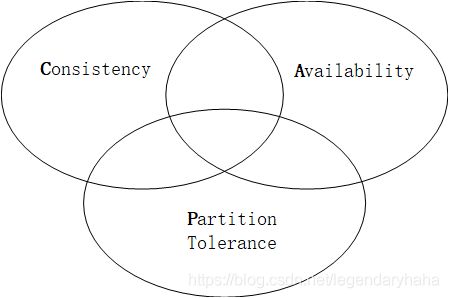
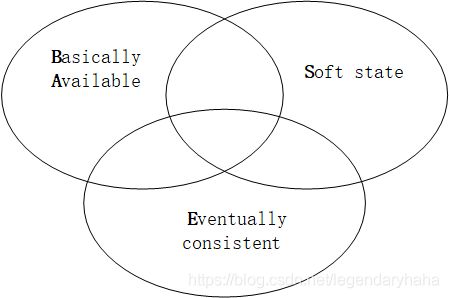
Linux调试器gdb和cgdb的使用【Ubuntu】一、样例代码在介绍如何使用gdb和cgdb之前,先准备一个简单的C程序作为调试示例。假设我们有一个简单的程序example.c,它包含了一个求数组平均值的函数。#include#defineSIZE5doublecalculate_average(intarr[],intsize){intsum=0;for(inti=0;i
Web-API-day4 DOM节点
码哥DFS
javascript开发语言ecmascript
一、日期对象1.实例化日期对象constdate=newDate()指定时间constdate1=newDate('2025-7-922-00-00')获取日期的另一种表达方式:toLocaleString()2.获取日期对象每一个部分getFullYear():获取年份getMonth()+1:获取月份getDate():获取月份某中某一天getHours():获取小时getMinutes():
cocos2dx3.x项目升级到xcode15以上的iconv与duplicate symbols报错问题
itme268
iconv报错
cocos2dx3.x项目升级xcode15以上后会有几处报错。1.CCFontAtlas.cpp文件下的iconv与iconv_close的报错。修改如下://iconv_close(_iconv);iconv_close((iconv_t)_iconv);iconv((iconv_t)_iconv,(char**)&pin,&inLen,&pout,&outLen);//iconv(_icon
《破局节点失效:Erlang分布式容错系统的自愈机制与恢复逻辑》
后端
节点故障是无法根除的常态——硬件老化、网络波动、资源耗尽等因素,随时可能让某个节点从集群中“消失”。Erlang语言凭借其面向并发的设计哲学与原生分布式支持,成为构建容错系统的优选工具。但真正的挑战不在于避免故障,而在于当节点失效时,系统能否像有机体自愈般自动恢复,这需要对Erlang的进程模型、分布式通信与状态管理进行深度挖掘,构建一套从故障感知到服务续接的完整逻辑闭环。Erlang节点间的默认
windows下tokenizers-cpp编译
Wite_Chen
windowstokenizers-cpp
github地址一、rust环境配置参考二、编译1、修改cmakelists.txt,支持x86和64编译(tokenizers_c库,原始版本windows下只支持64位)修改顶层CMakeLists.txt文件(77行),支持x86编译elseif(CMAKE_SYSTEM_NAMESTREQUAL"Windows")#set(TOKENIZERS_CPP_CARGO_TARGETx86_64
Python与c++互相调用(pybind11)
欢迎下辈子光临
CPPPythonpythonc++开发语言
1.安装pybind11看网上使用pipinstallpybind11,没有弄明白,因此下载源码编译。1.1下载pybind11gitclonehttps://github.com/pybind/pybind11.git1.2源码编译cd/pybind11mkdirbuildcdbuildcmake..make编译完成2.cpp样例//example.cpp#include#include"Abs
2023 睿抗机器人开发者大赛CAIP-编程技能赛-本科组(省赛)
Harold0895
算法c语言c++
