目标检测学习笔记1
文章目录
- 一.前言
-
- 1. 目标检测目的
- 2. 如何定位?
- 3. 目标检测方法
- 4. 一些概念介绍:
- 二、滑动窗口检测
-
- 1.识别流程
- 2.方法缺点
- 三、R-CNN模型
-
- 1.算法流程
- 2.如何选出候选区域?
- 3.如何分类?
- 4.非极大抑制(NMS)
- 5.修正候选区域
- 6.目标检测评估指标
- 7.RCNN缺点
- 四、SPP-Net
-
- 1.为什么要输入固定尺寸?
- 2.算法流程
- 3.SPP-Net优缺点
- 五、Fast-RCNN
-
- 1.算法流程
- 2.改进部分
- 3.模型性能对比
- 六、Faster-RCNN
-
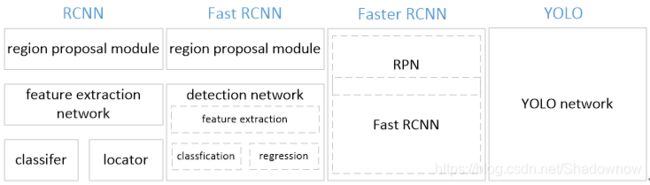
- 1.RCNN三者对比
- 2.网络结构
- 3.算法流程
- 4.区域生成网络(RPN)原理
- 5.Faster-RCNN的训练
- 6.Faster-RCNN效果对比
- 7.Faster-RCNN总结
- 七、Yolo(You Only Look Once)
-
- 1. 网络结构
- 2.单元格(grid cell)
- 3.训练过程
- 4.与Faster-RCNN比较
- 5.YOLO总结
- 八、SSD
-
- 1.网络结构
- 2. 算法流程
- 3. PriorBox 层
- 4. 训练和测试过程
- 5. 总结
一.前言
计算机视觉有四大基本任务,分别是:分类、定位、检测、分割。其中分类任务是所有任务的基础。因为对于一幅图像,可能含有多个物体。所以分类任务是对图像中主体事物类别的判断。定位任务也是单目标任务,和分类任务唯一的不同是,不仅需要分类还需要把判别出的主体事物的边界框出来。目标检测是多目标任务,是对图像中各种需要检测的物体如果出现用边界框框住,并判别其类别。分割任务和检测任务的区别就在于是框的形状是物体的边界形状。
1. 目标检测目的
从图像或视频流中,检测出其中一个或多个物体的类别与其位置 其任务简而言之即:对一个或多个物体分类+定位
| 任务 | 输入 | 输出 | 评判标准 |
|---|---|---|---|
| 分类 | 图 | 标签 | 准确率 |
| 定位 | 图 | 坐标 | IoU |
2. 如何定位?
-
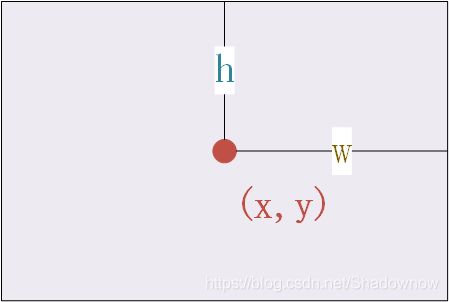
x,y,w,h:中心点位置(x,y),中心点距离两边的长和宽(w,h)
-
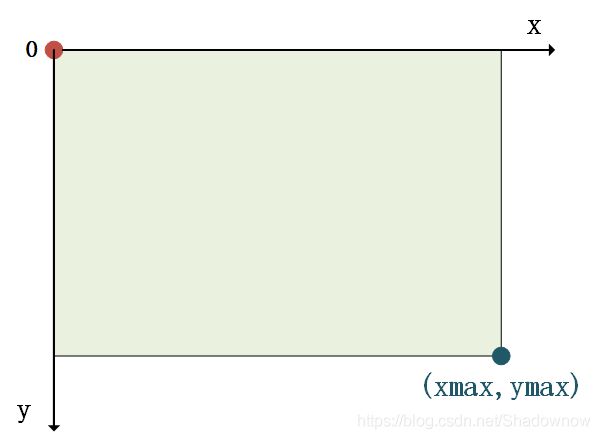
xmin,ymin,xmax,ymax:左上角坐标(xmin,ymin),右下角坐标(xmax,ymax)
3. 目标检测方法
- 两步走:区域推荐—>分类 ,先推荐图像中可能具有目标物体的区域,然后对这些区域进行分类。(典型网络:RCNN,SPP-Net,Fast-RCNN,Faster-RCNN)
- 端到端:采用一个网络一步到位(典型网络:Yolo,SSD)
4. 一些概念介绍:
- Ground-truth bounding box:图片中真实标记的物体位置的框
