Pytorch学习笔记(深度之眼)(6)之权值初始化
1、梯度消失与爆炸

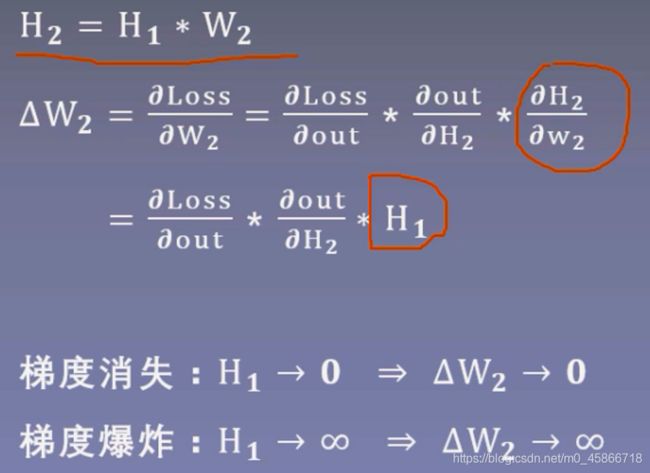 上面公式中, H 1是上一层神经元的输出值, W 2的梯度依赖于上一层的输出,如果 H 1 的输出值趋向于零, W 2 的梯度也趋向于零,从而导致梯度消失。如果 H 1 趋向于无穷大,那么 W 2 也趋向于无穷大,从而导致梯度爆炸。
上面公式中, H 1是上一层神经元的输出值, W 2的梯度依赖于上一层的输出,如果 H 1 的输出值趋向于零, W 2 的梯度也趋向于零,从而导致梯度消失。如果 H 1 趋向于无穷大,那么 W 2 也趋向于无穷大,从而导致梯度爆炸。
从上面我们可以知道,要避免梯度消失或者梯度爆炸,就要严格控制网络输出层的输出值的范围,也就是每一层网络的输出值不能太大也不能太小。
 从公式推导可以发现,第一个隐藏层的输出值的方差变为n,而输入数据的方差为1,经过一个网络层的前向传播,数据的方差就扩大了n倍,标准差扩大了根号n倍。同理,从第一个隐藏层到第二个隐藏层,标准差就变为n。不断往后传播,每经过一层,输出值的尺度范围都会不断扩大根号n倍,最终超出精度可以表示的范围,最终变为nan。
从公式推导可以发现,第一个隐藏层的输出值的方差变为n,而输入数据的方差为1,经过一个网络层的前向传播,数据的方差就扩大了n倍,标准差扩大了根号n倍。同理,从第一个隐藏层到第二个隐藏层,标准差就变为n。不断往后传播,每经过一层,输出值的尺度范围都会不断扩大根号n倍,最终超出精度可以表示的范围,最终变为nan。
从公式中可以发现,标准差由三个因素决定,第一个是n,就是每一层的神经元个数,第二个是X的方差,也就是输入值的方差,第三个是W的方差,也就是网络层权值的方差。从这个公式中可以看到,如果想让网络层的方差保持尺度不变,只能让方差等于1,因为层与层之间的方差是进行相乘得到的。让方差为1,这样多个1相乘得到的方差结果仍为1。
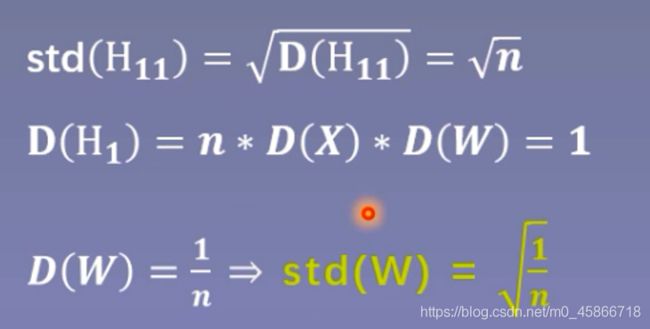 采用一个零均值,标准差为 1 n \sqrt{\frac{1}{n}} n1
采用一个零均值,标准差为 1 n \sqrt{\frac{1}{n}} n1
的分布去初始化权值,再来观察网络层的输出的标准差:
import os
import torch
import random
import numpy as np
import torch.nn as nn
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
set_seed(1) # 设置随机种子
class MLP(nn.Module): # 建立全连接模型
def __init__(self, neural_num, layers):
super(MLP, self).__init__()
self.linears = nn.ModuleList([nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)])
self.neural_num = neural_num
def forward(self, x):
for (i, linear) in enumerate(self.linears):
x = linear(x)
print("layer:{}, std:{}".format(i, x.std()))
if torch.isnan(x.std()):
print("output is nan in {} layers".format(i))
break
return x
def initialize(self): # 初始化模型参数
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight.data,std=np.sqrt(1/self.neural_num))
flag = 1
if flag:
layer_nums = 100
neural_nums = 256
batch_size = 16
net = MLP(neural_nums, layer_nums)
net.initialize()
inputs = torch.randn((batch_size, neural_nums)) # normal: mean=0, std=1
output = net(inputs)
print(output)
结果:
D:\anaconda\install\envs\pytorch_gpu\python.exe G:/hello/test.py
layer:0, std:0.9974957704544067
layer:1, std:1.0024365186691284
layer:2, std:1.002745509147644
layer:3, std:1.0006227493286133
layer:4, std:0.9966009855270386
layer:5, std:1.019859790802002
layer:6, std:1.026173710823059
layer:7, std:1.0250457525253296
layer:8, std:1.0378952026367188
layer:9, std:1.0441951751708984
layer:10, std:1.0181655883789062
