WebServer项目代码逻辑分析
文章目录
- 项目介绍
- 一、服务器编程基本框架
- 一、WebServer类详解
-
- 1.初始化
- 2.启动WebServer
- 二、I/O处理的具体流程
- 三、线程池
- 四、HTTP请求报文解析与响应报文生成
-
- 1.请求报文
- 2.响应报文
- 3.process()函数
- 五、缓冲区
- 六、定时器
-
- 1.定时器的组成
- 2.定时器的管理
- 七、数据库连接池
- 八、压力测试
- 总结
项目介绍
该项目
Linux下C++轻量级Web服务器,使用线程池+非阻塞socket+epoll(ET模式)+事件处理(Reactor)的并发模型
使用状态机解析HTTP报文请求,支持解析GET、POST请求
访问服务器数据库实现客户端用户注册、登录功能,可以请求服务器图片、视频文件;
经Webbench压力测试可以实现上万的并发连接。
一、服务器编程基本框架

| 模块 | 功能 |
|---|---|
| I/O处理单元 | 处理客户连接,读写网络数据 |
| 逻辑单元 | 业务进程或线程 |
| 网络存储 | 数据库、文件或缓存 |
| 请求队列 | 各单元之间的通信方式 |
提示:以下是本篇文章正文内容,下面案例可供参考
一、WebServer类详解
WebServer类基于http类、pool类、epoll类、timer类、buffer类实现了一个高性能Web服务器,其实现了以下功能:
- 初始化服务器;
- 处理每一个http请求,包括连接和读写;
- 为每一个http请求设置定时器;
- 采用epoll技术实现IO多路复用;
- 采用线程池技术提高服务器性能。
1.初始化
InitSocket_();//初始化Socket连接
InitEventMode_(trigMode);//初始化事件模式
SqlConnPool::Instance()->Init();//初始化数据库连接池
初始化Socket连接函数InitSocket_();这里插入一句,C/S建立连接就是socket-bind-listen-accept-发送接收数据这几步,而InitSocket_();函数实现了socket-bind-listen这几步,然后把前边得到(就是socket环节)的Listenfd 添加到epoll模型上,即把accept()和接受数据的操作交给epoll进行处理了,至于怎么处理就是后话了。并且把该文件描述符设置为非阻塞。
初始化事件模式函数InitEventMode_(trigMode);这里我们选择将listenEvent_和connEvent_都设置为EPOLLET模式;
初始化数据库连接池,就是为用户的注册登录做准备的。
2.启动WebServer
//为说明逻辑删除部分代码
timeMS = timer_->GetNextTick();
int eventCnt = epoller_->Wait(timeMS);
for(int i = 0; i < eventCnt; i++) {
/* 处理事件 */
int fd = epoller_->GetEventFd(i);
uint32_t events = epoller_->GetEvents(i);
if(fd == listenFd_) {
DealListen_();//处理监听的操作,接受客户端连接
}
else if(events & EPOLLIN) {
DealRead_(&users_[fd]); //处理读操作
}
else if(events & EPOLLOUT) {
DealWrite_(&users_[fd]); //处理写操作
}
接下来启动WebServer,首先需要设定epoll_wait()等待的时间,这里我们选择调用定时器的GetNextTick()函数,这个函数的作用是返回最小堆堆顶的连接设定的过期时间与现在时间的差值。这个时间的选择可以保证服务器等待事件的时间不至于太短也不至于太长。接着调用epoll_wait()函数,返回需要已经就绪事件的数目。这里的就绪事件分为两类:收到新的http请求和其他的读写事件。
这里设置两个变量fd和events分别用来存储就绪事件的文件描述符和事件类型。
1.收到新的HTTP请求的情况
在fd==listenFd_的时候,也就是收到新的HTTP请求的时候,调用函数DealListen_();处理监听,接受客户端连接;
2.已经建立连接的HTTP发来IO请求的情况
在events& EPOLLIN 或events & EPOLLOUT为真时,需要进行读写的处理。分别调用 DealRead_(&users_[fd])和DealWrite_(&users_[fd]) 函数。这里需要说明:DealListen_()函数并没有调用线程池中的线程,而DealRead_(&users_[fd])和DealWrite_(&users_[fd]) 则都交由线程池中的线程进行处理了。
如果是其他情况则不进行处理,断开连接。
二、I/O处理的具体流程
DealRead_(&users_[fd])和DealWrite_(&users_[fd]) 通过调用