- Predicted bounding box:预测的框
如下图所示,绿色的框为正确标记的物体位置,红色的框为模型预测的物体位置。

对于多个目标,无法提前预测图片中到底有多少个物体出现,因此就没有固定个数的输出。接下来对目标检测的一些方法进行简要说明。
二、滑动窗口检测
这是一种暴力解法。定义一个滑动窗口,沿着图片从左往右,从上到下滑动,形成子图片,识别子图片是否包含所识别物体,并进行分类。
需设定一个固定大小的窗口,可使用不同大小的宽高比多次滑动。
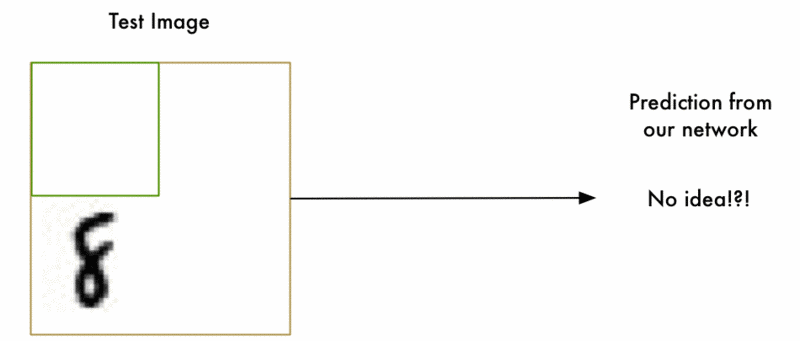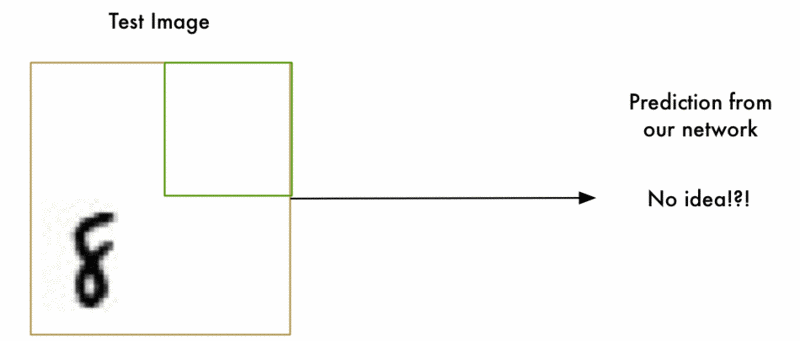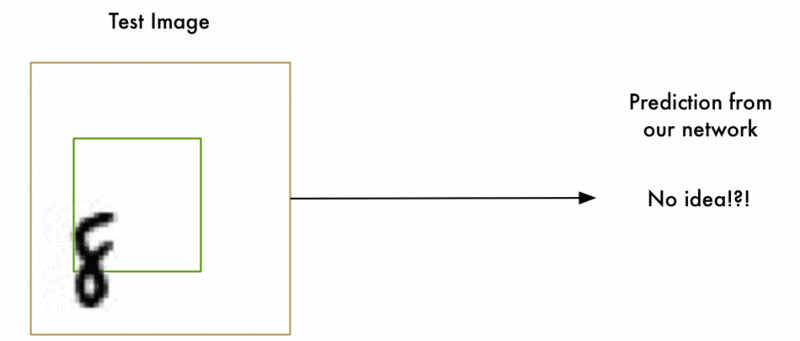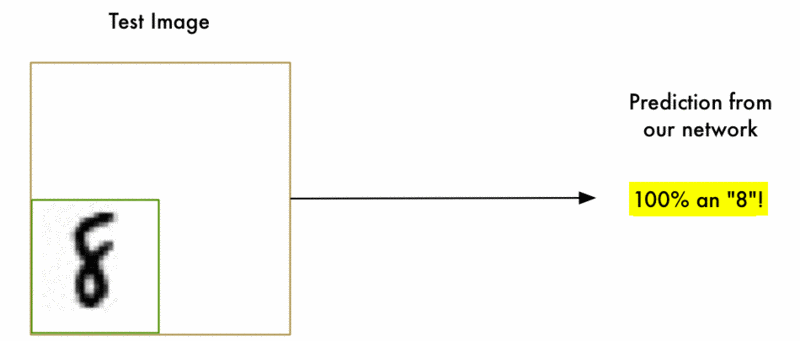
1.识别流程
- 首先定义若干个尺寸的窗口。假设K个。
- 每种尺寸的窗口分别去滑动(如上图所示滑动流程)。假设每个窗口滑动M次。
- 因此生成了K×M个子图片去分类。
2.方法缺点
暴力穷举,计算量十分大。
因此为我们提供了一种思路,有没有不暴力穷举的方法呢?
三、R-CNN模型
为了解决滑动窗口方法暴力穷举带来的缺点,提出了一种思路:
候选区域方法(Region Proposal Method):从初始图片中找出可能存在物体的候选区域,然后对候选区域进行分类。
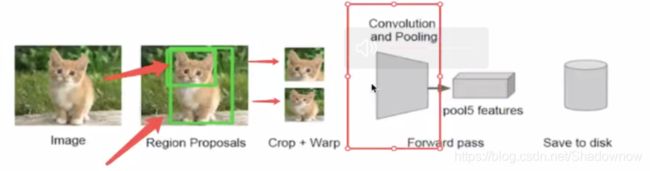
1.算法流程
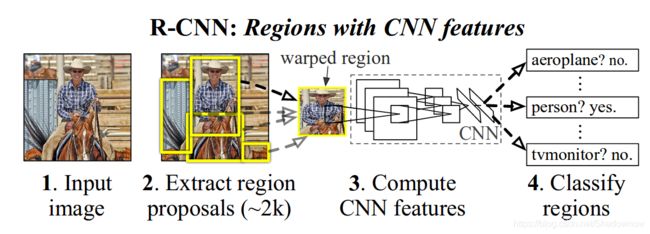
此算法识别流程如上图所示:
- 找出图片中可能存在的候选区域(ROI,Region of Interest),默认找2000个候选区域。
- 此处以AlexNet网络为基准,将候选区域调整图像比例,以适应AlexNet网络的输入要求227×227。对每个候选区域进行卷积提取特征,每个候选区域输出提取到的特征4096,因此输出2000×4096。
- 将2000×4096维特征输入至SVM分类器进行分类(假设有20种分类,SVM是二分类,因此此处有20个SVM分类器)。获得2000×20维矩阵。
- 分别对2000×20维矩阵进行非极大抑制(NMS:Non-Maxinum Suppression),以剔除重叠的、不好的区域,剩下结果相对较好的框。
- 修正bbox,对其做回归微调。
2.如何选出候选区域?
Selective Search算法,简称SS。
1、首先以像素为单位划分图像,分为组。
2、计算每组的相似度,将最接近的两个组进行合并。
3、重复操作2,直到图像合并完。
4、以上合并操作产生的区域都成为候选区域。
如下图所示。

- 由于产生的每个候选框尺寸不同,但CNN提取特征向量时需要接受固定长度的输入,因此需要对候选区域作尺寸上的修改。
- 所提取到的特征会存于磁盘中(这些特征才是真正要训练的数据)。
3.如何分类?
2000×4096维的特征向量:每张图片提取了4096特征,共有2000张图像。
针对每张图像,需要分别输入到20个分类器中。
如:
1.猫分类器
2.狗分类器
.
.
.
