Linux和开源存储
Linux和开源存储
-
- 为什么需要开源存储
- Linux开源存储技术原理和解决方案
- Linux开源存储系统方案介绍
-
- Linux单节点存储方案
- 存储服务的分类
- 数据压缩
- 重复数据删除
- 开源云计算数据存储平台
- 存储管理和软件定义存储
- 开源分布式存储和大数据解决方案
- 开源文档管理系统
- 网络功能虚拟化存储
- 虚拟机/容器存储
- 数据保护
- 三大顶级基金会
经典的存储级别图,如图1-1所示。数据在计算机系统中的存储级别自上而下地划分为4大块:
CPU、CPU缓存、易失内存、非易失内存。

易 失 内 存 主 要 是 指 内 存 , 分 为 SRAM ( Static Random Access
Memory)和DRAM(Dynamic Random Access Memory),主要以双内联
存储器模块(Dual In-line Memory Module,DIMM)接口为主。当然目前
也有支持双内联存储器模块接口的非易失内存,如英特尔的Apache
Pass(AEP)。
非易失内存种类繁多,可以基于PCIe、SATA(Serial Advanced
Technology Attachment ) 、 SAS ( Serial Attached SCSI ) 、
AHCI(Advanced Host Controller Interface)等各种协议。根据介质和工作
原理,非易失内存可以分为机械硬盘(Harddisk)、固态硬盘(Sdid State
Drive,SSD)及磁带(Tape)。其中,固态硬盘根据颗粒和介质可以分
为NAND和3D XPoint等。
为什么需要开源存储
- 1.基于商用/闭源存储软件的时代
1)存储设备的发展
2)存储的整体需求不高
3)开发存储产品的高门槛
评估一个存储系统,一般有以下指标。
性能指标,可靠性标准,功能性标准,能耗标准; - 2.风向的转变
从商用/闭源存储系统到开源的存储系统,其中的原因,主要有以下几点。
1)商用存储软件功能的局限性
2)商用存储系统的价格昂贵
3)开源生态圈的蓬勃发展
4)互联网企业的身体力行
Linux开源存储技术原理和解决方案
Linux的开源存储软件,需要满足如下要求。
1)软件集成在Linux发行版本中
2)软件有活跃的社区
3)软件的特性满足应用的需求
Linux开源存储系统方案介绍
Linux单节点存储方案
- 1.Linux本地文件系统

对于Linux操作系统中基于内核文件系统的支持,其实可以分为两大块:
一是内核中虚拟文件系统、具体文件系统、内核通用块设备及各个I/O子系统的支持;
二是Linux用户态与文件系统相关的管理系统,以及应用程序可以用的系统调用或库文件(Glibc)的支持。
在用户态也有一些用户态文件系统的实现,但是一般这样的系统性能不是太高,因为文件系统最终是建立在实际的物理存储设备上的,且这些物理设备的驱动是在内核态实现的。那么即使文件系统放在用户态,I/O的读和写也还是需要放到内核态去完成的。除非相应的设备驱动也被放到用户态,形成一套完整的用户态I/O栈的解决方案,就可以降低I/O栈的深度,另外采用一些无锁化的并行机制,就可以提高I/O的性能。例如,由英特尔开源的SPDK(Storage Performance DevelopmentKit)软件库,就可以利用用户态的NVMe SSD(Non-Volatile Memoryexpress)驱动,从而加速那些使用NVMe SSD的应用,如iSCSI Target或NVMe-oF Target等。
- 2.Linux远程存储服务
1)块设备服务
Linux常用的块设备服务主要基于iSCSI(Internet Small Computer System Interface)和NVMe over Fabrics。
iSCSI协议是SCSI(Small Computer System Interface)协议在以太网上的扩展,通过iSCSI协议被访问的设备称为Target,而访问Target的客户(Client)端称为Initiator
NVMe over Fabrics则是NVMe协议在Fabrics上的延伸,主要的设计目的是让客户端能够更高效地访问远端的服务器上的NVMe盘。相对iSCSI协议,NVMe over Fabrics则完全是为高效访问基于NVMe协议的快速存储设备设计的,往往和带有RDMA(Remote Direct Memory Access)功能的以太网卡,或者光纤通道、Infiniband一起工作
2)文件存储服务
基于网络文件系统(Network File System,NFS)协议的服务,基于CIFS(Common Internet File System)的samba服务,基于文件传输协议(File Transfer Protocol,FTP)的服务
存储服务的分类
-
1)块存储服务
对于块存储服务来说,操作的对象是一块“裸盘”,访问的方式是打开这块“裸盘”,通过逻辑区块地址对其进行读/写操作。在使用上,磁盘通过分区、格式化挂载之后则可以直接使用 -
2)文件存储服务
文件存储服务,即提供以文件为基础、与文件系统相关的服务, -
3)对象存储服务
对象存储更简洁。对象存储采用扁平化的形式管理数据,没有目录的层次结构,并且对象的操作主要以put、get、delete为主。所以在对象存储中,不支持类似read、write的随机读/写操作,一个文件“put”到对象存储之后,在读取时只能“get”整个文件,如果要修改,必须重新“put”一个新的对象到对象存储里。
元数据(Metadata)会被独立出来作为元数据服务器,主要负责存储对象的属性,其他则是负责存储数据的分布式服务器,一般称为OSD(Object Storage Device)。
文件存储与对象存储的本质区别就是有无层次结构
块存储的优点是读/写速度快,缺点是不太适合共享;
文件存储的优点是利于共享,缺点是读/写速度慢。
所以结合它们各自的优点出现了对象存储,对象存储不仅读/写速度快,而且适用于分布式系统中,利于共享
数据压缩
1.数据压缩基础
1)霍夫曼编码
2)算术编码
2.Linux下开源数据压缩软件
1)FreeArc
2)7-Zip
3)Snappy
重复数据删除
重复数据删除一般用于备份系统中(或二级存储)衡量一个应用重复数据删除的备份系统是不是优秀,有以下几个主要特征。
- 数据去重复率
- 吞吐率
- 数据的可靠性
- 备份过程的安全性
1.重复数据删除的分类
重复数据删除根据应用的位置,可分为源端重复数据删除和目标端
重复数据删除两种,其中源端指备份数据的来源;目标端指备份系统。
所谓源端重复数据删除是指在源端判断数据重复的工作
根据数据在备份系统中进行重复数据删除的时间发生点,
分为离线(Post-process)重复数据删除和在线(Inline)重复数据删除两种。
离线重复数据删除,是指在用户数据上传的过程中,数据去重复并不会发生,直接写到存储设备上;当用户数据上传完全结束后,再进行相关的数据去重复工作
所谓在线重复数据删除,就是在用户数据通过网络上传到备份系统的时候,数据去重复就会发生。
2.深入理解重复数据删除
1)数据切片算法
2)高效删除重复数据
3)数据可靠性
3.重复数据删除应用
重复数据删除除了在数据备份系统(主要指Secondary Storage)中的应用,在其他方面也有相应的应用,如主存储(Primary Storage)、文件系统、虚拟化,甚至内存。
4.Linux下开源数据删除软件
OpenDedup针对Linux的重复数据删除文件系统被称为SDFS,主要针对的是那些使用虚拟化环境,且追求低成本、高性能、可扩展的重复数据解决方案的用户
开源云计算数据存储平台