threadpool_->AddTask(std::bind(&WebServer::OnRead_, this, client));//读
threadpool_->AddTask(std::bind(&WebServer::OnWrite_, this, client));//写
函数来取出线程池中的线程继续进行读写,而主进程这时可以继续监听新来的就绪事件了。
OnRead_()和OnWrite_()函数分别进行读写的处理。
OnRead_()函数首先把数据从缓冲区中读出来,然后交由逻辑函数OnProcess()处理。这里多说一句,process()函数在解析请求报文后随即就生成了响应报文等待OnWrite_()函数发送。
这里必须说清楚OnRead_()和OnWrite_()函数进行读写的方法,那就是:
分散读和集中写。
分散读(scatter read)和集中写(gatherwrite)具体来说是来自读操作的输入数据被分散到多个应用缓冲区中,而来自应用缓冲区的输出数据则被集中提供给单个写操作。
这样做的好处是:它们只需一次系统调用就可以实现在文件和进程的多个缓冲区之间传送数据,免除了多次系统调用或复制数据的开销。
具体代码放在后续的博文中说吧,写了这么久真的有点顶不住了。
OnWrite_()函数首先把之前根据请求报文生成的响应报文从缓冲区交给fd,传输完成后交由OnProcess()处理。
为什么都要OnProcess()处理呢?
具体见下面的代码,OnProcess()会把fd重新置为EPOLLOUT(写)或EPOLLIN(读)以便再次处理。
OnProcess()就是进行业务逻辑处理(解析请求报文、生成响应报文)的函数了。具体细节就放在第四部分HTTP请求报文解析与响应报文生成说了。
void WebServer::OnProcess(HttpConn* client) {
//首先调用process()进行逻辑处理
if(client->process()) {//然后,根据返回的信息重新将fd置为EPOLLOUT(写)或EPOLLIN(读)
epoller_->ModFd(client->GetFd(), connEvent_ | EPOLLOUT);
} else {
epoller_->ModFd(client->GetFd(), connEvent_ | EPOLLIN);
}
}
三、线程池
为了实现系统的并发,提高了CPU的工作效率。线程池内有多个线程,当提交一项任务后,从线程池内取出一个线程进行处理,可以实现不阻塞主线程的情况下完成这项工作。

线程池采用了生产者消费者模式,其中生产者是主线程,负责产生新的工作任务,而线程池中的线程是消费者,负责处理这些任务。大致过程就是主线程将需要处理的任务放入线程池中,线程池中的线程取出任务进行处理,自然线程池就是临界区。这里我们采用互斥量和条件变量来保护线程池。
我们需要创建一个线程池结构体,包括互斥量和条件变量,并维护一个任务队列。
struct Pool {
std::mutex mtx;//互斥量
std::condition_variable cond;//条件变量
bool isClosed; //线程池是否关闭
std::queue<std::function<void()>> tasks;//任务队列
};
生产者向线程池中放入任务的函数是AddTask() ,向工作队列中加入一个任务就用条件变量notify_one();函数唤醒一个线程进行处理。
void AddTask(F&& task) {//添加任务就唤醒一个线程来消费工作任务task
{
std::lock_guard<std::mutex> locker(pool_->mtx);
pool_->tasks.emplace(std::forward<F>(task));//将任务加入队列
}
pool_->cond.notify_one();//唤醒一个线程
}
线程池工作函数的流程如下:
for(size_t i = 0; i < threadCount; i++) {
std::thread([pool = pool_] {
//获得线程池的锁
std::unique_lock<std::mutex> locker(pool->mtx);
while(true) {
if(!pool->tasks.empty()) {
//从任务队列中取出一个任务
auto task = std::move(pool->tasks.front());
//移除掉已取出的这一任务
pool->tasks.pop();
//对线程池解锁以让任务完成
locker.unlock();
//处理任务,
task();
//重新上锁
locker.lock();
}
else if(pool->isClosed) break;
else pool->cond.wait(locker); //线程池为空就等待
}
}).detach();
四、HTTP请求报文解析与响应报文生成
前边已经讲了读数据,下边就要对读取的数据进行分析了。
1.请求报文
http请求报文的结构如下:
包括请求行,请求头部,空行和请求数据四个部分。