20.鸟分类器
因此输出2000×20的分数:每张图片有20个分数,共有2000张图片。分数代表分类为某类别的概率,值在0-1之间。
4.非极大抑制(NMS)
目的:筛选候选框,以为可能有的候选框位置很接近,就没有必要都保留。最理想的情况是,每个目标物体仅留一个最优的候选框。
迭代过程:
- 假设有2个目标物体
- 则最理想是从2000个框中最终筛选出2个候选框
-
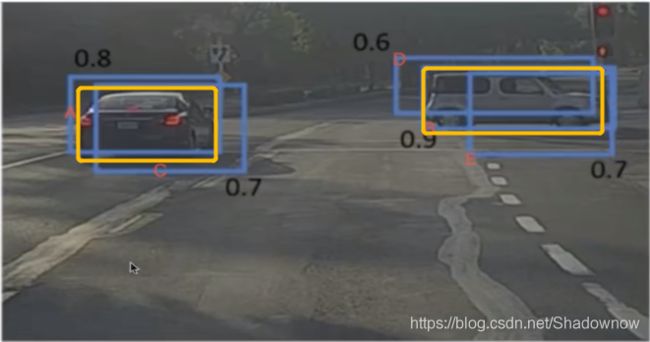
依据每个候选框的分类得分,根据阈值对2000个候选框进行筛选(假设阈值0.5)。如图所示,蓝色的框就被筛选掉了,留下了红色的框(此处的框数量仅仅举例,实际上有2000个框参与判断)

-
计算每个GT bbox与每个候选框的IoU(何为IoU在文章后面会有补充说明),选出每个GT bbox所对应的最高IoU值的候选框(假设经过1筛选后有5个候选框,则此处计算了2×5=10个IoU值,选出来2个候选框(A1,A2)。如图所示,两个黄色的框是GT bbox目标物体,计算五个蓝色框分别与两个黄色框的IoU值,假设与左黄IoU最高的是A,与右黄IoU最高的是B。
-
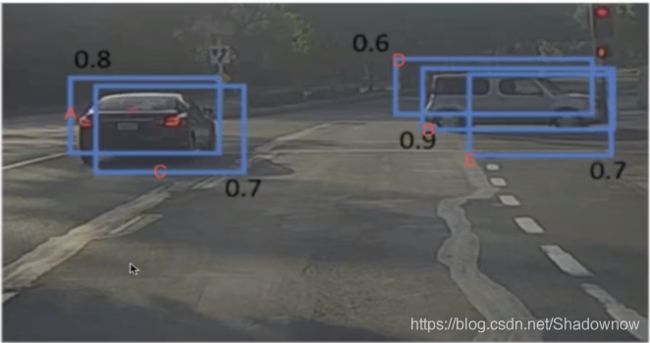
计算与A1,A2预测同一物体的剩余候选框(N)的IoU值,高于阈值的N就舍弃掉(这就代表重合度很高的框就没必要保留了)。如图,计算C与A的IoU(假设=0.8),以及D和E与B的IoU(假设=0.6和0.5),高于阈值的0.5的就删掉,那么CDE就被删掉了,最终剩下了A,B两个候选框。
5.修正候选区域
由上述结果可看到,候选区域A与左黄的位置还有一些差异,B与右黄也是如此,因此希望通过一定的操作可以使候选区域与GT bbox更吻合,更准确。
使用方法:建立一个bbox regressor。回归用于修正筛选后的候选框,使之回归于GT bbox。默认认为这两个框具有线性关系。
修正过程:
1、已知候选区坐标(px,py,pw,ph)与GT bbox坐标(tx,ty,tw,th),回归训练学习参数使得pxwx=tx,pywy=ty,pwww=tw,phwh=th)
2、则下一次预测时,候选区坐标×参数,得到预测值。
3、如图,A是候选区,G是GT,每次得到A后,先×参数,得到预测狂G’。

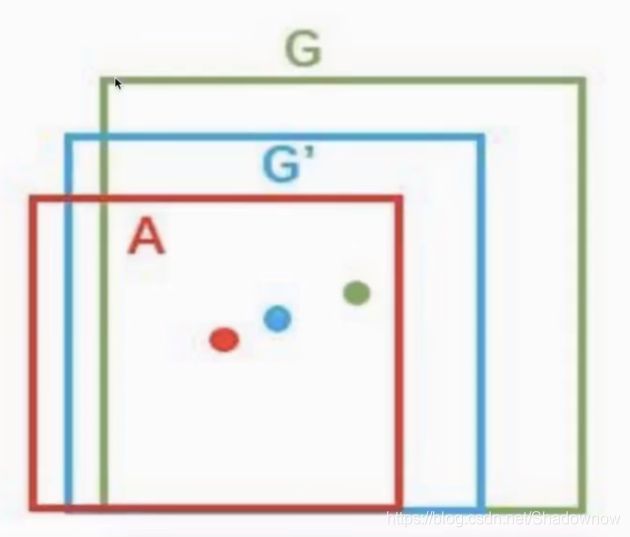
因此,RCNN的输出:一张图片预测候选框x,x ×w=y_locate
y_locate才是真正的算法输出位置。
6.目标检测评估指标
6.1 评估位置
使用IoU交并比(Intersection over Union)
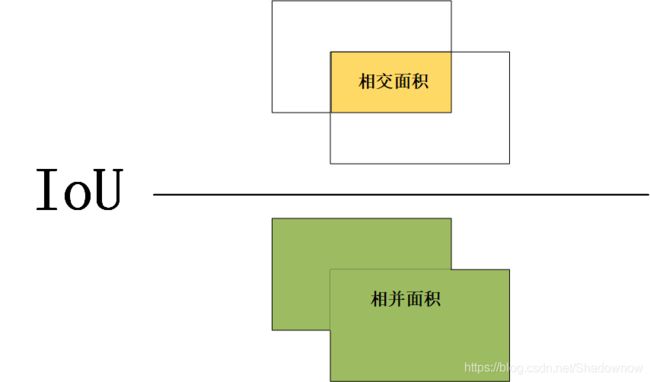
- 其值在0~1之间。IoU值越大,代表位置重合度越高。
- 预测框与真实框IoU值越大,则代表预测位置越准确。
6.2 评估分类
训练样本的标记:候选框标记
- 与每个GT bbox的IoU最大的候选框标记为正样本
- 剩余候选框与任何GT bbox的IoU大于阈值(假设0.7)的记为正样本;IoU小于阈值(假设0.3)的记为负样本。
使用平均精确率(mean Average Precision,mAP)
- mAP=所有类别的AP之和/类别总个数
- AP:Average precision
- 多个类别目标检测中,每个类别都可以根据recall(召回率)和percision(准确率)绘制一条曲线。AP就是该曲线下的面积,mAP意思是对每一类的AP再求平均。
True positives(TP): 被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数;
