1. 什么是 Babel
简单地说,Babel 能够转译 ECMAScript 2015+ 的代码,使它在旧的浏览器或者环境中也能够运行。
// es2015 的 const 和 arrow function
const add = (a, b) => a + b;
// Babel 转译后
var add = function add(a, b) {
return a + b;
};Babel 的功能很纯粹。我们传递一段源代码给 Babel,然后它返回一串新的代码给我们。就是这么简单,它不会运行我们的代码,也不会去打包我们的代码。
它只是一个编译器。
大名鼎鼎的 Taro 也是利用 Babel 将 React 语法转化成小程序模板。
2. Babel的包构成
核心包
- babel-core:babel转译器本身,提供了babel的转译API,如babel.transform等,用于对代码进行转译。像webpack的babel-loader就是调用这些API来完成转译过程的。
- babylon:js的词法解析器,AST生成
- babel-traverse:用于对AST(抽象语法树,想了解的请自行查询编译原理)的遍历,主要给plugin用
- babel-generator:根据AST生成代码
功能包
- babel-types:用于检验、构建和改变AST树的节点
- babel-template:辅助函数,用于从字符串形式的代码来构建AST树节点
- babel-helpers:一系列预制的babel-template函数,用于提供给一些plugins使用
- babel-code-frames:用于生成错误信息,打印出错误点源代码帧以及指出出错位置
- babel-plugin-xxx:babel转译过程中使用到的插件,其中babel-plugin-transform-xxx是transform步骤使用的
- babel-preset-xxx:transform阶段使用到的一系列的plugin(官方写好的插件)
- babel-polyfill:JS标准新增的原生对象和API的shim,实现上仅仅是core-js和regenerator-runtime两个包的封装
- babel-runtime:功能类似babel-polyfill,一般用于library或plugin中,因为它不会污染全局作用域
工具包
babel-cli:babel的命令行工具,通过命令行对js代码进行转译
babel-register:通过绑定node.js的require来自动转译require引用的js代码文件
babel8 将包名变为了@babel
3. 原理
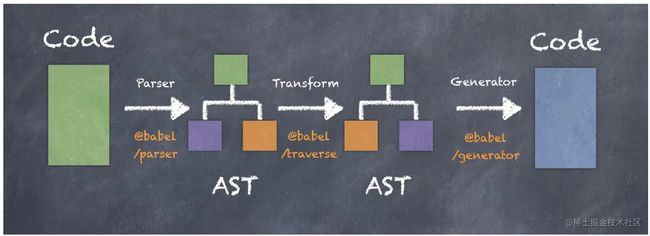
Babel 转换 JS 代码可以分成以下三个大步骤:
- Parser(解析):此过程接受转换之前的源码,输出 AST(抽象语法树)。在 Babel 中负责此过程的包为 babel/parser;
- Transform(转换):此过程接受 Parser 输出的 AST(抽象语法树),输出转换后的 AST(抽象语法树)。在 Babel 中负责此过程的包为 @babel/traverse;
- Generator(生成):此过程接受 Transform 输出的新 AST,输出转换后的源码。在 Babel 中负责此过程的包为 @babel/generator。
所以AST相关知识,你应该预先就了解了
babel是一个转译器,感觉相对于编译器compiler,叫转译器transpiler更准确,因为它只是把同种语言的高版本规则翻译成低版本规则,而不像编译器那样,输出的是另一种更低级的语言代码。
但是和编译器类似,babel的转译过程也分为三个阶段:parsing、transforming、generating,以ES6代码转译为ES5代码为例,babel转译的具体过程如下:
(1)code --> AST
第一步就是把我们写的 ES6 代码字符串转换成 ES6 AST
那转换的工具为 babel 的 parser
怎么转换的你就理解为正常的转 AST,简单的例子会放到结尾
(2)Transform
这一步做的事情,就是操作 AST。 将 ES6 的 AST 操作 JS 转换成 ES5 的 AST
Transform 会遍历AST,在此过程中会对 AST 结构进行添加、移除、更新等操作,当然这些操作依赖开发者提供的插件。Babel 对每一个 AST 节点都提供了「进入节点 enter」 与 「退出节点 exit」 两个时机,第三方开发者可以利用这两个时机对旧 AST 做操作。值得一提的是,Transform 步骤是 Babel 最复杂的部分,也是第三方插件能大显身手的地方。
