C++——《高质量C/C++编程》读书笔记
温故而知新
参考: 林锐 《高质量C/C++编程》
极小部分规范是自己根据个人经验自行修改或添加的
文章目录
-
-
- 头文件.h中包含
- 源文件.c/.cpp内容
- 代码行
- 类的版式
- 命名规则
- 表达式和基本语句
-
- 运算符的优先级
- 与零值比较的注意事项
- 指针变量与零值比较
- 常量
-
- const VS #define
- 常量定义规则
- 类中的常量
- 函数设计
-
- 参数的规则
- 函数内部实现的规则
- 其他建议
- 使用断言
- 引用与指针的比较
- 内存管理
-
- 内存分配方式
- 常见的内存错误及其对策
- 指针与数组的对比
-
- 内容复制与比较
- 计算内存容量
- 指针参数传递内存的方式
- free与delete对指针的操作
- 动态内存不会被自动释放
- 杜绝“野指针”
- malloc/free Vs new/delete
- 内存耗尽
- malloc/free的使用要点
- new/delete的使用要点
- C++函数的高级特性
-
- 函数重载的概念
- 当心隐式类型转换导致重载函数产生二义性
- 隐藏规则
- 参数的缺省值
- 运算符重载
- 函数内联
- 类的构造|析构|赋值函数
-
- 构造函数的初始化表
- 构造和析构的次序
- 拷贝构造函数与赋值函数
- 偷懒的办法处理拷贝构造函数与赋值函数
- 在派生类中实现类的基本函数
- 类的继承与组合
- 其他编程经验
-
- 使用const提高函数的健壮性
-
头文件.h中包含
- 版权信息,文件名称,简述,当前版本号,作者/修改者,完成/修改日期,历史版本信息等
- 预处理块
- 函数和类结构声明
样例:
/*
* Copyright (c) 2020, tsuibeyond
* All rights reserved.
*
* FileName: example.h
* Abstract:
* Author: tsuibeyond
* Date: 2020.06.06
* Version: 0.0
*/
#ifndef _EXAMPLE_H_
#define _EXAMPLE_H_
#include 源文件.c/.cpp内容
- 版权信息,文件名称,简述,当前版本号,作者/修改者,完成/修改日期,历史版本信息等
- 对头文件的引用
- 程序的实现体
样例:
/*
* Copyright (c) 2020, tsuibeyond
* All rights reserved.
*
* FileName: example.h
* Abstract:
* Author: tsuibeyond
* Date: 2020.06.06
* Version: 0.0
*/
#include "example.h"
// 全局函数的实现体
void MyFunction(...)
{
}
// 类成员函数的实现体
void MyClass::myFunc(...)
{
...
}
代码行
- 一行代码只做一件事情,如只定义一个变量,或只写一条语句,从而方便阅读与注释
- if,for,while,do等语句自己占一行,执行语句不得紧跟其后,不论执行语句有多少都要加{},防止出现书写失误。
- 当代码较长,特别是有多重嵌套时,应当在一些段落的结束加注释,如
// end for if
// end for while
类的版式
将public类型的函数写在类内部的前面,private类型的数据写在类内部的后面,即以
以行为为中心
重点关注类应该实现什么样的接口。
(不仅让自己在设计类的时候思路清晰,也方便其他人阅读,没有人乐意先看到一堆私有数据成员!)
命名规则
没有一种命名规则能让所有程序员赞同
- 不要混用“大小写”和“小写加下划线”的命名方式,如
AddElement和add_element - 不要出现仅靠大小写区分的相似的标识符,如
int x, X;
void foo(int x);
void FOO(int x); - 尽量不要出现标识符完全相同的局部变量和全局变量
- 变量的名字应当使用“名词”或者“形容词+名词”,如
float value
float oldValue
float newValue - 全局函数的名字应当使用“动词”或者“动词+名词”。类的成员函数应当只使用“动词”,被省略的名词就是对象本身。如
BoilEgg(); // 全局函数
egg->boil(); // 类的成员函数 - 类名和全局函数名用大写字母开头的单次组合而成,如
class Point; // 类名
class Line; // 类名
void Draw(void); // 全局函数名
void SetValue(void); // 全局函数名 - 变量和参数用小写字母开头的单词组合而成,如
bool flag;
int actMode; - 常量全用大写的字母,用下划线分割单词,如
const int MAX = 100;
const int MAX_LENGTH = 100; - 静态变量加前缀s_,用来表示static,如
void Init(void)
{
static int s_initValue; // 静态变量
...
}
- 如果不得已需要全局变量,则使全局变量加前缀g_,如
int g_howManyPeople;
int g_howMuchMoney; - 类的成员函数小写开头大写分割,类的数据成员加前缀m_(表示member),这样可以避免数据成员与成员函数的参数同名,如
void Object::setValue(int width, int height)
{
m_width = width;
m_height = height;
}
表达式和基本语句
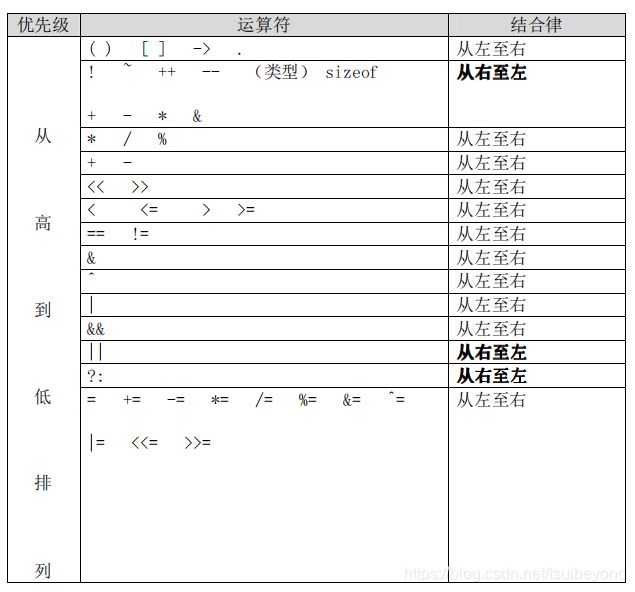
运算符的优先级
如果代码行中的运算符比较多,需要用括号确定表达式的操作顺序,避免使用默认的优先级。
如:if((a|b) && (a&c))
与零值比较的注意事项
- 不可以将布尔变量直接与TRUE、FALSE或者1、0进行比较。(根据布尔类型的语义,零值记为“假”,任何非零值都是“真”,TRUE的值究竟是什么并没有统一的标准。例如,Visual C++将TRUE定义为1,而Visual Basic则将TRUE定义为-1)。
标准写法为:
if(flag) // 表示 flag 为真
if(!flag) // 表示 flag 为假
其它的用法都属于不良风格,例如:
if(flag == TRUE)
if(flag == 1)
if(flag == FALSE)
if(flag == 0)
- 应当将整型变量用“==”或“!=”直接与0比较,标准语句如:
if(value == 0)
if(value != 0)
// 不可以模仿布尔变量的风格写成
if(value) // 会让人误解value是布尔变量
if(!value)
- 浮点变量与零值比较
不可将浮点变量用“==”或“!=”与任何数字比较,正确的写法是
if((x>=-EPSINON) && (x<=EPSINON)) // EPSINON是允许的误差(即精度)
指针变量与零值比较
应当将指针变量用“==”或“!=”与NULL比较
指针变量的零值是“空”(记为NULL),尽管NULL的值与0相同,但是两者意义不同,假设指针变量的名字为p,它与零值比较的标准if语句如下:
// p与NULL显示比较,强调p是指针变量
if(p == NULL)
if(p != NULL)
// 不要写成以下
if(p == 0) // 容易让人误解p是整型变量
if(!p) // 容易让人误解p是布尔变量
常量
const VS #define
C语言使用 #define 来定义常量,称为宏常量
C++ 除了使用#define之外,还可以使用 const 来定义常量。
用 const 定义常量相比于#define,有以下优点:
- const 有数据类型,编译器可以对前者进行类型安全检查,后者智能进行字符替换
- 有些集成化的调试工具可以对const常量进行调试,但是不能对宏常量进行调试
因此,C++程序中只使用 const 常量而不使用 宏常量,即要用
const常量完全取代宏常量
常量定义规则
- 需要对外公开的常量放在头文件中,不需要对外公开的常量放在定义文件的头部。为便于管理,可以把不同模块的常量集中存放在一个公共的头文件中
- 如果某一常量与其他常量密切相关,应在定义中包含这种关系,而不是给出一些孤立的值,如
const float RADIUS = 100;
const float DIAMETER = RADIUS *2;
类中的常量