False positives(FP): 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;
False negatives(FN):被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数;
True negatives(TN): 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。

6.3 方法步骤
1、对于其中一个类别C,首先将算法输出的所有类别C的预测框,按照预测的分数排序;
2、设定不同的k值,选择top k个预测框,计算FP和TP,计算Precision和AP;
3、将得到的N个类别的AP取平均值,即得到了mAP;AP是针对单一类别的,mAP是所有类别的AP求和,再取平均。
RCNN在VOC2007数据集上的mAP达到66%
7.RCNN缺点
虽然RCNN解决了滑动窗口暴力穷举的缺点,但也存在缺陷。
- 训练阶段多;训练网络、SVM、bbox回归器。还不能一起训练,SVM是离线训练的 ,回归器也是离线训练
- 训练耗时。因为分别要对每一个候选区域都要特征提取。
- 占用磁盘空间大,因为提取的特征都要保存到磁盘中,用于训练。5000张的图片的特征文件就达到了几百G;
- 处理速度慢(论文中,使用GPU处理识别一张图片要47s);
- 图片形状变化。因为候选区域要经过crop/warp进行固定大小,无法保证图片不变形。
改进:提出SPP-Net,减少卷积运算。
四、SPP-Net
在此之前,所有的神经网络都是需要输入固定尺寸的图片,比如224224(ImageNet)、3232(LenNet)、96*96等。这样对于我们希望检测各种大小的图片的时候,需要经过crop,或者warp等一系列操作,这都在一定程度上导致图片信息的丢失和变形,限制了识别精确度。
1.为什么要输入固定尺寸?
卷积层的参数和输入大小无关,它仅仅是一个卷积核在图像上滑动,不管输入图像多大都没关系,只是对不同大小的图片卷积出不同大小的特征图,但是全连接层的参数就和输入图像大小有关,因为它要把输入的所有像素点连接起来,需要指定输入层神经元个数和输出层神经元个数,所以需要规定输入的feature的大小。
因此,固定长度的约束仅限于全连接层。
而SPP-Net解决了这个问题。SPP-Net在最后一个卷积层后,接入了SPP金字塔池化层,使用这种方式,可以让网络输入任意的图片,而且还会生成固定大小的输出。

2.算法流程
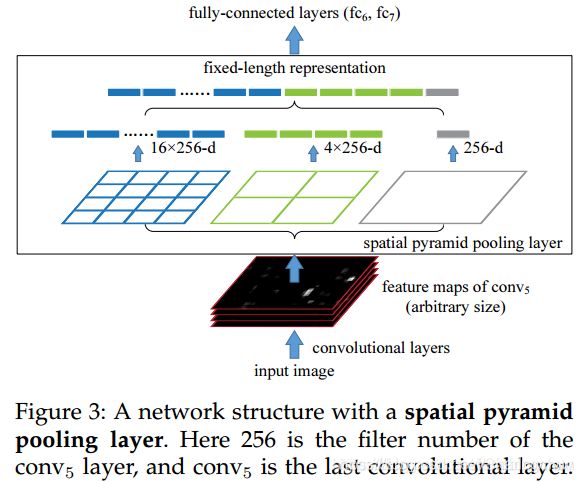
- 对整个输入图像进行特征提取,得到feature map;
- SS算法对输入图像提取候选区域;
- 将所得候选区域映射到feature map对应位置,得到候选区域的特征向量;
- 所得候选区域特征向量经过SPP层,输出固定大小的特征向量,输送给全连接层。
2.1 如何映射
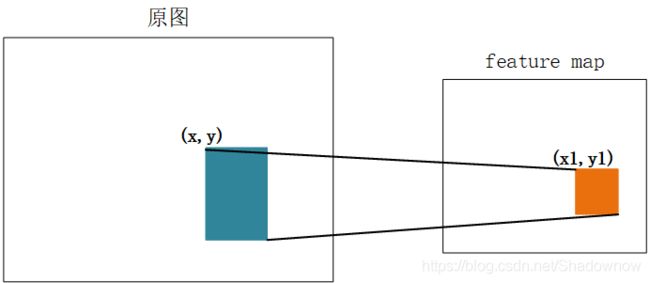
映射关系如上图所示,计算公式如下:
左上角:x1=[x/s]+1
右下角:y1=[y/s]-1
s是CNN中所有strides的乘积(包含了池化、卷积的步长,论文中s=2222=16
2.2 如何转换为固定大小特征向量
- 假设原图224*224,原图经过卷积后输出13×13×256,其中某个候选区域12×10×256
- SPP Layer将候选区域划分成1×1,2×2,4×4三个子图,对每个子图的每个区域进行max pooling,得到(1+4+16)×256=21×256=5376个结果
- 再全给全连接层。
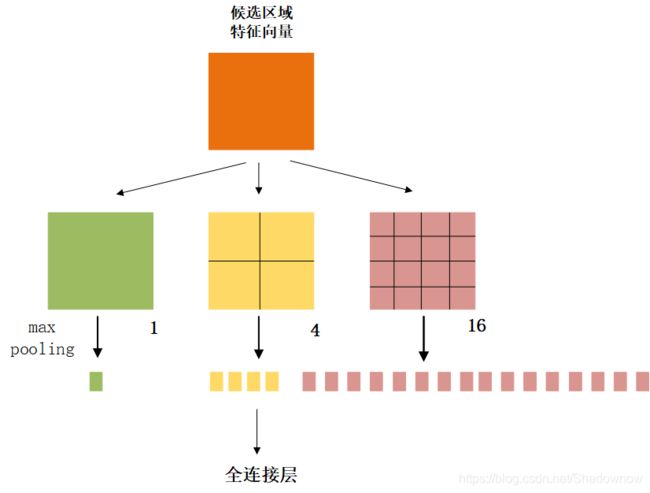