这一步是最重要的地方,类似webpack,插件plugins就是在这里生效,也可以自己手写插件加入其中。
Transform 过程采用的是典型的 访问者模式 不熟悉的同学可以了解一下。
我们可以看到 AST 中有很多相似的元素,它们都有一个 type 属性,这样的元素被称作节点。一个节点通常含有若干属性,可以用于描述 AST 的部分信息。
比如这是一个最常见的 Identifier 节点:
{
type: 'Identifier',
name: 'add'
}表示这是一个标识符。
所以,操作 AST 也就是操作其中的节点,可以增删改这些节点,从而转换成实际需要的 AST。
Babel 对于 AST 的遍历是深度优先遍历,对于 AST 上的每一个分支 Babel 都会先向下遍历走到尽头,然后再向上遍历退出刚遍历过的节点,然后寻找下一个分支。
参考 前端进阶面试题详细解答
{
"type": "Program",
"body": [
{
"type": "VariableDeclaration", // 变量声明
"declarations": [ // 具体声明
{
"type": "VariableDeclarator", // 变量声明
"id": {
"type": "Identifier", // 标识符(最基础的)
"name": "add" // 函数名
},
"init": {
"type": "ArrowFunctionExpression", // 箭头函数
"id": null,
"expression": true,
"generator": false,
"params": [ // 参数
{
"type": "Identifier",
"name": "a"
},
{
"type": "Identifier",
"name": "b"
}
],
"body": { // 函数体
"type": "BinaryExpression", // 二项式
"left": { // 二项式左边
"type": "Identifier",
"name": "a"
},
"operator": "+", // 二项式运算符
"right": { // 二项式右边
"type": "Identifier",
"name": "b"
}
}
}
}
],
"kind": "const"
}
],
"sourceType": "module"
}根节点我们就不说了,从 declarations 里开始遍历:
- 声明了一个变量,并且知道了它的内部属性(id、init),然后我们再以此访问每一个属性以及它们的子节点。
- id 是一个 Idenrifier,有一个 name 属性表示变量名。
- 之后是 init,init 也有好几个内部属性:
- type 是ArrowFunctionExpression,表示这是一个箭头函数表达式
- • params 是这个箭头函数的入参,其中每一个参数都是一个 Identifier 类型的节点;
- • body 属性是这个箭头函数的主体,这是一个 BinaryExpression 二项式:left、operator、right,分别表示二项式的左边变量、运算符以及右边变量。
这是遍历 AST 的白话形式,再看看 Babel 是怎么做的:
Babel 会维护一个称作 Visitor 的对象,这个对象定义了用于 AST 中获取具体节点的方法。
Visitor
Babel 遍历 AST 其实会经过两次节点:遍历的时候和退出的时候,所以实际上 Babel 中的 Visitor 应该是这样的:
var visitor = {
Identifier: {
enter() {
console.log('Identifier enter');
},
exit() {
console.log('Identifier exit');
}
}
};比如我们拿这个 visitor 来遍历这样一个 AST:
params: [ // 参数
{
"type": "Identifier",
"name": "a"
},
{
"type": "Identifier",
"name": "b"
}
]过程可能是这样的...
- 进入 Identifier(params[0])
- 走到尽头
- 退出 Identifier(params[0])
- 进入 Identifier(params[1])
- 走到尽头
- 退出 Identifier(params[1])
当然,Babel 中的 Visitor 模式远远比这复杂...
