是专门为NVMe SSD优化的,尤其是对高速NVMe SSD,比如基于3D XPoint的Intel Optane设备,能够在单CPU核上管理多个NVMe SSD设备,实现高吞吐量、低延时、多设备、高效CPU使用的特点
4.SPDK NVMe驱动新特性
- Reservations:可以很好地支持双控制器的NVMe SSD(如Intel D3700),在需要高可靠性的场景下,达到控制器的备份冗余
· Scatter Gather List(SGL):可以更灵活地分配内存,减少I/O操作,提供高效的读/写操作
· Multiple Namespace:可以暴露给上层应用多个逻辑空间,做到在同一物理设备上的共享和隔离。
· In Controller Memory Buffer(CMB):可以把I/O的发送和完成队列放到固态硬盘设备上,同时相应的Buffer也从固态硬盘设备上来分配,一方面可以减少延时,另一方面使得两个NVMe SSD设备间的DMA成为可能。
5.SPDK用户态驱动多进程的支持
前面提到SPDK用户态驱动会暴露对应的API给应用程序来控制和操作硬件设备。此时内核NVMe驱动已经不会对设备做任何的操作,所以类似于/dev/nvme0和/dev/nvme0n1的设备不会存在。这样带来一个问题,如果多个应用程序都需要访问同一个硬件设备的话,那么SPDK用户态驱动该如何来支持。
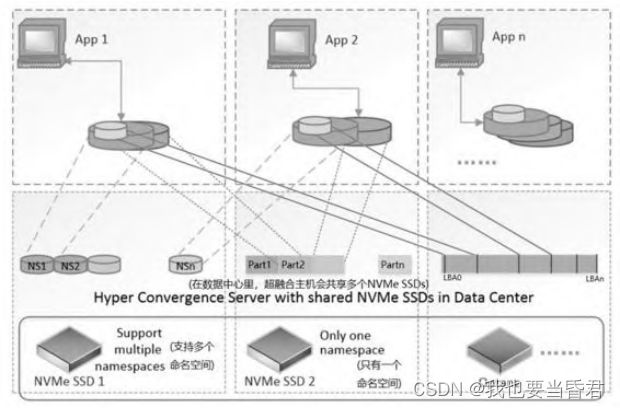
这 里 NVMe SSD 可 以 通 过 不 同 的 Namespace , 或 者 在 同 一 个Namespace中划分出不同的空间分配给不同的应用程序来进行数据存储**。Optane作为性能极高的设备**,可以划分不同的空间给不同的应用作为数据缓存。基于DPDK共享设备的底层支持,SPDK用户态驱动也解决了应用之间共享同一个硬件设备的问题。
1)共享内存

在初始化这些共享资源之前,我们给相关的进程做了区分,可以显示指定某个进程为主进程(Master Process),或者系统自动判断第一个进程为主进程。当主进程启动的时候,把相关的资源分配好,同时初始化完成需要共享的资源。当配置副进程(Slave Process)的应用启动时,无须再去分配内存资源,只需要通过共同的标识符来匹配主进程,把相关的内存资源配置到副进程上即可
2)共享NVMe SSD
SPDK在单CPU核的情况下,可以很容易地具备低延时、高带宽的特性,这些性能指标只需要依赖少数甚至单个I/O队列就可以达到。因此这里的I/O队列是需要让某个进程从逻辑上单独使用的,即便整个NVMe SSD是对多个进程共享可见的。SPDK的用户态驱动对单独I/O队列是无锁化处理的,因此从性能考虑,只需要应用程序分配自己的I/O队列就可以达到较高的性能。
由于NVMe SSD本身只有一个管理队列,因此当多个应用程序需要对设备发起相应的管理操作时,这个管理队列需要通过互斥的机制来保证操作的顺序性。相对来说,在控制通道上引入互斥机制对每个进程影响不会很大。
3)管理软件完成队列
NVMe SSD只有一个管理队列,对应一个发送队列和一个完成队列列。这个管理队列是共享给所有进程的,比如每个进程都需要通过这个管理队列来创建逻辑上独享的I/O队列。这里除了通过互斥的机制来串行多个进程的需求,还需要记录请求操作和进程的对应关系,这样才能避免出现一种场景:进程A发送的创建I/O队列的请求由进程B来处理回调函数。

由此SPDK引入了针对每个进程的单独数据结构,来记录每个进程独享的资源,比如这里需要的软件模拟的完成队列。多个软件模拟的完成队列都对应到同一个管理完成队列(Admin Completion Queue)。为了区分哪一个操作属于哪一个进程,这里通过PID(Process Identifier)来标识每个进程。当任何一个进程去异步轮询管理队列时,会把所有硬件设备完成的操作取回来,同时根据请求的PID标志,将这些请求插入到对应进程的软件完成队列。之后该进程会处理对应的软件完成队列来回调用户的操作
4)NVMe SSD共享管理流程
在多进程情况下,主进程和副进程需要做些什么工作来实现多个应用对同一个设备的共享?

SPDK用户态驱动提供了对多进程访问的支持后,有几个典型的使用场景。
- 主进程完成对设备的管理和读/写操作,副进程来监控设备,读取设备使用信息。
- 主进程只负责资源的初始化和设备的初始化工作,多个副进程来操作设备,区分设备的管理通道和数据通道。
- 当主进程和副进程不进行区分时,都会对设备进行管理和读/写操作
推荐一个零声学院免费公开课程,个人觉得老师讲得不错,分享给大家:Linux,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK等技术内容,立即学习