因此,无论什么尺寸输入的候选区域,都可以得到相同尺寸5376的输出。
3.SPP-Net优缺点
- 优点:速度提升(但提升不多)
- 缺点:训练速度还是过慢,效率低,特征也是需要写入磁盘,分阶段训练。
五、Fast-RCNN
希望在SPP-Net的基础上,整合模型的训练,可以提升训练速度。
1.算法流程
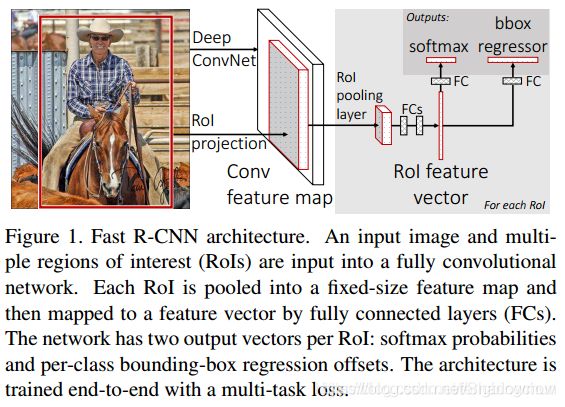
- 对输入图像进行卷积,提取特征feature map;
- SS算法提取候选区域;
- RoI Projection操作将候选区域映射到feature map,得到候选区域的特征向量;
- RoI pooling layer 提取一个固定长度的特征向量,每个特征会输入到一系列的全连接层,得到一个RoI特征向量(对每个候选区域都做一样的操作)
- 进行softmax分类和bbox regressor。
2.改进部分
废弃了SVM和SPP layer;
换用RoI Pooling 和 softmax多任务分类。
2.1RoI Pooling
- 在这部分,为了在得到固定长度的向量的同时,还减少计算时间,只使用4×4的盒子划分(SPP-Net中用了三种尺寸1×1,2×2,4×4的盒子)可以减少计算量和计算时间,快很多。实际上是简单版本的SPP。
- 经过此部分改进,可以节省很多时间,准确率没有突出得提升很多。
2.2End-to-End model
从输入端到输出端直接使用一个神经网络相连,整体优化目标函数。
为什么这整个网络可以统一训练?
特征提取CNN的训练和SVM分类器的训练在时间上是先后顺序,且训练方式相互独立,因此去掉了SVM分类这一过程,而使用softmax分类。
所有特征都存储在内存中,不占用硬盘空间,形成End-to-End模型。(proposal除外,end-to-end在Faster-RCNN中得以完善)
2.3多任务损失
两个loss:
- 对于分类的loss,是N+1路的softmax输出(N个种类,1为背景),使用交叉熵损失计算;
- 对于位置回归loss,是4*N路输出的regressor,对每个类别都单独训练一个regressor。使用平均绝对误差损失计算。
2.4fine-tuning训练
- 在微调时,调整CNN+RoI pooling+softmax
- 调整bbox,regressor回归中的参数
2.5总结
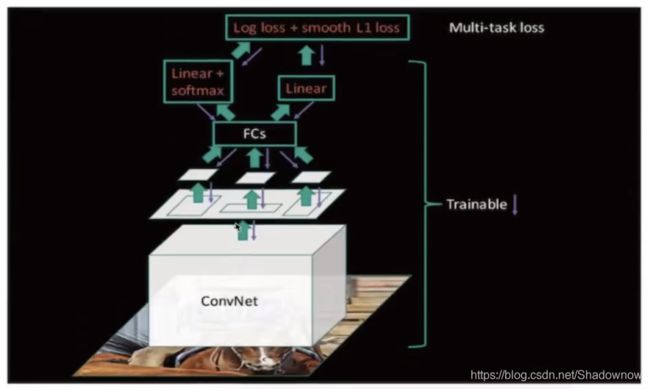
- 经过卷积得到特征图
- 候选区域经过映射后,通过RoI pooling 后传输给全连接层,经过Linear softmax 和 Linear 计算多任务损失,再返回。
3.模型性能对比
| 参数 | R-CNN | SPPNet | Fast R-CNN |
|---|---|---|---|
| 训练时间(h) | 84 | 25 | 9.5 |
| 测试时间/图片 | 47.0s | 2.3s | 0.32s |
| mAP | 66.0 | 63.1 | 66.9 |
缺点:使用SS提取候选区域,没有实现真正意义上的端对端,操作也十分耗时。
六、Faster-RCNN
在Fast-RCNN的基础上,Faster-RCNN将候选区域筛选融合到网络当中。
Faster-RCNN可简单看作是区域生成网络+Fast-RCNN的模型,使用区域生成网络(Region Proposal Network,RPN)来代替SS
1.RCNN三者对比
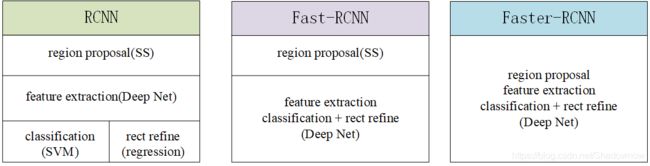
2.网络结构
输入图像提取到的feature map供区域生成网络和全连接层共用。