有时我们希望某些常量只在类中有效。由于#define 定义的宏常量是全局的,不能达到目的,于是想当然地觉得应该用 const 修饰数据成员来实现。const 数据成员的确是存在的,但其含义却不是我们所期望 的。const 数据成员只在 某个对象生存期内是常量,而对于整个类而言却是可变的,因为类可以创建多个对象,不同的对象其 const 数据成员的值可以不同。
不能在类声明中初始化const数据成员,以下用法是错误的,因为类的对象未被创建时,编译器不知道SIZE的值是什么,错误示例如下:
class A
{
const int SIZE = 100; // 错误,企图在类声明中初始化const数据成员
int array[SIZE]; //错误,未知的SIZE
}
const 数据成员的初始化只能在类构造函数的初始化表中进行,例如
class A
{
A(int size); // 构造函数
const int SIZE;
}
A::A(int size) : SIZE(size) // 构造函数的初始化表
{
...
}
A a(100); // 对象 a 的SIZE值为100
A b(200); // 对象 b 的SIZE值为200
建立在整个类中都恒定的常量,需要用枚举常量实现,例如
class A
{
enum { SIZE1 = 100; SIZE2 = 200;}; // 枚举常量
int array1[SIZE1];
int array2[SIZE2];
};
枚举常量不会占用对象的存储空间,会在编译时被全部求值。这样做的缺点是:
- 隐含数据类型是整数,其最大值有限
- 不能表示浮点数,如PI=3.1415926
函数设计
参数的规则
- 函数参数的书写要完整,不要贪图省事只写参数的类型而省略参数的名字。如果函数没有参数,则要用void填充,如
void SetValue(int width, int height); // 良好的风格
void SetValue(int, int); // 不良的风格
float GetValue(void); // 良好的风格
float GetValue(); // 不良的风格
- 参数命名要恰当,顺序要合理。一般地,应将目的参数放在前面,源参数放在后面,如
void StringCopy(char* strSource, char* strDestination);
// 调用时,根据参数命名,可以自然的使用如下调用
char str[20];
StringCopy(str, "hello world");
- 如果参数是指针,且仅用于输入,则应在其类型前加const,以防止指针在函数体内被意外修改,如
void StringCopy(char* strDestination, const char* strSource); - 如果输入参数以值传递的方式传递对象,则宜改用
const &方式来传递,这样可以省去临时对象的构造和析构过程,从而提高效率。 - 避免函数有太多的参数,参数个数尽量控制在 5 个以内。如 果参数太多,在使用时容易将参数类型或顺序搞错。
- 尽量不要使用类型和数目不确定的参数,这种风格的函数在编译时丧失了严格的类型安全检查。C 标准库函数 printf 是采用不确定参数的典型代表,其原型为:
int printf(const char *format[, argument] ...); - 函数名字与返回值类型在语义上不可冲突,违反这条规则的典型代表是C标准库函数getchar,如
char c;
c = getchar();
if( c == EOF )
{
...
}
按照 getchar 名字的意思,将变量 c 声明为 char 类型是很自然的事情。但
不幸的是 getchar 的确不是 char 类型,而是 int 类型,其原型如下:
int getchar(void);
由于 c 是 char 类型,取值范围是[-128,127],如果宏 EOF 的值在 char 的 取值范围之外,那么 if 语句将总是失败,这种“危险”人们一般哪里料得到! 导致本例错误的责任并不在用户,是函数 getchar 误导了使用者
- 不要将正常值和错误标志混在一起返回。正常值用输出参数获得,而错误标志用 return 语句返回。在正常情况下,getchar 的确返回单个字符。但如果 getchar 碰到文件结束 标志或发生读错误,它必须返回一个标志 EOF。为了区别于正常的字符,只好将EOF 定义为负数(通常为负 1)。因此函数 getchar 就成了 int 类型。
- 为了避免出现误解,应该将正常值和错误标志分开。即:正常值用输出参数获得,而错误标志用
return 语句返回。如函数getchar可以改写成bool GetChar(char* c); - 有时候函数原本不需要返回值,但为了增加灵活性如支持链式表达,可以附加返回值。
例如字符串拷贝函数 strcpy 的原型:
char* strcpy(char* strDest, const char* strSrc);
strcpy 函数将 strSrc 拷贝至输出参数 strDest 中,同时函数的返回值又是 strDest。这样做并非多此一举,可以获得如下灵活性:
char str[20];
int length = strlen(strcpy(str, "hello world"));
- 如果函数的返回值是一个对象,有些场合用“引用传递”替 换“值传递”可以提高效率。而有些场合只能用“值传递”而不能用“引用传递”,否则会出错。
例如:
class String
{
// 赋值函数
String & operate=(const String &other);
// 相加函数,如果没有friend修饰则只许有一个右侧参数
friend String operate+(const String &s1, const String &s2);
private:
char* m_data;
}
String的赋值函数operate= 的实现如下:
String & String::operate=(const String &other)
{
if(this == &other)
{
return *this;
}
delete m_data;
m_data = new char[strlen(other.data)+1];
strcpy(m_data, other.data);
return *this; // 返回的是 *this 的引用,无需拷贝过程
}
对于赋值函数,应当用“引用传递”的方式返回 String 对象。如果用“值传递”的方式,虽然功能仍然正确,但由于 return 语句要把 *this 拷贝到保存
返回值的外部存储单元之中,增加了不必要的开销,降低了赋值函数的效率。例如:
String a, b, c;
a = b; // 如果使用“值传递”,将产生一次*this拷贝
a= b = c; // 如果使用“值传递”,将产生两次*this拷贝
String的相加函数operate+的实现如下:
String operate+(const String &s1, const String &s2)
{
String temp;
delete temp.data; // temp.data是仅含'\0'的字符
temp.data = new char[strlen(s1.data)+strlen(s2.data)+1];
strcpy(temp.data, s1.data);
strcat(temp.data, s2.data);
return temp;
}
对于相加函数,应当用“值传递”的方式返回String对象。如果改用“引用传递”,那么函数返回值是一个指向局部对象temp的“引用”,由于temp在函数结束时被自动销毁,将导致返回的“引用”无效,例如:
c = a + b;
此时a+b并不返回期望值,c什么也得不到,留下了隐患。
函数内部实现的规则
- 在函数体的“入口处”,对参数的有效性进行检查。很多程序错误是由非法参数引起的,我们应该充分理解并正确使用“断言” (assert)来防止此类错误。
- 在函数体的“出口处”,对 return 语句的正确性和效率进行检查。如果函数有返回值,那么函数的“出口处”是 return 语句。我们不要轻视 return 语句。如果 return 语句写得不好,函数要么出错,要么效率低下。
-
- return 语句不可返回指向“栈内存”的“指针”或者“引用”,因为该内存在函数体结束时被自动销毁。例如:
char* Func(void)
{
char str[] = "hello world"; // str的内存位于栈上
...