2023睿抗机器人开发者大赛CAIP-编程技能赛-本科组(省赛)RC-u1亚运奖牌榜题意给定两个国家/地区的金银铜牌的获得记录,输出他们的金银铜牌的具体记录,并输出哪个国家/地区排名高思路直接读入后比较即可代码#includeusingnamespacestd;inta[5],b[5];voidsolve(){intn;cin>>n;for(inti=1;i>wh>>op;if(wh==0)a[o
[论文阅读] 人工智能 + 软件工程 | 当 LLM 写代码时,它的 “思考过程” 靠谱吗?—— 揭秘 CoT 质量的那些事儿
张较瘦_
前沿技术论文阅读人工智能软件工程
当LLM写代码时,它的“思考过程”靠谱吗?——揭秘CoT质量的那些事儿论文标题:AreTheyAllGood?EvaluatingtheQualityofCoTsinLLM-basedCodeGenerationarXiv:2507.06980[pdf,html,other]AreTheyAllGood?EvaluatingtheQualityofCoTsinLLM-basedCodeGenera
【论文笔记】GaussianFusion: Gaussian-Based Multi-Sensor Fusion for End-to-End Autonomous Driving
原文链接:https://arxiv.org/abs/2506.00034v1简介:现有的多传感器融合方法多使用基于注意力的拉直(flatten)融合或通过几何变换的BEV融合,但前者可解释性差,后者计算开销大(如下图(a)(b)所示)。本文提出GaussianFusion(下图(c)),一种基于高斯的多传感器融合框架,用于端到端自动驾驶。使用直观而紧凑的高斯表达,聚合不同传感器的信息。具体来说,
【线上故障排查】缓存穿透攻击的识别与布隆过滤器(面试题 + 3 步追问应对 + 案例分析)
程序员岳彬
从项目到面试:Java高频面试题场景化通关指南缓存java后端springbootlinuxredis
一、高频面试题问题1:什么是缓存穿透?它对系统的核心危害是什么?参考答案:缓存穿透指的是用户请求的数据在缓存和数据库中都不存在,导致请求直接绕过缓存打到数据库。核心危害是大量无效请求会耗尽数据库资源,比如CPU、内存或连接数,严重时可能引发数据库宕机,进而导致整个系统崩溃,影响服务可用性。第一步追问:缓存穿透和缓存雪崩有什么本质区别?参考答案:两者本质不同。缓存穿透是请求不存在的数据,攻击或逻辑漏
在sf=0.1时测试fireducks、duckdb、polars的tpch
l1t
数据库编程语言软件工程python压力测试
首先,从https://github.1git.de/fireducks-dev/polars-tpch下载源代码包,将其解压缩到/par/fire目录。然后进入此目录,运行SCALE_FACTOR=0.1./run-fireducks.sh,脚本会首先安装所需的包,编译tpch的数据生成器,然后按照sf=0.1生成tbl文件,再转化为parquet格式,最后执行。如下所示:root@DESKTO
12行脚本实现duckdb自动完成tpch测试
l1t
数据库编程语言软件工程数据库sqlgithub
核心思想:利用duckdbtpch插件内置的tpch_queries()表函数输出查询Sql语句到qs.txt,然后读入生成的qs.txt,将结果输出到res.txt,在控制台输出计时。autotpch.txt脚本如下:LOADtpch;PRAGMAdisable_progress_bar;CALLdbgen(sf=0.3);.outputqs.txt.modelist.headeroffsele
Redis 分布式锁实现与实践
佑瞻
数据库与知识图谱redis分布式数据库
在分布式系统架构中,多个独立进程对共享资源的并发访问控制是常见需求,分布式锁作为解决这一问题的关键技术,在缓存更新、任务调度、库存管理等场景中发挥着重要作用。本文将从基础原理出发,详细阐述基于Redis的分布式锁实现方案,包括单实例模式与Redlock算法,并探讨其在实际应用中的关键考量。分布式锁核心概念分布式锁是一种跨进程、跨机器的同步机制,用于保证多个分布式节点对共享资源的互斥访问。一个可靠的