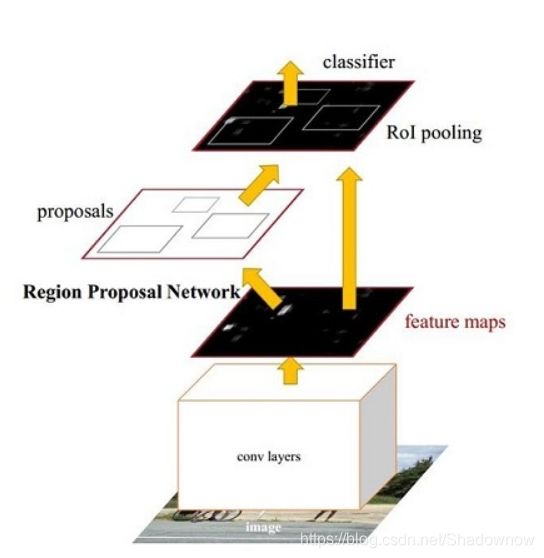
3.算法流程
- 输入图像,经过CNN网络提取feature map。
- 区域生成网络RPN。RPN网络用于生成候选区域,称作anchors。
-通过softmax判断anchors属于物体(foreground)还是背景(background);
- 利用bbox regression 修正属于物体的anchors,获得精确的候选区,输出TOP-N(默认为300)的区域给RoI pooling; - 后续进行Fast-RCNN的操作。
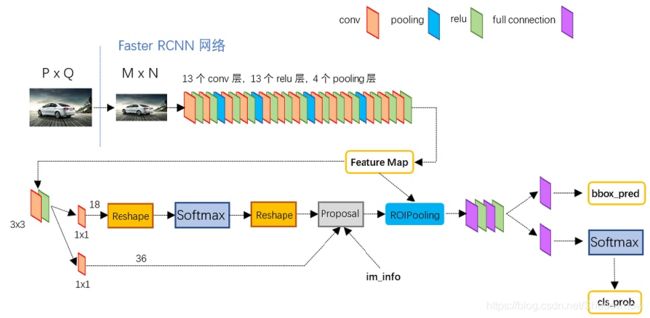
4.区域生成网络(RPN)原理
RPN网络的主要作用是得出比较准确的候选区域。
用n×n(默认3×3=9)的大小窗口去扫描特征图,每个滑窗位置映射到一个低维的向量(默认256维),并为每个滑窗位置考虑k种(在论文中设计k=9)可能的参考窗口(论文中称为anchors)
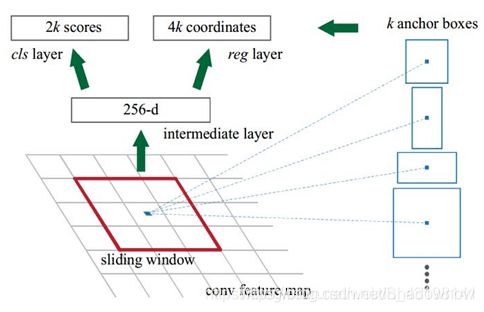
-
如图,假设feature map 为2020256,用3×3的滑动窗口去滑动,每一个位置有9种窗口比例,因此最终生成了20 * 20 * 9 * 256
-
3*3卷积核的中心点对应原图上的位置,将该点作为anchor的中心点,在原图框出多尺度、多种长宽比的anchors,三种尺度{128,256,512},三种长宽比{1:1,1:2,2:1},这样每个特征图中的像素点都有9种框。
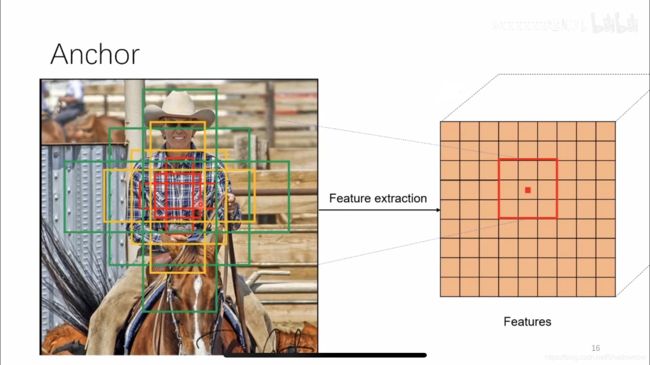
-
如下图所示,得到了51399个候选框,再进行分类(判断是否是背景)和bbox回归(回归位置)。目的是得到更好的候选区域提供给RoI pooling 使用。

-
然后进行Fast-RCNN部分。
5.Faster-RCNN的训练
5.1 RPN的训练
目的:从众多的候选区域中提取出score分数较高的,并且经过regression调整的候选区域。
- 分类:二分类,softmax,logistic regression
- 候选框的调整:均方误差作修正
5.2 Fast-RCNN的训练
- Fast-RCNN classification(over classes):所有类别分类N+1,得到候选区域的每个类别概率;softmax;
- Fast-RCNN regression(bbox regression):得到更好的位置。均方误差损失。
5.3 候选区域的训练
- 训练样本anchor标记
-每个GT bbox 有最高IoU的anchor为正样本;
- 剩下anchor和任何GT bbox的IoU大于0.7为正样本,IoU小于0.3为负样本
- 剩余样本忽略 - 正负样本比例1:3
三个误差:RPN中置信度误差和坐标误差、Faster-RCNN最后softmax分类的误差和坐标误差。
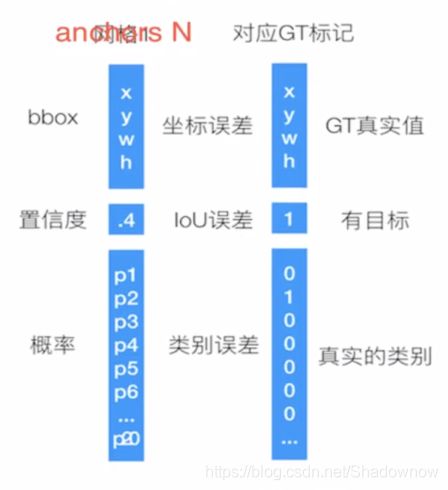
候选区域的训练是为了得出正确的候选区域,并且候选区域经过了回归微调,在这基础上作Fast-RCNN的训练是得到特征向量做分类预测和回归预测。
6.Faster-RCNN效果对比
| R-CNN | Fast R-CNN | Faster R-CNN | |
|---|---|---|---|
| Test time/image | 50.0s | 2.0s | 0.2s |
| mAP(VOC2007) | 66.0 | 66.9 | 66.9 |
由此可见,提升的速度很大,准确率没有什么提升。
7.Faster-RCNN总结
- 优点:提出RPN网络,形成端到端模型
- 缺点:训练参数过大
- 改进需求
