卷积神经网络的基本原理,图卷积神经网络原理
如何理解神经网络里面的反向传播算法
1.普通的机器学习模型:其实,基本上所有的基本机器学习模型都可以概括为以下的特征:根据某个函数,将输入计算并输出。
图形化表示为下图:当我们的g(h)为sigmoid函数时候,它就是一个逻辑回归的分类器。当g(h)是一个只能取0或1值的函数时,它就是一个感知机。
那么问题来了,这一类模型有明显缺陷:当模型线性不可分的时候,或者所选取得特征不完备(或者不够准确)的时候,上述分类器效果并不是特别喜人。
如下例:我们可以很轻易的用一个感知机模型(感知器算法)来实现一个逻辑与(and),逻辑或(or)和逻辑或取反的感知器模型,(感知器模型算法链接),因为上述三种模型是线性可分的。
但是,如果我们用感知器模型取实现一个逻辑非异或(相同为1,不同为0),我们的训练模型的所有输出都会是错误的,该模型线性不可分!
2.神经网络引入:我们可以构造以下模型:(其中,A代表逻辑与,B代表逻辑或取反,C代表逻辑或)上述模型就是一个简单的神经网络,我们通过构造了三个感知器,并将两个感知器的输出作为了另一个感知其的输入,实现了我们想要的逻辑非异或模型,解决了上述的线性不可分问题。
那么问题是怎么解决的呢?其实神经网络的实质就是每一层隐藏层(除输入和输出的节点,后面介绍)的生成,都生成了新的特征,新的特征在此生成新的特征,知道最新的特征能很好的表示该模型为止。
这样就解决了线性不可分或特征选取不足或不精确等问题的产生。
(以前曾介绍过线性不可分的实质就是特征不够)神经网络的模型结构如下:(蓝色,红色,黄色分别代表输入层,影藏层,输出层)在此我们介绍的神经网络中的每一个训练模型用的都是逻辑回归模型即g(h)是sigmoid函数。
我们可以将神经网络表示如下:3.神经网络的预测结果(hypothesis函数)的计算和CostFunction的计算预测结果的计算其实与普通的逻辑回归计算没有多大区别。
只是有时候需要将某几个逻辑回归的输出作为其他逻辑回归模型的输入罢了,比如上例的输出结果为:那么CostFunction的计算又和逻辑回归的CostFunction计算有什么区别呢?
逻辑回归的CostFunction如下:上述式子的本质是将预测结果和实际标注的误差用某一种函数估算,但是我们的神经网络模型有时候输出不止一个,所以,神经网络的误差估算需要将输出层所有的CostFunction相加:k:代表第几个输出。
补充:神经网络可以解决几分类问题?
理论上,当输出单元只有一个时,可以解决2分类问题,当输出单元为2时可以解决4分类问题,以此类推...实质上,我们三个输出单元时,可以解决三分类问题([1,0,0],[0,1,0],[0,0,1]),为什么如此设计?
暂时留白,以后解决ps:面试题:一个output机器,15%可能输出1,85%输出0,构造一个新的机器,使0,1输出可能性相同?
答:让output两次输出01代表0,10代表1,其余丢弃4.神经网络的训练这儿也同于logistic回归,所谓的训练也就是调整w的权值,让我们再一次把神经网络的CostFunction写出来!
W代表所有层的特征权值,Wij(l)代表第l层的第i个元素与第j个特征的特征权值m代表样本个数,k代表输出单元个数hw(x(i))k代表第i个样本在输出层的第k个样本的输出y(i)k代表第i个样本的第k个输出然后同于logistic回归,将所有的W更新即可。
难处在于此处的偏导数怎么求?
首先得说说链式求导法则:所以我们可以有:接下来的问题就是有theta了,当我们要求的错误变化率是最后一层(最后一层既是输出层的前一层)且只看一个输出神经元时则:多个相加即可那么中间层次的神经元变化率如何求得呢?
我们需要研究l层和了+1层之间的关系,如下图:第l层的第i个Z与第l层的第i个a的关系就是取了一个sigmod函数,然而第l层的第i个a与和其对应的w相乘后在加上其他的节点与其权值的乘积构成了第l+1层的Z,好拗口,好难理解啊,看下式:大体也就是这么个情况,具体的步骤为:1.利用前向传播算法,计算出每个神经元的输出2.对于输出层的每一个输出,计算出其所对应的误差3.计算出每个神经元的错误变化率即:4.计算CostFunction的微分,即:
如何对CNN网络的卷积层进行反向传播
在多分类中,CNN的输出层一般都是Softmax爱发猫 www.aifamao.com。RBF在我的接触中如果没有特殊情况的话应该是“径向基函数”(RadialBasisFunction)。
在DNN兴起之前,RBF由于出色的局部近似能力,被广泛应用在SVM的核函数中,当然也有我们熟悉的RBF神经网络(也就是以RBF函数为激活函数的单隐含层神经网络)。
如果说把RBF作为卷积神经网络的输出,我觉得如果不是有特殊的应用背景的话,它并不是一个很好的选择。至少从概率角度上讲,RBF没有Softmax那样拥有良好的概率特性。
如果题主是在什么地方看到它的源代码并且感到困惑的话,可以贴上源链接一起讨论一下。
的定义和计算公式参考:/link?url=7LE6KImv5IveCM90JcnctlgVY7OgCd7E_G0Yv0vyTfV3P8S3Q_rZU3CM6f0udS-b6ux2w-hejkOrGMkmj8Nqba。
卷积神经网络是如何反向调整参数的?