仓颉编程语言:从入门到精通
为啥要瞅瞅仓颉这玩意儿?有一说一,现在的编程语言多得跟米一样,对吧?那一门新语言想火,没点绝活儿肯定不行。仓颉(Cangjie)这哥们儿,是华为搞出来的新玩意儿,静态编译的,主打的就是一个现代化、性能炸裂、安全感满满,而且天生就会搞并发。就凭这几点,已经有不少大佬开始关注了。这篇博客呢,就是你的“老司机”指南,带你把仓颉这车开得明明白白。不管你是刚上路的小白,还是开惯了Rust、Go、Java、N
从 callTool 到思考型调用:月影 Resolver 颠覆传统 MCP 的三板斧
weixin_55007223
月影陪伴智能体AI编程语言模型人工智能
3ms与2s——这是Resolver用两条完全不同的路径给出的答案。当大多数MCP集成还停留在callTool(…)的机械时代,月影把“工具调用”推进了一格:让语义去找工具,让工具自己组队。这不是一次简单的工程优化,而是我们对“人机协作边界”的一次重新提问。我们相信——工具不只是工具,而是智能的触角;而Resolver,是月影整个意识系统中最冷静、最精准的那个判断节点。结果也在验证这一点:95%日
C语言易错点整理(一)
WangJiaLeLeLeLe
c语言算法数据结构
1、对于字符数组而言,只是将这些字符放进我们所开辟的空间里,不能直接用strlen计算,因为没有"\0",会导致出现随机值,例如一下代码chararr[]={'b','i','t'};printf("%d",strlen(arr));2、switch语句中,关键字包含case、break、default,但是不包含continue(不执行其下面的语句直接返回判断条件判断)3、在不同作用域中可以有相
Python中字符串的操作方法
幻鸩605
pythonjava开发语言
字符串拼接使用+运算符将多个字符串连接起来。例如:s1="Hello"s2="World"result=s1+""+s2print(result)#输出:HelloWorld字符串重复使用*运算符重复字符串。例如:s="abc"result=s*3print(result)#输出:abcabcabc字符串长度使用len()函数获取字符串长度。例如:s="Python"length=len(s)pr
使用Ora2Pg迁移Oracle数据到openGauss
hid_clf-2oizpt7skaq
oracle数据库
下载及安装Ora2Pg1.下载说明PerlDBD:SearchtheCPAN-metacpan.org#只需在搜索输入框中输入模块的全名(例如:DBD::Oracle、DBD::Pg)Ora2Pg:Ora2Pg:MigratesOracletoPostgreSQL在Windows下,应该安装StrawberryPerl(StrawberryPerlforWindows)和操作系统对应的Oracle
oracle pg 文件级迁移,从Oracle迁移到AntDB(二)-- ora2pg-对象和数据的导出导入
使用Ora2pg和psqlcopy方式进行数据迁移author:yafeishitags:AntDB,ora2pg,oracleAntDB:github_url,基于postgresql的高性能分布式数据库使用Ora2pg和psqlcopy方式进行数据迁移准备工作使用本文档的前提本文档指导如何使用ora2pg进行oracle到ADB的数据迁移,但是在参照本文档操作之前,有以下条件必须满足:-ADB
Spring 生态创新应用:微服务架构设计与前沿技术融合实践
七夜zippoe
#Javaspring微服务java