- RPN部分可以选择更多尺度去识别一些小目标
- 速度提升
七、Yolo(You Only Look Once)
Faster-R-CNN利用RPN网络与真实值调整了候选区域,然后再进行候选区域和卷积特征结果映射的特征向量的处理,来通过与真实值优化网络预测结果。
Yolo系列算法将这两个步骤合成一个步骤,直接网络输出预测结果进行优化。
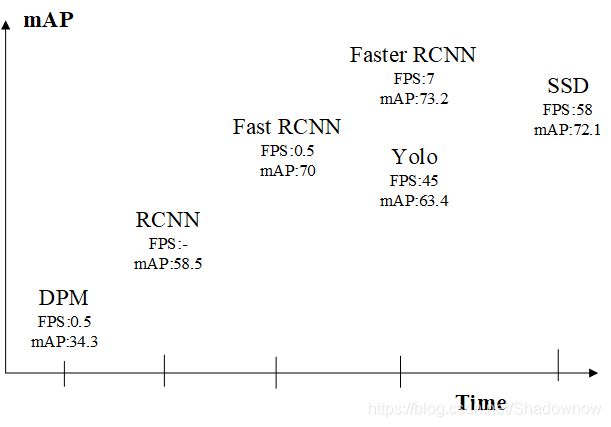
接下来对比一些网络(FPS和mAP越大越好)
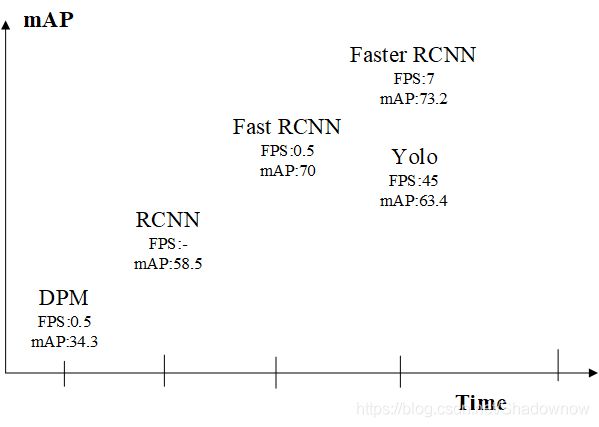
由上图可看出,Yolo的速度在Faster-RCNN上有了很大提升,但是准确率打折。
1. 网络结构
一个网络搞定一切!GoogleNet+4个卷积层+2个全连接层
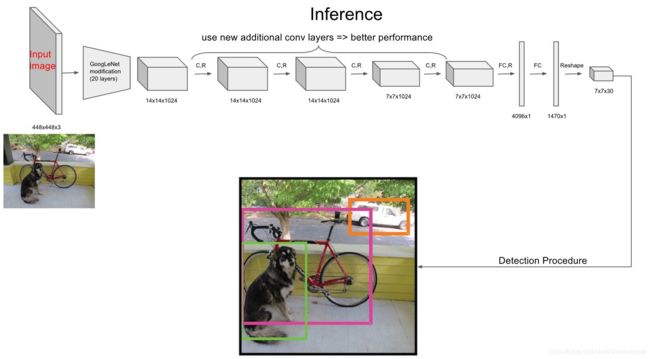
流程理解:
- 原始图片resize到448×448,经过前面的卷积网络之后,将图片输出成一个7 7 30的结构。
- 于是将图片分为7*7的单元格,每个单元格负责去检测那些中心点落在该格子内的目标,检测出框的位置和置信度。如下图所示(此图用3 * 3的网格来演示),假设一个单元格预测2个候选框,那么就预测出来了18个候选框。
-所谓置信度其实包含两个方面,一是这个边界框含有目标的可能性大小,二是这个边界框的准确度。前者记为a ,当该边界框是背景时(即不包含目标),此时a=0 。而当该边界框包含目标时,a=1 。边界框的准确度可以用预测框与实际框(ground truth)的IOU(intersection over union,交并比)来表征,记为b。因此置信度可以定义为a * b。
- 候选框经过NMS筛选,筛选概率以及IoU

2.单元格(grid cell)
- 每个单元格负责预测一个物体类别,并且直接预测物体的概率值
- 每个单元格预测两个(默认是两个)bbox的位置,两个bbox置信度(confidence)
- 输出30个值(4+1+4+1+20),4是坐标信息,1是置信度,20代表20类类别的概率。(只用其中一个比较好的候选框去预测类别概率,至于用哪个,通过置信度来决定)
不同意Faster RCNN中的anchors,yolo的框坐标、概率值都是由网络直接得出的,而Faster RCNN是认为设定的一个值,然后利用RPN网络对其优化到一个更准确的坐标和是否背景类别。
- 非极大抑制:先过滤掉低于某一阈值的bbox,然后对每个类别过滤IoU。就得到了最终检测结果。
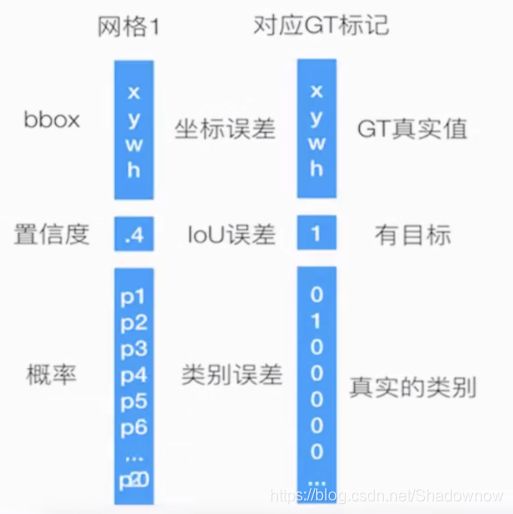
3.训练过程
3个部分的损失,损失相加,然后去更新前面的网络
4.与Faster-RCNN比较
Faster-R-CNN利用RPN网络与真实值调整了候选区域,然后再进行候选区域和卷积特征结果映射的特征向量的处理,来通过与真实值优化网络预测结果。而这两步在yolo算法中合成了一个步骤,直接网络输出预测结果进行优化。
所以经常会YOLO算法为直接回归法代表。YOLO的特点就是快。但准确率会下降一些。
5.YOLO总结
- 优点:速度快
- 缺点:1. 准确率打折扣; 2. YOLO对相互靠得很近的物体(挨在一起且中点落在同一个格子的情况),还有很小的物体效果不好。因为在YOLO中,每个网格仅仅预测一种物体,且框太少。
八、SSD
SSD:Single Shot MultiBox Detector
结合了Faster RCNN的anchor机制和YOLO回归思想,以达到准和快的目的。
SSD核心:在不同尺度的特征图上采用卷积核来预测一系列Default Bounding Boxes的类别以及坐标偏移。
1.网络结构