return str; // 将导致错误
}
-
- 要搞清楚返回的究竟是“值”、“指针”还是“引用”。
-
- 如果函数返回值是一个对象,要考虑return语句的效率。例如
return String(s1+s2);这是临时对象的语法,表示“创建一个临时对象并返回它”。不要以为它与“先创建一个局部对象temp并返回它的结果”是等价的,如
- 如果函数返回值是一个对象,要考虑return语句的效率。例如
String temp(s1+s2);
return temp;
实质不然,上述代码将发生三件事。首先,temp 对象被创建,同时完成初始化;然后拷贝构造函数把 temp 拷贝到保存返回值的外部存储单元中;最后,temp在函数结束时被销毁(调用析构函数)。然而“创建一个临时对象并返回它”的
过程是不同的,编译器直接把临时对象创建并初始化在外部存储单元中,省去了拷贝和析构的化费,提高了效率。
类似地,不要将
return int(x+y); // 创建一个临时变量并返回它
写成
int temp = x + y; return temp;
由于内部数据类型如 int,float,double 的变量不存在构造函数与析构函数, 虽然该“临时变量的语法”不会提高多少效率,但是程序更加简洁易读。
其他建议
- 函数的功能要单一,不要设计多用途的函数
- 函数体的规模要小,尽量控制在50行代码以内
- 尽量避免函数带有“记忆”功能,相同的输入应当产生相同的输出。带有“记忆”功能的函数,其行为可能是不可预测的,因为它的行为可能取决于某种“记忆状态”。这样的函数既不易理解又不利于测试和维护。在 C/C++语言中,函数的 static 局部变量是函数的“记忆”存储器。建议尽量少用static局部变量,除非必需。
- 不仅要检查输入参数的有效性,还要检查通过其它途径进入函数体内的变量的有效性,例如全局变量、文件句柄等。
- 用于出错处理的返回值一定要清楚,让使用者不容易忽视或 误解错误情况。
使用断言
程序一般分为 Debug 版本和 Release 版本,Debug 版本用于内部调试,Release版本发行给用户使用。
断言 assert 是仅在 Debug 版本起作用的宏,它用于检查“不应该”发生的情况。在运行过程中,如果 assert 的参数为假, 那么程序就会中止(一般地还会出现提示对话,说明在什么地方引发了 assert)。如:
void* memcpy(void* pvTo, const void* pvFrom, size_t size)
{
assert((pvTo!=NULL) && (pvFrom != NULL); // 使用断言
byte* pbTo = (byte*)pvTo; // 防止改变pvTo的地址
byte* pbFrom = (byte*)pvFrom; // 防止改变pvFrom的地址
while(size-- > 0)
{
*pbTo++ = *pbFrom ++;
}
return pvTo;
}
assert 不是一个仓促拼凑起来的宏。为了不在程序的 Debug 版本和 Release版本引起差别,assert 不应该产生任何副作用。所以 assert 不是函数,而是宏。
程序员可以把 assert 看成一个在任何系统状态下都可以安全使用的无害测试手段。如果程序在 assert 处终止了 assert 处终止了,并不是说含有该 ,并不是说含有该 assert 的函数有错误 assert 的函数有错误,而是调用者出了差错,assert ,assert 可以帮助我们找到发生错误的原因 assert 可以帮助我们找到发生错误的原因。
- 使用断言捕捉不应该发生的非法情况。不要混淆非法情况与错误情况之间的区别,后者是必然存在的并且是一定要作出处理的。
- 在函数的入口处,使用断言检查参数的有效性(合法性)。
- 在编写程序时,要进行反复的考察,一旦确定了的假定,就要使用断言对假定进行检查。
- 一般教科书都鼓励程序员们进行防错设计,但要记住这种编 程风格可能会隐瞒错误。当进行防错设计时,如果“不可能发生”的事情的确发生了,则要使用断言进行报警。
引用与指针的比较
引用是 C++中的概念,初学者容易把引用和指针混淆一起。一下程序中,n 是 m 的一个引用(reference),m 是被引用物(referent)。
int m;
int &n = m;
n相当于m的别名(绰号),对n的任何操作就是对m的操作。
引用的一些规则如下:
- 引用被创建的同时必须被初始化(指针则可以在任何时候被初始化)
- 不能有 NULL 引用,引用必须与合法的存储单元关联(指针则可以是 NULL)
- 一旦引用被初始化,就不能改变引用的关系(指针则可以随时改变所指的对象)
一个容易混淆的例子:
int i = 5;
int j = 6;
int &k = i;
k = j; // k和i的值都变成了6
上面的程序看起来象在玩文字游戏,没有体现出引用的价值。引用的主 要功能是传递函数的参数和返回值。C++语言中,函数的参数和返回值的传递方式有三种:值传递、指针传递和引用传递
实际上,“引用”可以做的任何事情“指针”也都能够做,为什么还要设计“引用”机制?