在数字化转型的深水区,企业级应用正面临从“单体架构”向“分布式智能架构”的根本性跃迁。Spring生态以其二十年技术沉淀形成的生态壁垒,已成为支撑这场变革的核心基础设施。从2002年RodJohnson发布《ExpertOne-on-OneJ2EEDesignandDevelopment》奠定的理论基础,到如今覆盖从开发到运维全链路的技术矩阵,Spring始终以“简化开发”为初心,构建出适配不同业
Excalidraw:开源手绘风格白板工具的技术与生态解析
wylee
开源
一、项目定位与核心价值Excalidraw是一款基于浏览器的开源虚拟手绘风格白板工具,由Excalidraw团队开发并维护。项目以MIT协议开源,旨在提供轻量级、高定制性的在线绘图解决方案,适用于流程图设计、原型绘制、教学演示等场景。截至2025年3月,项目已发布v0.18.0版本,月下载量超24.5万次,被GoogleCloud、Meta等企业集成,成为开源协作工具领域的标杆项目。二、核心功能与
Linux中安装Tomcat
十一的学习笔记
运维中服务安装管理linuxtomcat运维
文章目录一、Tomcat介绍1.1、Tomcat是什么1.2、Tomcat的工作原理1.3、Tomcat适用的场景1.4、Tomcat与Nginx、Apache比较1.4.1、优势1.4.2、劣势1.4.3、定位功能1.5、Tomcat的主要组件1.6、Tomcat的主要配置文件二、Tomcat安装2.1、查看可用的JDK2.2、安装OpenJDK112.3、配置环境变量2.4、验证安装2.5、查
TDengine 集群节点管理
TDengine (老段)
TDengineSQL手册tdengine数据库时序数据库大数据物联网iotdbiot
简介组成TDengine集群的物理实体是dnode(datanode的缩写),它是一个运行在操作系统之上的进程。在dnode中可以建立负责时序数据存储的vnode(virtualnode),在多节点集群环境下当某个数据库的replica为3时,该数据库中的每个vgroup由3个vnode组成;当数据库的replica为1时,该数据库中的每个vgroup由1个vnode组成。如果要想配置某个数据库为
linux环境下tomcat安装
M.za
linuxtomcat运维服务器
Tomcat一、什么是Tomcat?1.1、Tomcat介绍Tomcat又叫ApacheTomcat最早是sun公司开发的,1999年捐献给apache基金会,隶属于雅加达项目,现在已经独立成一个顶级项目,因为tomcat技术先进,性能稳定,又是一个开源的web应用服务器,所以很多企业都在使用,很多Java开发者也在使用,开发调试jsp的首选,被更多企业用于Java容器。Tomcat官网:http
84.7k Star!Excalidraw:开源的在线白板工具,具备手绘风格和实时协作功能
蚝油菜花
每日AI项目与应用实例人工智能开源画板实时协作
❤️如果你也关注大模型与AI的发展现状,且对大模型应用开发非常感兴趣,我会快速跟你分享最新的感兴趣的AI应用和热点信息,也会不定期分享自己的想法和开源实例,欢迎关注我哦!微信公众号|搜一搜:蚝油菜花快速阅读Excalidraw是一款开源的在线白板工具,具备手绘风格和实时协作功能。支持多种绘图工具、便捷导出、离线可用及跨平台兼容性。适用于远程协作、头脑风暴、产品设计和技术绘图等多个场景。正文(附运行
蓝牙协议栈低功耗之安全管理协议层(SMP)
写代码的无赖的猴子
BLE低功耗蓝牙协议栈网络信息与通信物联网
逻辑链路控制和适配协议层L2CAPSMP层阶段一阶段二Legacyparing安全连接交换公匙鉴权阶段1鉴权阶段2阶段三LElegacypairing:LESecureConnections交叉密匙特性配对PDU类型Hello,我是无赖的猴子,一个蓝牙爱好者,分享蓝牙相关的知识,关注我,学习蓝牙:蓝牙文章链接直达:1.profile层(待更新)2.属性协议层(ATT)(待更新)3.安全管理协议层(
HarmonyOS 入门到精通:为什么状态管理是鸿蒙开发的核心?