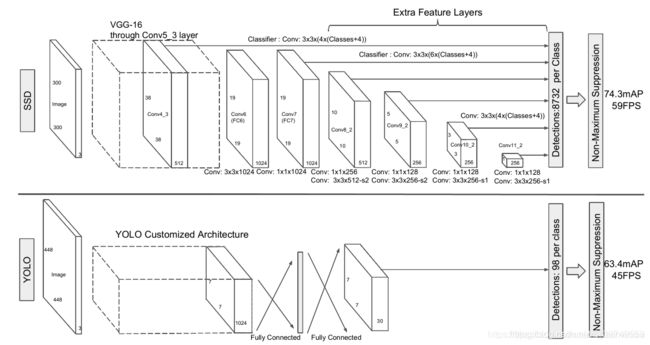
上图是SSD和YOLO的网络结构,通过对比可以发现,SSD的优点就是它生成的 default box 是多尺度的,这是因为SSD生成default box 的 feature map 不仅仅是CNN输出的最后一层,还有利用比较浅层的feature map 生成的default box。
以VGG16为基础,使用VGG的前5个卷积,后面增加从conv6开始的5个卷积结构。输入图片要求300*300。
2. 算法流程
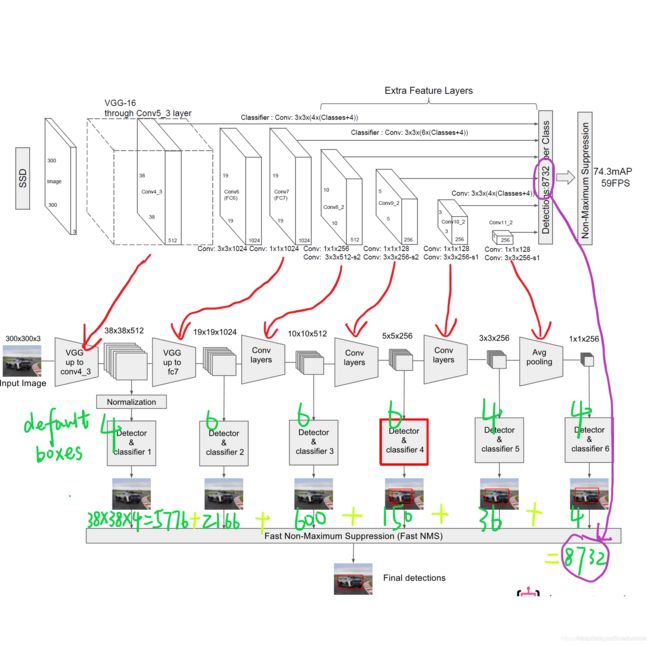
- 图片输入;
- 经过VGG网络后,输出38 * 38 * 512的特征图1;
- 再经过卷积结构,输出19 * 19 * 1024的特征图2;
- 再经过卷积结构,输出10 * 10 * 512的特征图3;
- 再经过卷积结构,输出5 * 5 * 256的特征图4;
- 再经过卷积结构,输出3 * 3 * 256的特征图5;
- 再经过卷积结构,输出1 * 1 * 256的特征图6;
- 对于特征图1,经过归一化,每一个像素点预测4个default box,则预测了38 * 38 * 4=5776个框;
- 对于特征图2,每一个像素点预测6个default box,则预测了19 * 19 * 6=2166个框;
- 对于特征图3,每一个像素点预测6个default box,则预测了10 * 10 * 6=600个框;
- 对于特征图4,每一个像素点预测6个default box,则预测了5* 5 * 6=150个框;
- 对于特征图5,每一个像素点预测4个default box,则预测了3* 3 * 4=36个框;
- 对于特征图6,每一个像素点预测4个default box,则预测了1* 1 * 4=4个框;
- 则一共预测了5776+2166+600+150+36+4=8732个框。这些框经过Fast NMS 得到最终预测框。
论文中将Detector & classifier 称作 PriorBox 层。
3. PriorBox 层
做什么:
- 得到default box;(按照不同的长宽比)
- 吸取Yolo的优点,在网络直接输出每个框的4个位置和预测类别概率;
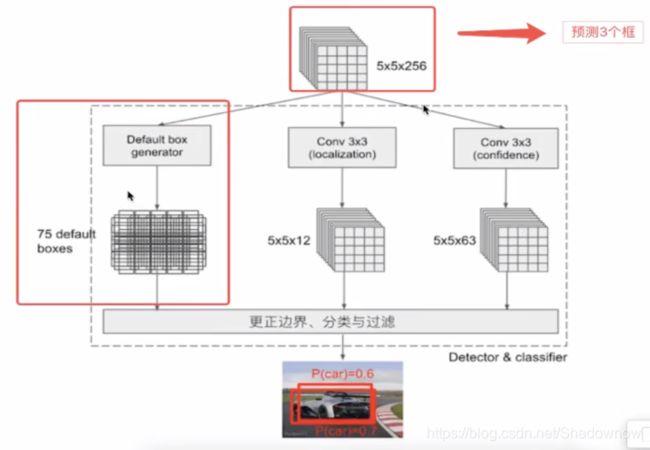
- 生成默认候选框default box;(对标Faster-RCNN中anchor)生成后会利用设定的4个variance做位置微调,回归调整候选框;
- Conv3 ×3:生成location,4个位置偏移;
- Conv3×3:confidence,21个类别置信度(要区分出背景)。
- location和confidence
-用来过滤和训练。 - Detector & classifier的作用
- SSD的核心是在不同尺度的特征图上进行Detector & classifier 容易使得SSD观察到更小的物体。
4. 训练和测试过程
4.1 训练过程
- 输入 -> 输出 -> 结果与GT bbox标记样本回归损失计算 -> 反向传播,更新权值
- 样本标记:
先将prior box 与 ground truth box做匹配进行标记正负样本,每次并不训练8732张计算好的default boxes,先进行置信度的筛选,并且训练指定的正样本和负样本,如下规则
- 正样本:1.与GT重合度最高的boxes 2.与GT的IoU超过一定阈值的
- 负样本:其他样本
- 比例正:负=1:3- 损失: 置信度softmax,位置回归Smooth L1 Loss
4.2 测试过程
- 输入 -> 输出 -> NMS -> 输出
5. 总结