我复制了自己浏览器访问www.baidu.com时的请求包,结构如下
GET / HTTP/1.1
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
Connection: keep-alive
Host: www.baidu.com
Sec-Fetch-Dest: document
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: none
Sec-Fetch-User: ?1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.41 Safari/537.36 Edg/101.0.1210.32
sec-ch-ua: " Not A;Brand";v=“99”, “Chromium”;v=“101”, “Microsoft Edge”;v=“101”
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: “Windows”
上边只包括请求行和请求头,请求数据为空。可以看到请求方法是GET,协议版本是 HTTP/1.1。请求头是键值对形式。
解析请求报文用有限自动状态机实现:
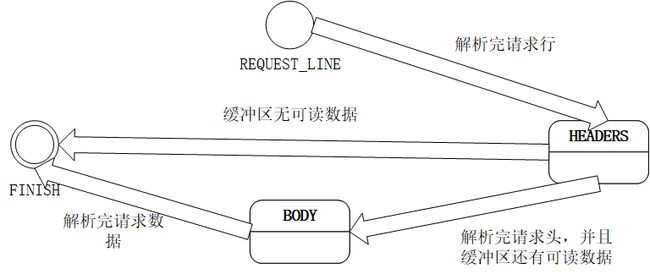
解析过程由parse()函数完成;函数根据状态分别调用了
ParseRequestLine_();//解析请求行
ParseHeader_();//解析请求头
ParseBody_();//解析请求体
三个函数对请求行、请求头和数据体进行解析。当然解析请求体的函数还会调用ParsePost_(),因为Post请求会携带请求体。
2.响应报文
响应报文需要有响应行、响应头、响应体。这一过程由MakeResponse()函数完成。
首先对解析到的请求报文进行判断,确定响应状态码。之后根据状态码返回出错页面或者是对应的资源页面。
AddStateLine_();//生成响应体
AddHeader_();//生成响应头
AddContent_();//生成响应体
在添加响应头时,需要得到文件类型信息,这部分由GetFileType_()函数实现;
在添加响应体时,如果所请求的文件打不开,需要返回相应的错误信息,这个功能由函数ErrorContent()实现。
3.process()函数
上边说的解析请求报文和生成响应报文都是在process()函数内完成的。并且是在解析请求报文后随即生成了响应报文。之后这个生成的响应报文便放在缓冲区等待writev()函数将其发送给fd。
//只为了说明逻辑,代码有删减
bool HttpConn::process() {
request_.Init();//初始化解析类
if(readBuff_.ReadableBytes() <= 0) {//从缓冲区中读数据
return false;
}
else if(request_.parse(readBuff_)) {//解析数据,根据解析结果进行响应类的初始化
response_.Init(srcDir, request_.path(), request_.IsKeepAlive(), 200);
} else {
response_.Init(srcDir, request_.path(), false, 400);
}
response_.MakeResponse(writeBuff_);//生成响应报文放入writeBuff_中
/* 响应头 iov记录了需要把数据从缓冲区发送出去的相关信息
iov_base为缓冲区首地址,iov_len为缓冲区长度 */
iov_[0].iov_base = const_cast<char*>(writeBuff_.Peek());
iov_[0].iov_len = writeBuff_.ReadableBytes();
iovCnt_ = 1;
/* 文件 */
if(response_.FileLen() > 0 && response_.File()) { //
iov_[1].iov_base = response_.File();
iov_[1].iov_len = response_.FileLen();
iovCnt_ = 2;
}
return true;
}
五、缓冲区
在WebServer中,客户端连接发来的HTTP请求以及回复给客户端所请求的响应报文,都需要通过缓冲区来进行。我们以vector容器作为底层实体,在它的上面封装自己所需要的方法来实现一个自己的buffer缓冲区,满足读写的需要。
buffer缓冲区的组成
省去每一个类必有的构造和析构函数,还需要以下部分:
buffer的存储实体
缓冲区的最主要需要是读写数据的存储,也就是需要一个存储的实体。自己去写太繁琐了,直接用vector来完成。也就是buffer缓冲区里面需要一个:
std::vector<char>buffer_;
buffer所需要的变量
由于buffer缓冲区既要作为读缓冲区,也要作为写缓冲区,所以我们既需要指示当前读到哪里了,也需要指示当前写到哪里了。所以在buffer缓冲区里面设置变量:
std::atomic<std::size_t>readPos_;
std::atomic<std::size_t>writePos_;
分别指示当前读写位置的下标。
buffer所需要的方法
读写接口
缓冲区最重要的就是读写接口,主要可以分为与客户端直接IO交互所需要的读写接口,以及收到客户端HTTP请求后,我们在处理过程中需要对缓冲区的读写接口。
与客户端直接IO的读写接口
ssize_t ReadFd();
ssize_t WriteFd();
这个功能直接用read()/write()、readv()/writev()函数来实现。从某个连接接受数据的时候,有可能会超过vector的容量,所以我们用readv()来分散接受来的数据。
根据后续功能的需要,写了各种需要的实现。这里暂时不再展开了。
六、定时器
WebServer希望可以满足同时接受大量的连接请求并进行处理,不过实际场景中往往会出现大量连接建立后却不进行读写请求的情况,这样造成了连接闲置,导致服务器无效资源的耗费。因此定时器是十分需要的。定时器为每一个http连接设置一个过期时间并定期清理过时连接,可以提高服务器的运行效率。
这里选择采用小顶堆这一数据结构实现定时器功能。小顶堆保证根元素的值为最小的,这里我们将堆的元素值设为每个连接的过期时刻。也就是说,最早过期的连接为堆顶元素。
1.定时器的组成
定时器结点
为了实现定时器的功能,我们将每个http连接的文件描述符fd来标记这个连接,记为id。同时,我们还需要设置每一个HTTP连接的过期时间。
这里需要说明:这个文件描述符是调用accept()以后得到的,与最开始的监听文件描述符不是同一个。
关键代码:
int fd = accept(listenFd_, (struct sockaddr *)&addr, &len);
AddClient_(fd, addr);
timer_->add(fd, timeoutMS_, std::bind(&WebServer::CloseConn_, this, &users_[fd]));
为了后面处理过期连接的方便,我们给每一个定时器里面放置一个回调函数,用来关闭过期连接。
为了便于定时器结点的比较,主要是后续堆结构的实现方便,我们还需要重载比较运算符。
struct TimerNode{
public:
int id; //用来标记定时器
TimeStamp expire; //设置过期时间
TimeoutCallBack cb; //设置一个回调函数用来方便删除定时器时将对应的HTTP连接关闭
bool operator<(const TimerNode& t)
{
return expire<t.expire;
}
};
2.定时器的管理
主要有对堆节点进行增删和调整的操作。
void addTimer(int id,int timeout,const TimeoutCallBack& cb);//添加一个定时器
void del_(size_t i);//删除指定定时器
void siftup_(size_t i);//向上调整
bool siftdown_(size_t index,size_t n);//向下调整
void swapNode_(size_t i,size_t j);//交换两个结点位置
值得一提的是,当某个连接有新请求到达时,我们就需要更新它的过期时间。
七、数据库连接池
数据库连接池通过单例模式,保证只生成一个连接池。
八、压力测试
压力测试采用webbench,是一款轻量级的网址压力测试工具,可以实现高达3万的并发测试。
Webbench实现的核心原理是:父进程fork若干个子进程,每个子进程在用户要求时间或默认的时间内对目标web循环发出实际访问请求,父子进程通过管道进行通信,子进程通过管道写端向父进程传递在若干次请求访问完毕后记录到的总信息,父进程通过管道读端读取子进程发来的相关信息,子进程在时间到后结束,父进程在所有子进程退出后统计并给用户显示最后的测试结果,然后退出。
#需要把ip和port替换为需要进行测试的WebServer
./webbench-1.5/webbench -c 100 -t 10 http://ip:port/
./webbench-1.5/webbench -c 1000 -t 10 http://ip:port/
./webbench-1.5/webbench -c 5000 -t 10 http://ip:port/
./webbench-1.5/webbench -c 10000 -t 10 http://ip:port/
webbench 参数介绍:
-c表示并发数
-t表示运行测试URL的时间(秒)
总结
WebServer这个项目涉及的知识点还是很多的,要耐心分析学习。
写着写着发现一个点容易扩展太开,所以这里主要抓住主要逻辑进行总结,太具体的放在之后写,希望自己不会挖坑不填。
项目基于牛客指导校招冲刺集训营-C++里的项目进行分析。
参考链接:
WebServer项目详解
来用C++写一个最最最简单的Tcp服务器吧
Tinywebserver——服务器面试题
【博客159】分散读(readv) 与集中写(writev)