逻极
harmonyos鸿蒙笔记harmonyos华为鸿蒙入门到精通状态管理状态模式arkts
在现代应用开发中,状态管理是构建响应式应用的基石。对于鸿蒙这种面向全场景的分布式操作系统,状态管理机制显得尤为重要。它不仅是实现复杂交互逻辑的关键,还直接关系到应用的性能、可维护性和用户体验。什么是状态管理?状态是指UI组件所依赖的、会随时间变化的数据。状态管理则是对这些变化数据的有效组织和控制,包括:状态的创建与初始化:在应用启动或组件加载时,为状态变量分配初始值,确保组件能够正确渲染初始界面。
MCP协议采用客户端-服务器架构的深层逻辑与架构对比分析
一、架构选择的核心动因1.功能解耦与安全边界的强制性要求MCP采用客户端-服务器(C/S)架构的核心动因源于AI系统与真实世界交互的特殊性:权限分层控制:主机(Host)作为协调层,严格划分客户端(Client)与服务端(Server)的操作权限。例如医疗场景中,诊断模型(Client)仅能通过医院授权的主机访问脱敏病历服务器,无法直接接触原始数据。沙箱隔离需求:每个MCP服务器运行在独立容器中(
4.服务注册发现:微服务的神经系统
在微服务架构中,服务之间不再是固定连接,而是高度动态、短暂存在的。如何让每个服务准确找到彼此,是分布式系统治理的核心问题之一。服务注册发现机制,正如神经系统之于人体,承担着连接、协调、感知变化的关键角色。本文将围绕Netflix开源的服务注册发现组件Eureka展开,深入剖析其原理,并以SpringCloud实战为导向,帮助你掌握服务治理的第一步。一、为什么需要服务注册发现?在单体架构中,服务调用
LeetCode[位运算] - #137 Single Number II
Cwind
javaAlgorithmLeetCode题解位运算
原题链接:#137 Single Number II
要求:
给定一个整型数组,其中除了一个元素之外,每个元素都出现三次。找出这个元素
注意:算法的时间复杂度应为O(n),最好不使用额外的内存空间
难度:中等
分析:
与#136类似,都是考察位运算。不过出现两次的可以使用异或运算的特性 n XOR n = 0, n XOR 0 = n,即某一
《JavaScript语言精粹》笔记
aijuans
JavaScript
0、JavaScript的简单数据类型包括数字、字符创、布尔值(true/false)、null和undefined值,其它值都是对象。
1、JavaScript只有一个数字类型,它在内部被表示为64位的浮点数。没有分离出整数,所以1和1.0的值相同。
2、NaN是一个数值,表示一个不能产生正常结果的运算结果。NaN不等于任何值,包括它本身。可以用函数isNaN(number)检测NaN,但是
你应该更新的Java知识之常用程序库
Kai_Ge
java
在很多人眼中,Java 已经是一门垂垂老矣的语言,但并不妨碍 Java 世界依然在前进。如果你曾离开 Java,云游于其它世界,或是每日只在遗留代码中挣扎,或许是时候抬起头,看看老 Java 中的新东西。
Guava
Guava[gwɑ:və],一句话,只要你做Java项目,就应该用Guava(Github)。
guava 是 Google 出品的一套 Java 核心库,在我看来,它甚至应该
HttpClient
120153216
httpclient
/**
* 可以传对象的请求转发,对象已流形式放入HTTP中
*/
public static Object doPost(Map<String,Object> parmMap,String url)
{
Object object = null;
HttpClient hc = new HttpClient();
String fullURL
Django model字段类型清单
2002wmj
django
Django 通过 models 实现数据库的创建、修改、删除等操作,本文为模型中一般常用的类型的清单,便于查询和使用: AutoField:一个自动递增的整型字段,添加记录时它会自动增长。你通常不需要直接使用这个字段;如果你不指定主键的话,系统会自动添加一个主键字段到你的model。(参阅自动主键字段) BooleanField:布尔字段,管理工具里会自动将其描述为checkbox。 Cha
在SQLSERVER中查找消耗CPU最多的SQL
357029540
SQL Server
返回消耗CPU数目最多的10条语句
SELECT TOP 10
total_worker_time/execution_count AS avg_cpu_cost, plan_handle,
execution_count,
(SELECT SUBSTRING(text, statement_start_of
Myeclipse项目无法部署,Undefined exploded archive location
7454103
eclipseMyEclipse
做个备忘!
错误信息为:
Undefined exploded archive location
原因:
在工程转移过程中,导致工程的配置文件出错;
解决方法:
GMT时间格式转换
adminjun
GMT时间转换
普通的时间转换问题我这里就不再罗嗦了,我想大家应该都会那种低级的转换问题吧,现在我向大家总结一下如何转换GMT时间格式,这种格式的转换方法网上还不是很多,所以有必要总结一下,也算给有需要的朋友一个小小的帮助啦。
1、可以使用
SimpleDateFormat SimpleDateFormat
EEE-三位星期
d-天
MMM-月
yyyy-四位年
Oracle数据库新装连接串问题
aijuans
oracle数据库
割接新装了数据库,客户端登陆无问题,apache/cgi-bin程序有问题,sqlnet.log日志如下:
Fatal NI connect error 12170.