实际上是为了用适当的工具做恰如其分的工作。
(减小使用指针时可能造成的风险)
内存管理
内存分配方式
- 从静态存储区域分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量,static 变量。
- 在栈上创建。在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令 集中,效率很高,但是分配的内存容量有限。
- 从堆上分配,亦称动态内存分配。程序在运行的时候用 malloc 或 new 申请任意多少的内存,程序员自己负责在何时用 free 或 delete 释放内存。动态内存的生存期由我们决定,使用非常灵活,但问题也最多。
常见的内存错误及其对策
- 内存分配未成功,却使用了它。 编程新手常犯这种错误,因为他们没有意识到内存分配会不成功。常用解决办法是,在使用内存之前检查指针是否为 NULL。如果指针 p 是函数的参数,那么在函数的入口处用 assert(p!=NULL)进行检查。如果是用 malloc 或 new 来申 请内存,应该用 if(p==NULL) 或 if(p!=NULL)进行防错处理。
- 内存分配虽然成功,但是尚未初始化就引用它。犯这种错误主要有两个起因:一是没有初始化的观念;二是误以为内存的缺省初值全为零,导致引用初值错误(例如数组)。
- 内存分配成功并且已经初始化,但操作越过了内存的边界。例如在使用数组时经常发生下标“多 1”或者“少 1”的操作。特别是在 for循环语句中,循环次数很容易搞错,导致数组操作越界。
- 忘记了释放内存,造成内存泄露。含有这种错误的函数每被调用一次就丢失一块内存。刚开始时系统的内存充 足,你看不到错误。终有一次程序突然死掉,系统出现提示:内存耗尽。
动态内存的申请与释放必须配对,程序中 malloc 与 free 的使用次数一定要相同,否则肯定有错误(new/delete 同理)。 - 释放了内存却继续使用它。
(1)程序中的对象调用关系过于复杂,实在难以搞清楚某个对象究竟是否已经释放了内存,此时应该重新设计数据结构,从根本上解决对象管理的混乱局面。
(2)函数的 return 语句写错了,注意不要返回指向“栈内存”的“指针”或者“引用”,因为该内存在函数体结束时被自动销毁。
(3)使用 free 或 delete 释放了内存后,没有将指针设置为 NULL。导致产生“野指针”。 - 用 malloc 或 new 申请内存之后,应该立即检查指针值是否为 NULL。防止使用指针值为 NULL 的内存。
- 不要忘记为数组和动态内存赋初值。防止将未被初始化的内存作为右值使用。
- 避免数组或指针的下标越界,特别要当心发生“多 1”或者 “少 1”操作。
- 动态内存的申请与释放必须配对,防止内存泄漏。
- 用 free 或 delete 释放了内存之后,立即将指针设置为 NULL,防止产生“野指针”。
指针与数组的对比
C++/C程序中,指针和数组在不少地方可以相互替换着用,但实际上两者是不等价的。
- 数组要么在静态存储区被创建(如全局数组),要么在栈上被创 建。数组名对应着(而不是指向)一块内存,其地址与容量在生命期内保持不变, 只有数组的内容可以改变。
- 指针可以随时指向任意类型的内存块,它的特征是“可变”,所以我们常用指针来操作动态内存。指针远比数组灵活,但也更危险。
比较指针与数组的例子:
#include 内容复制与比较
数组和指针的内容复制方面比较类似
- 不能对数组名进行直接复制与比较。若想把数组 a 的内容复制给数组 b,不能用语句 b = a ,否则将产生编译错误。应该用标准库函 数 strcpy 进行复制。同理,比较 b 和 a 的内容是否相同,不能用 if(b==a) 来 判断,应该用标准库函数 strcmp 进行比较。
- 对于指针,p=a只是把地址复制了,如果想复制地址处的内容,可以先用库函数malloc申请一块容量为strlen(a)+1个字符的内存,再用strcpy进行字符串复制。同理,语句if(p==a)比较的不是内容而是地址,应该用库函数strcmp来比较。
// 数组
char a[] = "hello";
char b[10];
strcpy(b,a); // 不能使用 b = a;
if(strcmp(b,a)==0) // 不能用 if(b == a)
// 指针
int len = strlen(a);
char *p = (char*)malloc(sizeof(char)*(len+1));
strcpy(p,a); // 不能使用 p = a
if(strcmp(p,a)) // 不能使用if(p == a)
计算内存容量
C++/C语言无法知道指针所指的内存容量,除非在申请内存时记住它。如:
char a[] = "hello world";
char *p = a;
cout<<sizeof(a)<<endl; // 12 字节
cout<<sizeof(p)<<endl; // 4 字节
注意当数组作为函数的参数进行传递时,该数组自动退化为同类型的指针 ,该数组自动退化为同类型的指针。
void Func(char a[100])
{
cout<<sizeof(a)<<endl; // 4字节而不是100字节
}
指针参数传递内存的方式
如果函数的参数是一个指针,不要指望用该指针去申请动态内存。如:
void GetMemory(char* p, int num)
{
p = (char*)malloc(sizeof(char)*num);
}
void Test(void)
{
char* str = NULL;
GetMemory(str, 100); // str 仍然为 NULL
strcpy(str, "hello"); // 运行错误
}
问题分析:编译器总是要为函数的每个参数制作临时副本,指针参数 p 的副本是 _p,编译器使 _p = p。如果函数体内的程序修改了_p的内容,就导致参数 p 的内容作相应的修改。这是指针可以用作输出参数的原因。在本例中,_p 申请了新的内存,只是把 _p 所指的内存地址改变了,但是 p 丝毫未变。所以函数 GetMemory 并不能输出任何东西。事实上,每执行一次GetMemory 就会泄露一块内存,因 为没有用 free 释放内存。
**解决方法1:**改用 “指向指针的指针”,如
void GetMemory2(char** p, int num)
{
*p = (char*)malloc(sizeof(char)*num);
}
void Test2(void)
{
char* str = NULL;
GetMemory2(&str, 100); // 注意参数是 &str, 而不是str
strcpy(str, "hello");
cout<<str<<endl;
free(str);
}
**解决方法2:**用函数返回值来传递动态内存,这种方法更加简单,如
char* GetMemory3(int num)
{
char* p = (char*)malloc(sizeof(char)*num);
return p;
}
void Test3(void)
{
char *str = NULL;
str = GetMemory3(100);
strcpy(str,"hello");
cout<<str<<endl;
free(str);
}
但是需要强调,不要用return语句返回指向“栈内存”的指针,因为该内存在函数结束时自动消亡。如下例子:
char *GetString(void)
{
// return 语句返回指向了“栈内存”的指针
char p[] = "hello world";
return p; // 编译器将提出警告
}
void test4(void)
{
char *str = NULL;
str = GetString(); // str的内容是垃圾
cou<<str<<endl;
}
如果将上例改写为:
char *GetString2(void)
{
char* p = "hello world";
return p;
}
void Test5(void)
{
char* str = NULL;
str = GetString2();
cout<<str<<endl;
}
函数运行虽然不会出错,但是设计概念有错,因为“hello world”是常量字符串,位于静态存储区,它在程序生命周期中恒定不变。无论什么时候调用GetString2,它返回的始终是同一个“只读”的内存块。
free与delete对指针的操作
free与delete只把指针所指的内存释放掉,但是并没有把指针本身清除。
一个指针p被free或delete之后,其地址仍然不变(非NULL),只是该地址对应的内存是垃圾,p成了“野指针”。如果此时不把p设置成NULL,会让人误以为p是个合法的指针。
基于以上分析,用if(p!=NULL)进行防错处理将起不到预期的作用,因为即便p不是NULL指针,它也不指向合法的内存块。
动态内存不会被自动释放
函数体内的局部变量在函数结束时自动消亡,但是局部指针在函数内申请的内存,不会自动释放,如
void Func(void)
{
char* p = (char*)malloc(100); // 动态内存不会自动释放
}
- 指针消亡了,并不表示它所指的内存会被自动释放
- 内存被释放了,并不表示指针 ,并不表示指针会消亡或者成了 NULL 指针
杜绝“野指针”
“野指针”不是NULL指针,是指向“垃圾”内存的指针。人们一般不会错用 NULL 指针,因为用 if 语句很容易判断。但是“野指针”是很危险的,if 语句对它不起作用。
“野指针”的成因主要有两种:
(1)指针变量没有被初始化。任何指针变量刚被创建时不会自动成为 NULL 指针,它的缺省值是随机的,它会乱指一气。所以,指针变量在创建的同时应当被初始化,要么将指针设置为 NULL,要么让它指向合法的内存。
(2)指针 p 被 free 或者 delete 之后,没有置为 NULL,让人误以为 p 是个合法的指针。
(3)指针操作超越了变量的作用范围。这种情况让人防不胜防。
#include 但是 上面的程序运行时没有报错或出错!!!有点诡异!
