决策树算法分析天气、周末和促销活动对销量的影响
决策树算法分析天气、周末和促销活动对销量的影响
作者:AOAIYI
创作不易,觉得文章不错或能帮助到你,点赞收藏评论一下哦
文章目录
- 决策树算法分析天气、周末和促销活动对销量的影响
- 一、实验目的
- 二、实验原理
- 三、实验环境
- 四、实验内容
- 五、实验步骤
- 总结
一、实验目的
1.掌握决策树的计算原理
2.掌握利用决策树分析商品销量的影响因素
二、实验原理
- 决策树的基本认识
决策树是一种依托决策而建立起来的一种树。在机器学习中,决策树是一种预测模型,代表的是一种对象属性与对象值之间的一种映射关系,每一个节点代表某个对象,树中的每一个分叉路径代表某个可能的属性值,而每一个叶子节点则对应从根节点到该叶子节点所经历的路径所表示的对象的值。决策树仅有单一输出,如果有多个输出,可以分别建立独立的决策树以处理不同的输出。
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
决策树最重要的是决策树的构造。所谓决策树的构造就是进行属性选择度量确定各个特征属性之间的拓扑结构。构造决策树的关键步骤是分裂属性。所谓分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。分裂属性分为三种不同的情况:
1、属性是离散值且不要求生成二叉决策树。此时用属性的每一个划分作为一个分支。
2、属性是离散值且要求生成二叉决策树。此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支。
3、属性是连续值。此时确定一个值作为分裂点split_point,按照>split_point和<=split_point生成两个分支。
信息论中有熵(entropy)的概念,表示状态的混乱程度,熵越大越混乱。熵的变化可以看做是信息增益,决策树ID3算法的核心思想是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。
设D为用(输出)类别对训练元组进行的划分,则D的熵表示为:

其中pi表示第i个类别在整个训练元组中出现的概率,一般来说会用这个类别的样本数量占总量的占比来作为概率的估计;熵的实际意义表示是D中元组的类标号所需要的平均信息量。
如果将训练元组D按属性A进行划分,则A对D划分的期望信息为:

于是,信息增益就是两者的差值:
![]()
ID3决策树算法就用到上面的信息增益,在每次分裂的时候贪心选择信息增益最大的属性,作为本次分裂属性。每次分裂就会使得树长高一层。这样逐步生产下去,就一定可以构建一颗决策树。
接下来以天气预报的例子来说明。下面是描述天气数据表,学习目标是play或者not play。

三、实验环境
Python3.6以上
Pycharm
sklearn0.19.0
四、实验内容
某餐饮企业作为大型连锁企业,生产的产品种类比较多,另外涉及的分店所在的位置也不同,数目比较多。对于企业的高层来讲,了解周末和非周末销售量是否有很大的区别,以及天气、促销活动这些因素是否能够影响门店的销售量等信息至关重要。因此,为了让决策者准确了解和销量有关的一系列影响因素,采用算法构建决策树模型,来分析天气、是否周末和是否有促销活动对销量的影响。
五、实验步骤
1.导入数据所需的外包
import pandas as pd
from sklearn.tree import DecisionTreeClassifier as DTC
from sklearn.tree import export_graphviz
2.导入数据
filename='/data/python13/sales_data.txt'
data=pd.read_csv(filename,index_col='序号')
3.数据预处理
data[data=='好']=1
data[data=='是']=1
data[data=='高']=1
data[data!=1]=-1
4.特征提取
x=data.iloc[:,:3].as_matrix().astype(int)
y=data.iloc[:,3].as_matrix().astype(int)
5.建立决策树模型
dtc=DTC(criterion="gini").fit(x,y)
6.模型可视化
with open( 'tree.dot','w') as f:
f=export_graphviz(dtc,feature_names=data.columns,out_file=f)
7.完整代码
#-*- coding: utf-8 -*-
import pandas as pd
from sklearn.tree import DecisionTreeClassifier as DTC
filename='/data/python13/sales_data.txt'
data=pd.read_csv(filename,index_col='序号')
print(data.columns)
data[data=='好']=1
data[data=='是']=1
data[data=='高']=1
data[data!=1]=-1
x=data.iloc[:,:3].as_matrix().astype(int)
y=data.iloc[:,3].as_matrix().astype(int)
dtc=DTC(criterion="gini").fit(x,y)
from sklearn.tree import export_graphviz
with open( 'tree.dot','w') as f:
f=export_graphviz(dtc,feature_names=data.iloc[:,:3].columns,out_file=f)
8.运行结果:
可以在当前目录下,看到一个名为tree.dot的文件,切换到当前项目所在目录下:~/python13文件下,以如下方式编译,将其转化为可视化文件tree.png
cd ~/python13
dot -Tpng tree.dot -o tree.png
9.在pycharm中打开tree.png文件。
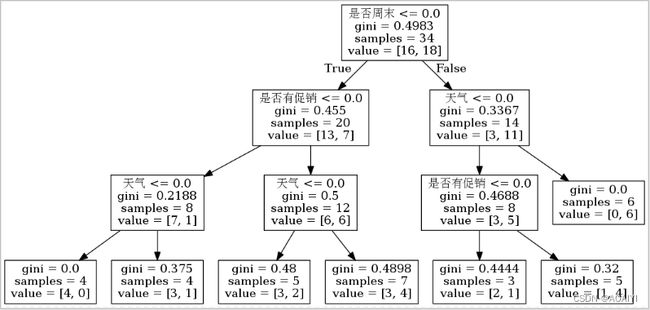
总结
为什么纸上谈兵不行?纸上谈兵太理想化了,把自己没有发现的问题隐藏了,当成了不存在的问题。只有实际多多亲自动手,才会发现有太多的问题是书上没提到的,也是自己没想到的。才会发现,一个小小的问题也要搞上半天。当然,如果你基础巩固的话,那这些问题应该都是可以被你解决的。熟练后,就不认为这些问题了。
不要看代码不难就感觉会了,只有自己的手打一遍,没有错误,编程的严谨些决定了,你错一个字母都不行。所以大家一定要注意,编程是自己打出来的,不是复制,粘贴你就会了,以后碰到了,还是不会。