layer:11, std:1.0074602365493774
layer:12, std:0.9948930144309998
layer:13, std:0.9987586140632629
layer:14, std:0.9981392025947571
layer:15, std:1.0045733451843262
layer:16, std:1.0055204629898071
layer:17, std:1.0122840404510498
layer:18, std:1.0076017379760742
layer:19, std:1.000280737876892
layer:20, std:0.9943006038665771
layer:21, std:1.012800931930542
layer:22, std:1.012657642364502
layer:23, std:1.018149971961975
layer:24, std:0.9776086211204529
layer:25, std:0.9592394828796387
layer:26, std:0.9317858815193176
layer:27, std:0.9534041881561279
layer:28, std:0.9811319708824158
layer:29, std:0.9953019022941589
layer:30, std:0.9773916006088257
layer:31, std:0.9655940532684326
layer:32, std:0.9270440936088562
layer:33, std:0.9329946637153625
layer:34, std:0.9311841726303101
layer:35, std:0.9354336261749268
layer:36, std:0.9492132067680359
layer:37, std:0.9679954648017883
layer:38, std:0.9849981665611267
layer:39, std:0.9982335567474365
layer:40, std:0.9616852402687073
layer:41, std:0.9439758658409119
layer:42, std:0.9631161093711853
layer:43, std:0.958673894405365
layer:44, std:0.9675614237785339
layer:45, std:0.9837557077407837
layer:46, std:0.9867278337478638
layer:47, std:0.9920817017555237
layer:48, std:0.9650403261184692
layer:49, std:0.9991624355316162
layer:50, std:0.9946174025535583
layer:51, std:0.9662044048309326
layer:52, std:0.9827387928962708
layer:53, std:0.9887880086898804
layer:54, std:0.9932605624198914
layer:55, std:1.0237400531768799
layer:56, std:0.9702046513557434
layer:57, std:1.0045380592346191
layer:58, std:0.9943899512290955
layer:59, std:0.9900636076927185
layer:60, std:0.99446702003479
layer:61, std:0.9768352508544922
layer:62, std:0.9797843098640442
layer:63, std:0.9951220750808716
layer:64, std:0.9980446696281433
layer:65, std:1.0086933374404907
layer:66, std:1.0276142358779907
layer:67, std:1.0429234504699707
layer:68, std:1.0197855234146118
layer:69, std:1.0319130420684814
layer:70, std:1.0540012121200562
layer:71, std:1.026781439781189
layer:72, std:1.0331352949142456
layer:73, std:1.0666675567626953
layer:74, std:1.0413838624954224
layer:75, std:1.0733673572540283
layer:76, std:1.0404183864593506
layer:77, std:1.0344083309173584
layer:78, std:1.0022705793380737
layer:79, std:0.99835205078125
layer:80, std:0.9732587337493896
layer:81, std:0.9777462482452393