malloc/free Vs new/delete
malloc 与 free 是 C++/C 语言的标准库函数,new/delete 是 C++的运算符。它们都可用于申请动态内存和释放内存。
对于非内部数据类型的对象而言,光用 maloc/free 无法满足动态对象的要求。对象在创建的同时要自动执行构造函数,对象在消亡之前要自动执行析构函数。由于 malloc/free 是库函数而不是运算符,不在编译器控制权限之内,不能够把执行构造函数和析构函数的任务强加于 malloc/free。
因此 C++语言需要一个能完成动态内存分配和初始化工作的运算符 new,以及一个能完成清理与释放内存工作的运算符 delete。注意 new/delete不是库函数。
由于内部数据类型的“对象”(如int double之类)没有构造与析构的过程,对它们而言malloc/free 和 new/delete 是等价的。
内存耗尽
如果在申请动态内存时找不到足够大的内存块,malloc 和 new 将返回 NULL 指针,宣告内存申请失败。通常判断指针是否为 NULL,如果是则马上用 return 语句或exit(1)终止本函数。如:
void Func(void)
{
A *a = new A;
if(a == NULL)
{
return;
// 或
// exit(1);
}
}
如果发生“内存耗尽”这样的事情,一般说来应用程序已 经无药可救。如果不用 exit(1) 把坏程序杀死,它可能会害死操作系统。
malloc/free的使用要点
函数 malloc 的原型如下:
void * malloc(size_t size);
用malloc申请一块长度为length的整数类型的内存,程序如下:
int *p = (int*)malloc(sizeof(int)*length);
malloc 返回值的类型是 void*,所以在调用 malloc 时要显式地进行类型 转换,将 void* 转换成所需要的指针类型。
函数free的原型如下:
void free(void * memblock);
是因为指针 p 的类型 以及它所指的内存的容量事先都是知道的,语句 free§能正 确地释放内存。 如果 p 是 NULL 指针,那么 free 对 p 无论操作多少次都不会出问题。
如果 p 不是NULL 指针,那么 free 对 p 连续操作两次就会导致程序 运行错误。
new/delete的使用要点
new 内置了 sizeof、类型转换和类型安全检查功能。对于非内部数据类型的对象而言,new 在创建动态对象的同时完成了初始化工作。如果对象有多个构造函数,那么 new 的语句也可以有多种形式。如:
class Obj
{
public:
Obj(void); // 无参数的构造函数
Obj(int x); // 带一个参数的构造函数
}
void Test(void)
{
Obj* a = new Obj;
Obj* b = new Obj(1); //初值为1
// ...
delete a;
delete b;
}
如果用 new 创建对象数组,那么只能使用对象的无参数构造函数。例如
Obj* objects = new Obj[100];
不能写成
Obj* objects = new Obj[100](1);
在用delete释放对象数组时,留意不能丢失符号’[]’,例如:
delete []objects; // 正确的用法
C++函数的高级特性
对比于 C 语言的函数,C++增加了重载(overloaded)、内联(inline)、 const 和 virtual 四种新机制。
重载和内联机制既可用于全局函数也可用于类的成员函数,const 与 virtual 机制仅用于类的成员函数。
函数重载的概念
在 C++程序中,可以将语义、功能相似的几个函数用同一个名字表示, 即函数重载。这样便于记忆,提高了函数的易用性,这是 C++语言采用重 载机制的一个理由。
C++语言采用重载机制的另一个理由是:类的构造函数需要重载机制。因为 C++规定构造函数与类同名,构造函数只能有一个名字。如果想用几种不同的方法创建对象该怎么办?别无选择,只能用重载机制来实现。所以类可以有多个同名的构造函数。
以只能靠参数而不能靠返回值类型的不同来区分重载函数。编译器根据参数为每个重载函数产生不同的内部标识符。
如果C++程序要调用已经被编译后的 C 函数,假设某个C函数的声明如下:
void foo(int x, int y);
该函数被 C 编译器编译后在库中的名字为_foo,而 C++编译器则会产生像 _foo_int_int 之类的名字用来支持函数重载和类型安全连接。由于编译后的名字不同,C++程序不能直接调用 C 函数。
C++提供了一个 C 连接交换指定符号 extern“C”来解决这个问题。例如:
extern "C"
{
void foo(int x, int y);
// 其他函数
}
或者写成
extern "C"
{
#include "myheader.h"
// 其他函数
}
这就告诉 C++编译译器,函数 foo 是个 C 连接,应该到库中找名字_foo 而不 是找_foo_int_int。C++编译器开发商已经对 C 标准库的头文件作了 extern“C”处理,所以我们可以用#include 直接引用这些头文件。
注意并不是两个函数的名字相同就能构成重载。全局函数和类的成员函数同名不算重载,因为函数的作用域不同。例如:
void Print(...); // 全局函数
class A
{
void Print(...); // 成员函数
}
不论两个 Print 函数的参数是否不同,如果类的某个成员函数要调用全局函数 Print,为了与成员函数 Print 区别,全局函数被调用时应加‘::’标志。如
::Print(...); // 表示 Print 是全局函数而非成员函数
当心隐式类型转换导致重载函数产生二义性
成员函数的重载、覆盖(override)与隐藏很容易混淆,C++程序员必须 要搞清楚概念,否则错误将防不胜防。
成员函数被重载的特征:
- 相同的范围(在同一个类中);
- 函数名字相同;
- 参数不同;
- virtual 关键字可有可无。
覆盖是指派生类函数覆盖基类函数,特征是:
- 不同的范围(分别位于派生类与基类);
- 函数名字相同;
- 参数相同;
- 基类函数必须有 virtual 关键字。
隐藏规则
本来仅仅区别重载与覆盖并不算困难,但是 C++的隐藏规则使问题复杂 性陡然增加。这里“隐藏”是指派生类的函数屏蔽了与其同名的基类函数,规则如下:
- 如果派生类的函数与基类的函数同名,但是参数不同。此时,不论有无 virtual 关键字,基类的函数将被隐藏(注意别与重载混淆)。
- 如果派生类的函数与基类的函数同名,并且参数也相同,但是基类函数没有 virtual 关键字。此时,基类的函数被隐藏(注意别与覆盖混淆)。