VERSION INFORMATION: TNS for Linux: Version 10.2.0.4.0 - Product
回顾java数组复制
ayaoxinchao
java数组
在写这篇文章之前,也看了一些别人写的,基本上都是大同小异。文章是对java数组复制基础知识的回顾,算是作为学习笔记,供以后自己翻阅。首先,简单想一下这个问题:为什么要复制数组?我的个人理解:在我们在利用一个数组时,在每一次使用,我们都希望它的值是初始值。这时我们就要对数组进行复制,以达到原始数组值的安全性。java数组复制大致分为3种方式:①for循环方式 ②clone方式 ③arrayCopy方
java web会话监听并使用spring注入
bewithme
Java Web
在java web应用中,当你想在建立会话或移除会话时,让系统做某些事情,比如说,统计在线用户,每当有用户登录时,或退出时,那么可以用下面这个监听器来监听。
import java.util.ArrayList;
import java.ut
NoSQL数据库之Redis数据库管理(Redis的常用命令及高级应用)
bijian1013
redis数据库NoSQL
一 .Redis常用命令
Redis提供了丰富的命令对数据库和各种数据库类型进行操作,这些命令可以在Linux终端使用。
a.键值相关命令
b.服务器相关命令
1.键值相关命令
&
java枚举序列化问题
bingyingao
java枚举序列化
对象在网络中传输离不开序列化和反序列化。而如果序列化的对象中有枚举值就要特别注意一些发布兼容问题:
1.加一个枚举值
新机器代码读分布式缓存中老对象,没有问题,不会抛异常。
老机器代码读分布式缓存中新对像,反序列化会中断,所以在所有机器发布完成之前要避免出现新对象,或者提前让老机器拥有新增枚举的jar。
2.删一个枚举值
新机器代码读分布式缓存中老对象,反序列
【Spark七十八】Spark Kyro序列化
bit1129
spark
当使用SparkContext的saveAsObjectFile方法将对象序列化到文件,以及通过objectFile方法将对象从文件反序列出来的时候,Spark默认使用Java的序列化以及反序列化机制,通常情况下,这种序列化机制是很低效的,Spark支持使用Kyro作为对象的序列化和反序列化机制,序列化的速度比java更快,但是使用Kyro时要注意,Kyro目前还是有些bug。
Spark
Hybridizing OO and Functional Design
bookjovi
erlanghaskell
推荐博文:
Tell Above, and Ask Below - Hybridizing OO and Functional Design
文章中把OO和FP讲的深入透彻,里面把smalltalk和haskell作为典型的两种编程范式代表语言,此点本人极为同意,smalltalk可以说是最能体现OO设计的面向对象语言,smalltalk的作者Alan kay也是OO的最早先驱,
Java-Collections Framework学习与总结-HashMap
BrokenDreams
Collections
开发中常常会用到这样一种数据结构,根据一个关键字,找到所需的信息。这个过程有点像查字典,拿到一个key,去字典表中查找对应的value。Java1.0版本提供了这样的类java.util.Dictionary(抽象类),基本上支持字典表的操作。后来引入了Map接口,更好的描述的这种数据结构。
&nb
读《研磨设计模式》-代码笔记-职责链模式-Chain Of Responsibility
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
/**
* 业务逻辑:项目经理只能处理500以下的费用申请,部门经理是1000,总经理不设限。简单起见,只同意“Tom”的申请
* bylijinnan
*/
abstract class Handler {
/*
Android中启动外部程序
cherishLC
android
1、启动外部程序
引用自:
http://blog.csdn.net/linxcool/article/details/7692374
//方法一
Intent intent=new Intent();
//包名 包名+类名(全路径)
intent.setClassName("com.linxcool", "com.linxcool.PlaneActi
summary_keep_rate
coollyj
SUM
BEGIN
/*DECLARE minDate varchar(20) ;
DECLARE maxDate varchar(20) ;*/
DECLARE stkDate varchar(20) ;
DECLARE done int default -1;
/* 游标中 注册服务器地址 */
DE
hadoop hdfs 添加数据目录出错
daizj
hadoophdfs扩容
由于原来配置的hadoop data目录快要用满了,故准备修改配置文件增加数据目录,以便扩容,但由于疏忽,把core-site.xml, hdfs-site.xml配置文件dfs.datanode.data.dir 配置项增加了配置目录,但未创建实际目录,重启datanode服务时,报如下错误:
2014-11-18 08:51:39,128 WARN org.apache.hadoop.h
grep 目录级联查找
dongwei_6688
grep
在Mac或者Linux下使用grep进行文件内容查找时,如果给定的目标搜索路径是当前目录,那么它默认只搜索当前目录下的文件,而不会搜索其下面子目录中的文件内容,如果想级联搜索下级目录,需要使用一个“-r”参数:
grep -n -r "GET" .