layer:82, std:0.9753198623657227
layer:83, std:0.9938382506370544
layer:84, std:0.9472599029541016
layer:85, std:0.9511011242866516
layer:86, std:0.9737769961357117
layer:87, std:1.005651831626892
layer:88, std:1.0043526887893677
layer:89, std:0.9889539480209351
layer:90, std:1.0130352973937988
layer:91, std:1.0030947923660278
layer:92, std:0.9993206262588501
layer:93, std:1.0342745780944824
layer:94, std:1.031973123550415
layer:95, std:1.0413124561309814
layer:96, std:1.0817031860351562
layer:97, std:1.128799557685852
layer:98, std:1.1617802381515503
layer:99, std:1.2215303182601929
tensor([[-1.0696, -1.1373, 0.5047, ..., -0.4766, 1.5904, -0.1076],
[ 0.4572, 1.6211, 1.9659, ..., -0.3558, -1.1235, 0.0979],
[ 0.3908, -0.9998, -0.8680, ..., -2.4161, 0.5035, 0.2814],
...,
[ 0.1876, 0.7971, -0.5918, ..., 0.5395, -0.8932, 0.1211],
[-0.0102, -1.5027, -2.6860, ..., 0.6954, -0.1858, -0.8027],
[-0.5871, -1.3739, -2.9027, ..., 1.6734, 0.5094, -0.9986]],
grad_fn=<MmBackward>)
Process finished with exit code 0
通过分析输出,可以看到输出的范围基本在1左右。因此通过恰当的权重初始化方法可以实现多层的全连接网络的输出值的尺度维持在一定的范围,不会过大也不会过小。通过以上的例子,我们可以知道,需要保持每一个网络层输出的方差为1,但是这里还需要考虑激活函数的存在,下面学习具有激活函数的权值初始化方法。
通过分析结果可以发现,网络层的标准差随着前向传播变得越来越小,从而导致梯度消失。针对存在激活函数的权值初始化问题,分别提出了Xavier方法和Kaiming方法。
2、 Xavier方法与Kaiming方法
Xavier方法

a = np.sqrt(6 / (self.neural_num + self.neural_num)) # Xavier初始化方法
tanh_gain = nn.init.calculate_gain('tanh')
a *= tanh_gain
nn.init.uniform_(m.weight.data, -a, a)
Kaiming初始化
针对Xavier方法不能有效解决Relu非饱和激活函数的问题,2015年提出了Kaiming初始化方法。基于方差一致性原则,Kaiming初始化方法保持数据尺度维持在恰当范围,通常方差为1,这种方法针对的激活函数为ReLU及其变种。

3.常用初始化方法
不良的初始化方法会导致输出的结果发生梯度消失或者梯度爆炸,最终导致模型没有办法正常训练。为了避免这一现象的发生,我们要控制网络层的输出值的尺度范围。从公式推导可以知道,要使每一层的输出值的方差尽量是1,争取方差一致性原则,保持网络层的输出值在1附近,下面来认识一下Pytorch提供的十种权值初始化方法:
Xavier均匀分布;
Xavier正态分布;
Kaiming均匀分布;
Kaiming正态分布;
均匀分布;
正态分布;
常数分布;
正交矩阵初始化;
单位矩阵初始化;
稀疏矩阵初始化;
相关函数:
torch.rand(*sizes, out=None)
均匀分布;返回一个张量,包含了从区间[0, 1)的均匀分布中抽取的一组随机数。张量的形状由参数sizes定义。
参数:
sizes (int…) - 整数序列,定义了输出张量的形状
out (Tensor, optinal) - 结果张量
torch.randn(*sizes, out=None)
标准正态分布;返回一个张量,包含了从标准正态分布(均值为0,方差为1,即高斯白噪声)中抽取的一组随机数。张量的形状由参数sizes定义。
参数:
sizes (int…) - 整数序列,定义了输出张量的形状
out (Tensor, optinal) - 结果张量
torch.nn.init.calculate_gain
torch.nn.init.calculate_gain(nonlinearity, param=None)
nonlinearity - 非线性函数名
param - 非线性函数的可选参数
主要功能
计算激活函数的方差变化尺度;
方差变化尺度意思就是输入数据的方差除于经过激活函数之后的输出数据的方差,也就是方差的比例。