参数的缺省值
有一些参数的值在每次函数调用时都相同,书写这样的语句会使人厌烦。C++语言采用参数的缺省值使书写变得简洁(在编译时,缺省值由编译器自动插入)。
参数缺省值的使用规则:
- 参数缺省值只能出现在函数的声明中,而不能出现在定义体中。
- 如果函数有多个参数,参数只能从后向前挨个儿缺省,否则将导致函数调用语句怪模怪样。
- 要注意,使用参数的缺省值并没有赋予函数新的功能,仅仅是使书写变得简洁一些。
运算符重载
在 C++语言中,可以用关键字 operator 加上运算符来表示函数,叫做运算符重载。
从语法上讲,运算符既可以定义为全局函数,也可以定义为成员函数。
在 C++运算符集合中,有一些运算符是不允许被重载的。这种限制是出 于安全方面的考虑,可防止错误和混乱:
- 不能改变 C++内部数据类型(如 int,float 等)的运算符。
- 不能重载‘.’,因为‘.’在类中对任何成员都有意义,已经成为标准用 法。
- 不能重载目前 C++运算符集合中没有的符号,如#,@,$等。原因有两点,一是难以理解,二是难以确定优先级。
- 对已经存在的运算符进行重载时,不能改变优先级规则,否则将引起混乱。
函数内联
C++ 语言支持函数内联,其目的是为了提高函数的执行效率(速度)。
在 C 程序中,可以用宏代码提高执行效率。宏代码本身不是函数,但使用起来象函数。预处理器用复制宏代码的方式代替函数调用,省去了参数压 栈、生成汇编语言的 CALL 调用、返回参数、执行 return 等过程,从而提高了速度。使用宏代码最大的缺点是容易出错,预处理器在复制宏代码时常常产生 意想不 到的边际效应。例如
#define MAX(a, b) (a)>(b)?(a):(b)
语句
result = MAX(i,j)+2
将被预处理器解释为
result = (i)>(j)?(i):(j)+2
由于运算符‘+’比运算符‘:’的优先级高,所以上述语句并不等价于期望的
result = ((i)>(j)?(i):(j))+2;
如果把宏代码改写为
#define MAX(a, b) ((a)>(b)?(a):(b))
则可以解决由优先级引起的错误。但是即使使用修改后的宏代码也不是万无一失的,例如语句
result = MAX(i++, j);
将被预处理器解释为
result = (i++)>(j)?(i++):(j);
对于 C++ 而言,使用宏代码还有另一种缺点:无法操作类的私有数据成员。
对于任何内联函数,编译器在符号表里放入函数的声明(包括名字、参数类型、返回值类型)。如果编译器 没有发现内联函数存在错 误,那么该函数的代码也被放入符号表里。在调用一个内联函数时,编译器首先检查调用是否正确(进行类型安全检查,或者进行自动类型转换,当然对所有的函数 都一样)。如果正确,内联函数的代码就会直 接替换函数调用,于是省去了函数调用的开销。这个过程与预处理有显著的不同, 因为预处理器不能进行类型安全检 查,或者进行自动类型转换。假如内联函数是成员函数,对象的地址(this)会被放在合适的地方,这也是预处理器办不到的。
C++ 语言的函数内联机制既具备宏代码的效率,又增加了安全性,而且可以自由操作类的数据成员。所以在 C++ 程序中,应该用内联函数取代所有宏代码,“断言 assert”恐怕是唯一的例外。assert 是仅在 Debug 版本起作用的宏,它用于检查“不应该”发生的情况。为了不在程序的 Debug 版本和 Release 版本引起差别,assert 不应该产生任何副作用。如果 assert 是函数,由于函数调用会引起内存、代码的变动,那么将导致 Debug 版本与 Release 版本存在差异。所以assert 不是函数,而是宏。
inline 是一种“用于实现的关键字”,而不是一种“用于声明的关键字”。一般地,用户可以阅读函数的声明,但是看不到函数的定 义。尽管在大多数教科书中内联函数的声明、定义体前面都加了 inline 关键字,但我认为 inline 不应该出现在函数的声明中。这个细节虽然不会影响函 数的功能, 但是体现了高质C++/C 程序设计风格的一个基本原则:声明与定义不可混为一谈,用户没有必要、也不应该知道函数是否需要内联。
需要注意的是:
- 定义在类声明之中的成员函数将自动地成为内联函数
- 将成员函数的定义体放在类声明之中虽然能带来书写上的方便,但不是一种良好的编程风格。
- 内联是以代码膨胀(复制)为代价,仅仅省去了函数调用的开销,从而提高函数的执行效率。如果执行函数体内代码的时间,相比于函数调用的开销较大,那么效率的收获会很少。另一方面,每一处内联函数的调用都要复制代码, 将使程序的总代码量增大,消耗更多的内存空间。
以下情况不宜使用内联:
- 如果函数体内的代码比较长,使用内联将导致内存消耗代价较高。
- 如果函数体内出现循环,那么执行函数体内代码的时间要比函数调用的开 销大。
类的构造函数和析构函数容易让人误解成使用内联更有效。要当心构造函数和析构函数可能会隐藏一些行为,如“偷偷地”执行了基类或成员对象的构造函数和析构函数。所以不要随便地将构造函数和析构函数的定义体放在类声明中。
一个好的编译器将会根据函数的定义体,自动地取消不值得的内联(这进一 步说明了 inline 不应该出现在函数的声明中)。
类的构造|析构|赋值函数
每个类只有一个析构函数和一个赋值函数,但可以有多个构造函数(包含一个拷贝构造函数,其它的称为普通构造函数)。对于任意一个类 A,如果不想编写上述函数,C++编译器将自动为 A 产生四个缺省的函数,如
A(void); // 缺省的无参数构造函数
A(const A &a); // 缺省的拷贝构造函数
~A(void); // 缺省的析构函数
A & operate=(const A & a); // 缺省的赋值函数
- 如果使用“缺省的无参数构造函数”和“缺省的析构函数”,等于放弃了 自主“初始化”和“清除”的机会,C++发明人 Stroustrup 的好心好意白费了。
- “缺省的拷贝构造函数”和“缺省的赋值函数”均采用“位拷贝”而非“值拷贝”的方式来实现,倘若类中含有指针变量,这两个函数注定将出错。
构造函数与析构函数与类名同名,且没有返回值,与返回值类型为void的函数不同。
构造函数的初始化表
构造函数有个特殊的初始化方式叫“初始化表达式表”(简称初始化表)。初始化表位于函数参数表之后,却在函数体 {} 之前。这说明该表里的初始化工作发生在函数体内的任何代码被执行之前。
构造函数初始化表的使用规则:
- 如果类存在继承关系,派生类必须在其初始化表里调用基类的构造函数,如:
class A
{
A(int x); // A 的构造函数
};
class B:public A
{
B(int x, int y); // B 的构造函数
};
B::B(int x, int y)
:A(x)
{
// ...