回到上面的,箭头函数是 ES5 不支持的语法,所以 Babel 得把它转换成普通函数,一层层遍历下去,找到了 ArrowFunctionExpression 节点,这时候就需要把它替换成 FunctionDeclaration 节点。所以,箭头函数可能是这样处理的:
import * as t from "@babel/types";
var visitor = {
ArrowFunction(path) {
path.replaceWith(t.FunctionDeclaration(id, params, body));
}
};(3) Generate(代码生成)
上一步是将 ES6 的 AST 操作 JS 转换成 ES5 的 AST
这一步就是将 ES5 的AST 转换成 ES5 代码字符串
经过上面两个阶段,需要转译的代码已经经过转换,生成新的 AST 了,最后一个阶段理所应当就是根据这个 AST 来输出代码。
Babel 是深度优先遍历。
Generator 可以看成 Parser 的逆向操作,根据新的 AST 生成代码,其实就是生成字符串,这些字符串本身没有意义,是编译器赋予了字符串意义才变成我们所说的「代码」。Babel 会深度优先遍历整个 AST,然后构建可以表示转换后代码的字符串。
class Generator extends Printer {
constructor(ast, opts = {}, code) {
const format = normalizeOptions(code, opts);
const map = opts.sourceMaps ? new SourceMap(opts, code) : null;
super(format, map);
this.ast = ast;
}
ast: Object;
generate() {
return super.generate(this.ast);
}
}经过这三个阶段,代码就被 Babel 转译成功了。
4. 简单实现
以 const add = (a, b) => a + b 为例,转化完成后应该变成 function add(a,b) {return a + b}。
定义待转化的代码字符串:
/** * 待转化的代码 */
const codeString = 'const add = (a, b) => a + b';(1)ES6 code --> AST
生成AST是需要进行字符串词法分析和语法分析的
首先进行词法分析
/**
* Parser 过程-词法分析
* @param codeString 待转化的字符串
* @returns Tokens 令牌流
*/
function tokens(codeString) {
let tokens = []; //存放 token 的数组
let current = 0; //当前的索引
while (current < codeString.length) {
let char = codeString[current];
//先处理括号
if (char === '(' || char === ')') {
tokens.push({
type: 'parens',
value: char
});
current++;
continue;
}
//处理空格,空格可能是多个连续的,所以需要将这些连续的空格一起放到token数组中
const WHITESPACE = /\s/;
if (WHITESPACE.test(char)) {
let value = '';
while (current < codeString.length && WHITESPACE.test(char)) {
value = value + char;
current++;
char = codeString[current];
}
tokens.push({
type: 'whitespace',
value: value
});
continue;
}
//处理连续数字,数字也可能是连续的,原理同上
let NUMBERS = /[0-9]/;
if (NUMBERS.test(char)) {
let value = '';
while (current < codeString.length && NUMBERS.test(char)) {
value = value + char;
current++;
char = codeString[current];
}
tokens.push({
type: 'number',
value: value
});
continue;
}
//处理标识符,标识符一般以字母、_、$开头的连续字符
const LETTERS = /[a-zA-Z\$\_]/;
if (LETTERS.test(char)) {
let value = '';
//标识符
while (current < codeString.length && /[a-zA-Z0-9\$\_]/.test(char)) {
value = value + char;
current++;
char = codeString[current];
}
tokens.push({
type: 'identifier',
value: value
});
continue;
}
//处理 , 分隔符
const COMMA = /,/;
if (COMMA.test(char)) {
tokens.push({
type: ',',
value: ','
});
current++;
continue;
}
//处理运算符
const OPERATOR = /=|\+|>/;
if (OPERATOR.test(char)) {
let value = '';
while (OPERATOR.test(char)) {
value += char;
current++;
char = codeString[current];
}
//如果存在 => 则说明遇到了箭头函数
if (value === '=>') {
tokens.push({
type: 'ArrowFunctionExpression',
value,
});
continue;
}
tokens.push({
type: 'operator',
value
});
continue;
}
throw new TypeError(`还未加入此字符处理 ${char}`);
}
return tokens;
}语法分析
/** * Parser 过程-语法分析 * @param tokens 令牌流 * @returns AST */
const parser = tokens => {
// 声明一个全时指针,它会一直存在
let current = -1;
// 声明一个暂存栈,用于存放临时指针
const tem = [];
// 指针指向的当前token
let token = tokens[current];
const parseDeclarations = () => {
// 暂存当前指针
setTem();
// 指针后移