什么是卷积神经网络?为什么它们很重要
卷积神经网络(ConvolutionalNeuralNetwork,CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。
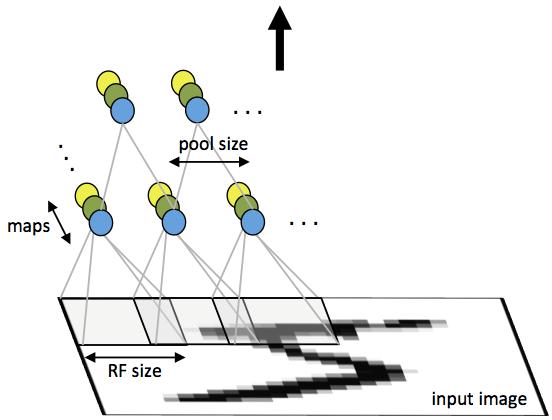
[1] 它包括卷积层(alternatingconvolutionallayer)和池层(poolinglayer)。卷积神经网络是近年发展起来,并引起广泛重视的一种高效识别方法。
20世纪60年代,Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现其独特的网络结构可以有效地降低反馈神经网络的复杂性,继而提出了卷积神经网络(ConvolutionalNeuralNetworks-简称CNN)。
现在,CNN已经成为众多科学领域的研究热点之一,特别是在模式分类领域,由于该网络避免了对图像的复杂前期预处理,可以直接输入原始图像,因而得到了更为广泛的应用。
K.Fukushima在1980年提出的新识别机是卷积神经网络的第一个实现网络。随后,更多的科研工作者对该网络进行了改进。
其中,具有代表性的研究成果是Alexander和Taylor提出的“改进认知机”,该方法综合了各种改进方法的优点并避免了耗时的误差反向传播。
卷积神经网络反向传播和bp有什么区别
CNN(卷积神经网络)是什么?
在数字图像处理的时候我们用卷积来滤波是因为我们用的卷积模版在频域上确实是高通低通带通等等物理意义上的滤波器。
然而在神经网络中,模版的参数是训练出来的,我认为是纯数学意义的东西,很难理解为在频域上还有什么意义,所以我不认为神经网络里的卷积有滤波的作用。接着谈一下个人的理解。
首先不管是不是卷积神经网络,只要是神经网络,本质上就是在用一层层简单的函数(不管是sigmoid还是Relu)来拟合一个极其复杂的函数,而拟合的过程就是通过一次次backpropagation来调参从而使代价函数最小。
请问卷积神经网络的概念谁最早在学术界提出的?
福岛邦彦。2021年4月29日,福岛邦彦(KunihikoFukushima)获得2021年鲍尔科学成就奖。
他为深度学习做出了杰出贡献,其最有影响力的工作当属「Neocognitron」卷积神经网络架构。
其实,熟悉这位JürgenSchmidhuber人都知道,他此前一直对自己在深度学习领域的早期原创性成果未能得到业界广泛承认而耿耿于怀。
1979年,福岛博士在STRL开发了一种用于模式识别的神经网络模型:Neocognitron。很陌生对吧?
但这个Neocognitron用今天的话来说,叫卷积神经网络(CNN),是深度神经网络基本结构的最伟大发明之一,也是当前人工智能的核心技术。什么?
卷积神经网络不是一个叫YannLeCun的大佬发明的吗?怎么又换成了福岛邦彦(KunihikoFukushima)了?
严格意义上讲,LeCun是第一个使用误差反向传播训练卷积神经网络(CNN)架构的人,但他并不是第一个发明这个结构的人。
而福岛博士引入的Neocognitron,是第一个使用卷积和下采样的神经网络,也是卷积神经网络的雏形。
福岛邦彦(KunihikoFukushima)设计的具有学习能力的人工多层神经网络,可以模仿大脑的视觉网络,这种「洞察力」成为现代人工智能技术的基础。
福岛博士的工作带来了一系列实际应用,从自动驾驶汽车到面部识别,从癌症检测到洪水预测,还会有越来越多的应用。