};
- 类的 const 常量只能在初始化表里被初始化,因为它不能在函数体内用赋值的方式来初始化。
- 类的数据成员的初始化可以采用初始化表或函数体内赋值两种方式,这两种方式的效率不完全相同
- 非内部数据类型的成员对象应当采用第一种方式初始化,以获取更高的 ,以获取更高的效率。如:
class A
{
A(void); // 无参数构造函数
A(const A &other); // 拷贝构造函数
A & operate=(const A &other); // 赋值函数
};
class B
{
public:
B(const A &a); // B的构造函数
private:
A m_a; // 成员对象
};
B::B(const A &a)
:m_a(a)
{
}
B::B(const A &a)
{
m_a = a;
}
- 第一种方式,类 B 的构造函数在其初始化表里调用了类 A 的拷贝构造函数,从而将成员对象m_a初始化;
- 类 B 的构造函数在函数体内用赋值的方式将成员对象 m_a初始化。我们看到的只是一条赋值语句,但实际上 B 的构造函数干了两件事:先暗地里创建 m_a 对象(调用了 A 的无参数构造函数),再调用类 A 的赋值函数, 将参数 a 赋给 m_a。
- 对于内部数据类型的数据成员而言,两种初始化方式的效率几乎没有区别,但后者的程序版式似乎更清晰些。
构造和析构的次序
构造从类层次的最根处开始,在每一层中,首先调用基类的构造函数,然后调用成员对象的构造函数。析构则严格按照与构造相反的次序执行, 该次序是唯一的,否则编译器将无法自动执行析构过程。
一个有趣的现象是,成员对象初始化的次序完全不受它们在初始化表中次序的影响,只由成员对象在类中声明的次序决定。这是因为类的声明是唯一的, 而类的构造函 数可以有多个,因此会有多个不同次序的初始化表。如果成员对象按照初始化表的次序进行构造,这将导致析构函数无法得到唯一的逆序。
类String的构造与析构函数
// String 的普通构造函数
String::String(const char * str)
{
if(str==NULL)
{
m_data = new char[1];
*m_data = '\0';
}
else
{
int length = strlen(str);
m_data = new char[length+1];
strcpy(m_data, str);
}
}
// String的析构函数
String::~String(void)
{
delete [] m_data;
}
拷贝构造函数与赋值函数
- 本章开头讲过,如果不主动编写拷贝构造函数和赋值函数,编译器将以“位拷贝”的方式自动生成缺省的函数。倘若类中含有指针变量,那么这两个缺省的函数就隐含了错误。以类 String 的两个对象 a,b 为例,假设 a.m_data的内容为“hello”,b.m_data 的内容为“world”。现将 a 赋给 b,缺省赋值函数的“位拷贝”意味着执行 b.m_data = a.m_data。这将造成三个错误:一是 b.m_data 原有的内存没被释放,造成内存泄露;二是 b.m_data 和 a.m_data 指向同一块内存,a 或 b 任何一方变动都会影响另一方;三是在对象被析构时,m_data 被释放了两次。
- 拷贝构造函数和赋值函数非常容易混淆,常导致错写、错用。拷贝构造函数是在对象被创建时调用的,而赋值函数只能被已经存在了的对象调用。
示例:
String a("hello");
String b("world");
String c = a; // 调用了拷贝构造函数,最好写成c(a);
c = b; // 调用了赋值函数
第三个语句的风格较差,宜改写成 String c(a) 以区别于第四个语句。
String的拷贝构造函数与赋值函数:
// 拷贝构造函数
String::String(const String &other)
{
// 允许操作other的私有成员m_data
int length = strlen(other.m_data);
m_data = new char[length+1];
strcpy(m_data, other.m_data);
}
// 赋值函数
String & string::operate=(const String &other)
{
// (1) 检查自赋值
if(this == &other)
{
return *this;
}
// (2) 释放原有的内存资源
delete [] m_data;
// (3) 分配新的内存资源,并复制内容
int length = strlen(other.m_data);
m_data = new char[length+1];
strcpy(m_data, other.m_data);
// (4) 返回本对象的引用
return *this;
}
类String拷贝构造函数与普通构造函数的区别是:在函数入口处无需与NULL进行比较,这是因为“引用”不可能是NULL,而“指针”可以为NULL。
类String的赋值函数比构造函数复杂得多,分四步实现:
(1)检查自赋值。也许不会写出a=a这样的自赋值语句,按时有可能无意中产生间接的自赋值,如
内容自赋值:
b = a;
...
c = b;
...
a = c;
地址自赋值:
b = &a; // 把a的地址赋值给b
...
a = *b; // b的地址处的内容赋值给a
臆想:“即使出现自赋值,我也可以不理睬,大不了化点时间让对 象复制自己而已,反正不会出错!”
但是,如果在类的赋值函数中有delete,就不能正确的复制自己。(意思是说:间接自赋值可能会被编译器优化成直接赋值??!)
(2)第二步,用delete释放原有的内存资源。如果现在不释放,以后就没机会了,将造成内存泄露。
(3)第三步,分配新的内存资源,并复制字符串。注意函数 strlen 返回的是有效字符串长度,不包含结束符‘\0’。函数 strcpy 则连‘\0’一起复制。
(4)第四步,返回本对象的引用,目的是为了实现象 a = b = c 这样的链式表达。注意不要将 return *this 错写成 return this 。注意: 不可以写成return other,因为我们不知道参数other的生命周期,有可能other是个临时对象,在赋值结束后它会马上消失,那么return other返回的将是垃圾。
偷懒的办法处理拷贝构造函数与赋值函数
安全而且省事的处理拷贝构造函数和赋值函数的办法是:
将拷贝构造函数和赋值函数声明为私有函数,
不用编写代码
例如:
class A
{
private:
A(const A &a); // 私有的拷贝构造函数
A & operate = (const A &a); // 私有的赋值函数
};
如果有人试图编写如下程序:
A b(a); // 调用了私有的拷贝构造函数
b = a; // 调用了私有的赋值函数
编译器将指出错误,因为外界不可以操作A的私有函数。
在派生类中实现类的基本函数
基类的构造函数、析构函数、赋值函数都不能被派生类继承。如果类之间存在继承关系,在编写上述基本函数时应注意以下事项:
(1)派生类的构造函数应在其初始化表里调用基类的构造函数。
(2)基类与派生类的析构函数应该为虚(即加 virtual 关键字)
#include 输出结果为:
~Derived
~Base
如果析构函数不为虚,那么输出结果为
~Base
在编写派生类的赋值函数时,注意不要忘记对基类的数据成员重新赋值,如
class Base
{
public:
...
Base & operate = (const Base &other); // 类Base的赋值函数
private:
int m_i, m_j, m_k;
};
class Derived : public Base
{
public:
...
Derived & operate = (const Derived &other); // 类Derived赋值函数
private:
int m_x, m_y, m_z;
};
Derived & Derived::operate = (const Derived &other)
{
// (1)检查自赋值
if(this == &other)
{
return *this;
}
// (2) 对基类的数据成员重新赋值
Base::operate = (other); // 因为不能直接操作私有数据成员
// (3) 对派生类的数据成员赋值
m_x = other.m_x;
m_y = other.m_y;
m_z = other.m_z;
// (4) 返回本对象的引用
return *this;
}
类的继承与组合
对于 C++程序而言,设计孤立的类是比较容易的,难的是正确设计基类及其派生类。本章仅仅论述“继承”(Inheritance)和“组合”(Composition)的概念。
正因为“继承”太有用、太容易用,才要防止乱用“继承”,需要给“继承”设定一些使用规则:
(1)如果类A和类B毫不相关,不可以为了使B的功能更多些而让B继承A的功能和属性。
(2)若在逻辑上B是A的“一种”,则允许B继承A的功能和属性。例如男人(Man)是人(Human)的一种,男孩(Boy)是男人的一种。那么类Man可以从类Human派生,类Boy可以从类Man派生。
(3)看起来很简单,但是实际应用时可能会有意外,继承的概念在程序世界与现实世界并不完全相同。例如从生物学角度讲,鸵鸟(Ostrich)是鸟(Bird)的一种,按理说类 Ostrich 应该可以从类 Bird 派生。但是鸵鸟不能飞。从数学角度讲,圆(Circle)是一种特殊的椭圆(Ellipse),按理说
类 Circle 应该可以从类 Ellipse 派生。但是椭圆有长轴和短轴,如果圆继承了椭圆的长轴和短轴,岂非画蛇添足?