next();
// 如果字符为'const'可见是一个声明
if (token.type === 'identifier' && token.value === 'const') {
const declarations = {
type: 'VariableDeclaration',
kind: token.value
};
next();
// const 后面要跟变量的,如果不是则报错
if (token.type !== 'identifier') {
throw new Error('Expected Variable after const');
}
// 我们获取到了变量名称
declarations.identifierName = token.value;
next();
// 如果跟着 '=' 那么后面应该是个表达式或者常量之类的,这里咱们只支持解析函数
if (token.type === 'operator' && token.value === '=') {
declarations.init = parseFunctionExpression();
}
return declarations;
}
};
const parseFunctionExpression = () => {
next();
let init;
// 如果 '=' 后面跟着括号或者字符那基本判断是一个表达式
if (
(token.type === 'parens' && token.value === '(') ||
token.type === 'identifier'
) {
setTem();
next();
while (token.type === 'identifier' || token.type === ',') {
next();
}
// 如果括号后跟着箭头,那么判断是箭头函数表达式
if (token.type === 'parens' && token.value === ')') {
next();
if (token.type === 'ArrowFunctionExpression') {
init = {
type: 'ArrowFunctionExpression',
params: [],
body: {}
};
backTem();
// 解析箭头函数的参数
init.params = parseParams();
// 解析箭头函数的函数主体
init.body = parseExpression();
} else {
backTem();
}
}
}
return init;
};
const parseParams = () => {
const params = [];
if (token.type === 'parens' && token.value === '(') {
next();
while (token.type !== 'parens' && token.value !== ')') {
if (token.type === 'identifier') {
params.push({
type: token.type,
identifierName: token.value
});
}
next();
}
}
return params;
};
const parseExpression = () => {
next();
let body;
while (token.type === 'ArrowFunctionExpression') {
next();
}
// 如果以(开头或者变量开头说明不是 BlockStatement,我们以二元表达式来解析
if (token.type === 'identifier') {
body = {
type: 'BinaryExpression',
left: {
type: 'identifier',
identifierName: token.value
},
operator: '',
right: {
type: '',
identifierName: ''
}
};
next();
if (token.type === 'operator') {
body.operator = token.value;
}
next();
if (token.type === 'identifier') {
body.right = {
type: 'identifier',
identifierName: token.value
};
}
}
return body;
};
// 指针后移的函数
const next = () => {
do {
++current;
token = tokens[current]
? tokens[current]
: {type: 'eof', value: ''};
} while (token.type === 'whitespace');
};
// 指针暂存的函数
const setTem = () => {
tem.push(current);
};
// 指针回退的函数
const backTem = () => {
current = tem.pop();
token = tokens[current];
};
const ast = {
type: 'Program',
body: []
};
while (current < tokens.length) {
const statement = parseDeclarations();
if (!statement) {
break;
}
ast.body.push(statement);
}
return ast;
};可以大概认为,转成AST的过程中就是不断的循环、正则、标识符比对等一系列的操作
(2) Transform
const traverser = (ast, visitor) => {
// 如果节点是数组那么遍历数组
const traverseArray = (array, parent) => {
array.forEach((child) => {
traverseNode(child, parent);
});
};
// 遍历 ast 节点
const traverseNode = (node, parent) => {
const methods = visitor[node.type];
if (methods && methods.enter) {
methods.enter(node, parent);
}
switch (node.type) {
case 'Program':
traverseArray(node.body, node);
break;
case 'VariableDeclaration':
traverseArray(node.init.params, node.init);
break;
case 'identifier':
break;
default:
throw new TypeError(node.type);
}
if (methods && methods.exit) {