IaaS:虚拟机,可在上面安装操作系统或其他应用程序。典型的代表有Amazon的AWS和阿里云ECS
平台即服务(Platform As a Service,PaaS):可在上面安装其他应用程序,但不能修改已经预装好的操作系统和运行环境
软件即服务(Software As a Service,SaaS):百度云盘、360云盘
存储管理和软件定义存储
1.软件定义存储的发展
2.软件定义存储开源项目介绍
OpenSDS, Libvirt Storage Management, OHSM
开源分布式存储和大数据解决方案
Hadoop,HPCC,GlusterFS,Ceph,Sheepdog
开源文档管理系统
DSpace,Epiware,OpenKM
网络功能虚拟化存储
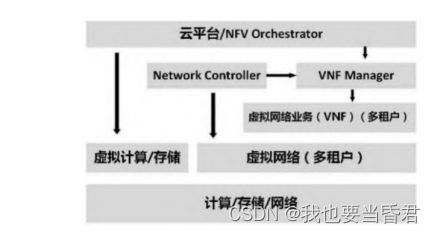
网络功能虚拟化(Network Functions Virtualization,NFV)在维基百科的定义是“使用虚拟化技术,将各个类别的网络节点功能虚拟化为连接在一起的通信服务”。
NFV主要包括3个部分:NFVI(网络功能虚拟化基础设施)、VNF(虚拟网络功能)和MANO(NFV管理与编排)。
NFV在云计算场景中的架构如图
虚拟机/容器存储
1.虚拟机存储
完全虚拟化技术:半虚拟化技术:硬件辅助虚拟化技术
VHost是Host Kernel中的一个模块,它可以与Guest直接进行通信,数据交换都在Guest和VHost模块之间进行,可以减少VMM的干涉,从而减少了上下文切换缩短了I/O路径。目前,由于VHost是Host Kernel中的模块,I/O需要与Host Kernel相互配合,避免不了从用户态到内核态的上下文切换。因此英特尔提出,在用户态中实现VHost,从而使得QEMU与用户态的VHost实现通信,进一步提高I/O性能。
2.容器存储
Data-volume + Volume-Plugin;
Container-define Storage;
STaaC(Storage as a Containter);
Container-aware(容器感知);
数据保护
在虚拟化领域大名鼎鼎的VMware在数据保护方面提供了多种支持,如具有强大功能的VADP(vStorage APIs for DataProtection)接口,其他备份软件只要遵循这个接口,就可以实现数据保护的大多数功能。
分布式存储系统Ceph和GlusterFS都可以通过网关节点来复制快照,从而把数据备份到本地或远程目标上。
三大顶级基金会
是Linux基金会、OpenStack基金会和Apache基金会
推荐一个零声学院免费公开课程,个人觉得老师讲得不错,分享给大家:Linux,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK等技术内容,立即学习