上面的命令将会找出当前目录“.”及当前目录中所有下级目录
yii 修改模块使用的布局文件
dcj3sjt126com
yiilayouts
方法一:yii模块默认使用系统当前的主题布局文件,如果在主配置文件中配置了主题比如: 'theme'=>'mythm', 那么yii的模块就使用 protected/themes/mythm/views/layouts 下的布局文件; 如果未配置主题,那么 yii的模块就使用 protected/views/layouts 下的布局文件, 总之默认不是使用自身目录 pr
设计模式之单例模式
come_for_dream
设计模式单例模式懒汉式饿汉式双重检验锁失败无序写入
今天该来的面试还没来,这个店估计不会来电话了,安静下来写写博客也不错,没事翻了翻小易哥的博客甚至与大牛们之间的差距,基础知识不扎实建起来的楼再高也只能是危楼罢了,陈下心回归基础把以前学过的东西总结一下。
*********************************
8、数组
豆豆咖啡
二维数组数组一维数组
一、概念
数组是同一种类型数据的集合。其实数组就是一个容器。
二、好处
可以自动给数组中的元素从0开始编号,方便操作这些元素
三、格式
//一维数组
1,元素类型[] 变量名 = new 元素类型[元素的个数]
int[] arr =
Decode Ways
hcx2013
decode
A message containing letters from A-Z is being encoded to numbers using the following mapping:
'A' -> 1
'B' -> 2
...
'Z' -> 26
Given an encoded message containing digits, det
Spring4.1新特性——异步调度和事件机制的异常处理
jinnianshilongnian
spring 4.1
目录
Spring4.1新特性——综述
Spring4.1新特性——Spring核心部分及其他
Spring4.1新特性——Spring缓存框架增强
Spring4.1新特性——异步调用和事件机制的异常处理
Spring4.1新特性——数据库集成测试脚本初始化
Spring4.1新特性——Spring MVC增强
Spring4.1新特性——页面自动化测试框架Spring MVC T
squid3(高命中率)缓存服务器配置
liyonghui160com
系统:centos 5.x
需要的软件:squid-3.0.STABLE25.tar.gz
1.下载squid
wget http://www.squid-cache.org/Versions/v3/3.0/squid-3.0.STABLE25.tar.gz
tar zxf squid-3.0.STABLE25.tar.gz &&
避免Java应用中NullPointerException的技巧和最佳实践
pda158
java
1) 从已知的String对象中调用equals()和equalsIgnoreCase()方法,而非未知对象。 总是从已知的非空String对象中调用equals()方法。因为equals()方法是对称的,调用a.equals(b)和调用b.equals(a)是完全相同的,这也是为什么程序员对于对象a和b这么不上心。如果调用者是空指针,这种调用可能导致一个空指针异常
Object unk
如何在Swift语言中创建http请求
shoothao
httpswift
概述:本文通过实例从同步和异步两种方式上回答了”如何在Swift语言中创建http请求“的问题。
如果你对Objective-C比较了解的话,对于如何创建http请求你一定驾轻就熟了,而新语言Swift与其相比只有语法上的区别。但是,对才接触到这个崭新平台的初学者来说,他们仍然想知道“如何在Swift语言中创建http请求?”。
在这里,我将作出一些建议来回答上述问题。常见的
Spring事务的传播方式
uule
spring事务
传播方式:
新建事务
required
required_new - 挂起当前
非事务方式运行
supports
&nbs