methods.exit(node, parent);
}
};
traverseNode(ast, null);
};
/**
* Transform 过程
* @param ast 待转化的AST
* 此函数会调用traverser,传入自定义的visitor完成AST转化
*/
const transformer = (ast) => {
// 新 ast
const newAst = {
type: 'Program',
body: []
};
// 此处在ast上新增一个 _context 属性,与 newAst.body 指向同一个内存地址,traverser函数操作的ast_context都会赋值给newAst.body
ast._context = newAst.body;
traverser(ast, {
VariableDeclaration: {
enter(node, parent) {
let functionDeclaration = {
params: []
};
if (node.init.type === 'ArrowFunctionExpression') {
functionDeclaration.type = 'FunctionDeclaration';
functionDeclaration.identifierName = node.identifierName;
functionDeclaration.params = node.init.params;
}
if (node.init.body.type === 'BinaryExpression') {
functionDeclaration.body = {
type: 'BlockStatement',
body: [{ type: 'ReturnStatement', argument: node.init.body }],
};
}
parent._context.push(functionDeclaration);
}
},
});
return newAst;
};(3) generate
/** * Generator 过程 * @param node 新的ast * @returns 新的代码 */
const generator = (node) => {
switch (node.type) {
// 如果是 `Program` 结点,那么我们会遍历它的 `body` 属性中的每一个结点,并且递归地
// 对这些结点再次调用 codeGenerator,再把结果打印进入新的一行中。
case 'Program':
return node.body.map(generator)
.join('\n');
// 如果是FunctionDeclaration我们分别遍历调用其参数数组以及调用其 body 的属性
case 'FunctionDeclaration':
return 'function' + ' ' + node.identifierName + '(' + node.params.map(generator) + ')' + ' ' + generator(node.body);
// 对于 `Identifiers` 我们只是返回 `node` 的 identifierName
case 'identifier':
return node.identifierName;
// 如果是BlockStatement我们遍历调用其body数组
case 'BlockStatement':
return '{' + node.body.map(generator) + '}';
// 如果是ReturnStatement我们调用其 argument 的属性
case 'ReturnStatement':
return 'return' + ' ' + generator(node.argument);
// 如果是ReturnStatement我们调用其左右节点并拼接
case 'BinaryExpression':
return generator(node.left) + ' ' + node.operator + ' ' + generator(node.right);
// 没有符合的则报错
default:
throw new TypeError(node.type);
}
};(4) 整个流程串联起来,完成调用链
let token = tokens(codeString);
let ast = parser(token);
let newAST = transformer(ast);
let newCode = generator(newAST);
console.log(newCode);5. 其他扩展知识
此外,还要注意很重要的一点就是,babel只是转译新标准引入的语法,比如ES6的箭头函数转译成ES5的函数;而新标准引入的新的原生对象,部分原生对象新增的原型方法,新增的API等(如Proxy、Set等),这些babel是不会转译的。需要用户自行引入polyfill来解决
plugins
插件应用于babel的转译过程,尤其是第二个阶段transforming,如果这个阶段不使用任何插件,那么babel会原样输出代码。
我们主要关注transforming阶段使用的插件,因为transform插件会自动使用对应的词法插件,所以parsing阶段的插件不需要配置。
presets
如果要自行配置转译过程中使用的各类插件,那太痛苦了,所以babel官方帮我们做了一些预设的插件集,称之为preset,这样我们只需要使用对应的preset就可以了。以JS标准为例,babel提供了如下的一些preset:
• es2015
• es2016
• es2017
• env
es20xx的preset只转译该年份批准的标准,而env则代指最新的标准,包括了latest和es20xx各年份
另外,还有 stage-0到stage-4的标准成形之前的各个阶段,这些都是实验版的preset,建议不要使用。
polyfill
polyfill是一个针对ES2015+环境的shim,实现上来说babel-polyfill包只是简单的把core-js和regenerator runtime包装了下,这两个包才是真正的实现代码所在(后文会详细介绍core-js)。
使用babel-polyfill会把ES2015+环境整体引入到你的代码环境中,让你的代码可以直接使用新标准所引入的新原生对象,新API等,一般来说单独的应用和页面都可以这样使用。
runtime
polyfill和runtime的区别(必看)
直接使用babel-polyfill对于应用或页面等环境在你控制之中的情况来说,并没有什么问题。但是对于在library中使用polyfill,就变得不可行了。因为library是供外部使用的,但外部的环境并不在library的可控范围,而polyfill是会污染原来的全局环境的(因为新的原生对象、API这些都直接由polyfill引入到全局环境)。这样就很容易会发生冲突,所以这个时候,babel-runtime就可以派上用场了。