更加严格的继承规则应当是:若在逻辑上 BBB 是B 是 A 是 AAA 的的“的“一种 “一种”,”,并且 AAA 的所有功能和属性对 A 的所有功能和属性对 BBB 而言都有意义 B 而言都有意义,则允许 ,则允许BBB 继承 B 继承 AAA 的功能和属性 A 的功能和属性。
(4)若在逻辑上 A 是 B 的“一部分”(a part of),则不允许B 从 A 派生,而是要用 A 和其它东西组合出 B。例如眼(Eye)、鼻(Nose)、口(Mouth)、耳(Ear)是头(Head)的一部分,所以类 Head 应该由类 Eye、Nose、Mouth、Ear 组合而成,不是派生而成。
以下的代码虽然正确,但是设计却不合理:
class Head : public Eye, public Nose, public Mouth, public Ear
{
...
};
其他编程经验
使用const提高函数的健壮性
const 更大的魅力是它可以修饰函数的参数、返回值,甚至函数的定义体。所以很多 C++程序设
计书籍建议:“Use const whenever you need”。
(1)用 const 修饰函数的参数。如果参数作输出用,不论它是什么数据类型,也不论它采用“指针传递”还是“引用传递”,都不能加 const 修饰,否则该参数将失去输出功能。
(2)如果输入参数采用“指针传递”,那么加 const 修饰可以防止意外地改动该指针,起到保护作用。
例如StringCopy函数:
void StringCopy(char* strDestination, const char* strSource);
其中 strSource 是输入参数,strDestination 是输出参数。
(3)如果输入参数采用“值传递”,由于函数将自动产生临时变量用于复制该参数,该输入参数本来就无需保护,所以不要加const修饰。例如不要将函数void Func1(int x)写成void Func1(const int x)。
(4)对于非内部数据类型的参数而言,象 void Func(A a) 这样声明的函数注定效率比较底。因为函数体内将产生 A 类型的临时对象用于复制参数 a,而临 时对象的构造、复制、析构过程都将消耗时间。为了提高效率,可以将函数声明改为 void Func(A &a),因为“引用传递” 仅借用一下参数的别名而已,不需要产生临时对象。但是函数 void Func(A &a)存在一个缺点:“引用传递”有可能改变参数 a,这是我们不期望的。解决这个问题很容易,加 const 修饰即可,因此函数最终成为 void Func(const A &a)。
以此类推,是否应将 void Func(int x) 改写为 void Func(const int &x), 以便提高效率?完全没有必要,因为内部数据类型的参数不存在构造、析构的过程,而复制也非常快,“值传递”和“引用传递”的效率几乎相当。
(5)用 const 用 const 修饰函数的返回值
如果给以“指针传递”方式的函数返回值加 const 修饰,那么函数返回值(即指针)的内容不能被修改,该返回值只能被赋给加const 修饰的同类型指针。例如函数
const char* GetString(void);
如下语句将出现编译错误:
char *str = GetString();
正确的用法是
const char *str = GetString();
如果函数返回值采用“值传递方式”,由于函数会把返回值复制到外部临时的存储单元中,加 const 修饰没有任何价值。
函数返回值采用“引用传递”的场合并不多,这种方式一般只出现在类的赋值函数中,目的是为了实现链式表达。例如:
class A
{
A & operate = (const A &other); // 赋值函数
}
A a, b, c; // a, b, c为A的对象
...
a = b = c; // 正常的链式赋值
(a = b) = c; // 不正常的链式赋值,但合法
如果将赋值函数的返回值加const修饰,那么该返回值的内容不允许被改动。上例中,语句a=b=c仍然正确,但是语句(a = b) = c则是非法的。
(6)const 成员函数
任何不会修改数据成员的函数都应该声明为 const 类型。如果在编写const 成员函数时,不慎修改了数据成员,或者调用了其它非 const 成员函数, 编译器将指出错误,这无疑会提高程序的健壮性。
例如,类stack的成员函数GetCount仅用于计数,从逻辑上将GetCount应当为const函数。编译器将指出GetCount函数中的错误。
class Stack
{
public:
void Push(int elem);
int Pop(void);
int GetCount(void) const; // const成员函数
private:
int m_num;
int m_data[100];
};
int Stack::GetCount(void) const
{
++ m_num; //编译错误,企图修改数据成员m_num;
Pop(); // 编译错误,企图调用非const函数
return m_num;
}
const 成员函数的声明看起来怪怪的:const 关键字只能放在函数声明的尾部,大概是因为其它地方都已经被占用了。
(6)提高程序的效率
- 程序的时间效率是指运行速度,空间效率是指程序占用内存或者外存的状况。全局效率是指站在整个系统的角度上考虑的效率,局部效率是指站在模块或函数角度上考虑的效率。
- 不要一味地追求程序的效率,应当在满足正确性、可靠性、健壮性、可读性等质量因素的前提下,设法提高程序的效率。
- 以提高程序的全局效率为主,提高局部效率为辅。
- 在优化程序的效率时,应当先找出限制效率的“瓶颈”,不要在无关紧要之处优化。
- 先优化数据结构和算法,再优化执行代码。
- 有时候时间效率和空间效率可能对立,此时应当分析那个更重要,作出适当的折衷。例如多花费一些内存来提高性能。
- 不要追求紧凑的代码,因为紧凑的代码并不能产生高效的机器码。
(7)其他有益的建议
- 当心那些视觉上不易分辨的操作符发生书写错误。
- 经常会把“==”误写成“=”,像“||”、“&&”、“<=”、“>=”这类符号也很容易发生“丢1”失误,编译器却不一定能够自动指出这类错误。
- 变量(指针、数组)被创建之后应当及时把他们初始化,以防止把未被初始化的变量当成右值使用。
- 当心变量的初值、缺省值错误,或者精度不够。
- 当心数据类型转换发生错误。尽量使用显示的数据类型转换(让人们知道发生了什么事情),避免让编译器悄悄地进行隐式的数据类型转换。
- 当心变量发生上溢或下溢,数组的下标越界。
- 当心忘记编写错误处理程序,当心错误处理程序本身有误。
- 当心文件 I/O 有错误。
- 避免编写技巧性很高代码。
- 不要设计面面俱到、非常灵活的数据结构。
- 如果原有的代码质量比较好,尽量复用它。但是不要修补 很差劲的代码,应当重新编写。
- 尽量使用标准库函数,不要“发明”已经存在的库函数。
- 尽量不要使用与具体硬件或软件环境关系密切的变量。
- 把编译器的选择项设置为最严格状态。
- 如果可能的话,使用 PC-Lint、LogiScope 等工具进行代码审查。